概要
Databricks にて Hadoop Catalog の Apache Iceberg のテーブルディレクトリからデータを取得する方法の検証結果を共有します。いずれかの Databricks Runtime のバージョンで動いたものを動作確認できた方法として紹介します。エラーとなった方法や Databricks Runtime のバージョンごとの動作結果も備忘録として残しています。
事前準備
データ書き込み用クラスターの準備
以下の設定を行ったクラスターを作成します。
- Databricks Runtime のバージョンを 12.2LTS 以前にすること
- アクセスモードを分離なし共有(Uniyt Catalog 利用不可のモード」)にすること
- Java 8 に対応したライブラリ(Iceberg 1.6.1 以前のライブラリ)を利用すること
- Spark 構成に Iceberg 関連の設定を実施
Spark 構成にて下記の設定を実施します。
spark.sql.catalog.spark_catalog = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.spark_catalog.type = hadoop
spark.sql.catalog.spark_catalog.warehouse = dbfs:/Iceberg
spark.sql.extensions = org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
Namespace を作成
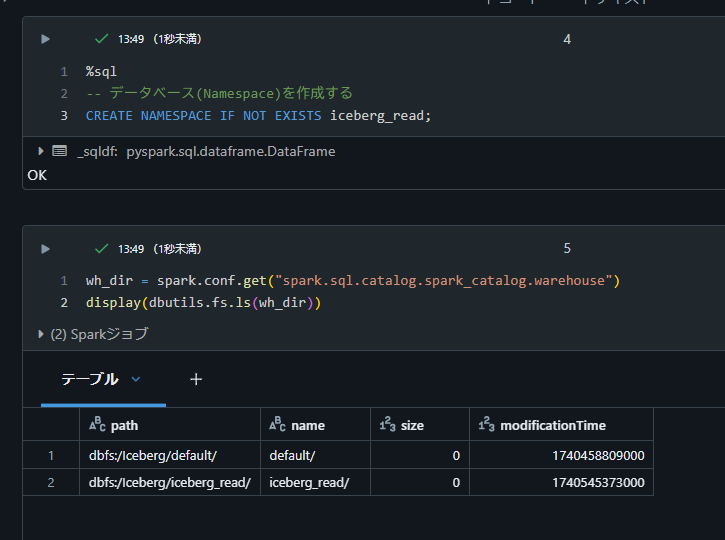
%sql
-- データベース(Namespace)を作成する
CREATE NAMESPACE IF NOT EXISTS iceberg_read;
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
display(dbutils.fs.ls(wh_dir))
テーブルの準備
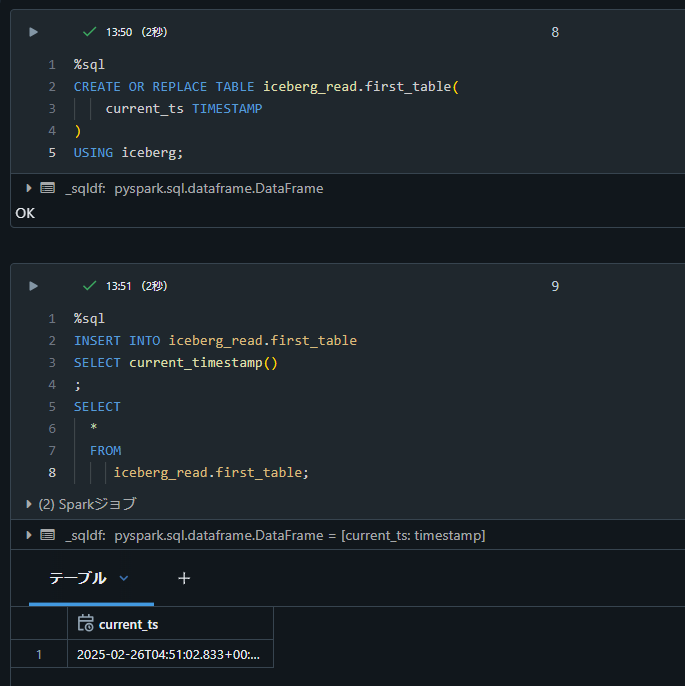
%sql
CREATE OR REPLACE TABLE iceberg_read.first_table(
current_ts TIMESTAMP
)
USING iceberg;
%sql
INSERT INTO iceberg_read.first_table
SELECT current_timestamp()
;
SELECT
*
FROM
iceberg_read.first_table;
読み込み用のクラスター作成
検証に利用する Databricks Runtime (12.2、13.3、14.3、 16.2)のバージョンごとに下記の設定を実施したクラスターを作成
- アクセスモードを分離なし共有にすること
- Iceberg 関連のライブラリをインストール
動作確認できた方法
テーブルのディレクトリを指定する方法
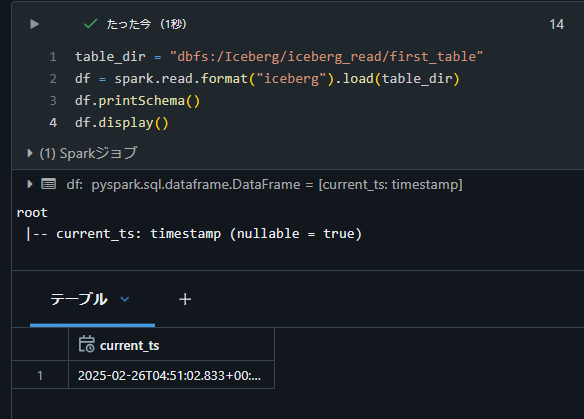
Databricks Runtime 12.2 にて下記のコードで動作を確認。
table_dir = "dbfs:/Iceberg/iceberg_read/first_table"
df = spark.read.format("iceberg").load(table_dir)
df.printSchema()
df.display()
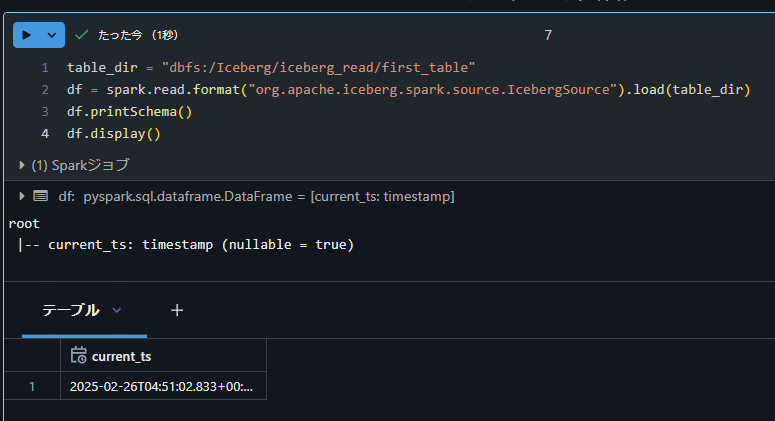
Databricks Runtime 13.3 、および、Databricks Runtime 16.2 ではsourceオプションを下記のように変更して動作することを確認。
table_dir = "dbfs:/Iceberg/iceberg_read/first_table"
df = spark.read.format("org.apache.iceberg.spark.source.IcebergSource").load(table_dir)
df.printSchema()
df.display()
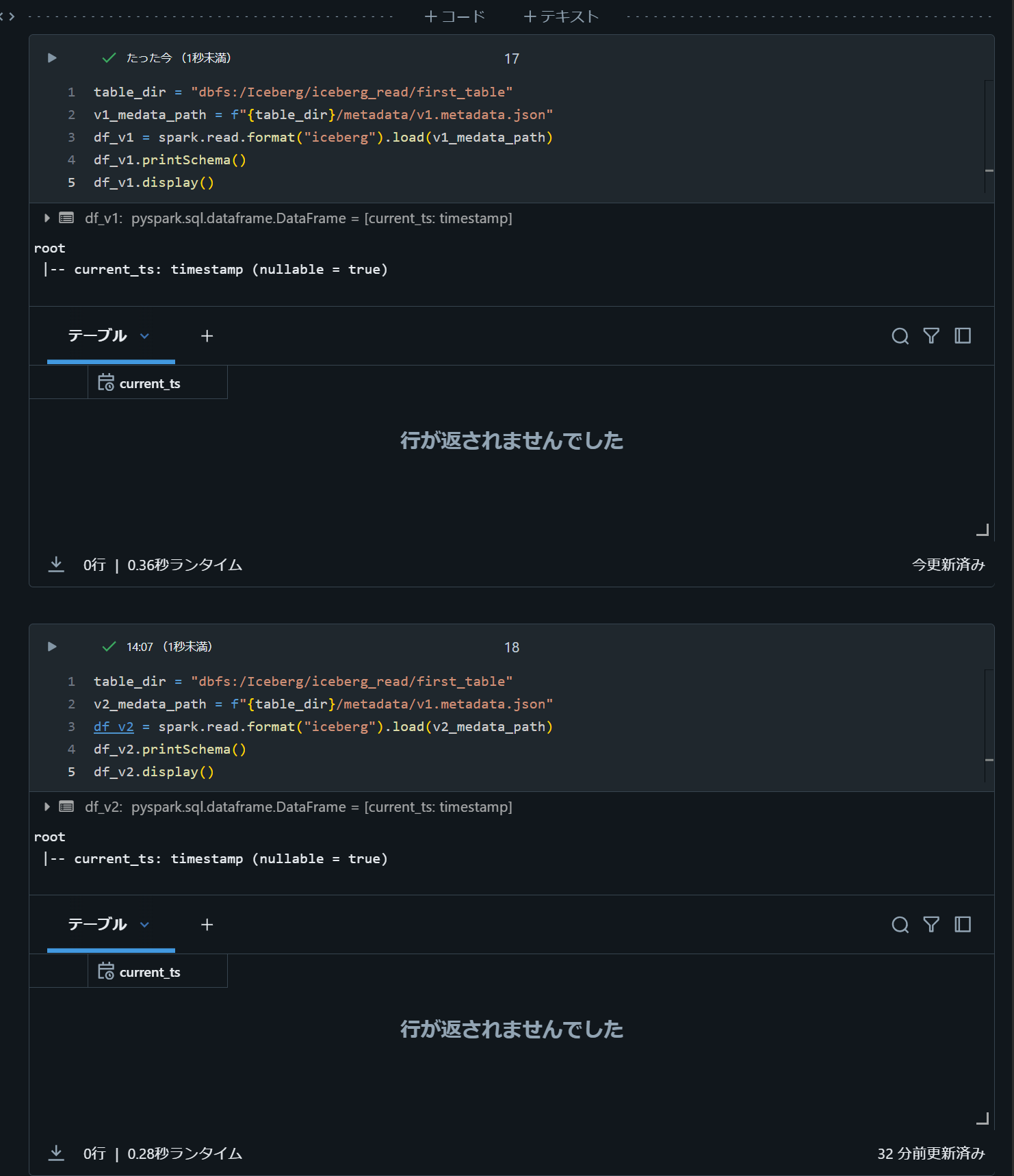
metadata file のパスを指定する方法
Databricks Runtime 12.2 にて下記のコードで動作を確認。
table_dir = "dbfs:/Iceberg/iceberg_read/first_table"
v1_medata_path = f"{table_dir}/metadata/v1.metadata.json"
df_v1 = spark.read.format("iceberg").load(v1_medata_path)
df_v1.printSchema()
df_v1.display()
table_dir = "dbfs:/Iceberg/iceberg_read/first_table"
v2_medata_path = f"{table_dir}/metadata/v1.metadata.json"
df_v2 = spark.read.format("iceberg").load(v2_medata_path)
df_v2.printSchema()
df_v2.display()
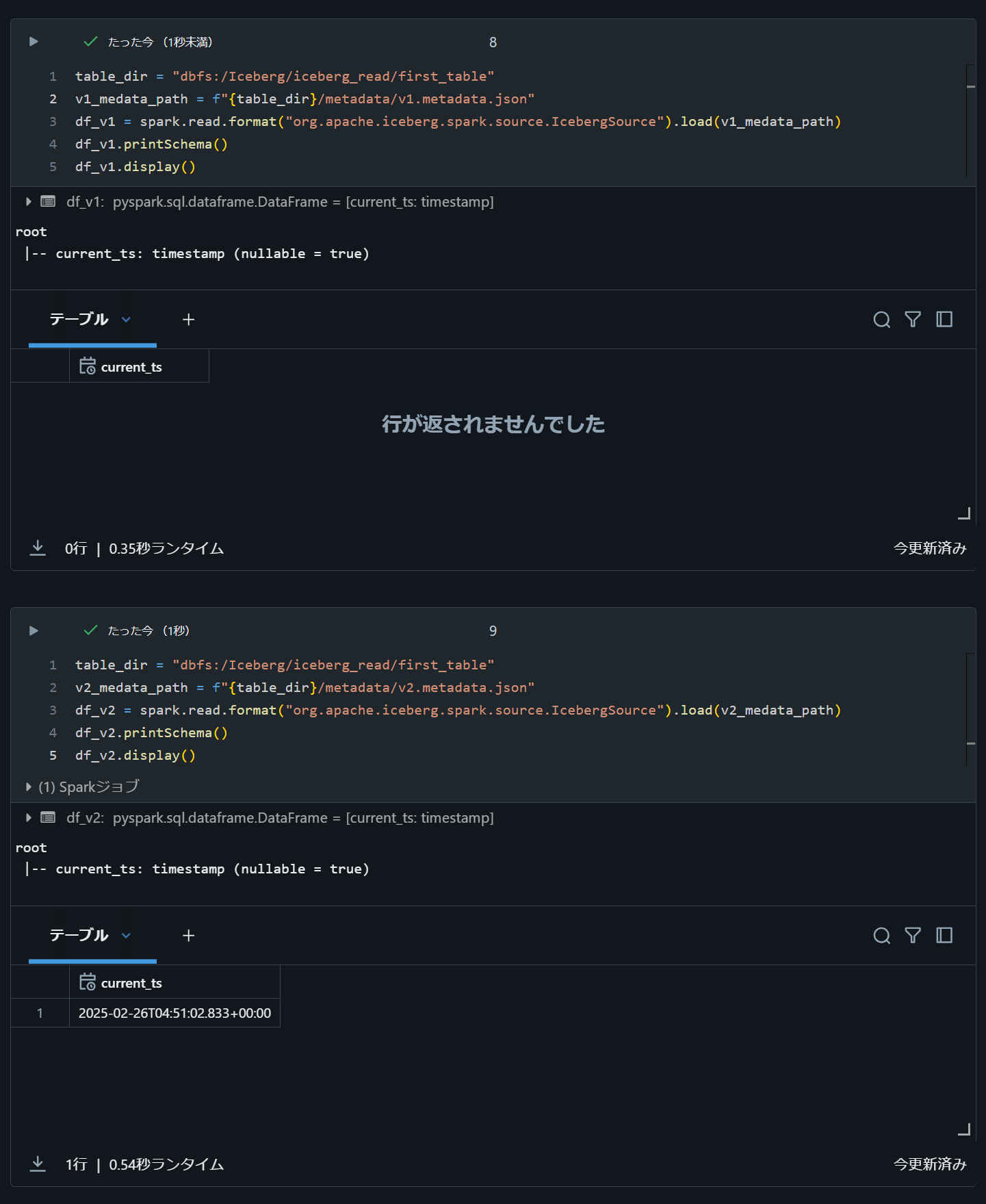
Databricks Runtime 13.3 ではsourceオプションを下記のように変更して動作することを確認。
table_dir = "dbfs:/Iceberg/iceberg_read/first_table"
v1_medata_path = f"{table_dir}/metadata/v1.metadata.json"
df_v1 = spark.read.format("org.apache.iceberg.spark.source.IcebergSource").load(v1_medata_path)
df_v1.printSchema()
df_v1.display()
table_dir = "dbfs:/Iceberg/iceberg_read/first_table"
v2_medata_path = f"{table_dir}/metadata/v2.metadata.json"
df_v2 = spark.read.format("org.apache.iceberg.spark.source.IcebergSource").load(v2_medata_path)
df_v2.printSchema()
df_v2.display()
実行確認できていない方法
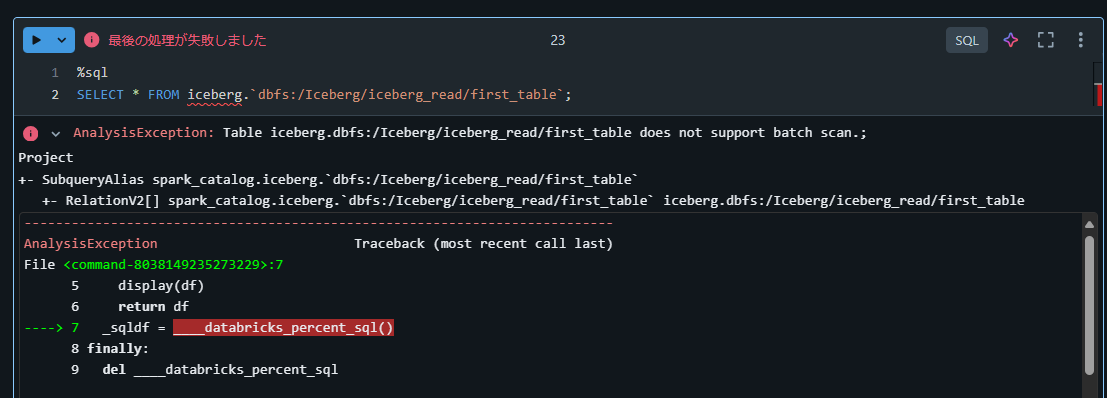
SQL にてicebergによりディレクトリを指定した方法
%sql
SELECT * FROM iceberg.`dbfs:/Iceberg/iceberg_read/first_table`;
AnalysisException: Table iceberg.dbfs:/Iceberg/iceberg_read/first_table does not support batch scan.;
Project
+- SubqueryAlias spark_catalog.iceberg.dbfs:/Iceberg/iceberg_read/first_table
+- RelationV2[] spark_catalog.iceberg.dbfs:/Iceberg/iceberg_read/first_tableiceberg.dbfs:/Iceberg/iceberg_read/first_table
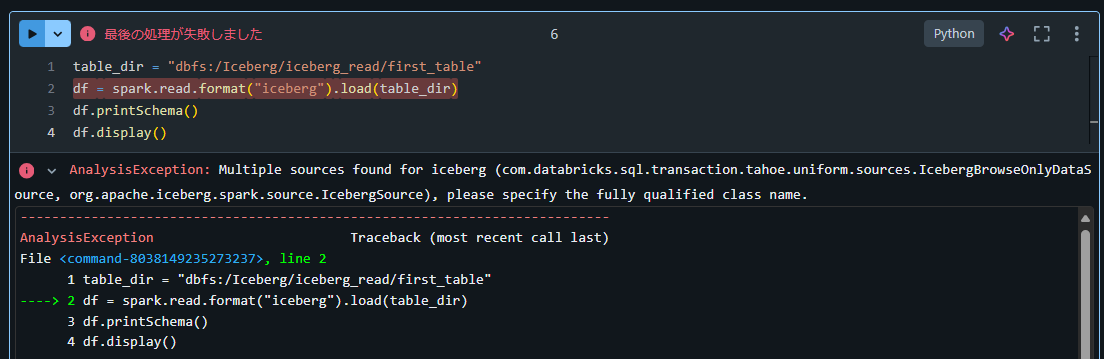
Databricks Runtime 13.3 上で PySpark にてformatオプションにicebergを指定する方法
table_dir = "dbfs:/Iceberg/iceberg_read/first_table"
df = spark.read.format("iceberg").load(table_dir)
df.printSchema()
df.display()
AnalysisException: Multiple sources found for iceberg (com.databricks.sql.transaction.tahoe.uniform.sources.IcebergBrowseOnlyDataSource, org.apache.iceberg.spark.source.IcebergSource), please specify the fully qualified class name.
Databricks Runtime 14.3上で PySpark にてformatオプションにorg.apache.iceberg.spark.source.IcebergSourceを指定する方法
df = spark.read.format("org.apache.iceberg.spark.source.IcebergSource").load(table_dir)
df.printSchema()
df.display()
UnsupportedOperationException: Byte-buffer read unsupported by com.databricks.common.filesystem.LokiAbfsInputStream
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3) (10.139.64.13 executor driver): java.lang.UnsupportedOperationException: Byte-buffer read unsupported by com.databricks.common.filesystem.LokiAbfsInputStream
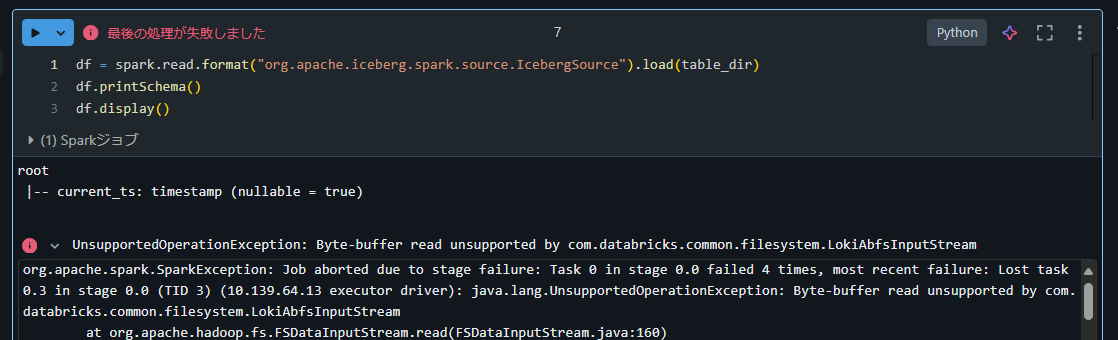
14.3 で上記エラーが発生することは Databricks による仕様であるため、 Databricks Runtime 16 以降を利用することで正常に動作することを確認。下記記事にて詳細を記述。