概要
Databricks を使用して Azure SQL Database の CHAR 型のカラムに対する読み書き操作を行う際のスペースの取り扱いについての調査結果を共有します。
具体的には、以下の4つのシナリオについて検証しています。各シナリオでは、テーブルの作成、データの挿入、データの参照、文字数の算出、データの書き込みなどを行っています。また、各シナリオの結果はPythonとSQLのコードを後述しています。
- ANSI_PADDING ON 設定での Azure SQL Database テーブの参照検証
- ANSI_PADDING OFF 設定での Azure SQL Database テーブルの参照検証
- ANSI_PADDING ON 設定での Azure SQL Database テーブルへの書き込み検証
- ANSI_PADDING OFF 設定での Azure SQL Database テーブルへの書き込み検証
検証結果としては、ANSI_PADDING が ON の場合に CHAR 型のカラムのデータを取得した際には、指定したバイトに満たない場合にはスペースが埋められて取得されることが確認されました。一方で、ANSI_PADDING が OFF の場合には、指定したバイトに満たない場合にはスペースが埋められずに取得されることが確認されました。Azure SQL Database にて Shift JIS (正確には CP932)で文字を保持する設定にしているため、あいうは 6 バイトと判断されて、スペースが 3 つ設定されています。
[
Row(char_col="abc ", 文字数=10),
Row(char_col="あいう ", 文字数=7),
Row(char_col=" ", 文字数=10),
Row(char_col=None, 文字数=None),
]
ANSI_PADDING のデフォルト設定値は ON であるため、本記事にて ANSI_PADDING ON 設定で検証を行う際には SET ステートメントにて明示していません。

引用元:SET ANSI_PADDING (Transact-SQL) - SQL Server | Microsoft Learn
Databricks から書きこみを実施する際には、テーブルが再作成されないように、truncateオプションを設定することが必要です。

引用元:JDBC To Other Databases - Spark 3.5.0 Documentation (apache.org)
検証コードと実行結果
事前準備
Databricks にて以下のコードを実行。
from pyspark.sql.functions import expr
server = "ads-01" ## サーバー名
database = "ads-01" ## データベース名
username = "user" ## Azure SQL DB のユーザー名
password = "password" ## Azure SQL DB のパスワード
1. Azure SQL Database テーブル(ANSI_PADDING ON)の参照検証
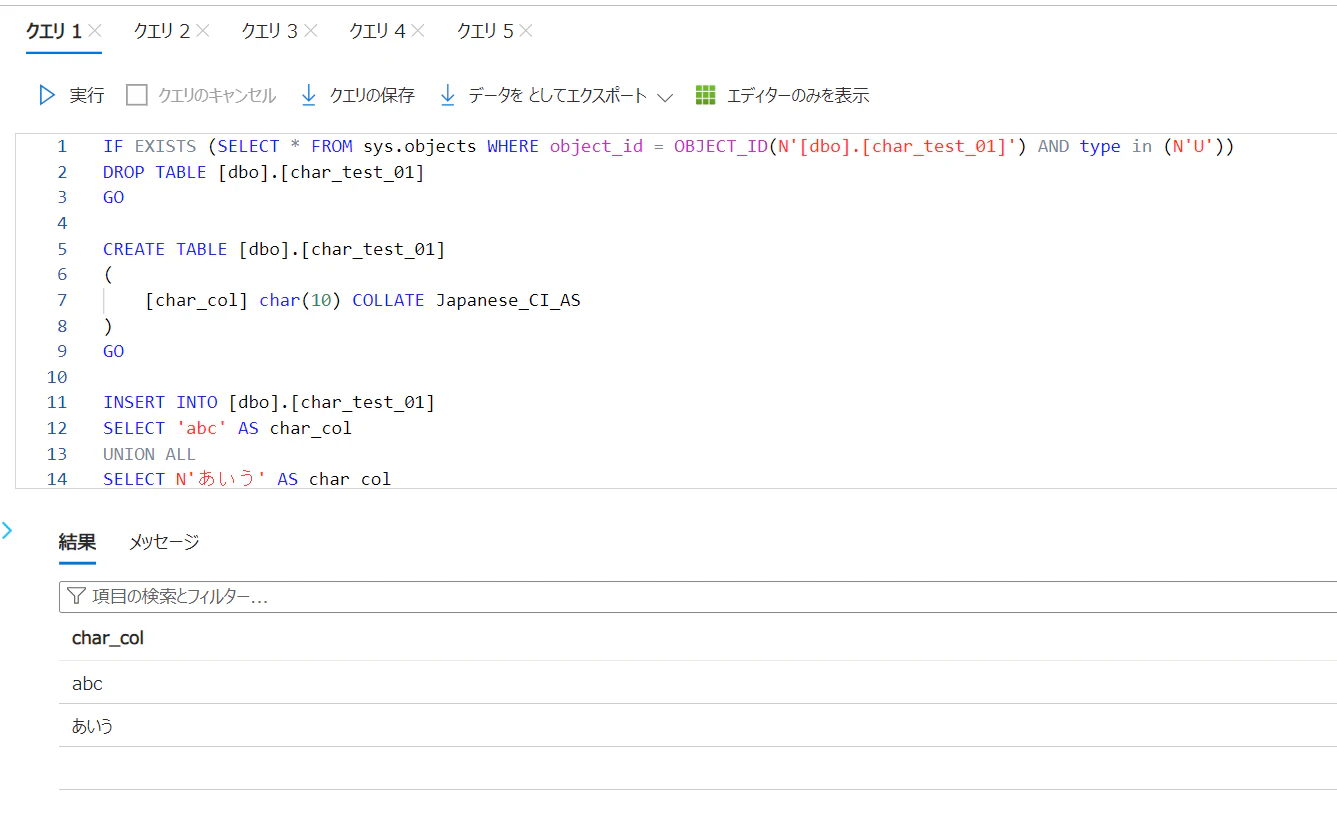
Azure SQL Database にて以下のコードを実行して、テーブルの作成とデータの挿入を実施
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[char_test_01]') AND type in (N'U'))
DROP TABLE [dbo].[char_test_01]
GO
CREATE TABLE [dbo].[char_test_01]
(
[char_col] char(10) COLLATE Japanese_CI_AS
)
GO
INSERT INTO [dbo].[char_test_01]
SELECT 'abc' AS char_col
UNION ALL
SELECT N'あいう' AS char_col
UNION ALL
SELECT '' AS char_col
UNION ALL
SELECT NULL AS char_col
GO
SELECT
*
FROM
[dbo].[char_test_01]
GO
Databricks にて以下のコードを実行して、Azure SQL Database のテーブルを参照したデータフレームを作成し、文字数を算出して表示。
tgt_tbl_name = "[dbo].[char_test_01]"
sql_db_table_01 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("dbTable", tgt_tbl_name)
.load()
)
sql_db_table_01.createOrReplaceTempView("tmp_view")
sql_db_table_01 = sql_db_table_01.withColumn("文字数", expr("len(char_col)"))
print(sql_db_table_01.collect())
sql_db_table_01.display()
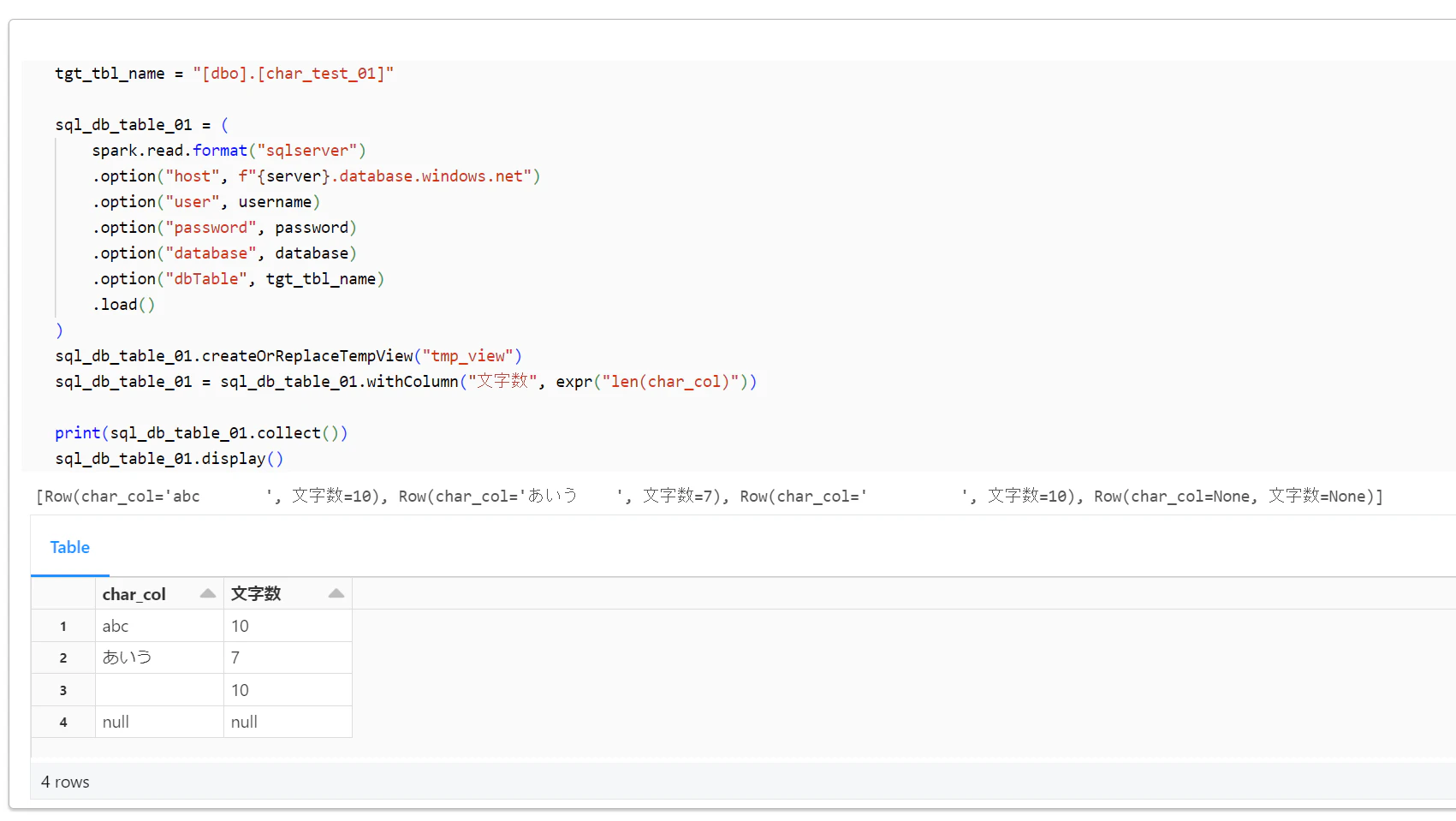
[
Row(char_col="abc ", 文字数=10),
Row(char_col="あいう ", 文字数=7),
Row(char_col=" ", 文字数=10),
Row(char_col=None, 文字数=None),
]
2. Azure SQL Database テーブル(ANSI_PADDING OFF)の参照検証
Azure SQL Database にて以下のコードを実行して、テーブルの作成とデータの挿入を実施
SET ANSI_PADDING OFF;
GO
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[char_test_02]') AND type in (N'U'))
DROP TABLE [dbo].[char_test_02]
GO
CREATE TABLE [dbo].[char_test_02]
(
[char_col] char(10) COLLATE Japanese_CI_AS
)
GO
INSERT INTO [dbo].[char_test_02]
SELECT 'abc' AS char_col
UNION ALL
SELECT N'あいう' AS char_col
UNION ALL
SELECT '' AS char_col
UNION ALL
SELECT NULL AS char_col
GO
SELECT
*
FROM
[dbo].[char_test_02]
GO
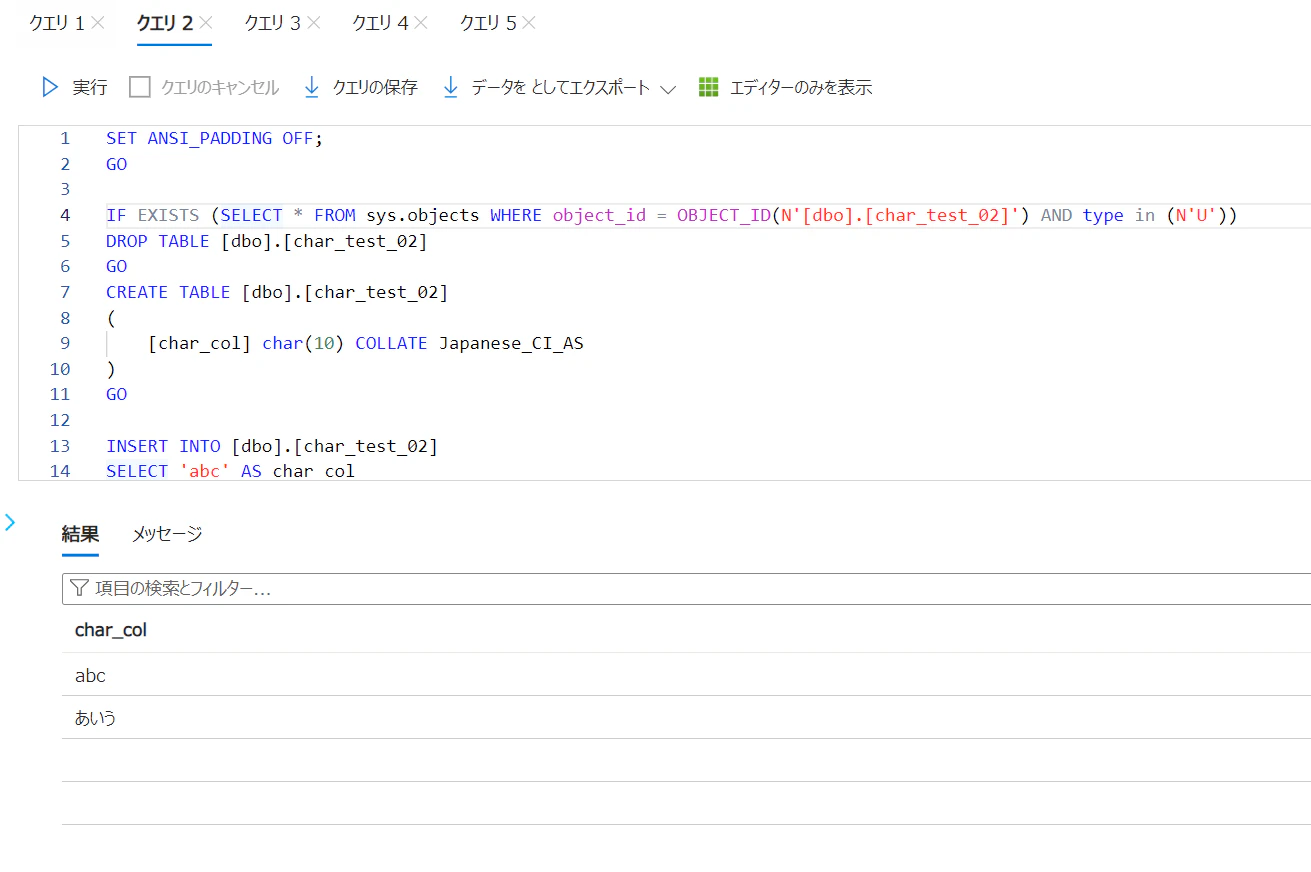
Databricks にて以下のコードを実行して、Azure SQL Database のテーブルを参照したデータフレームを作成し、文字数を算出して表示。
tgt_tbl_name = "[dbo].[char_test_02]"
sql_db_table_01 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("dbTable", tgt_tbl_name)
.load()
)
sql_db_table_01.createOrReplaceTempView("tmp_view")
sql_db_table_01 = sql_db_table_01.withColumn("文字数", expr("len(char_col)"))
print(sql_db_table_01.collect())
sql_db_table_01.display()
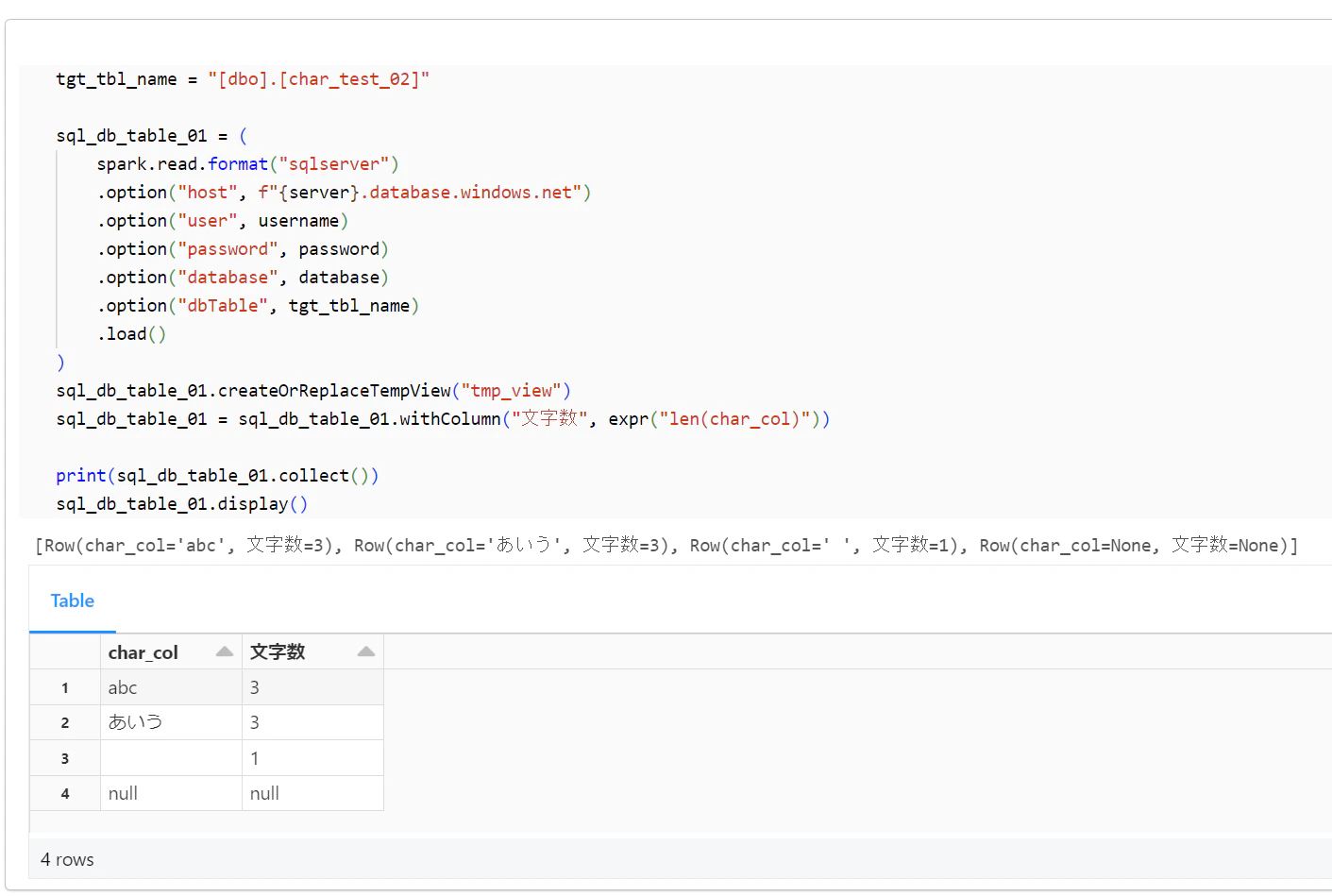
[
Row(char_col="abc", 文字数=3),
Row(char_col="あいう", 文字数=3),
Row(char_col=" ", 文字数=1),
Row(char_col=None, 文字数=None),
]
3. Azure SQL Database テーブル(ANSI_PADDING ON)への書き込み検証
Azure SQL Database にて以下のコードを実行して、テーブルを作成。
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[char_test_03]') AND type in (N'U'))
DROP TABLE [dbo].[char_test_03]
GO
CREATE TABLE [dbo].[char_test_03]
(
[char_col] char(10) COLLATE Japanese_CI_AS
)
GO
SELECT
*
FROM
[dbo].[char_test_03]
GO
Databricks にて以下のコードを実行して、Azure SQL Database のテーブルへデータを書きこみを実施。
src_schema = "char_col string"
src_data = [
{
"char_col": "abc",
},
{
"char_col": "あいう",
},
{
"char_col": "",
},
{
"char_col": None,
},
]
df = spark.createDataFrame(src_data,src_schema)
tgt_tbl_name = "[dbo].[char_test_03]"
(
df.write.format("sqlserver")
.mode("overwrite")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("truncate", True)
.option("dbTable", tgt_tbl_name)
.save()
)

Databricks にて以下のコードを実行して、Azure SQL Database のテーブルを参照したデータフレームを作成し、文字数を算出して表示。
tgt_tbl_name = "[dbo].[char_test_03]"
sql_db_table_03 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("dbTable", tgt_tbl_name)
.load()
)
sql_db_table_03 = sql_db_table_03.withColumn("文字数", expr("len(char_col)"))
print(sql_db_table_03.collect())
sql_db_table_03.display()
[
Row(char_col=None, 文字数=None),
Row(char_col=" ", 文字数=10),
Row(char_col="abc ", 文字数=10),
Row(char_col="あいう ", 文字数=7),
]
4. Azure SQL Database テーブル(ANSI_PADDING OFF)への書き込み検証
Azure SQL Database にて以下のコードを実行して、テーブルを作成。
SET ANSI_PADDING OFF;
GO
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[char_test_04]') AND type in (N'U'))
DROP TABLE [dbo].[char_test_04]
GO
CREATE TABLE [dbo].[char_test_04]
(
[char_col] char(10) COLLATE Japanese_CI_AS
)
GO
SELECT
*
FROM
[dbo].[char_test_04]
GO
Databricks にて以下のコードを実行して、Azure SQL Database のテーブルへデータを書きこみを実施。
src_schema = "char_col string"
src_data = [
{
"char_col": "abc",
},
{
"char_col": "あいう",
},
{
"char_col": "",
},
{
"char_col": None,
},
]
df = spark.createDataFrame(src_data,src_schema)
tgt_tbl_name = "[dbo].[char_test_04]"
(
df.write.format("sqlserver")
.mode("overwrite")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("truncate", True)
.option("dbTable", tgt_tbl_name)
.save()
)
Databricks にて以下のコードを実行して、Azure SQL Database のテーブルを参照したデータフレームを作成し、文字数を算出して表示。
tgt_tbl_name = "[dbo].[char_test_04]"
sql_db_table_04 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("dbTable", tgt_tbl_name)
.load()
)
sql_db_table_04 = sql_db_table_04.withColumn("文字数", expr("len(char_col)"))
print(sql_db_table_04.collect())
sql_db_table_04.display()
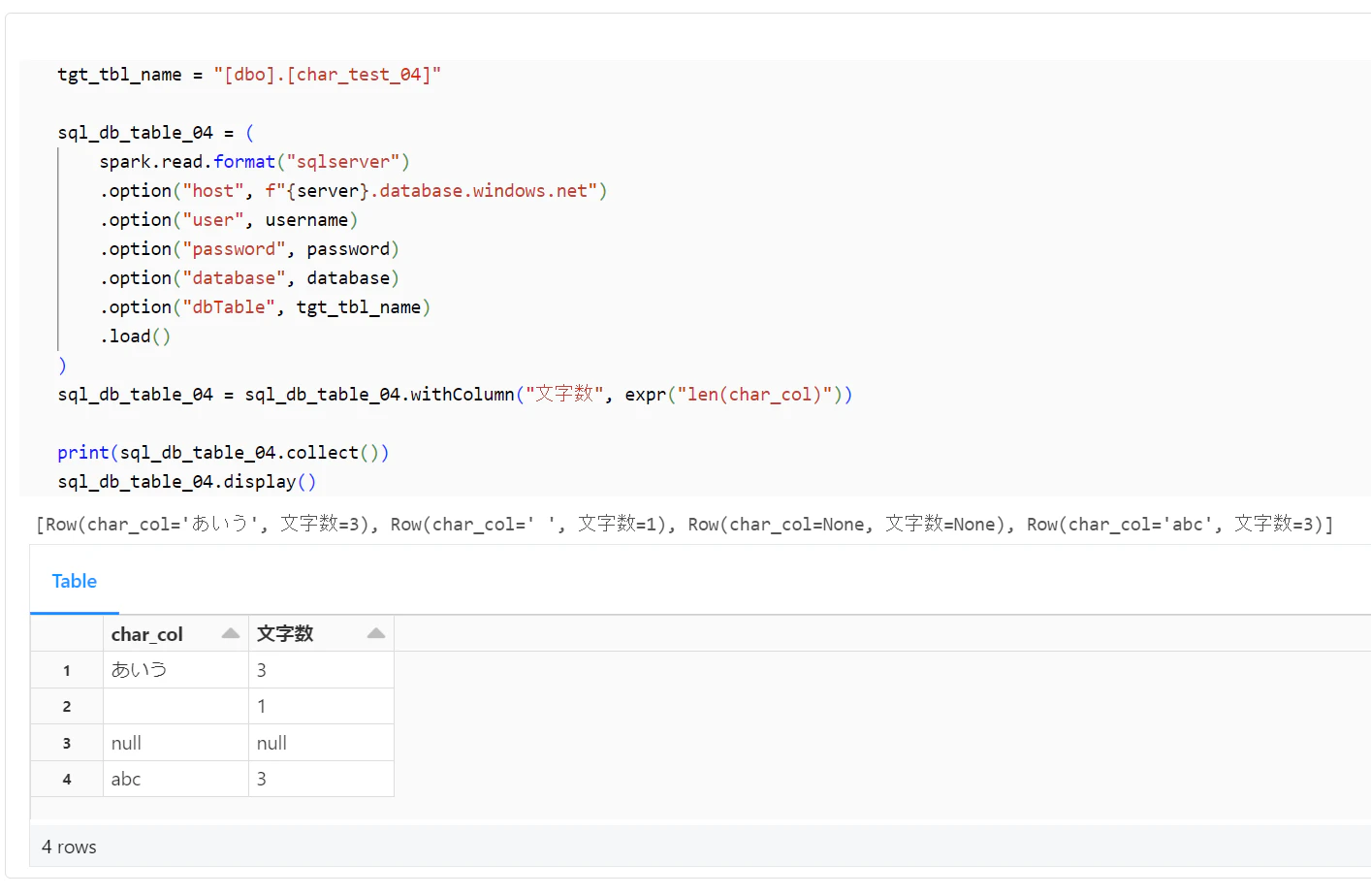
[
Row(char_col="あいう", 文字数=3),
Row(char_col="", 文字数=0),
Row(char_col="abc", 文字数=3),
Row(char_col=None, 文字数=None),
]
事後処理
Azure SQL Database にて以下のコードを実行して、Azure SQL Database に作成したテーブルを削除。
DROP TABLE [dbo].[char_test_01]
GO
DROP TABLE [dbo].[char_test_02]
GO
DROP TABLE [dbo].[char_test_03]
GO
DROP TABLE [dbo].[char_test_04]
GO