概要
多様な環境から多数のデータをクラウド環境へ連携する際に、 Azure Data Factory メタデータ駆動コピータスク機能がとても便利です。データ連携ツールがレコード量に対する課金であることから、コストの観点でデータ統合の推進のボトルネックとなることあるようです。そこで、Azure Data Factory のメタデータ駆動のコピータスクを利用することで、コストパフォーマンスに優れたサービスであり、短期間でデータ統合が可能となります。
Azure 上でデータ分析基盤を構築する際には、 Azure Data Factory にてデータインジェストやパイプラインの実行管理を行うためによく利用されています。他クラウドでデータ分析基盤を構築している方であっても、圧倒的にコストパフォーマンスに優れていることから Azure Data Factory の導入を検討することをおすすめします。
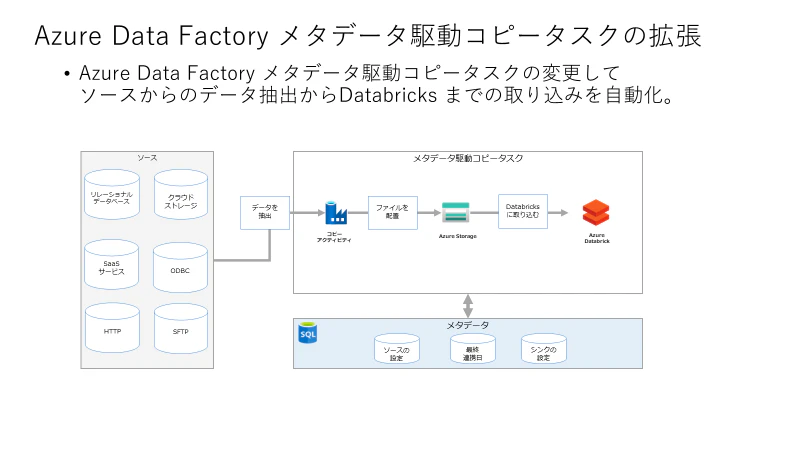
私は本機能を用いて Databricks までの連携を自動化しております。
Azure Data Factory について
Azure Data Factory のメリット
Azure Data Factory には、他社製品と比較すると下記のようなメリットがあります。
- コストパフォーマンスに優れていること
- 90 以上のコネクターを利用できること
- オンプレミス環境など異なるネットワークから安全に連携できること
コストパフォーマンスに優れている
Azure のドキュメントにて S3 から Azure Storage に 1 日 8 時間のデータ移動を実施した際の価格例が紹介されおり、 1 ヶ月当たり $122.00 (1ドル 161.13 円で換算すると約 19,657.68 円)とあります。Azure Data Factory は固定の費用もかからず、コネクターにより費用の変動もないため実際のこのような価格感で利用できます。データ連携ツールによっては、最低 10 万円からの契約であったり利用するコネクターによってはより高額なプランを契約しなくてはいけないことなどがあり、レコード量に応じて高額になることがあります。そういったデータ連携ツールと比較すると圧倒的なコストパフォーマンスです。
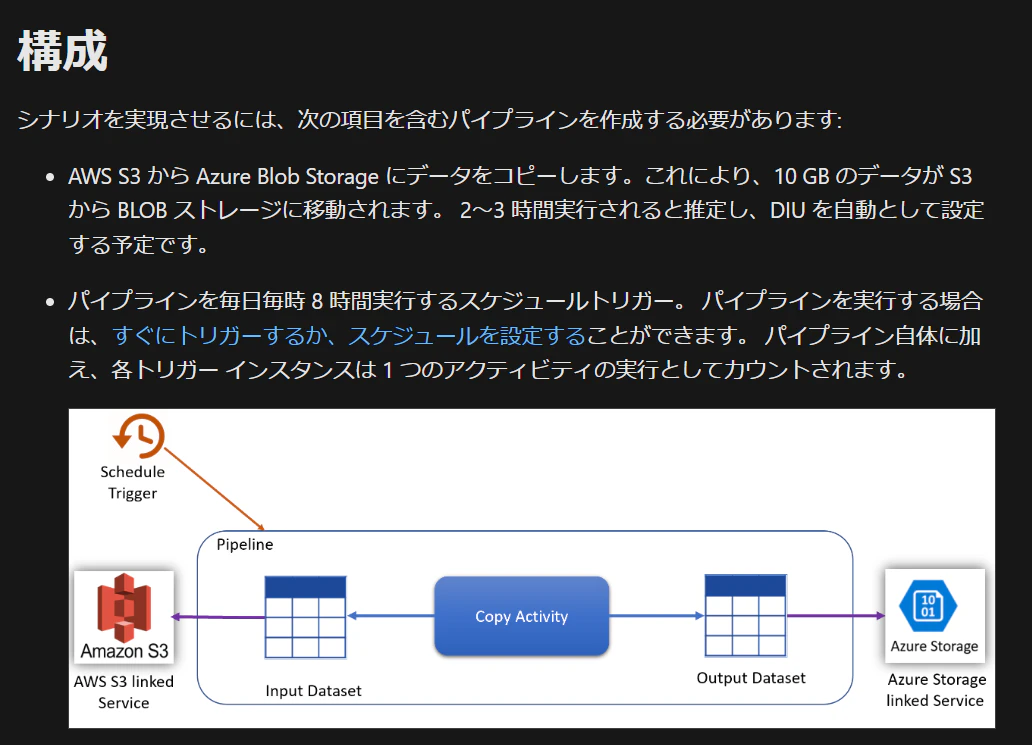
引用元:価格の例: AWS S3 から Azure Blob Storage に 1 時間ごとにデータをコピーする - Azure Data Factory | Microsoft Learn
90 以上のコネクターを利用できること
Azure Data Factory では 90 以上のコネクターを利用できます。一般的に利用されている製品のコネクターはサポートされており、 ODBC や REST API を利用できることが多くのソースからデータ取得できます。

ただし、サポートされている製品が海外でも利用されている製品が多いため、 日本でよく利用されている印象のある Yahoo! 広告や LINE 広告などのマーケティング分野のコネクターは TOROCCO のようにはありません。利用するコネクターがサポート状況の確認は必要です。
オンプレミス環境など異なるネットワークから安全に連携できること
エージェントを任意のサーバーにインストールしてデータ連携をできるため、オンプレミス環境などか異なるネットワーク上にあるデータを安全に連携できます。SaaS 型データ連携ツールの場合にはマルチテナント型であることが多いから、そのネットワークにデータソースを解放する必要がありネットワークポリシーを満たせない場合があります。異なるネットワークから連携が容易になるだけでなく、アウトバウンド時の IP アドレスを固定化できることからデータソースのシステムにて IP 制限を設定した上でデータ連携ができるようになります。
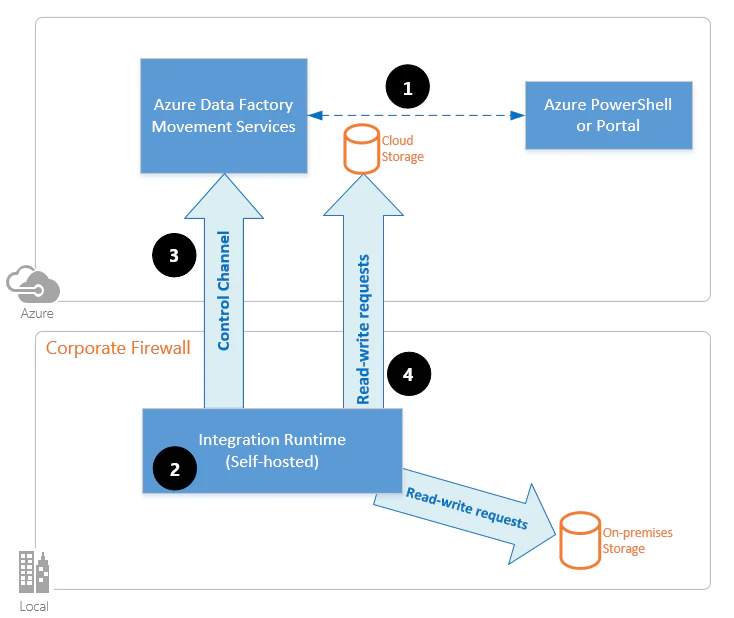
引用元:自己ホスト型統合ランタイムを作成する - Azure Data Factory & Azure Synapse | Microsoft Learn
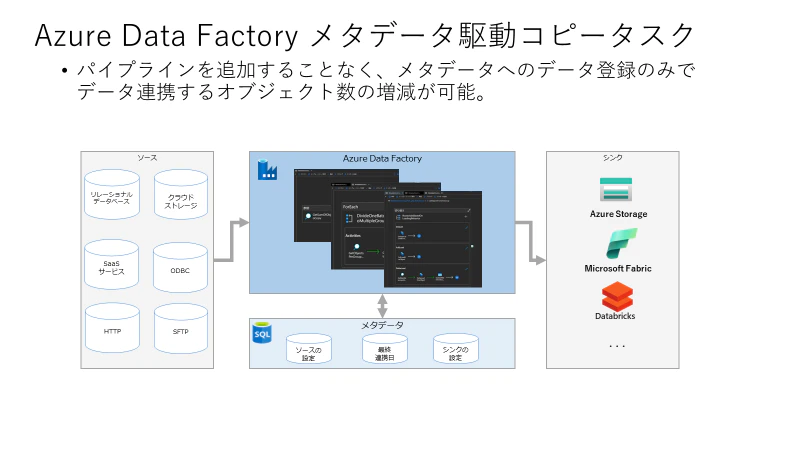
Azure Data Factory メタデータ駆動コピータスクとは
システムからクリックのみでデータ連携を行うパイプラインを作成できる機能です。同一のデータベースから数百のテーブルが連携する場合でも、同一のパイプラインで動作します。メタデータを保持する管理テーブルにおけるテーブル定義と INSERT 文、及び、3つのパイプラインが作成されます。Azure Data Factory の標準機能であるアクティビティを組み合わせて作られているため、改修することも容易に実施できます。

引用元:データのコピー ツールでメタデータ駆動型の方法を使用して大規模なデータ コピー パイプラインを作成する - Azure Data Factory | Microsoft Learn
作成される管理テーブルは下記の2つです。Main Control Table では、json 形式の文字列が保持されるため、json の文字列を外部で生成してテーブルに挿入することも可能です。
| # | テーブル | 概要 |
|---|---|---|
| 1 | Main Control Table | コピーするデータオブジェクトのリストや、それぞれのコピー動作に関する情報が格納されます |
| 2 | Connection Control Table | データストアの接続情報が格納されます。パラメータ化されたリンクドサービスを使用する場合、このテーブルに接続値が保存されます。 |
作成されるパイプラインは下記の3つであ。MetadataDrivenCopyTask_xxx_BottomLevel にて指定した並列数でコピーアクティビティが動作します。
| # | パイプライン名 | 概要 |
|---|---|---|
| 1 | MetadataDrivenCopyTask_xxx_TopLevel | このパイプラインは、コピーするオブジェクト(テーブルなど)の総数を計算し、最大同時コピータスク数に基づいてシーケンシャルバッチの数を決定します。その後、異なるバッチを順次コピーするために MiddleLevel のパイプラインを実行します。 |
| 2 | MetadataDrivenCopyTask_xxx_MiddleLevel | このパイプラインは、各バッチ内のオブジェクトを取得し、コピータスクを実行するための準備を行います。具体的には、各グループごとにコピーするオブジェクトを取得し、 BottomLevel のパイプラインに渡します。 |
| 3 | MetadataDrivenCopyTask_xxx_BottomLevel | このパイプラインは、実際のデータコピーを実行します。各オブジェクトのコピーを行い、必要に応じてウォーターマークの更新や差分コピーの処理を行います。 |
Azure Data Factory メタデータ駆動コピータスクのテクニック集
テクニック一覧
Azure Data Factory メタデータ駆動コピータスクを利用する際のテクニックとして下記表に示すテクニックがあります。
| # | 分類 | テクニック |
|---|---|---|
| 1 | 開発支援 | json ファイルの生成を Python 環境で生成 |
| 2 | パイプラインの改善 | 抽出期間を調整 |
| 3 | パイプラインの改善 | 再試行のロジックを追加 |
| 4 | パイプラインの改善 | SELECT 分による参照に変更 |
| 5 | パイプラインの改善 | 失敗したパイプラインのリトライ機構の追加 |
| 6 | パイプラインの改善 | 接続情報の切り替え |
| 7 | パイプラインの改善 | パイプラインの共通化 |
| 8 | パイプラインの改善 | watermarkColumnStartValue を単独の列として保持 |
| 9 | パイプラインの改善 | 差分連携時のファイル名を適切に設定 |
| 10 | レイクハウス対応 | データ挿入日をディレクトリに保持 |
| 11 | レイクハウス対応 | Databricks への取り込み処理を追加 |
開発支援
json ファイルの生成を Python 環境で生成
Azure Data Factory のメタデータ駆動のコピータスクにてメタデータを Python (Databricks)環境で生成する方法を下記記事にて紹介しています。
パイプラインの改善
抽出期間を調整
Azure Data Factory のメタデータ駆動のコピータスクにて差分読み込み(DeltaLoad)を透かし列(watermarkColumn、基準値列ともいう)を Datetime で実施する場合に抽出期間を長くする方法を下記記事で紹介しています。
再試行のロジックを追加
設定すべき個別のアクティビティの再試行の設定を行う手順を下記記事で紹介しています。
SELECT 分による参照に変更
Azure Data Factory のメタデータ駆動のコピータスクにて差分読み込み(DeltaLoad)時にCopySourceSettings列のsqlReaderQueryの値を利用する方法を下記記事で紹介しています。
失敗したパイプラインのリトライ機構の追加
Azure Data Factory のメタデータ駆動のコピータスクにて実行に失敗したコピーアクティビティのみ実行する方法を下記記事で紹介しています。
接続情報の切り替え
Azure Data Factory のメタデータ駆動のコピータスクにてデプロイメント環境(開発や本番などの環境)に応じて接続情報を切り替える方法を下記記事で紹介しています。
パイプラインの共通化
Azure Data Factory のメタデータ駆動のコピータスクにて利用するパイプラインをデータセットごとに共通化する方法を下記記事で紹介しています。
watermarkColumnStartValue を単独の列として保持
Azure Data Factory のメタデータ駆動のコピータスクにて、DataLoadingBehaviorSettings 列の json 内に保持されている watermarkColumnStartValue を watermarkColumnStartValue 列を単独の列として保持する方法を下記記事で紹介しています。メイン制御テーブルを Azure SQL Database 以外のデータベースで動作させたい場合などに UPDATE 文をシンプルにすることができます。
差分連携時のファイル名を適切に設定
Azure Data Factory のメタデータ駆動のコピータスクにて差分連携時のファイル名を適切に実施する方法を下記記事で紹介しています
レイクハウス対応
データ挿入日をディレクトリに保持
Azure Data Factory の メタデータ駆動のコピータスクにて Ingest Timestamp の Hive スタイルのパーティションの値(例:Ingest_timestamp=2024-06-05 02%3A46%3A50)を設定する方法を下記記事で紹介しています。
Databricks への取り込み処理を追加
Azure Data Factory メタデータ駆動のコピータスクにより ingest したファイルを Databricks で取り込む方法を下記記事で紹介しています。