概要
Azure Data Factory メタデータ駆動のコピータスクにより ingest したファイルを Databricks で取り込む方法を共有します。Azure Data Factory メタデータ駆動のコピータスクを組み合わせことで、大量のソースデータをレイクハウスアーキテクチャに高速、かつ、効率よく取り込むことができます。メタデータ駆動のコピータスクのメイン制御テーブルに Databricks の実行に必要となるパラメータを渡すことを想定しています。
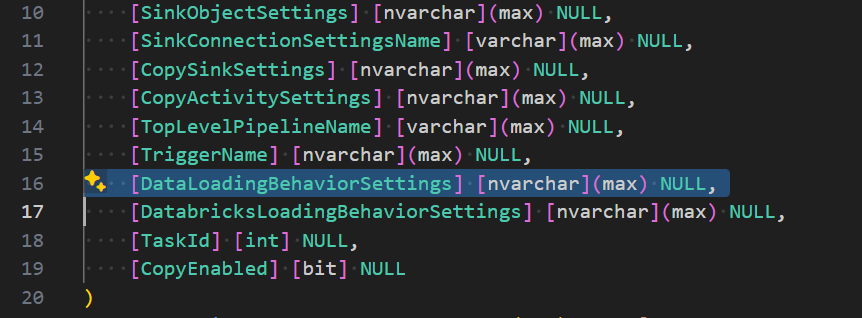
[DatabricksLoadingBehaviorSettings] [nvarchar](max) NULL,
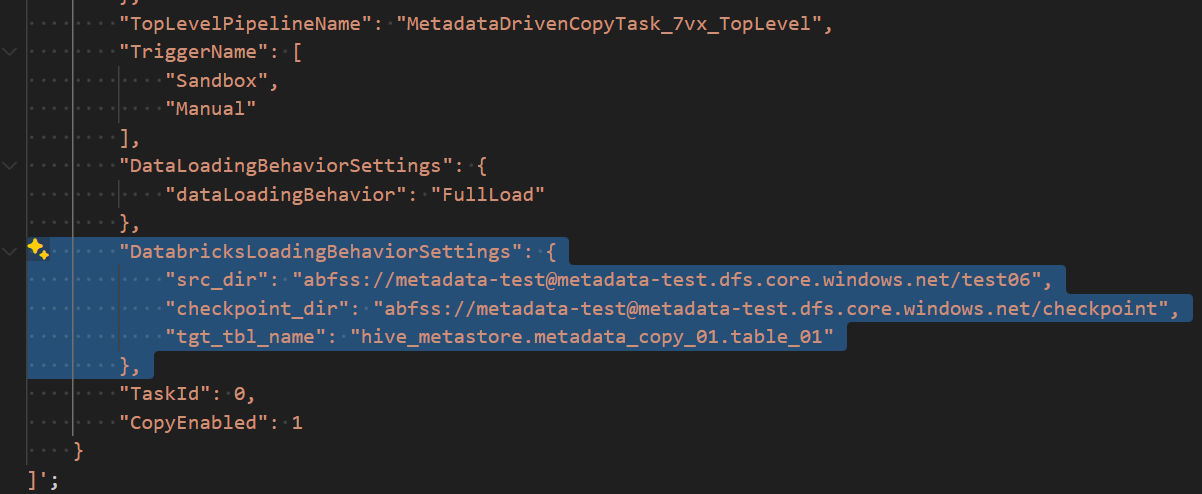
"DatabricksLoadingBehaviorSettings": {
"src_dir": "abfss://metadata-test@metadata-test.dfs.core.windows.net/test06",
"checkpoint_dir": "abfss://metadata-test@metadata-test.dfs.core.windows.net/checkpoint",
"tgt_tbl_name": "hive_metastore.metadata_copy_01.table_01"
},
本記事の実装方法は、投稿済みである下記記事の実装方法の応用です。
概要
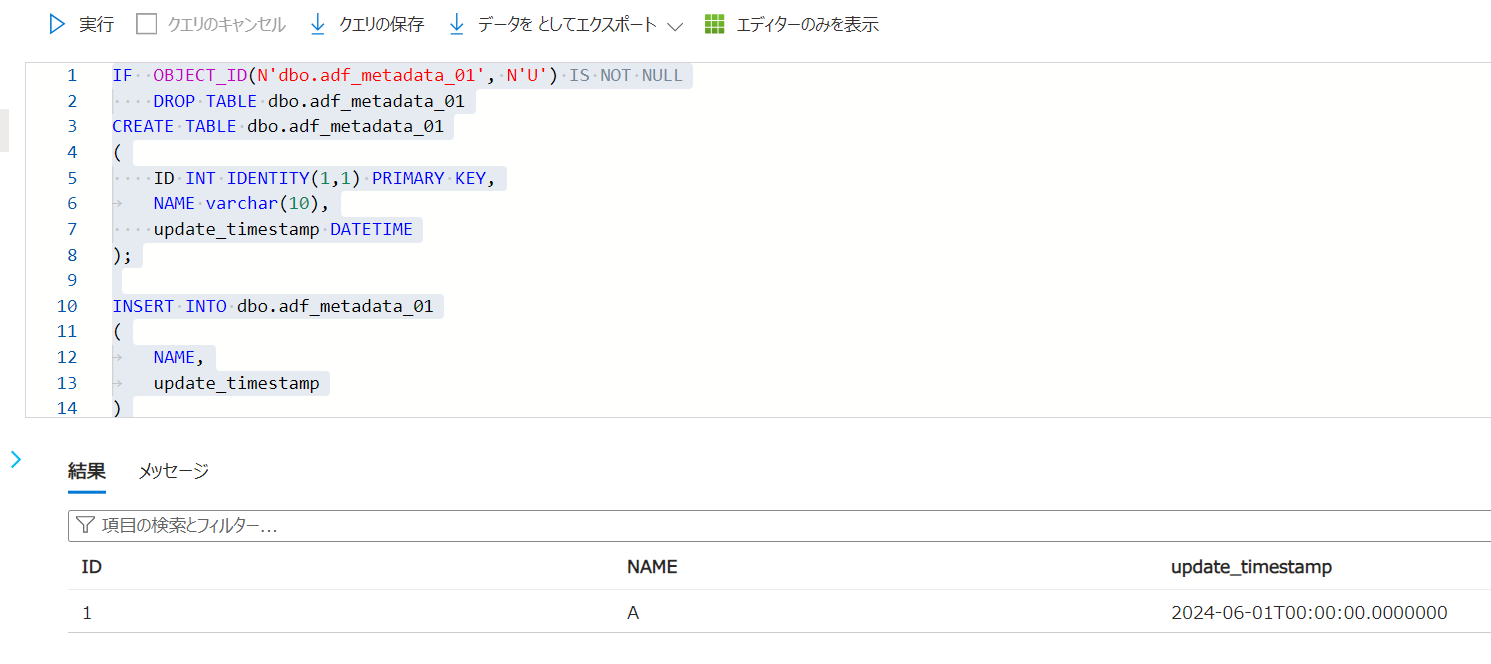
1. Azure SQL Database 上にソースとなるテーブルを作成とデータ挿入
IF OBJECT_ID(N'dbo.adf_metadata_01', N'U') IS NOT NULL
DROP TABLE dbo.adf_metadata_01
CREATE TABLE dbo.adf_metadata_01
(
ID INT IDENTITY(1,1) PRIMARY KEY,
NAME varchar(10),
update_timestamp DATETIME
);
INSERT INTO dbo.adf_metadata_01
(
NAME,
update_timestamp
)
SELECT 'A' AS NAME,CAST('2024-06-01' AS datetime2) AS update_timestamp
;
SELECT
*
FROM
dbo.adf_metadata_01
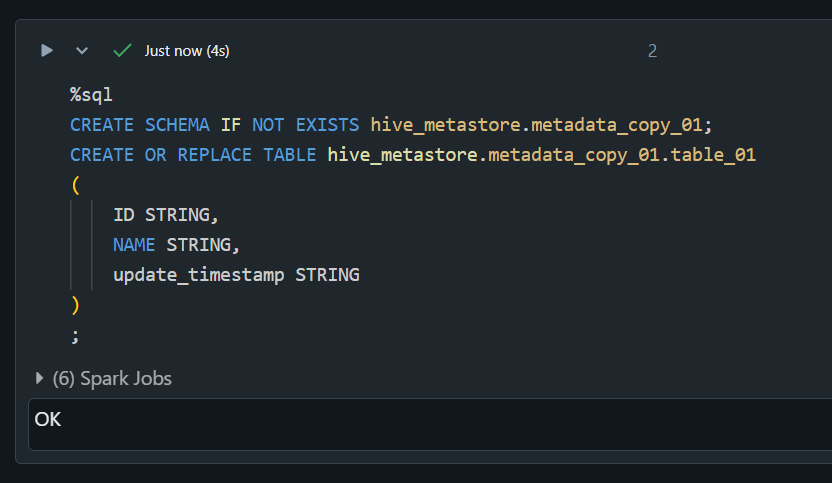
2. Databricks に書き込み先のスキーマとテーブルを作成
%sql
CREATE SCHEMA IF NOT EXISTS hive_metastore.metadata_copy_01;
CREATE OR REPLACE TABLE hive_metastore.metadata_copy_01.table_01
(
ID STRING,
NAME STRING,
update_timestamp STRING
)
;
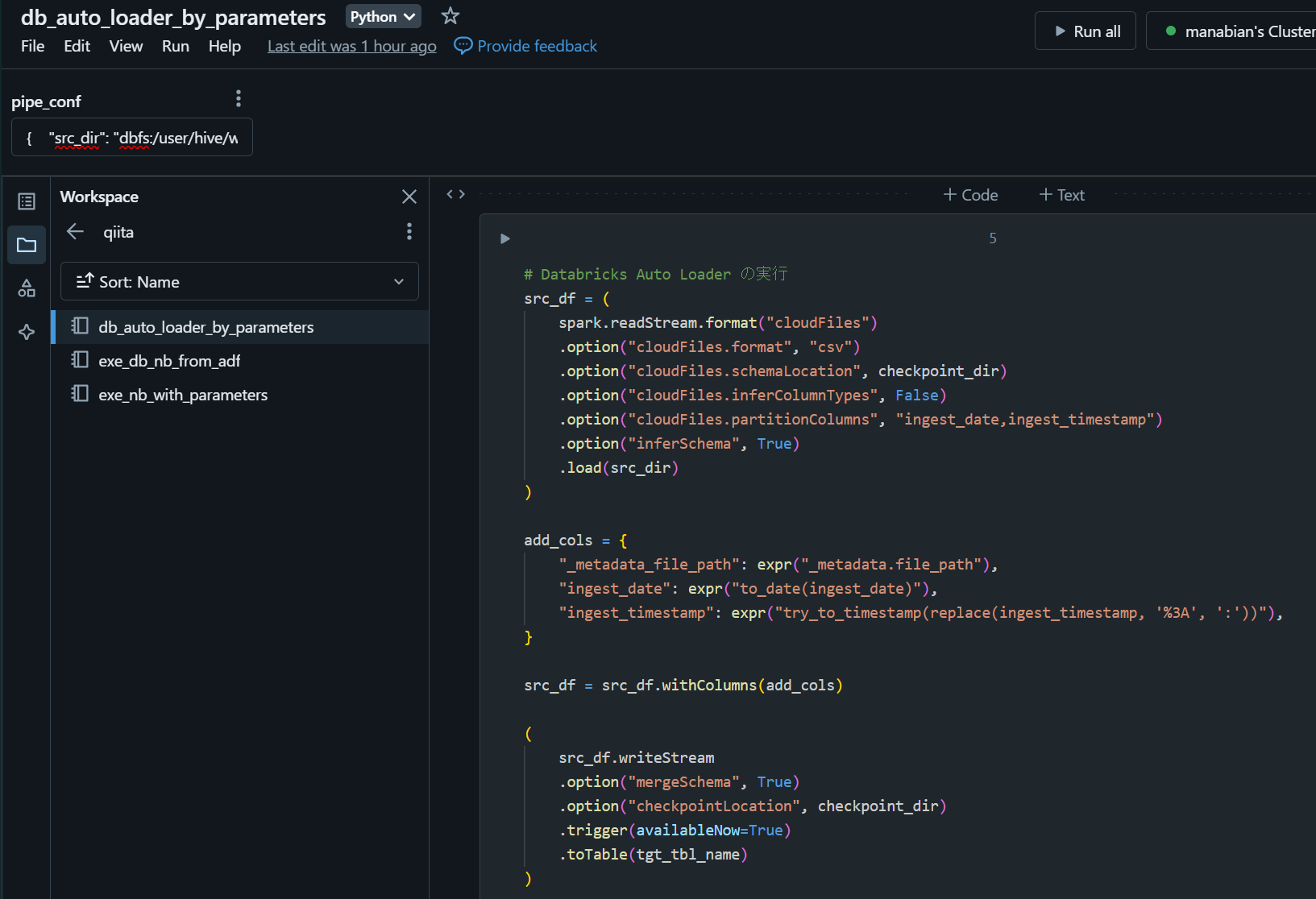
3. リンク先の記事を参考に Databricks Wokspace 上にノートブックを作成
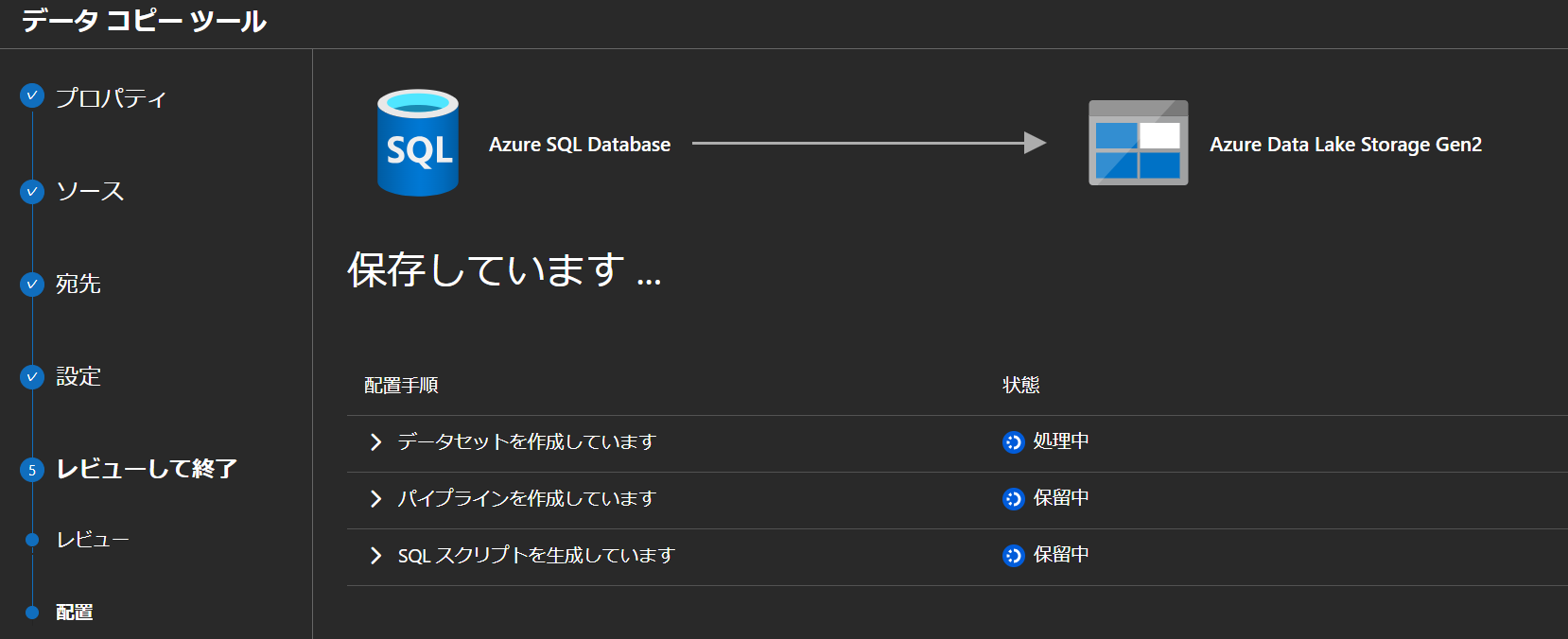
4. メタデータ駆動のコピータスクを作成
5. メイン制御テーブルの一部を修正後に実行
[DatabricksLoadingBehaviorSettings] [nvarchar](max) NULL,
"DatabricksLoadingBehaviorSettings": {
"src_dir": "abfss://metadata-test@metadata-test.dfs.core.windows.net/test06",
"checkpoint_dir": "abfss://metadata-test@metadata-test.dfs.core.windows.net/checkpoint",
"tgt_tbl_name": "hive_metastore.metadata_copy_01.table_01"
},
[DatabricksLoadingBehaviorSettings],
[DatabricksLoadingBehaviorSettings] [nvarchar](max) AS JSON,
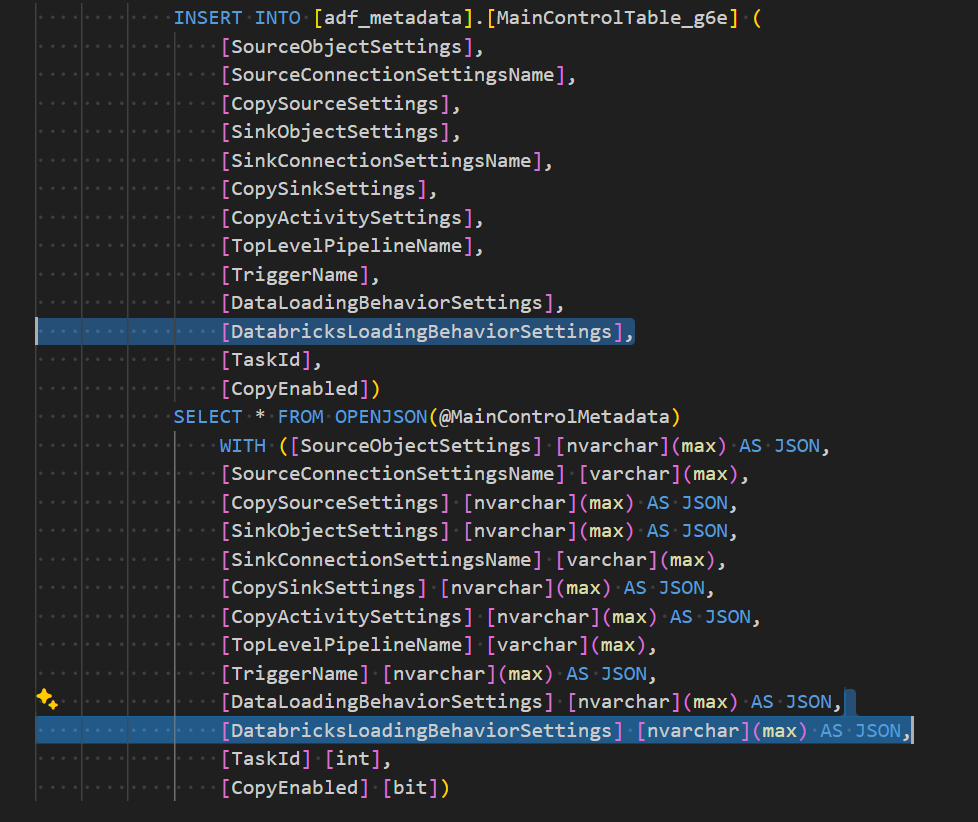
上記の修正後に Azure SQL Database でコードを実行します。
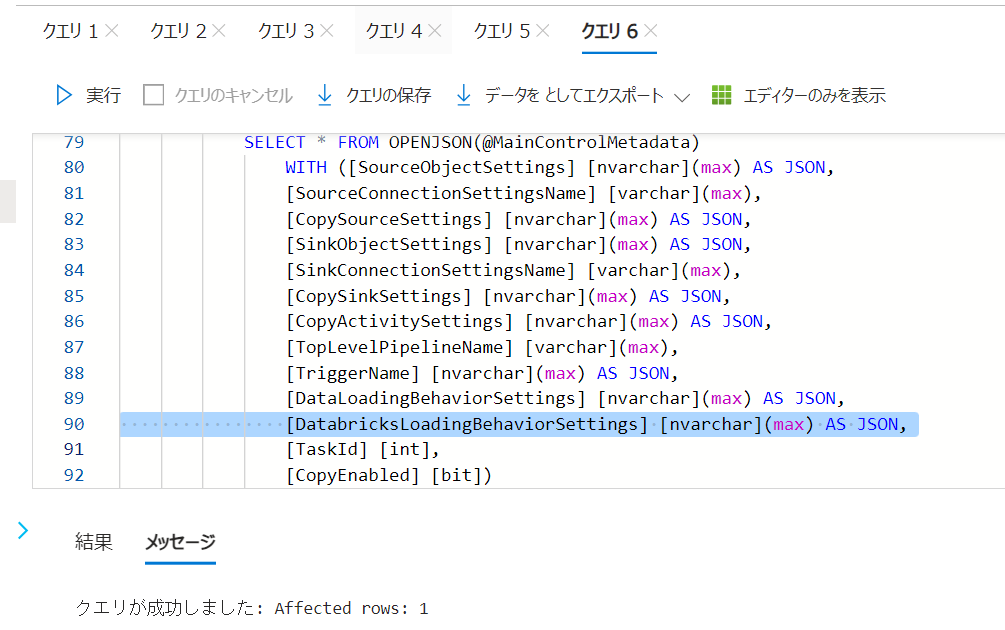
6. MetadataDrivenCopyTask_xxx_BottomLevelパイプラインにて作成したノートブックにベースパラメータとしてpipe_confという名前で@item().DatabricksLoadingBehaviorSettingsを渡す Databricks ノートブックアクティビティを追加
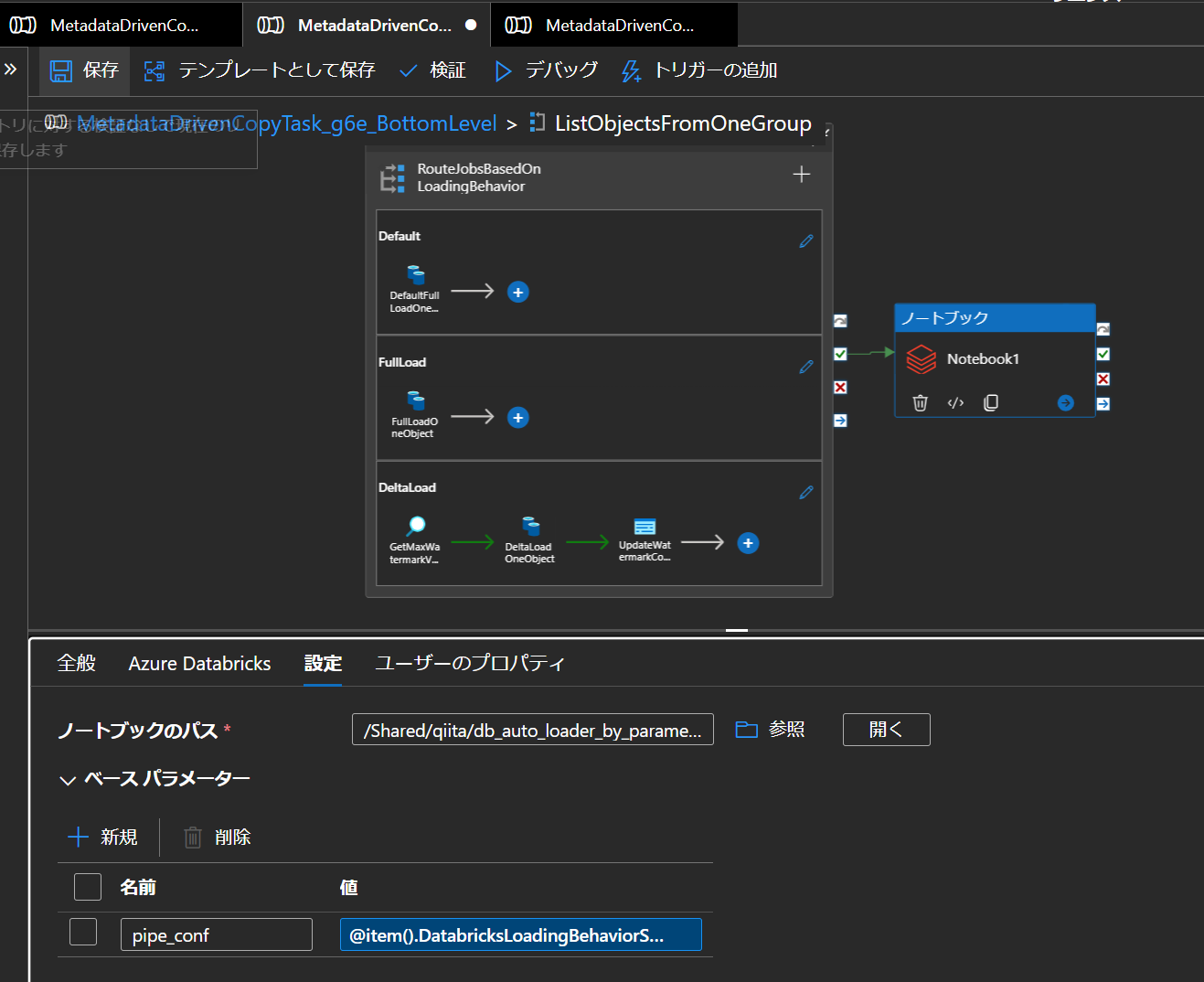
7. Azure Data Factory にてメタデータ駆動のコピータスクをデバック実行し正常終了することを確認
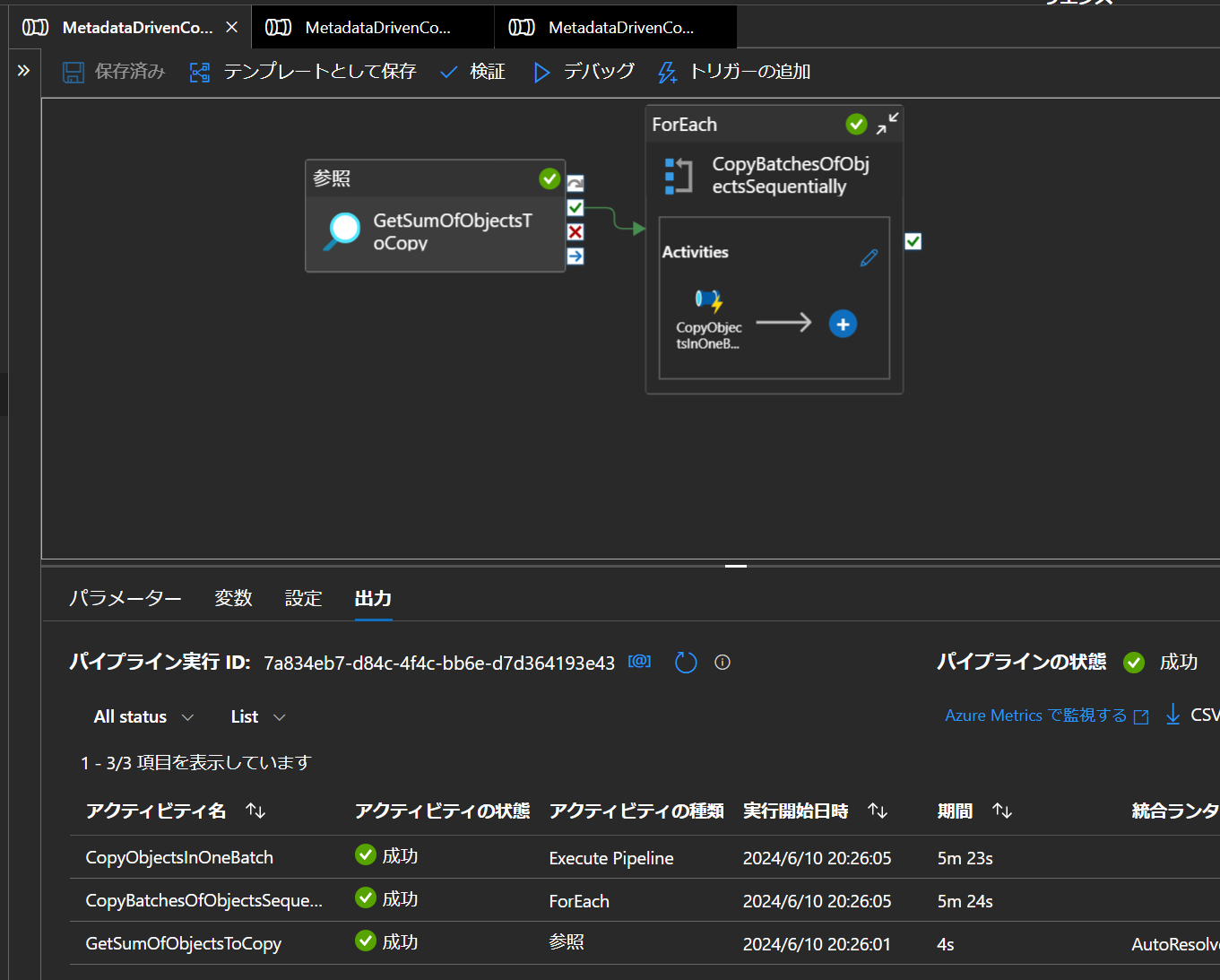
8. Databricks のテーブルにデータが書きこまれていることを確認
spark.table("hive_metastore.metadata_copy_01.table_01").display()
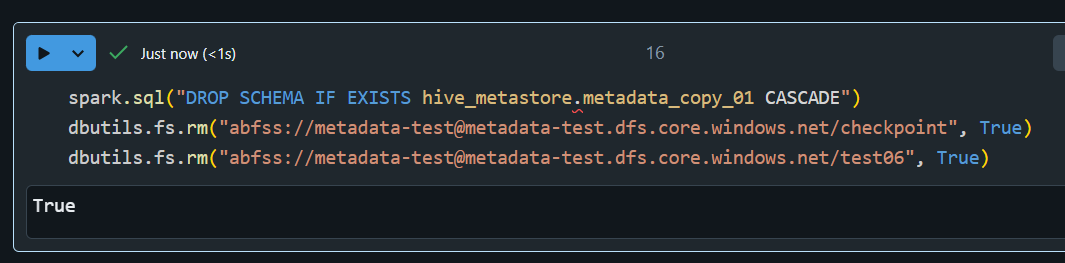
9. 作成したリソースを削除
spark.sql("DROP SCHEMA IF EXISTS hive_metastore.metadata_copy_01 CASCADE")
dbutils.fs.rm("abfss://metadata-test@metadata-test.dfs.core.windows.net/checkpoint", True)
dbutils.fs.rm("abfss://metadata-test@metadata-test.dfs.core.windows.net/test06", True)