概要
Databricks(Spark)のPythonにてNot Null制約が設定されているカラム情報を取得する方法を共有します。
dataframe.schema.jsonValue()により取得するスキーマ情報を整形します。
詳細は下記のGithub pagesのページをご確認ください。
コードを実行したい方は、下記のdbcファイルを取り込んでください。
https://github.com/manabian-/databricks_tecks_for_qiita/blob/main/tecks/get_not_null_columns_info/dbc/get_not_null_columns_info.dbc
環境
databricks runtime: 8.3.x-cpu-ml-scala2.12
Python version: 3.8.8
pyspark version: 3.1.2.dev0
手順
事前準備
サンプルのデータフレームを作成します。
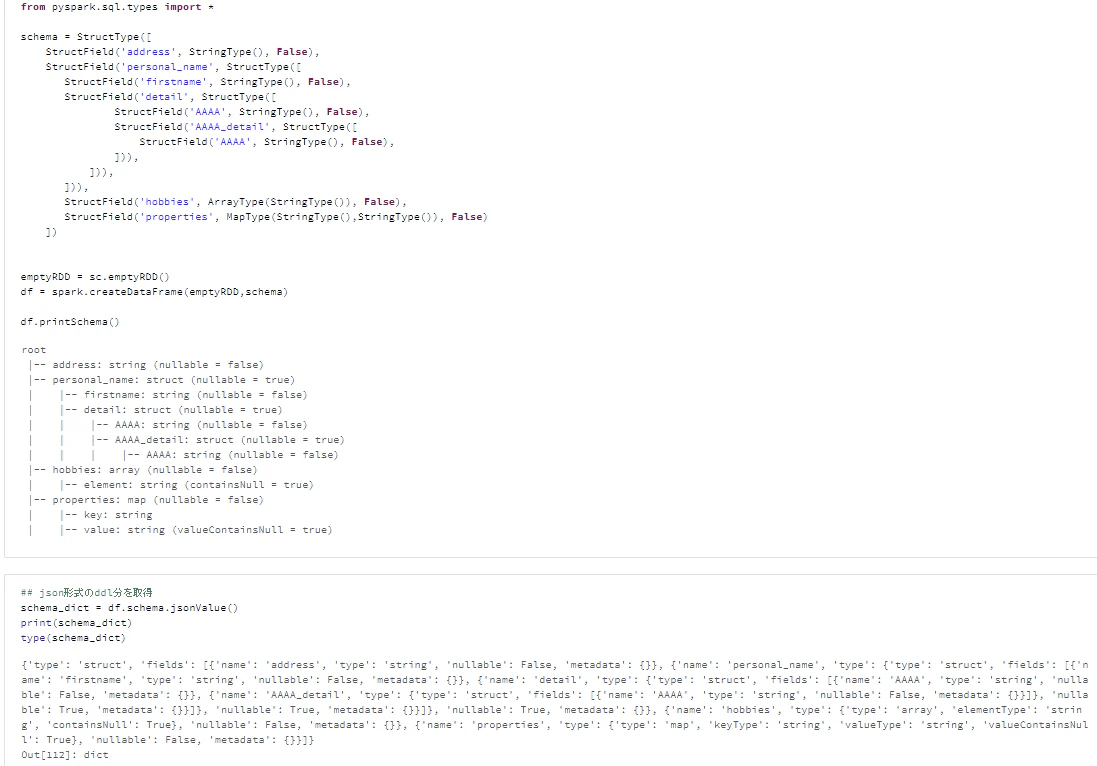
from pyspark.sql.types import *
schema = StructType([
StructField('address', StringType(), False),
StructField('personal_name', StructType([
StructField('firstname', StringType(), False),
StructField('detail', StructType([
StructField('AAAA', StringType(), False),
StructField('AAAA_detail', StructType([
StructField('AAAA', StringType(), False),
])),
])),
])),
StructField('hobbies', ArrayType(StringType()), False),
StructField('properties', MapType(StringType(),StringType()), False)
])
emptyRDD = sc.emptyRDD()
df = spark.createDataFrame(emptyRDD,schema)
関数を定義
def get_defination(schema, prefix=''):
fields = schema['fields']
list_definations=[]
prefix = prefix+'.' if prefix !='' else ''
for field in fields:
if type(field['type']) is dict:
if field['type']['type'] == 'struct':
list_definations.extend(get_defination(field['type'], prefix+field['name']))
else:
field["name"]=prefix + field["name"]
list_definations.append(field)
else:
field["name"]=prefix + field["name"]
list_definations.append(field)
return list_definations
def get_not_null_columns_info(schema_dict):
allcols = get_defination(schema_dict)
return list(filter(lambda col: col["nullable"]==False, allcols))
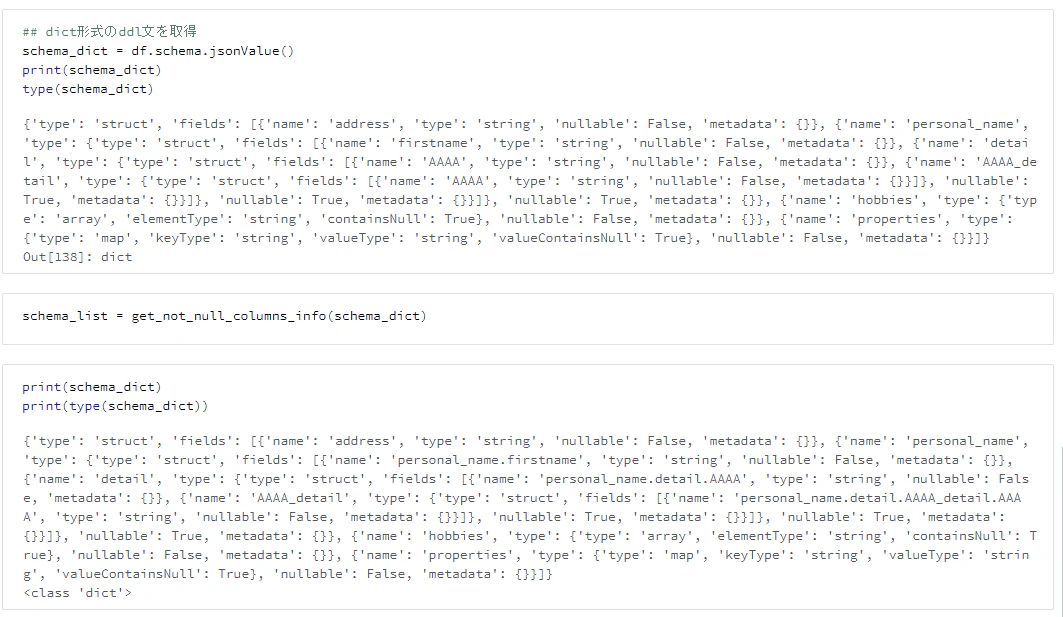
階層をフラットにしたDDLの辞書型変数を取得
## dict形式のddl文を取得
schema_dict = df.schema.jsonValue()
print(schema_dict)
type(schema_dict)
schema_list = get_not_null_columns_info(schema_dict)
階層をフラットにしたカラムのリスト型変数を取得
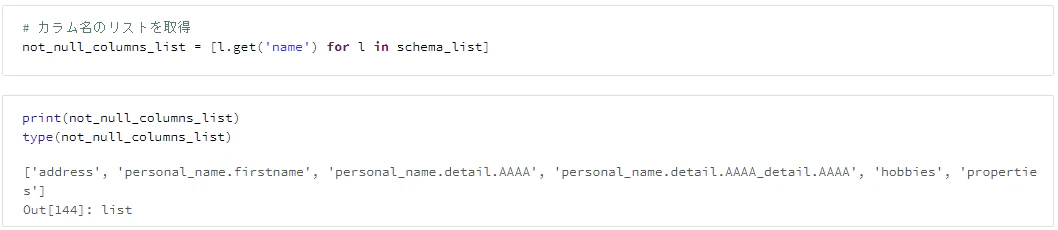
# カラム名のリストを取得
not_null_columns_list = [l.get('name') for l in schema_list]