概要
この記事では、Databricks を使用して Azure SQL Database の CHAR 型カラムから末尾の空白スペースを自動的に削除する RTRIM 処理の方法を紹介します。Azure SQL Database では、CHAR 型カラムのデータが指定されたバイト数に満たない場合、残りのスペースが空白で埋められます。Databricks でのデータ操作では、これらの空白スペースはしばしば不要です。そのため、Azure SQL Database のテーブル定義情報を基に、不要なスペースを削除する RTRIM 処理を行う方法を説明します。
以前の記事 Databricks にて jdbc 経由で Azure SQL Database の CHAR 型のカラムに読み込みと書き込みを実施した際のスペースの取り扱いに関する調査結果 #Python - Qiita で触れた内容を踏まえています。
検証コードと実行結果
Azure SQL Database への接続情報を定義
以下のコードは、Azure SQL Database への接続情報を定義しています。サーバー名、データベース名、ユーザー名、パスワードを指定し、Databricks のシークレットスコープを使用して認証情報を安全に管理しています。
server = "ads-01" ## サーバー名
database = "ads-01" ## データベース名
username = dbutils.secrets.get(scope="qiita", key="sql_authentificate_user") ## Azure SQL DB のユーザー名
password = dbutils.secrets.get(scope="qiita", key="sql_authentificate_password") ## Azure SQL DB のパスワード

Azure SQL Dataabse にてテーブルを作成しデータを挿入
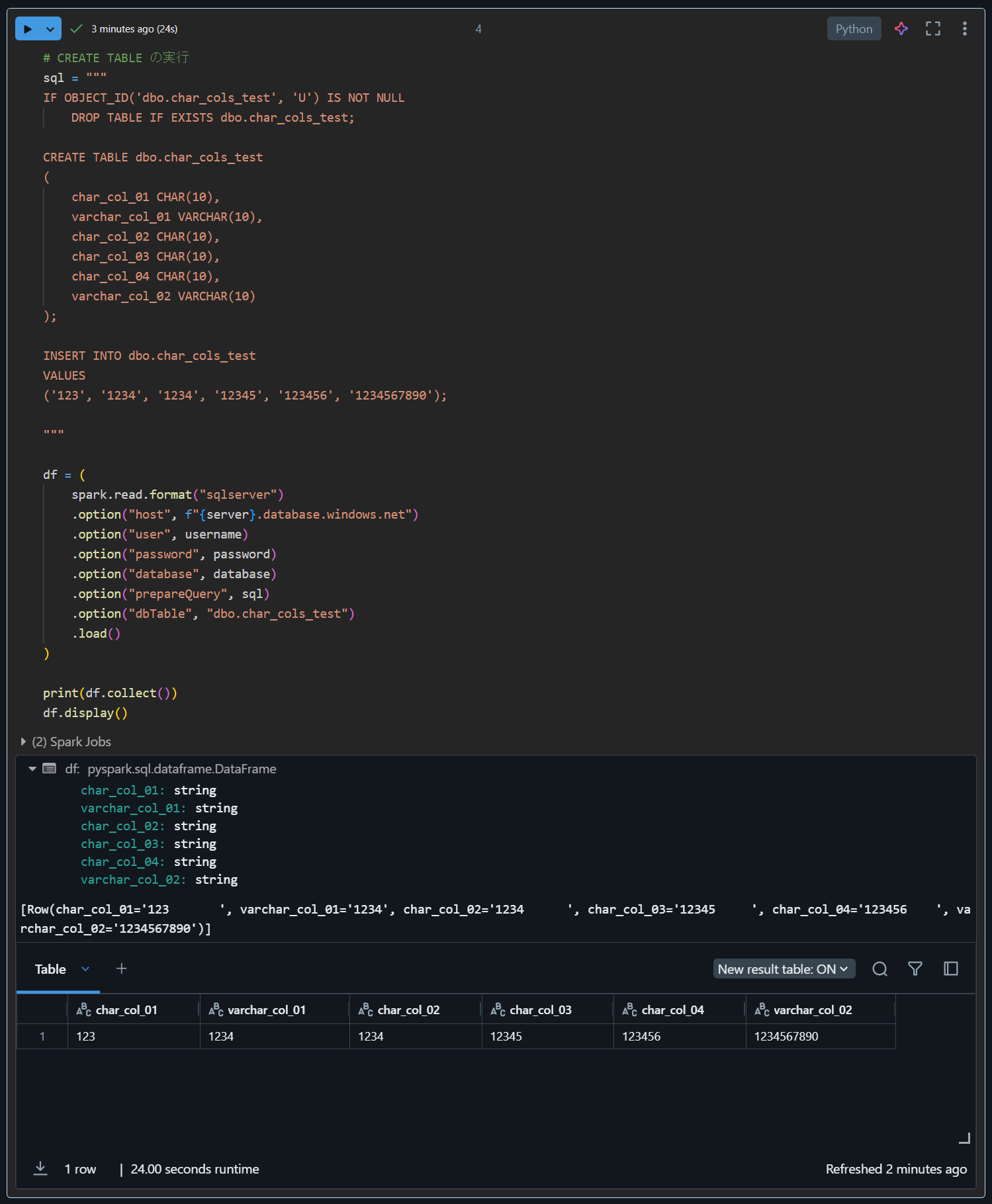
次のステップでは、Azure SQL Database 上にテーブルを作成し、テストデータを挿入しています。CHAR 型と VARCHAR 型のカラムを含むテーブルを定義し、サンプルデータを挿入後、Databricks でデータを読み込んで表示しています
# CREATE TABLE の実行
sql = """
IF OBJECT_ID('dbo.char_cols_test', 'U') IS NOT NULL
DROP TABLE IF EXISTS dbo.char_cols_test;
CREATE TABLE dbo.char_cols_test
(
char_col_01 CHAR(10),
varchar_col_01 VARCHAR(10),
char_col_02 CHAR(10),
char_col_03 CHAR(10),
char_col_04 CHAR(10),
varchar_col_02 VARCHAR(10)
);
INSERT INTO dbo.char_cols_test
VALUES
('123', '1234', '1234', '12345', '123456', '1234567890');
"""
df = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("prepareQuery", sql)
.option("dbTable", "dbo.char_cols_test")
.load()
)
print(df.collect())
df.display()
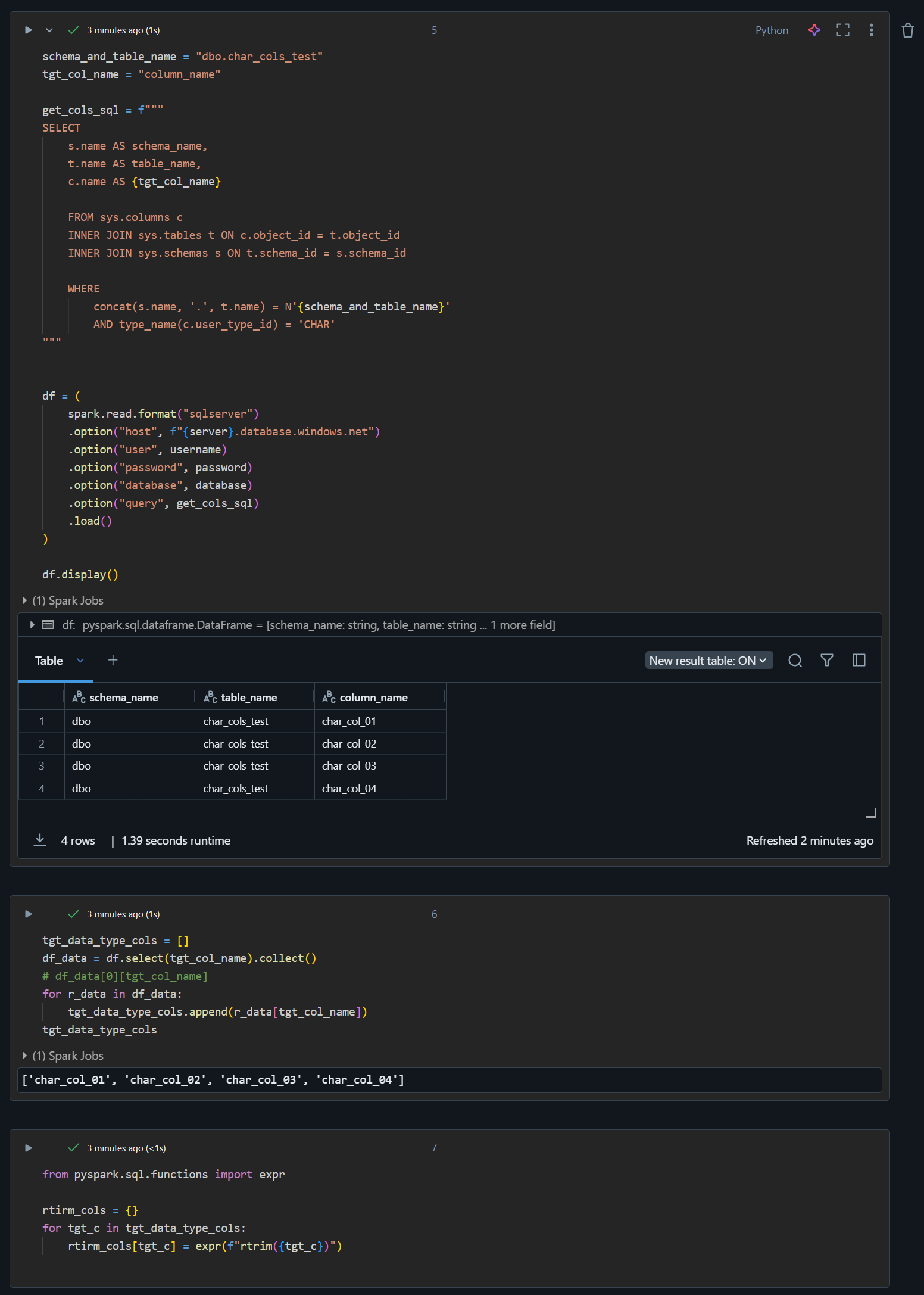
Azure SQL Database からテーブル定義の情報を取得して RTRIM 処理の変数を定義
このコードブロックでは、Azure SQL Database からテーブル定義の情報を取得し、RTRIM 処理を行うための変数を定義しています。CHAR 型のカラムのみを抽出し、それらのカラムに対して rtrim 関数を適用することで、末尾の空白を削除します。
schema_and_table_name = "dbo.char_cols_test"
tgt_col_name = "column_name"
get_cols_sql = f"""
SELECT
s.name AS schema_name,
t.name AS table_name,
c.name AS {tgt_col_name}
FROM sys.columns c
INNER JOIN sys.tables t ON c.object_id = t.object_id
INNER JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE
concat(s.name, '.', t.name) = N'{schema_and_table_name}'
AND type_name(c.user_type_id) = 'CHAR'
"""
df = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("query", get_cols_sql)
.load()
)
df.display()
tgt_data_type_cols = []
df_data = df.select(tgt_col_name).collect()
# df_data[0][tgt_col_name]
for r_data in df_data:
tgt_data_type_cols.append(r_data[tgt_col_name])
tgt_data_type_cols
from pyspark.sql.functions import expr
rtirm_cols = {}
for tgt_c in tgt_data_type_cols:
rtirm_cols[tgt_c] = expr(f"rtrim({tgt_c})")
Azure SQL Database からテーブルのデータを取得して RTRIM 処理を実行
以下のコードは、Azure SQL Database からテーブルのデータを取得し、定義した RTRIM 処理を実行しています。この処理により、CHAR 型カラムの末尾にある不要な空白スペースが削除されます。
src_df = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("dbTable", "dbo.char_cols_test")
.load()
)
src_df = src_df.withColumns(rtirm_cols)
print(src_df.collect())
src_df.display()

事後処理
DROP コマンドを使用して削除します。
# CREATE TABLE の実行
sql = """
IF OBJECT_ID('dbo.char_cols_test', 'U') IS NOT NULL
DROP TABLE IF EXISTS dbo.char_cols_test;
"""
df = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("prepareQuery", sql)
.option("dbTable", "(SELECT 1 AS test) src")
.load()
)
