概要
Databricks と TROCCO を用いてデータの自動処理パイプラインを構築する手順を紹介します。具体的には、Salesforce の Case と Account データを TROCCO 経由で Databricks に蓄積し、オープン状態のケース情報をもつ分析用テーブル(opened_case)を生成します。その後、最終的にデータを Google スプレッドシート へ出力して即座に分析可能な環境を実現します。これらの処理は、Databricks Workflows により自動化します。
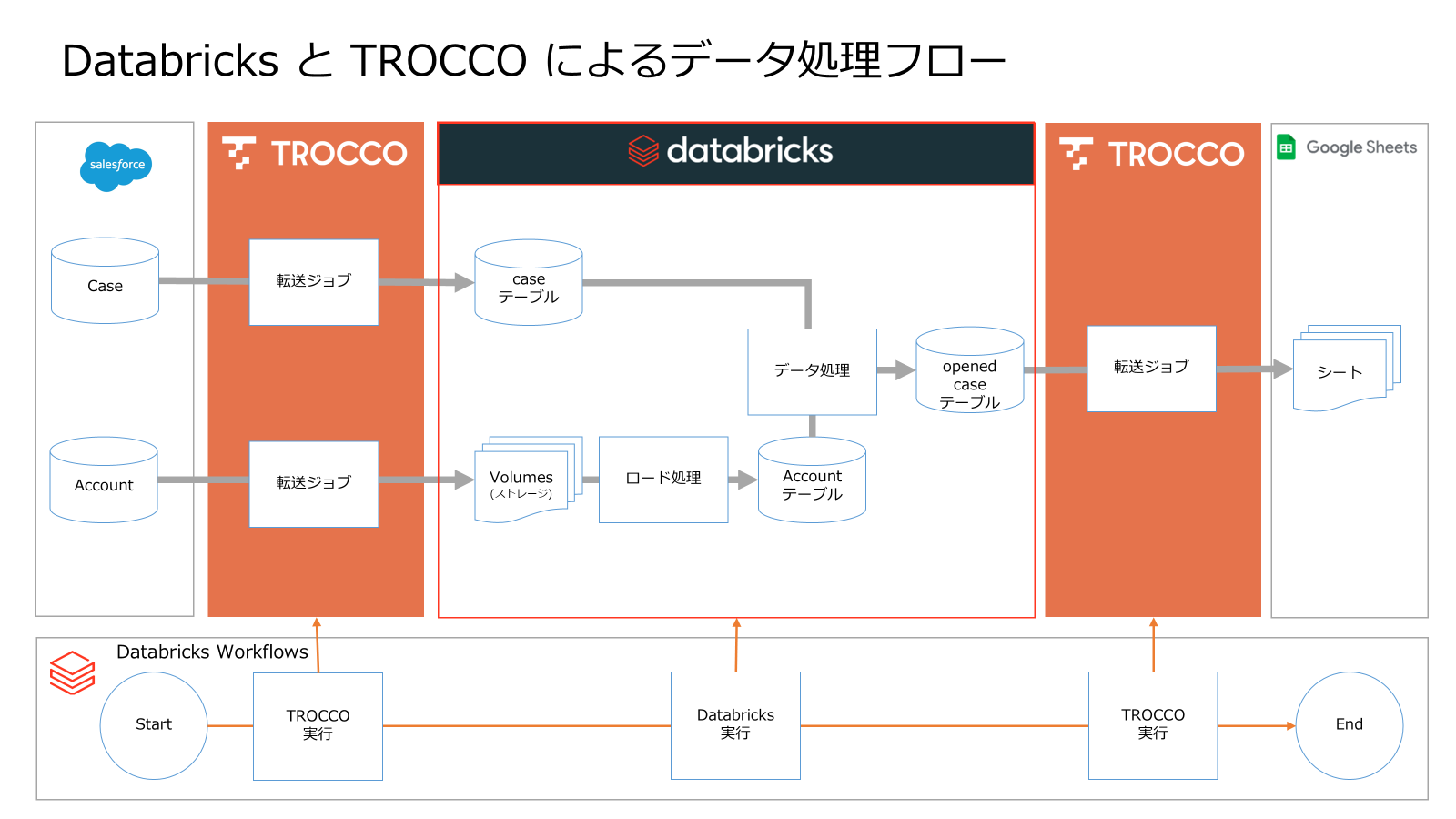
本記事の手順を実行すると、 Databricks Workflows 上で 5 つのタスクが自動的に実行され、 Salesforce のデータを素早くスプレッドシートで分析できるようになります。

また、別記事で紹介した自作ライブラリを利用することで、 TROCCO REST API を Python から直接操作可能になり、 Databricks Workflows 上でのワークフロー構築がさらに容易になります。
引用元:TROCCO REST API を Python で操作:GitHub Copilot で試してみた結果 #AI - Qiita
データパイプライン構築・実行手順
全体像
本記事で構築するデータパイプラインでは、以下のサービスを利用します。
- TROCCO
- Salesforce
- Azure Storage (ストレージ)
- Databricks
このワークフローは複数のタスクで構成され、順次実行されます。まず、 TROCCO の REST API を通じて Salesforce から取得したデータを Azure Storage へ転送(転送ジョブ)します。その後、 Databricks の Auto Loader を用いてストレージ上のデータを Databricks テーブルへロード(ロード処理)します。続いて、 CTAS ( Create Table As Select )による処理で分析用テーブルへデータを整形・更新(データ処理)し、最終的には整理済みの分析用データを再び TROCCO 経由で Google スプレッドシート へ出力することで、可視化・分析が可能な環境を実現します。
| 分類 | タスク名 | 役割・処理内容 |
|---|---|---|
| 転送ジョブ | salesforce_account_to_storage | Salesforce の Account データをストレージへ転送 |
| 転送ジョブ | salesforce_case_to_databricks | Salesforce の Case データを Databricks へ転送 |
| ロード処理 | load_storage_to_databricks | ストレージ上のデータを Databricks テーブルへロード |
| データ処理 | ctas_in_databricks | Databricks 内で CTAS 処理を実行し、分析用テーブルを生成 |
| 転送ジョブ | databricks_to_google_spreadsheet | Databricks 上の分析用テーブルを Google スプレッドシート へ出力 |
1. TROCCO 上での開発
1-1. 接続情報を定義
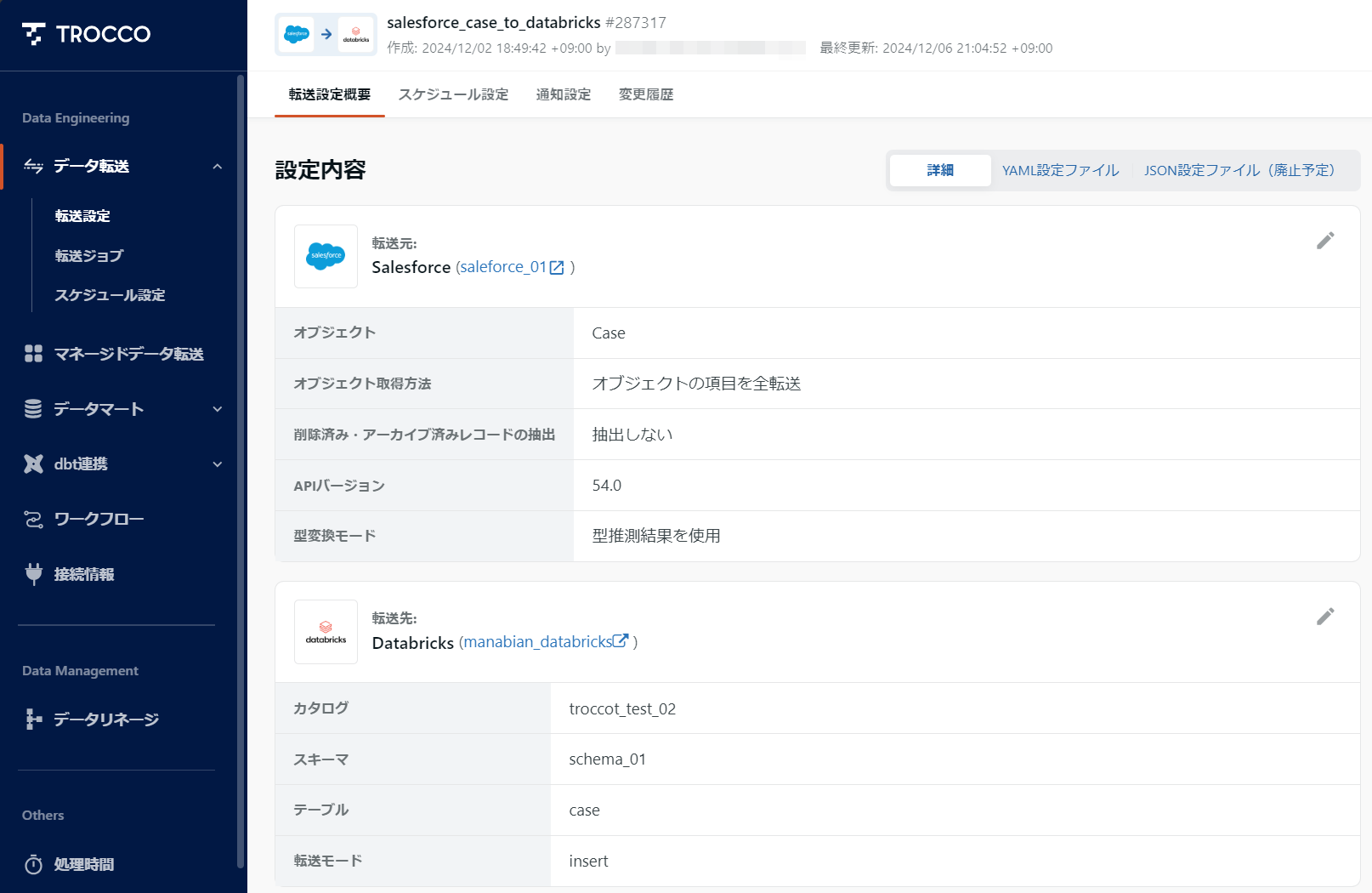
1-2. Salesforce の Case を Databricks に連携する転送ジョブを作成
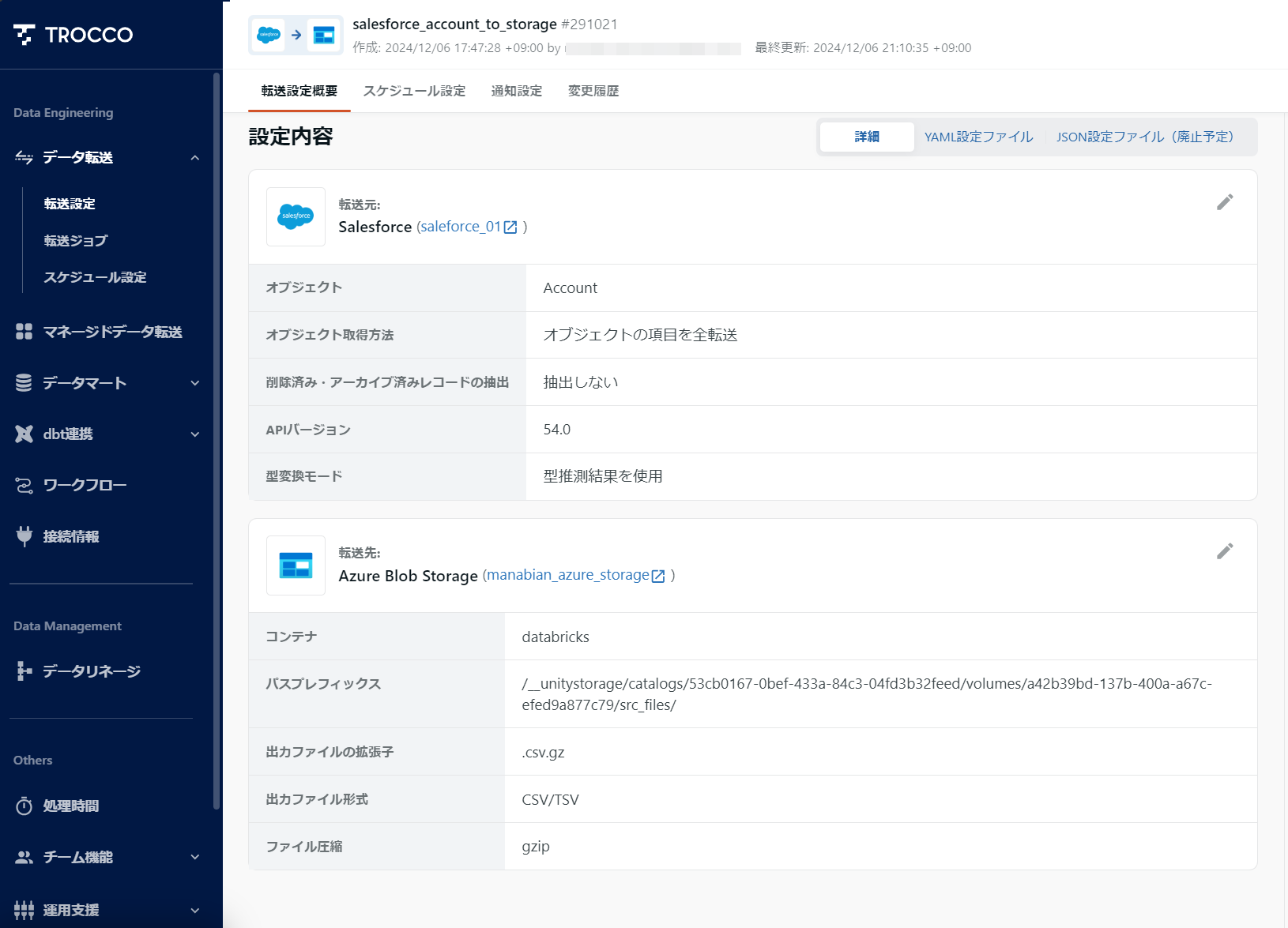
1-3. Salesforce の Account をストレージ( Azure Storage )に連携する転送ジョブを作成
1-4. Databricks から Google スプレッドシート に連携するジョブを作成
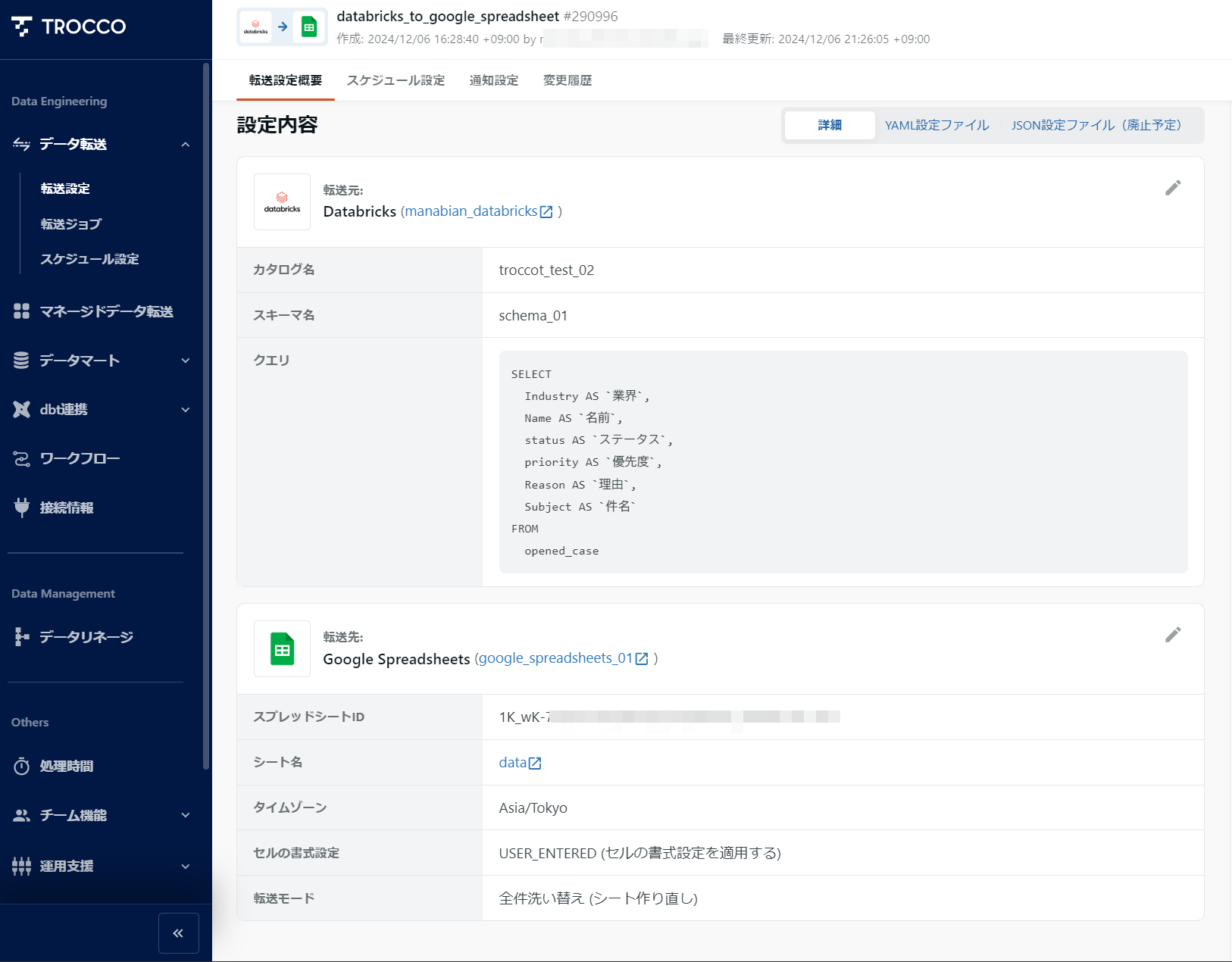
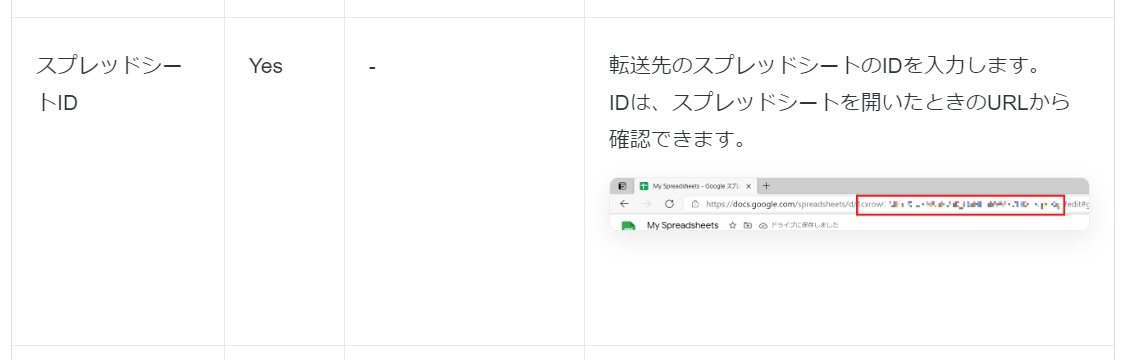
スプレッドシート ID の取得方法は、 TROCCO のドキュメントで詳しく説明されています。
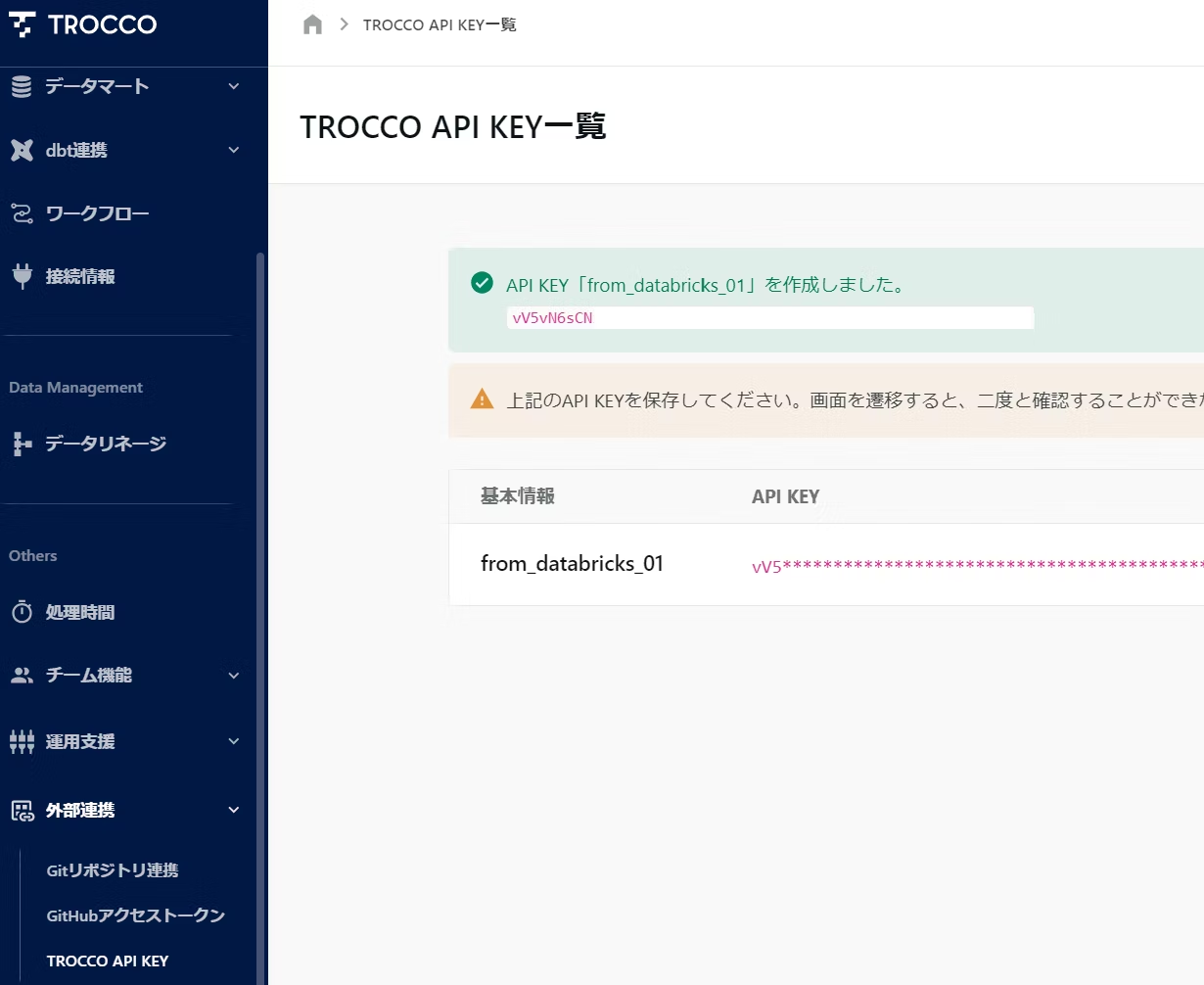
1-5. TROCCO API KEY を取得
2. Databricks 上での開発
2-1. データベースオブジェクトを作成
カタログとスキーマを作成します。
%sql
CREATE CATALOG IF NOT EXISTS troccot_test_02;
CREATE SCHEMA IF NOT EXISTS troccot_test_02.schema_01;

Account テーブルと Volume を作成し、既存のテーブルがある場合は削除します。 Case テーブルは TROCCO の転送ジョブ実行時に、 Opened_case テーブルは Databricks の処理実行時にそれぞれ作成されます。
%sql
-- case テーブルを削除
DROP TABLE IF EXISTS troccot_test_02.schema_01.case;
-- account テーブルを作成( Auto Loader のロード先であるため先に作成 )
DROP TABLE IF EXISTS troccot_test_02.schema_01.account;
CREATE TABLE troccot_test_02.schema_01.account;
-- opened_case テーブルを削除
DROP TABLE IF EXISTS troccot_test_02.schema_01.opened_case;
-- Volume を作成
CREATE VOLUME IF NOT EXISTS troccot_test_02.schema_01.src_volume_01;
Databricks Auto Loader で利用するチェックポイントディレクトリを初期化します。
# Auto Loader で利用するチェックポイントの初期化
dbutils.fs.rm("/Volumes/troccot_test_02/schema_01/src_volume_01/checkpoint", True)

2-2. Databricks シークレットのスコープとシークレットを作成
%pip install databricks-sdk --upgrade -q
dbutils.library.restartPython()

from databricks.sdk import WorkspaceClient
from databricks.sdk.core import DatabricksError
w = WorkspaceClient()

# scope 名をセット
scope_name = 'trocco'
# scope を作成
try:
w.secrets.create_scope(scope=scope_name)
except DatabricksError:
print(f"Scope `{scope_name}` already exists!")
# シークレットのキーと値をセット
scope_key_and_values = {
"api_key": "DkXvDxgowM482F5M7X6n9swK1dBF9deNpaFa4V7zzzzz",
}
# シークレットを登録
for key,value in scope_key_and_values.items():
w.secrets.put_secret(
scope=scope_name,
key=key,
string_value=value,
)

# シークレットを取得し確認
print(dbutils.secrets.get(scope_name,"api_key"))

2-3. TROCCO REST API の実行クラスを有するファイル( trocco_api.py )を作成
コードはこちら
import time
import requests
from typing import Optional
class TroccoAPIClient:
"""Trocco APIクライアントクラス。
Args:
api_key (str): Trocco APIのAPIキー。
wait_time (int, optional): リクエスト間の待機時間(秒)。デフォルトは30秒。
max_wait_time (int, optional): 最大待機時間(秒)。デフォルトは3600秒(60分)。
Attributes:
api_key (str): Trocco APIのAPIキー。
base_url (str): Trocco APIのベースURL。
headers (dict): リクエストヘッダー。
wait_time (int): リクエスト間の待機時間(秒)。
max_wait_time (int): 最大待機時間(秒)。
"""
def __init__(self, api_key: str, wait_time: int = 30, max_wait_time: int = 3600) -> None:
self.api_key = api_key
self.base_url = "https://trocco.io/api"
self.headers = {
"Authorization": f"Token {self.api_key}",
"Content-Type": "application/json"
}
self.wait_time = wait_time
self.max_wait_time = max_wait_time
def post_job(self, payload: dict) -> Optional[dict]:
"""ジョブを作成する。
Args:
payload (dict): ジョブ作成に必要なデータ。
Returns:
Optional[dict]: APIからのレスポンス。失敗した場合はNone。
"""
url = f"{self.base_url}/jobs"
try:
response = requests.post(url, json=payload, headers=self.headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"エラーが発生しました: {e}")
return None
def get_job(self, job_id: str) -> Optional[dict]:
"""特定のジョブの詳細を取得する。
Args:
job_id (str): 取得したいジョブのID。
Returns:
Optional[dict]: ジョブの詳細。失敗した場合はNone。
"""
url = f"{self.base_url}/jobs/{job_id}"
try:
response = requests.get(url, headers=self.headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"エラーが発生しました: {e}")
return None
def get_jobs(self, params: dict = {}) -> Optional[dict]:
"""ジョブの一覧を取得する。
Args:
params (dict, optional): クエリパラメータ。
Returns:
Optional[dict]: ジョブの一覧。失敗した場合はNone。
"""
url = f"{self.base_url}/jobs"
try:
response = requests.get(url, headers=self.headers, params=params)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"エラーが発生しました: {e}")
return None
def execute_job_and_wait(self, payload: dict) -> Optional[dict]:
"""ジョブを作成し、完了するまで待機して結果を取得する。
Args:
payload (dict): ジョブ作成に必要なデータ。
Returns:
Optional[dict]: 最終的なジョブの結果。失敗した場合はNone。
"""
job = self.post_job(payload)
if not job:
return None
job_id = job.get("id")
if not job_id:
print("ジョブIDを取得できませんでした。")
return None
start_time = time.time()
while True:
job_status = self.get_job(job_id)
if job_status:
status = job_status.get("status")
if status == "succeeded":
print("ジョブが成功しました。")
return job_status
elif status == "error":
print("ジョブが失敗しました。")
return job_status
else:
print(f"ジョブのステータス: {status}。待機します。")
else:
print("ジョブステータスの取得に失敗しました。リトライします。")
if time.time() - start_time > self.max_wait_time:
print("最大待機時間を超えました。")
return None
time.sleep(self.wait_time)

2-4. TROCCO REST API による転送ジョブ実行用ノートブック(00_execute_trocco_api)
job_definition_id をパラメータで受け取り、そのジョブを実行し完了まで待機します。
from trocco_api import TroccoAPIClient
dbutils.widgets.text("job_definition_id", "", "Enter Job Definition ID")
job_definition_id = dbutils.widgets.get("job_definition_id")
scope_name = "trocco"
secret_name = "api_key"
api_key = dbutils.secrets.get(scope_name, secret_name)
client = TroccoAPIClient(api_key)
payload = {
"job_definition_id": job_definition_id,
}
result = client.execute_job_and_wait(payload)
if result:
print("ジョブの結果:")
print(result)
else:
print("ジョブの取得に失敗しました。")

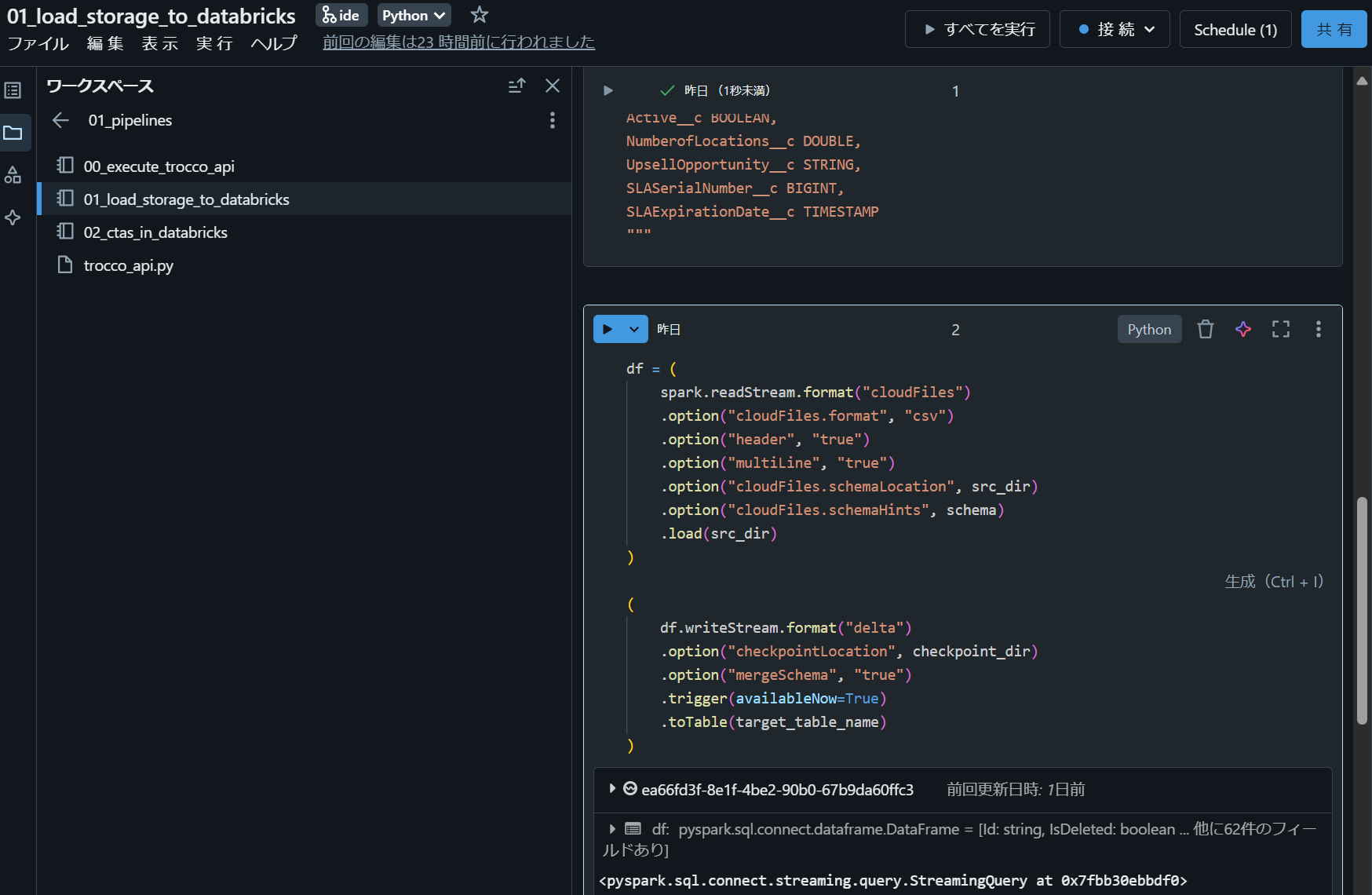
2-5. Databricks Auto Loader によるデータ取り込みノートブック(01_load_storage_to_databricks)
src_dir = "/Volumes/troccot_test_02/schema_01/src_volume_01/src_files"
checkpoint_dir = "/Volumes/troccot_test_02/schema_01/src_volume_01/checkpoint"
target_table_name = "troccot_test_02.schema_01.account"
schema = """
Id STRING,
IsDeleted BOOLEAN,
MasterRecordId STRING,
Name STRING,
Type STRING,
ParentId STRING,
BillingStreet STRING,
BillingCity STRING,
BillingState STRING,
BillingPostalCode BIGINT,
BillingCountry STRING,
BillingLatitude STRING,
BillingLongitude STRING,
BillingGeocodeAccuracy STRING,
ShippingStreet STRING,
ShippingCity STRING,
ShippingState STRING,
ShippingPostalCode BIGINT,
ShippingCountry STRING,
ShippingLatitude STRING,
ShippingLongitude STRING,
ShippingGeocodeAccuracy STRING,
Phone STRING,
Fax STRING,
AccountNumber STRING,
Website STRING,
PhotoUrl STRING,
Sic BIGINT,
Industry STRING,
AnnualRevenue DOUBLE,
NumberOfEmployees BIGINT,
Ownership STRING,
TickerSymbol STRING,
Description STRING,
Rating STRING,
Site STRING,
OwnerId STRING,
CreatedDate TIMESTAMP,
CreatedById STRING,
LastModifiedDate TIMESTAMP,
LastModifiedById STRING,
SystemModstamp TIMESTAMP,
LastActivityDate STRING,
LastViewedDate STRING,
LastReferencedDate STRING,
Jigsaw STRING,
JigsawCompanyId STRING,
CleanStatus STRING,
AccountSource STRING,
DunsNumber STRING,
Tradestyle STRING,
NaicsCode STRING,
NaicsDesc STRING,
YearStarted STRING,
SicDesc STRING,
DandbCompanyId STRING,
CustomerPriority__c STRING,
SLA__c STRING,
Active__c BOOLEAN,
NumberofLocations__c DOUBLE,
UpsellOpportunity__c STRING,
SLASerialNumber__c BIGINT,
SLAExpirationDate__c TIMESTAMP
"""
df = (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("header", "true")
.option("multiLine", "true")
.option("cloudFiles.schemaLocation", src_dir)
.option("cloudFiles.schemaHints", schema)
.load(src_dir)
)
(
df.writeStream.format("delta")
.option("checkpointLocation", checkpoint_dir)
.option("mergeSchema", "true")
.trigger(availableNow=True)
.toTable(target_table_name)
)
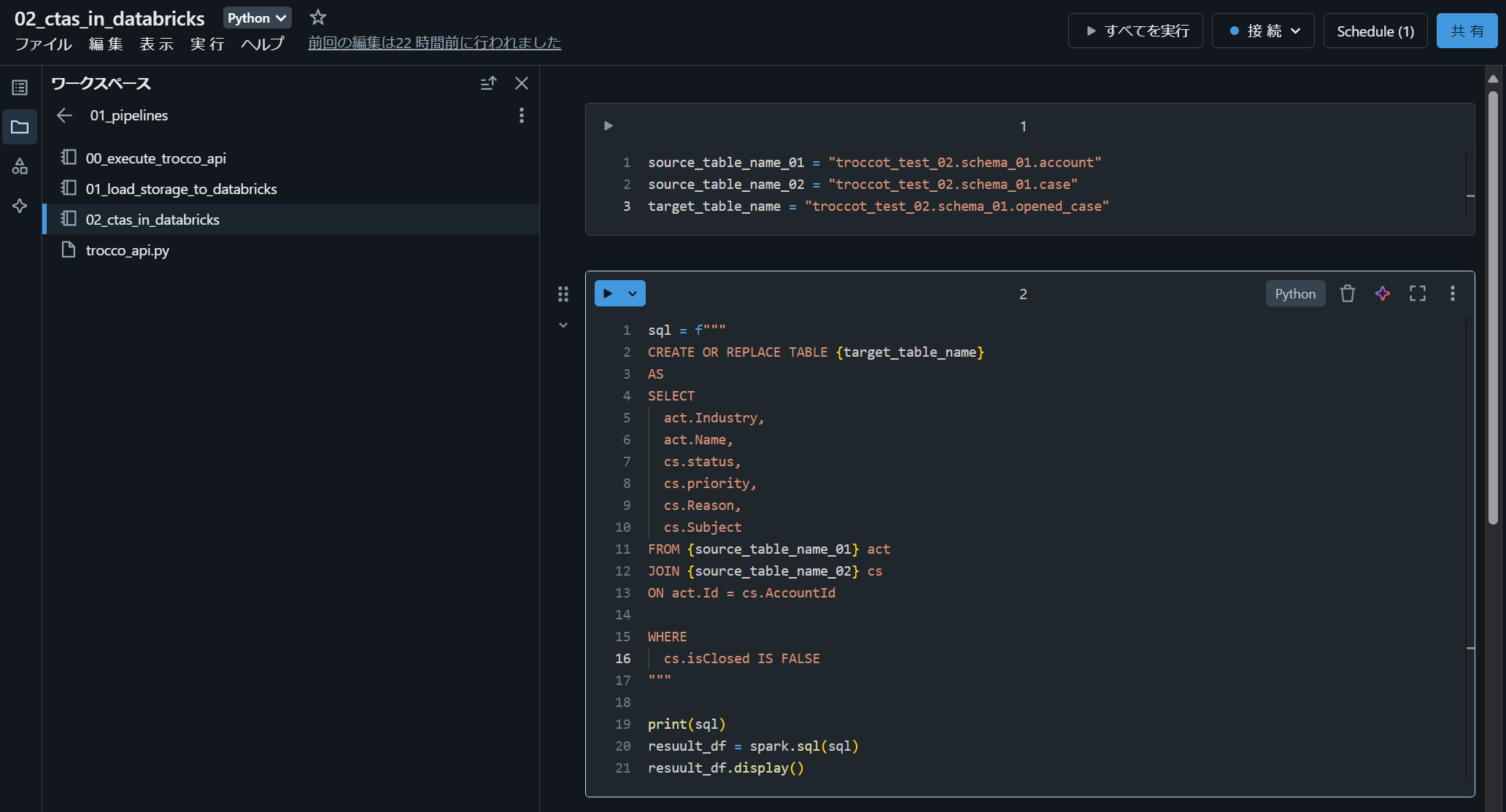
2-6. CTAS によるデータ処理ノートブック(02_ctas_in_databricks)
source_table_name_01 = "troccot_test_02.schema_01.account"
source_table_name_02 = "troccot_test_02.schema_01.case"
target_table_name = "troccot_test_02.schema_01.opened_case"
sql = f"""
CREATE OR REPLACE TABLE {target_table_name}
AS
SELECT
act.Industry,
act.Name,
cs.status,
cs.priority,
cs.Reason,
cs.Subject
FROM {source_table_name_01} act
JOIN {source_table_name_02} cs
ON act.Id = cs.AccountId
WHERE
cs.isClosed IS FALSE
"""
print(sql)
resuult_df = spark.sql(sql)
resuult_df.display()
3. ワークフローの実行と結果確認
3-1. Databricks Workflow のジョブを作成
Databricks Workflows にて、上記ノートブックを順次実行するジョブを作成します。転送ジョブを実行するノートブックは共通化しており、実行する転送ジョブの ID ( job_definition_id )をパラメータで渡します。

コードはこちら
resources:
jobs:
databricks_with_trocco:
name: databricks_with_trocco
tasks:
- task_key: salesforce_account_to_storage
notebook_task:
notebook_path: /Workspace/Shared/databricks_with_trocco/01_pipelines/00_execute_trocco_api
base_parameters:
job_definition_id: "291021"
source: WORKSPACE
- task_key: load_storage_to_databricks
depends_on:
- task_key: salesforce_account_to_storage
notebook_task:
notebook_path: /Workspace/Shared/databricks_with_trocco/01_pipelines/01_load_storage_to_databricks
source: WORKSPACE
- task_key: salesforce_case_to_databricks
notebook_task:
notebook_path: /Workspace/Shared/databricks_with_trocco/01_pipelines/00_execute_trocco_api
base_parameters:
job_definition_id: "287317"
source: WORKSPACE
- task_key: ctas_in_databricks
depends_on:
- task_key: load_storage_to_databricks
- task_key: salesforce_case_to_databricks
notebook_task:
notebook_path: /Workspace/Shared/databricks_with_trocco/01_pipelines/02_ctas_in_databricks
source: WORKSPACE
- task_key: databricks_to_google_spreadsheet_
depends_on:
- task_key: ctas_in_databricks
notebook_task:
notebook_path: /Workspace/Shared/databricks_with_trocco/01_pipelines/00_execute_trocco_api
base_parameters:
job_definition_id: "290996"
source: WORKSPACE
queue:
enabled: true
3-2. Databricks Workflow のジョブを実行
Databricks Workflows を実行すると、処理状況が可視化され、正常に完了したことを確認できます。

ノートブック実行結果は内部に保存されており、エラー発生時にも原因特定が容易なため、システム運用をスムーズに行えます。
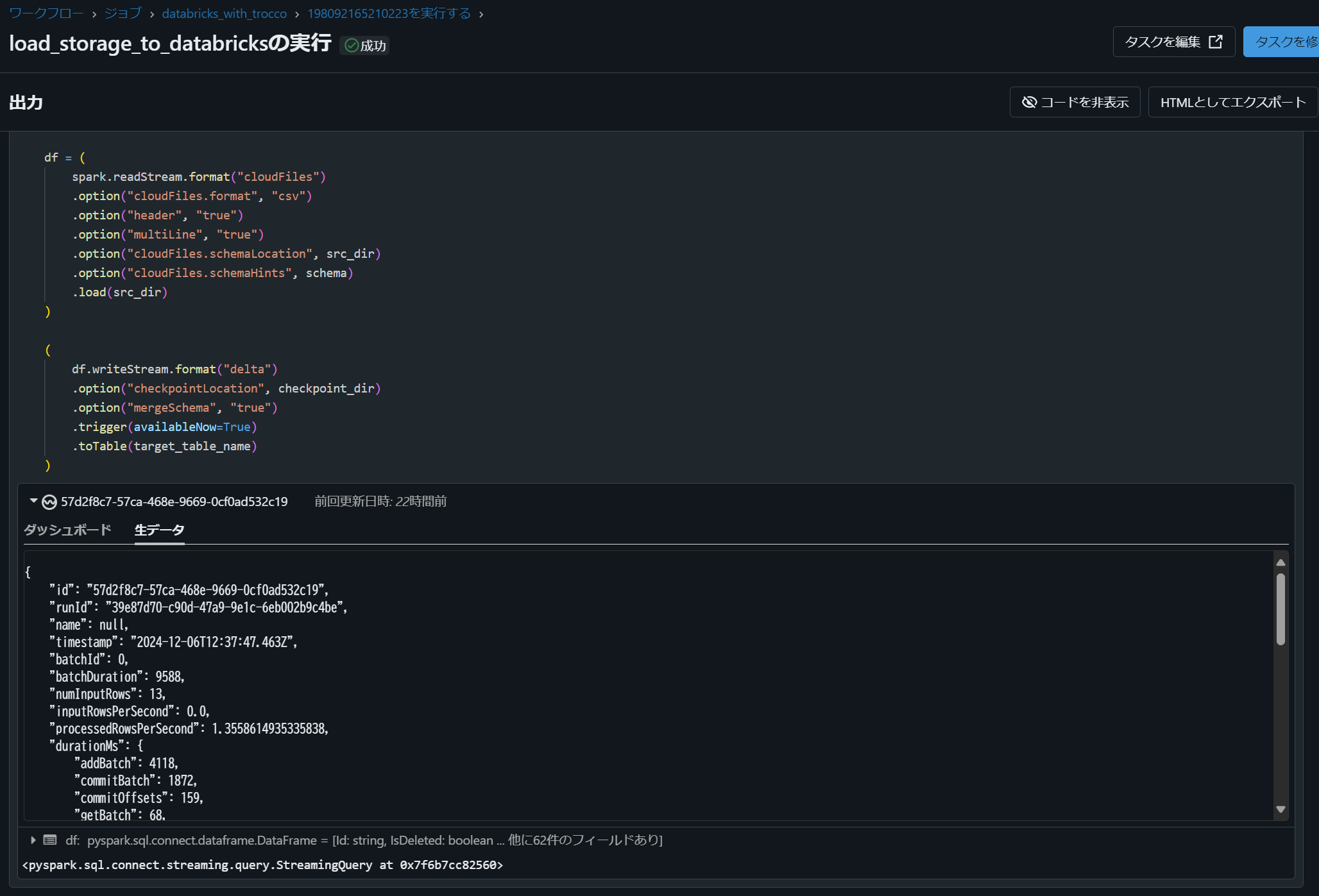
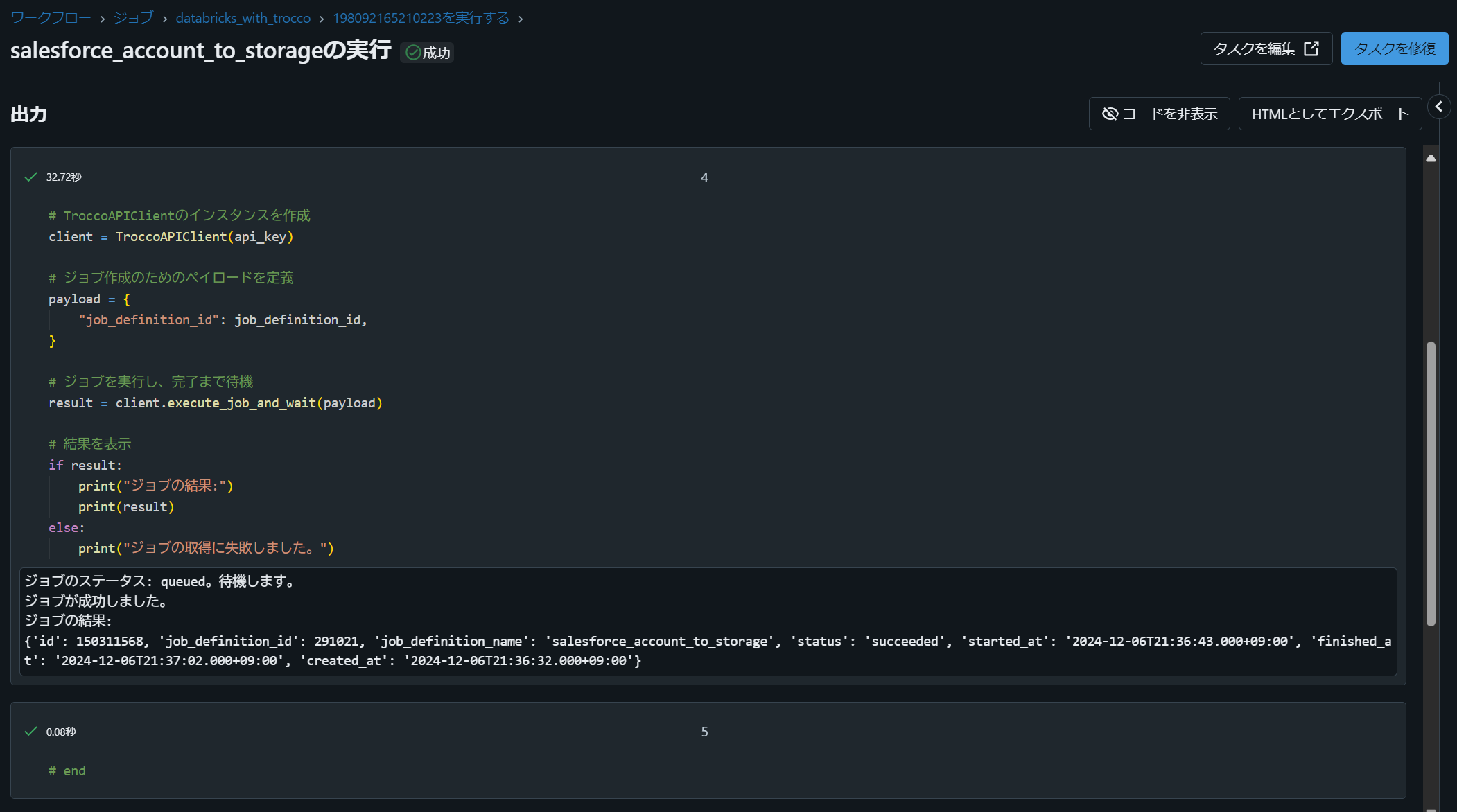
TROCCO にて REST API 実行結果を確認

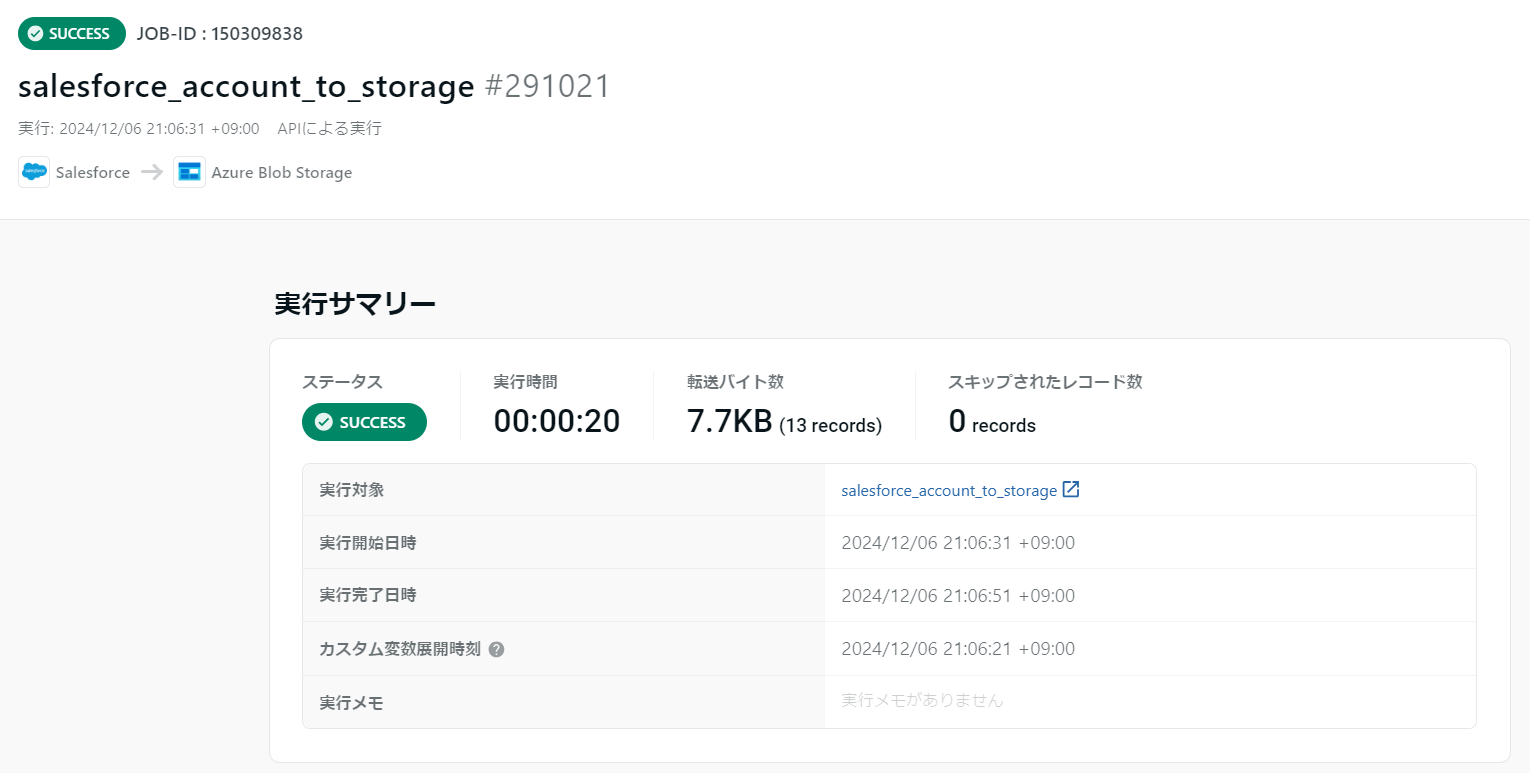

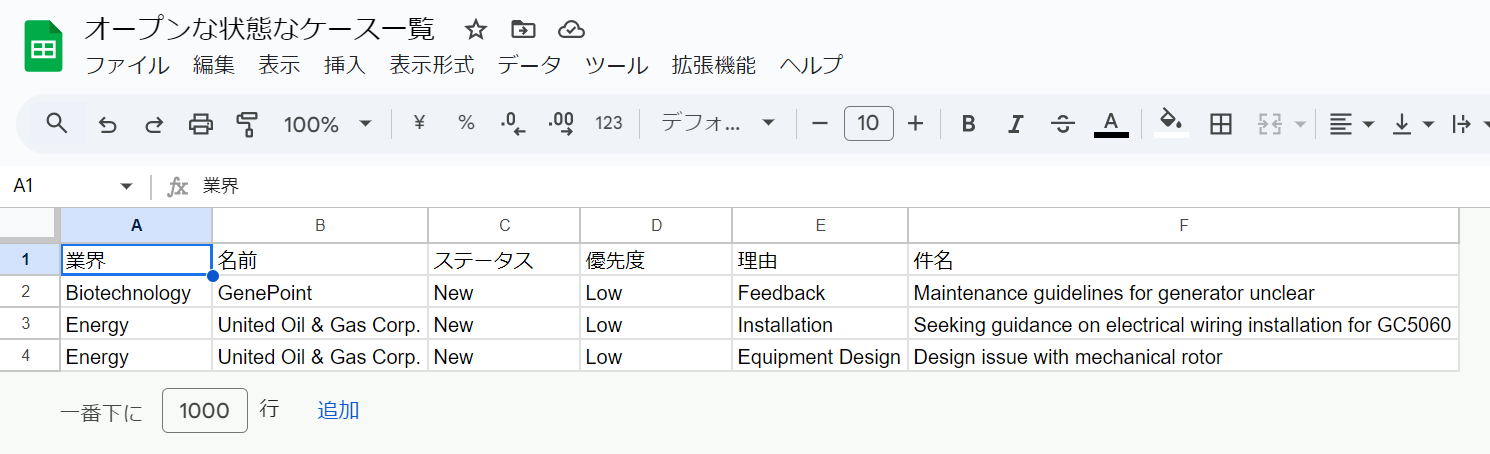
3-3. Google スプレッドシート にてデータが連携されたことを確認

Next Action
1. Databricks におけるデータアーキテクチャの設計
本記事では単純なデータアーキテクチャを扱いましたが、実運用に際しては、より適切なアーキテクチャの検討が必要です。
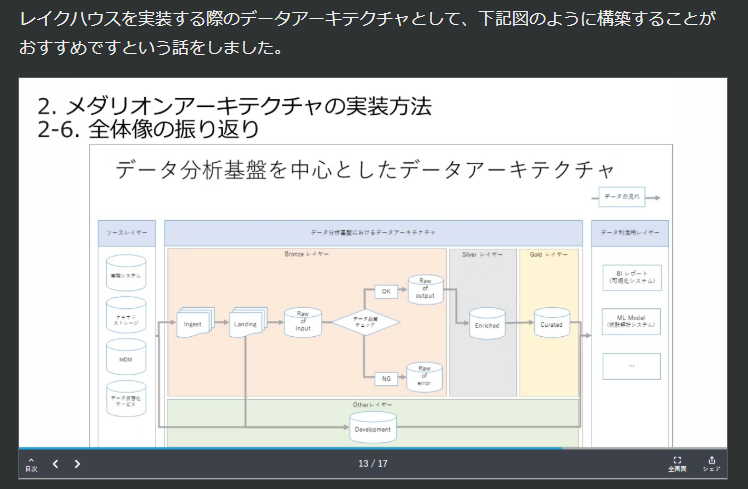
引用元:誰も教えてくれないメダリオンアーキテクチャの デザインメソッド:JEDA データエンジニア分科会 #1 #Python - Qiita
本記事では TROCCO と Databricks を連携する 2 つの手法を紹介しましたが、実際には運用要件やシステム構成に応じた手法選定が必要です。システム間を疎結合にし、ファイル連携時に Databricks の Auto Loader でファイル追加を容易に行う点を考慮すると、筆者は 2 番目の方法(ストレージ経由)が適するケースが多いと考えています。
- TROCCO から Databricks へ直接連携する方法
- TROCCO から Databricks へストレージ経由で連携する方法
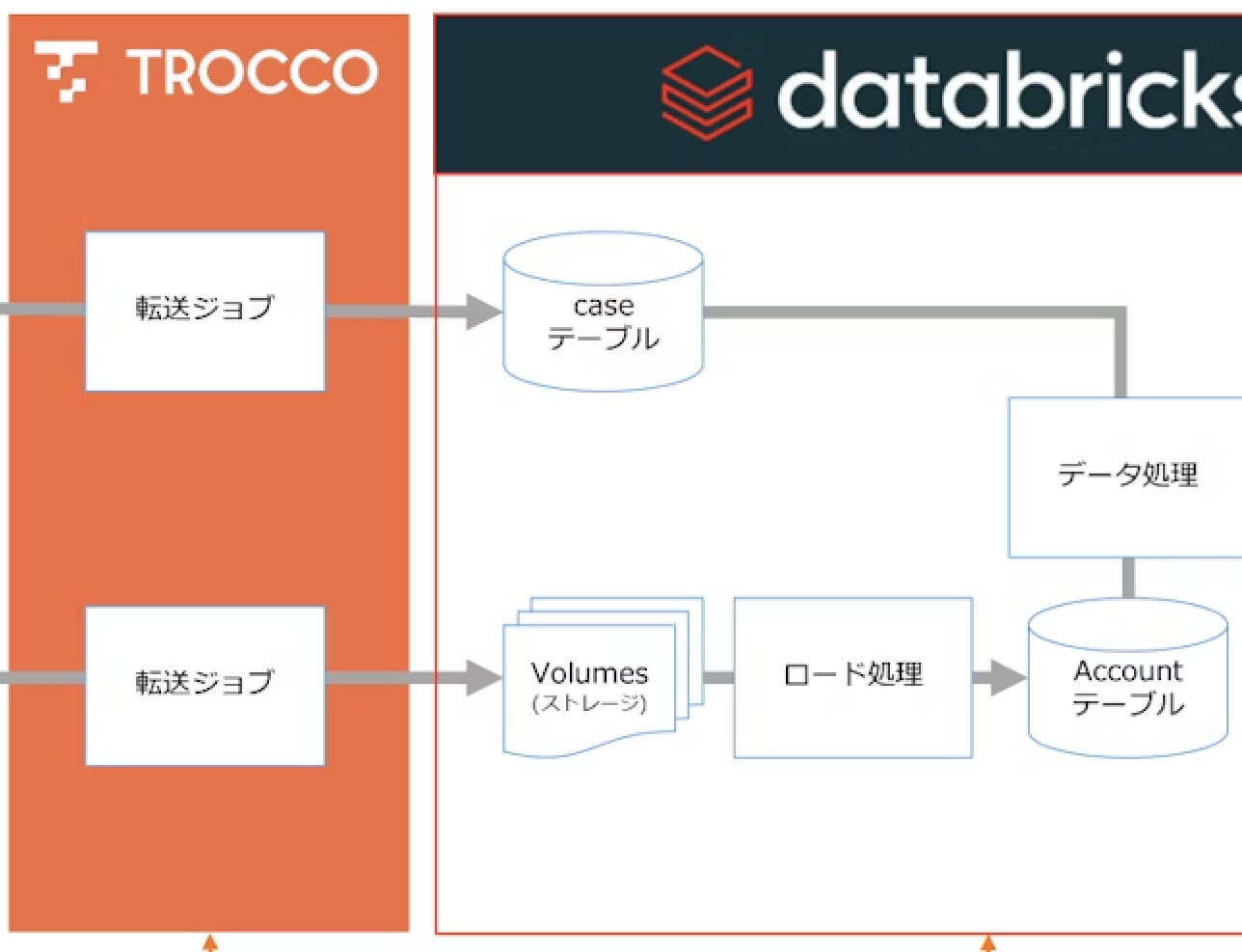
TROCCO にて Databricks と直接連携する方法として下記の方法が提供されています。マネージドデータ転送もサポートされており、ソースシステムから複数のオブジェクトを連携する際には便利です。
2. パイプラインの構築方法の検討
本記事ではノートブックでのパイプラインを構築しましたが、 dbt(Data Build Tool)や Databricks が開発している Delta live tables という機能により構築する方法があり、組織のスキルや状況に応じてパイプラインの構築方法を検討してください。
3. TROCCO REST API 実行ライブラリの改修
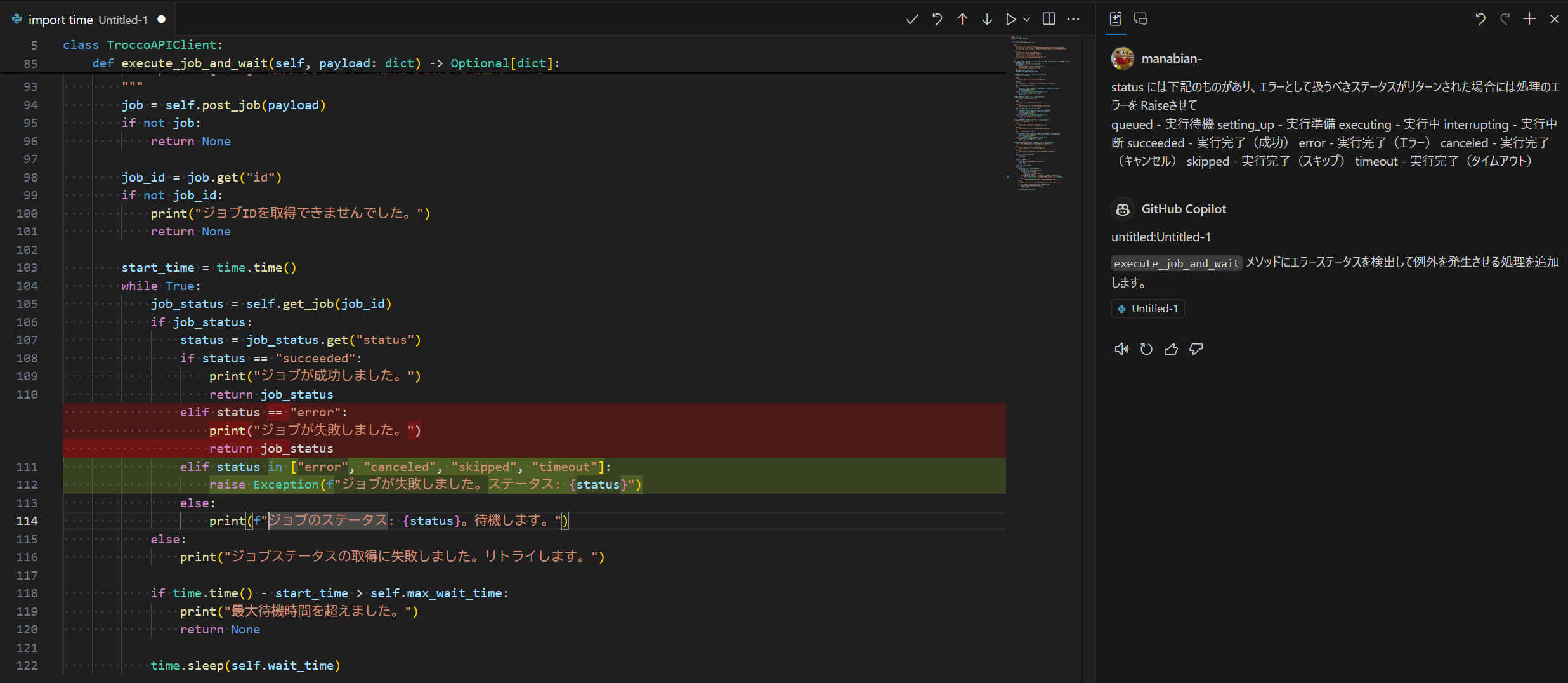
TROCCO REST API を実行するライブラリの改修も検討すべきです。例えば、今回利用した際には TROCCO 側の転送ジョブがエラーとなっても Databricks Workflows 上のタスクがエラーとして認識されませんでした。 GitHub Copilot の Copilot Edits 機能などを用いて、 API のステータスチェック処理を強化し、エラーステータス時に適切に例外をスローするように改修してください。
status には下記のものが存在し、エラーとして扱うべきステータスが返却された場合には処理エラーとして例外を発生させることが望まれます。
queued / setting_up / executing / interrupting / succeeded / error / canceled / skipped / timeout
return job_status
- elif status == "error":
- print("ジョブが失敗しました。")
+ elif status in ["error", "canceled", "skipped", "timeout"]:
+ raise Exception(f"ジョブが失敗しました。ステータス: {status}")
return job_status