概要
本記事では、 BigQuery サンドボックス環境から、 Apache Spark SQL Connector for Google BigQuery (以下「 Spark コネクター for BQ 」)を用いて Google Colab 上でデータを取得する方法を紹介します。 Spark コネクター for BQ は、 BigQuery Storage API を介してデータにアクセスするため、データフレーム操作などを行う際、低コストかつ高パフォーマンスな利用が可能な場合があります。
Google Colab 上での Spark 操作については下記の記事でまとめており、合わせてご確認ください。
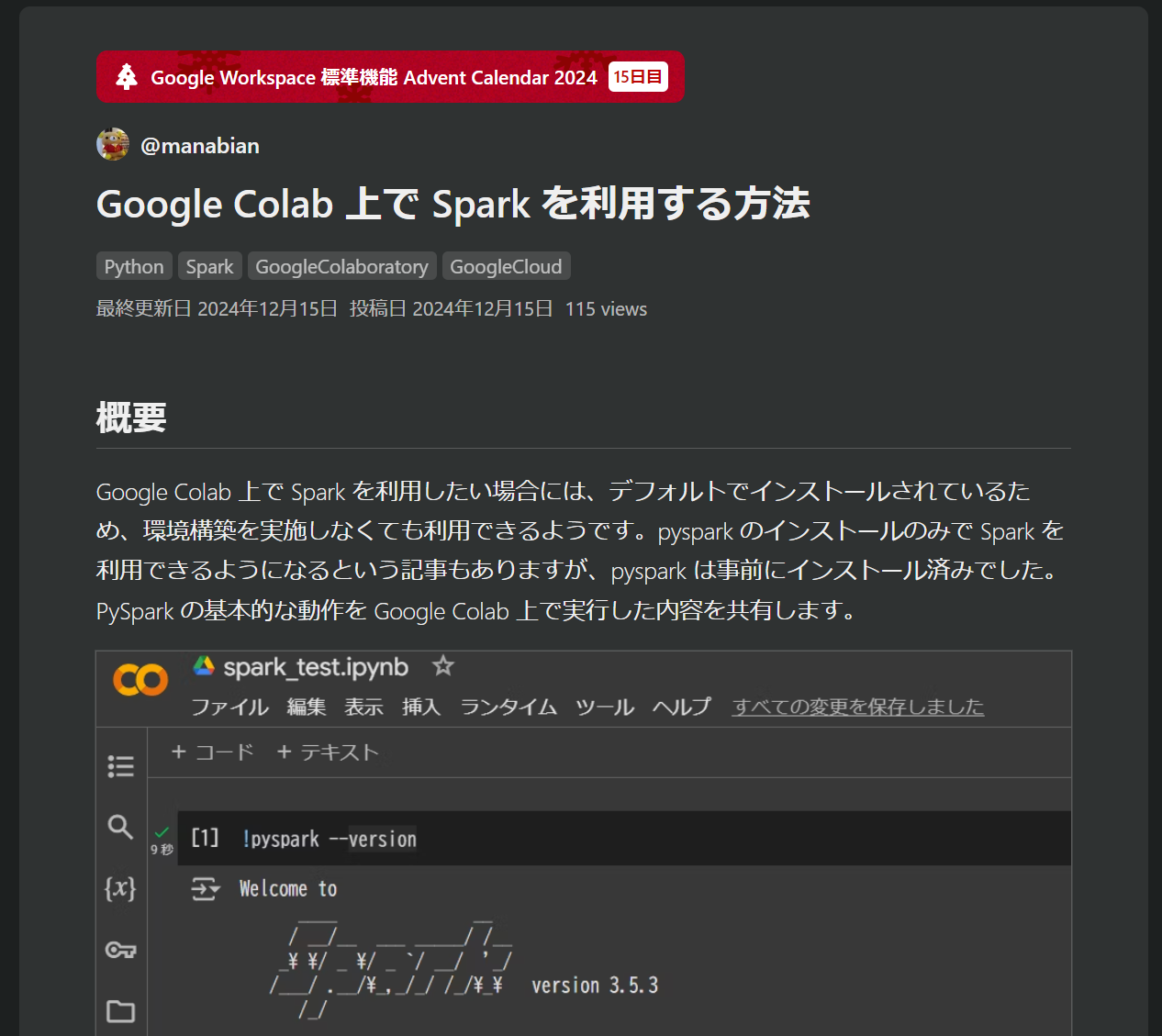
引用元:Google Colab 上で Spark を利用する方法 #Python - Qiita
Spark コネクター for BQ について
Spark コネクター for BQ は、 BigQuery と連携する際に BigQuery Storage API を用いるため、この API への理解が重要です。

The connector supports reading Google BigQuery tables into Spark's DataFrames, and writing DataFrames back into BigQuery. This is done by using the Spark SQL Data Source API to communicate with BigQuery.
引用元:spark-bigquery-connector/README.md at master · GoogleCloudDataproc/spark-bigquery-connector
コネクタは、Google BigQueryのテーブルをSparkのDataFrameに読み込むこと、およびDataFrameをBigQueryに書き戻すことをサポートしています。これは、Spark SQL Data Source APIを使用してBigQueryと通信することで実現されます。
上記の翻訳
BigQuery Storage Read API は、低コストで利用できる場合があります。たとえば、 BigQuery オンデマンドの料金が 1TB あたり 7.5 ドルであるのに対し、 BigQuery Storage Read API は 1TB あたり 1.32 ドルで、約 5 分の 1 以下のコストです。さらに、月間 300TB までは追加コストなしで利用できます。
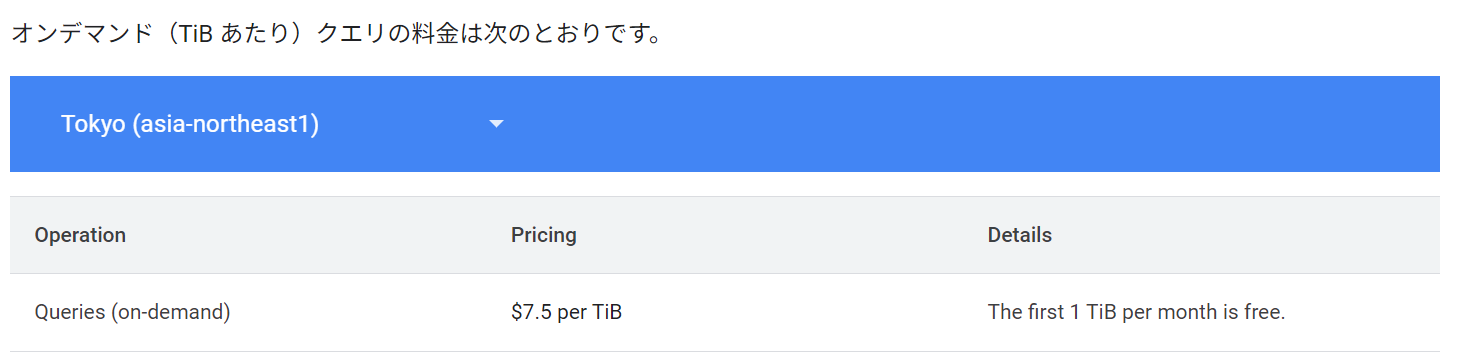
引用元:料金 | BigQuery: Cloud Data Warehouse | Google Cloud
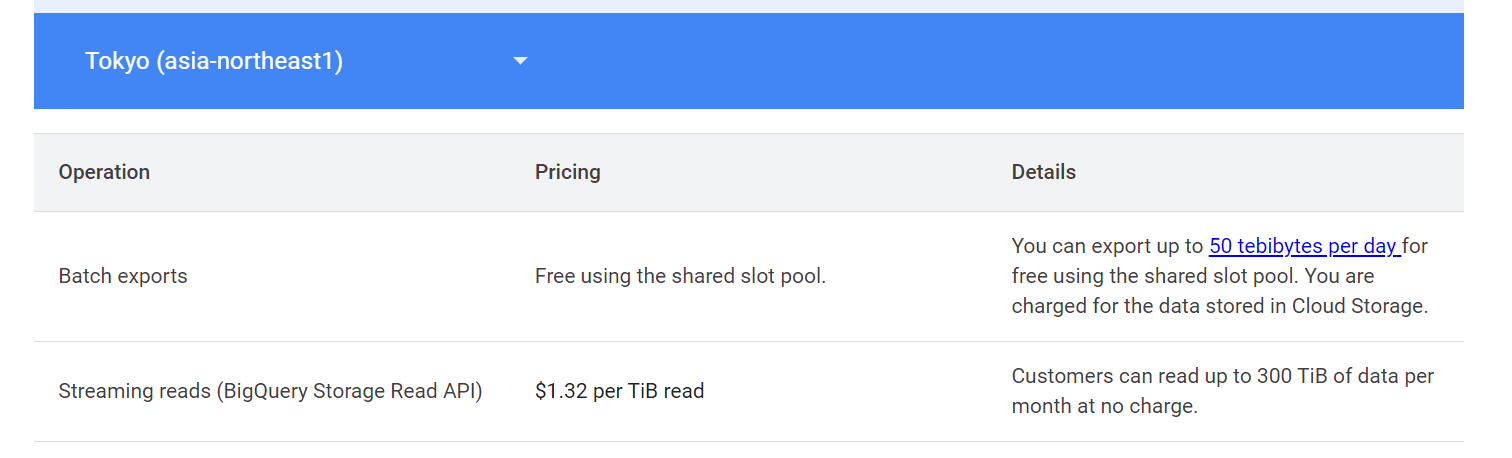
Customers can read up to 300 TiB of data per month at no charge.
引用元:料金 | BigQuery: Cloud Data Warehouse | Google Cloud
Spark コネクター for BQ を用いたデータ連携では、並列処理やフィルタプッシュダウンが行われるため、 JDBC 経由でのデータ取得と比較して高いパフォーマンスが期待できます。

The Storage API streams data in parallel directly from BigQuery via gRPC without using Google Cloud Storage as an intermediary.
引用元:spark-bigquery-connector/README.md at master · GoogleCloudDataproc/spark-bigquery-connector
Storage APIは、Google Cloud Storageを中間ストレージとして使用せず、gRPCを介してBigQueryからデータを直接並列でストリーミングします。
上記の翻訳

The Storage API supports arbitrary pushdown of predicate filters. Connector version 0.8.0-beta and above support pushdown of arbitrary filters to Bigquery.
引用元:spark-bigquery-connector/README.md at master · GoogleCloudDataproc/spark-bigquery-connector
Storage APIは、任意の述語フィルタのプッシュダウンをサポートしています。コネクタのバージョン0.8.0-beta以降では、任意のフィルタのプッシュダウンがBigQueryに対してサポートされています。
上記の翻訳
以上の理由から、 BigQuery データに基づいてデータフレーム操作を行う場合は、 Spark コネクター for BQ の利用が推奨されます。
検証コードと実行結果
BigQuery の事前設定
1. IAM と管理 -> サービス アカウントタブにて、+ サービス アカウントを作成を千九田ふぁ
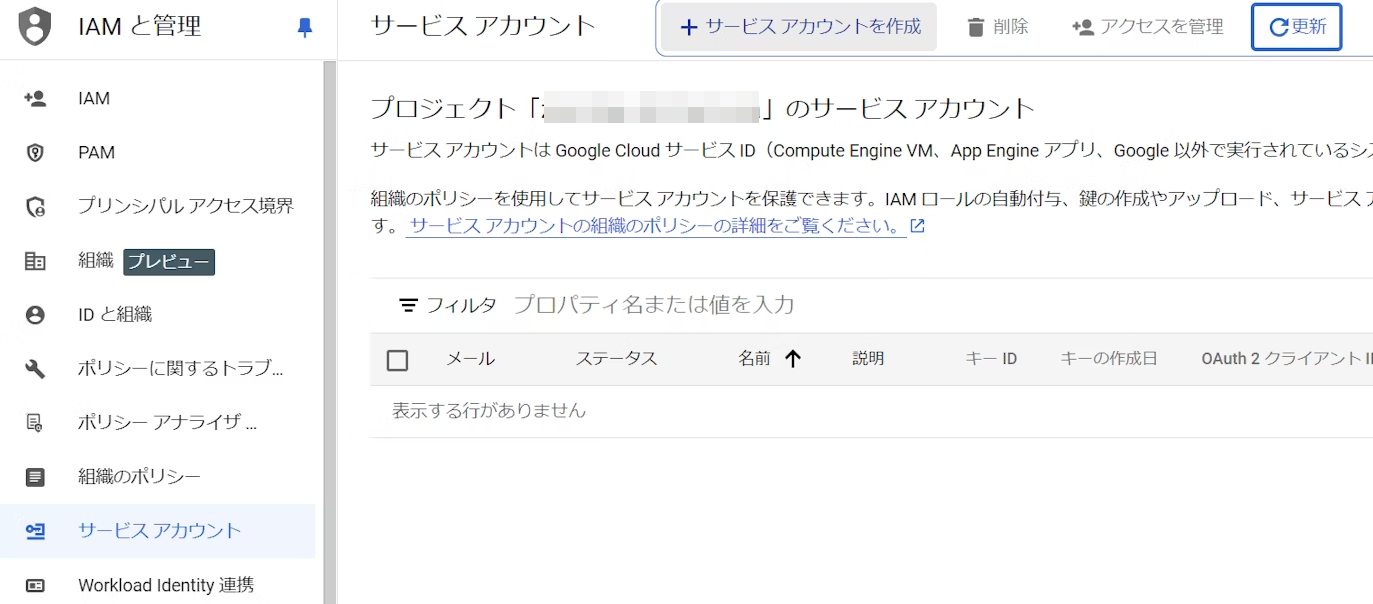
2. 任意の名称と ID を入力して作成して続行を選択
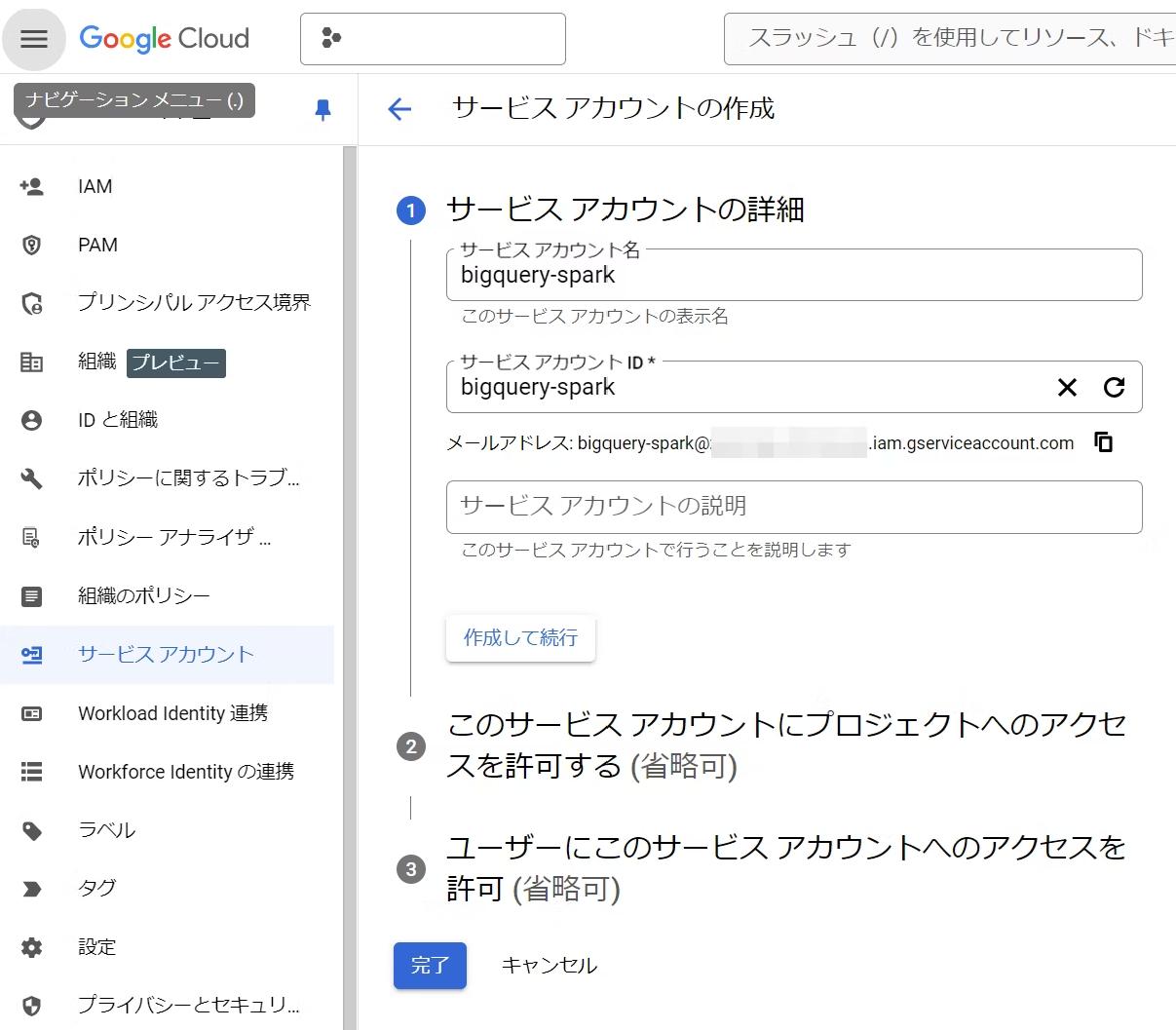
3. BigQuery user(BigQuery ユーザー)とBigQuery Data Editor(BigQuery データ編集者)のロールをついかして完了を選択
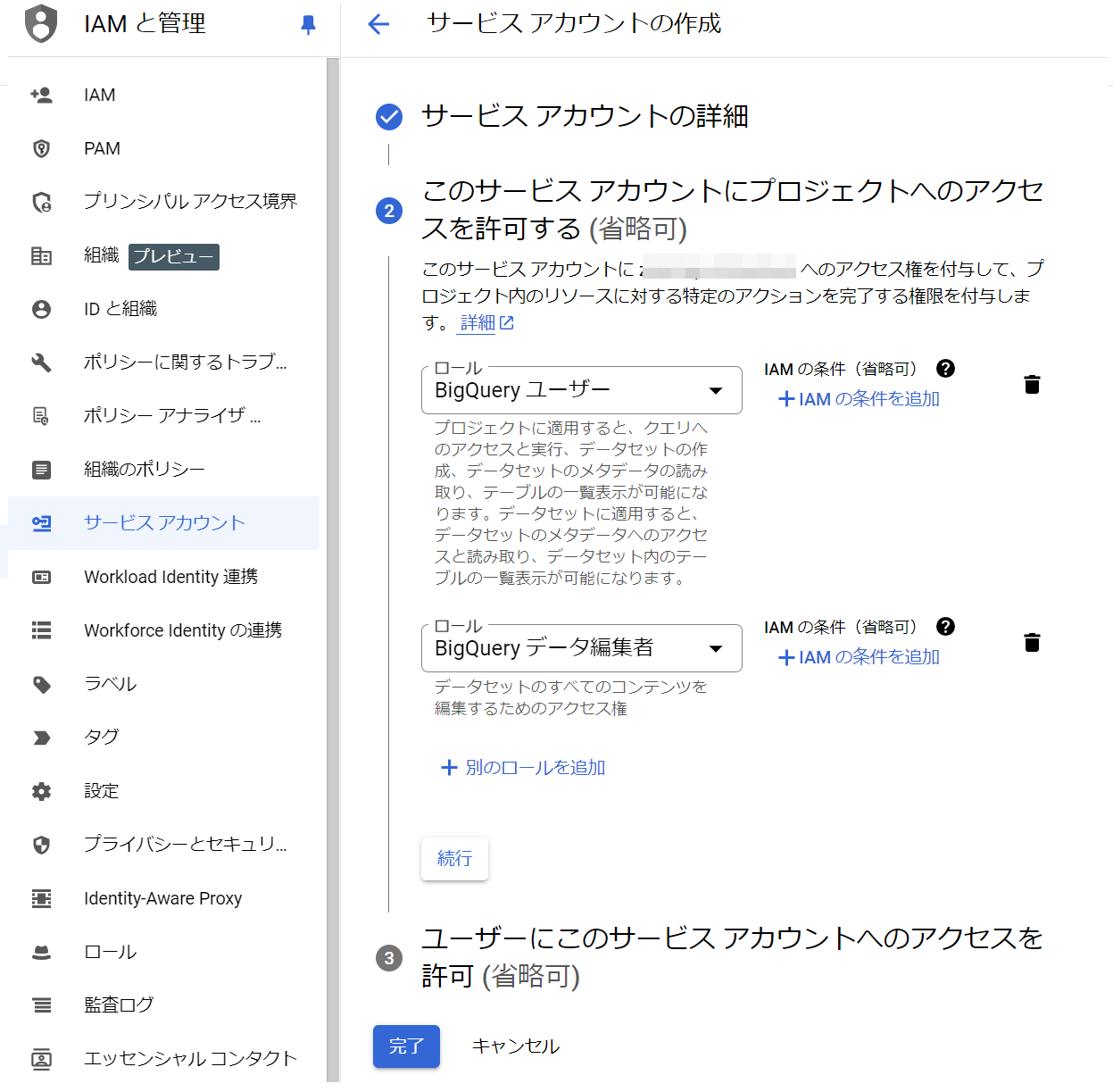
4. 作成したサービスアカウント -> キーを追記にある新しい鍵を作成を選択
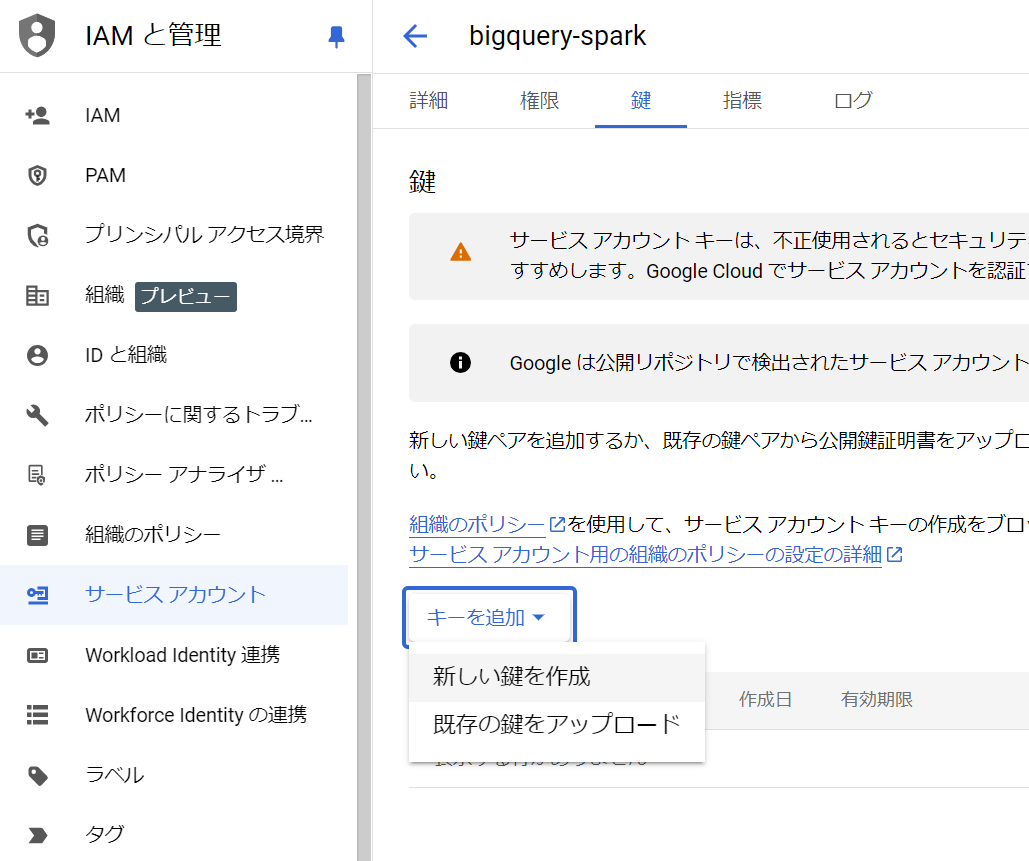
5. JSONを選択して作成を選択

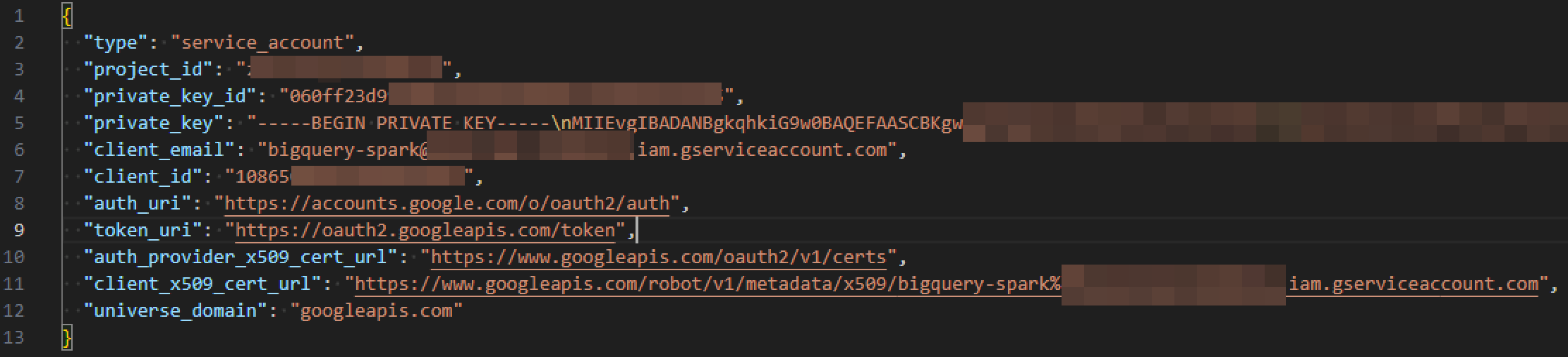
6. JSON ファイルがダウンロードされたことを確認
Google Colab での実行例
1. Google Colab のノートブックを作成
2. Google Cloud からダウンロードした認証情報の JSON ファイル(本手順ではbq-keys.jsonという名称にリネーム)をセッションストレージにアップロード

下記のコードを実行してファイルをアップロードできたことを確認できます。
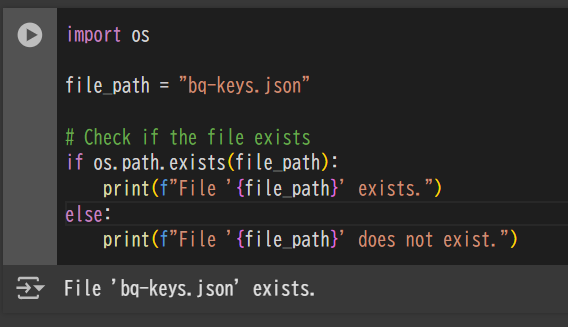
import os
file_path = "bq-keys.json"
# Check if the file exists
if os.path.exists(file_path):
print(f"File '{file_path}' exists.")
else:
print(f"File '{file_path}' does not exist.")
3. Apache Spark SQL connector for Google BigQuery をダウンロード
!wget https://repo1.maven.org/maven2/com/google/cloud/spark/spark-3.5-bigquery/0.41.0/spark-3.5-bigquery-0.41.0.jar
利用する jar ファイルのバージョンは Spark のバージョンに合わせて変更が必要です。
引用元:spark-bigquery-connector/README.md at master · GoogleCloudDataproc/spark-bigquery-connector
4. Google Cloud の Project ID を貼り付けて実行
# プロジェクト ID を設定
parent_project_id = "{project_id}"

Project ID は Google Cloud のコンソールにてプロジェクトを切り替えるウィンドウにて確認できます。

5. SparkSession の定義
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName('Top Shakepeare words')
.config('spark.jars', 'spark-3.5-bigquery-0.41.0.jar') \
.getOrCreate()
)
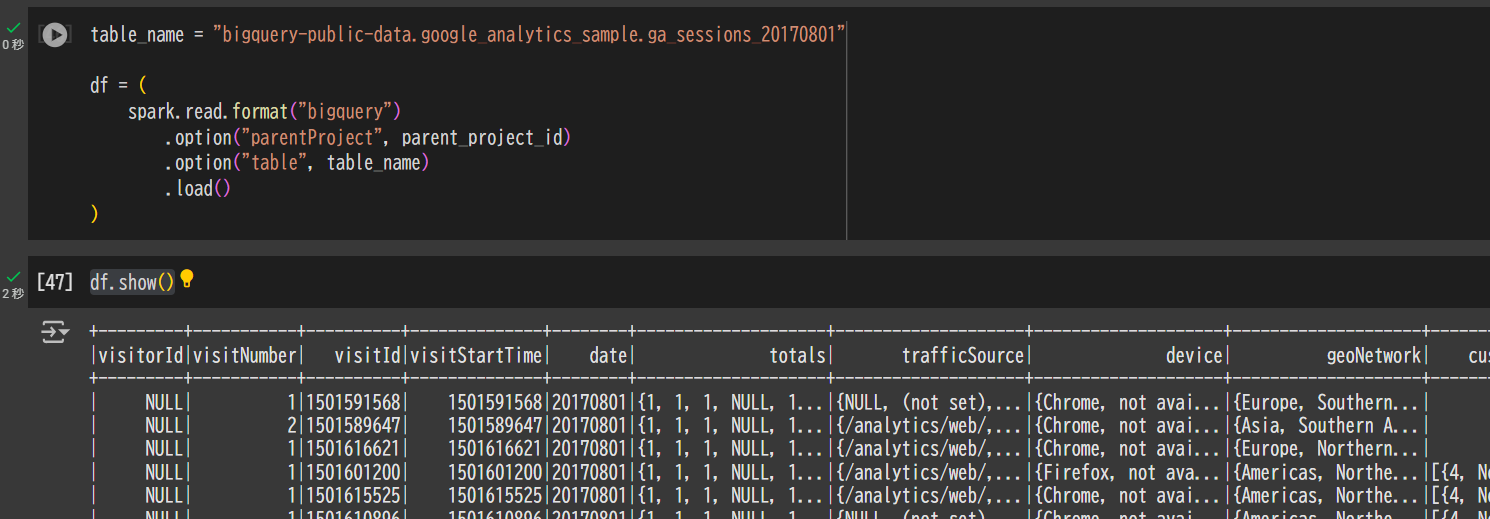
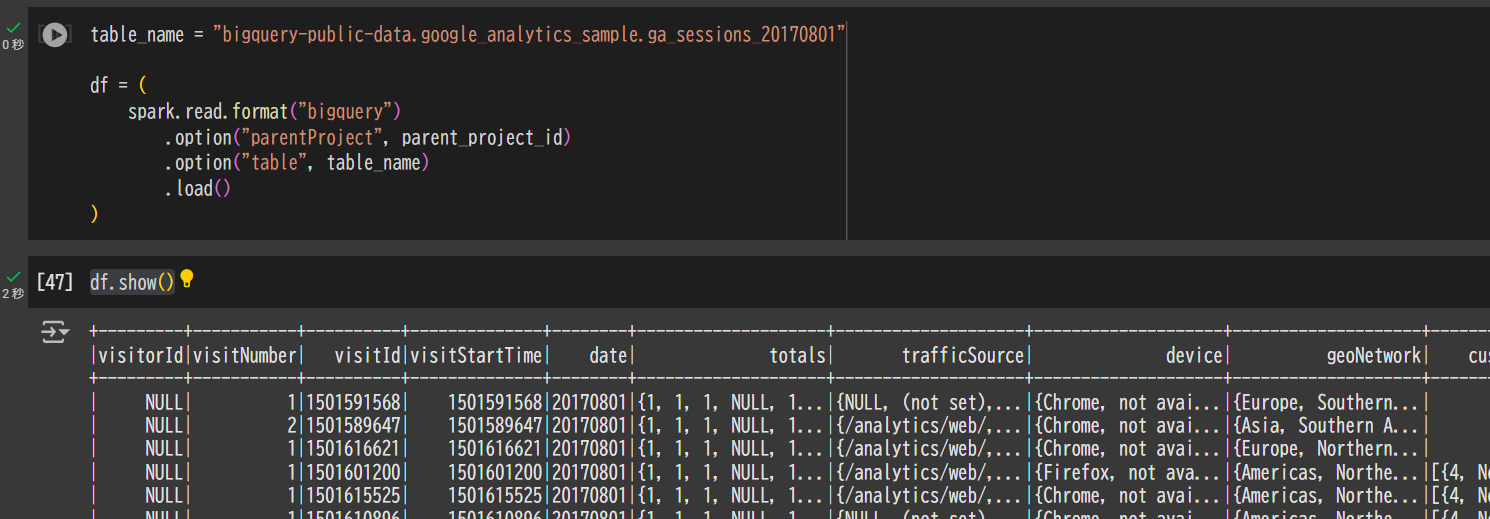
6. BigQuery からデータを取得するコードを実行
table_name = "bigquery-public-data.google_analytics_sample.ga_sessions_20170801"
df = (
spark.read.format("bigquery")
.option("parentProject", parent_project_id)
.option("table", table_name)
.load()
)
df.show()
まとめ
本記事では、Apache Spark SQL Connector for Google BigQuery(Spark コネクター for BQ) を利用し、Google Colab 上で BigQuery のデータを取得する手順を紹介しました。検証の結果、以下のポイントが明らかになりました。
-
Spark コネクター for BQ の利点
- BigQuery Storage API を利用することで、JDBC 経由よりも高パフォーマンスなデータ取得が可能です。
- 並列処理やフィルタのプッシュダウンにより、データ処理が効率的に行われます。
- コスト効率にも優れ、BigQuery オンデマンドと比較して低コストでの利用が期待できます。
-
Google Colab での実装
- Google Colab 上で Spark コネクター for BQ を利用する手順が確立され、BigQuery のデータを低コストかつ容易に取得できました。
- 認証情報の JSON ファイルをアップロードし、Spark セッションを定義することでデータフレーム操作が可能となります。
以上により、 BigQuery データを Spark で効率的に処理する具体的手法が示されました。 Spark コネクター for BQ は、大規模データ分析やデータフレーム操作において有用なツールであり、データエンジニアリングや分析業務における価値が再確認されました。