概要
Azure Data Factory から Databricks Notebook アクティビティにより Databricks のノートブックをシングルノードのジョブクラスターで実行する方法を共有します。データエンジニアリングなどのパイプラインを構築する際に、マルチノードが必要でないような処理を行うことがよくあり、そういった場合にはコスト削減につながります。いくつかの制約があることに注意して利用するようにしてください。
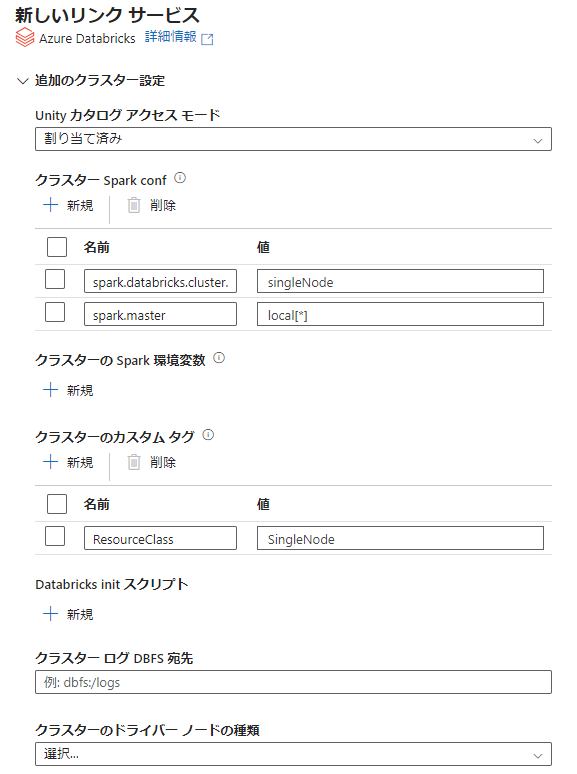
Azure Data Factory のリンクサービスにて、追加のクラスター設定を以下のように設定することで、シングルノードとなります。
| # | 分類 | 名前 | 値 |
|---|---|---|---|
| 1 | クラスター Spark conf | spark.databricks.cluster.profile | singleNode |
| 2 | クラスター Spark conf | spark.master | local[*] |
| 3 | クラスターのカスタム タグ | ResourceClass | SingleNode |
シングルノードとは
Databricksにおけるシングルノード(Single Node)クラスターは、すべての処理が1つのノード(VM)上で実行される特殊なクラスター構成です。大量のデータ処理には適していませんが、少量のデータを扱うジョブや単一ノードの機械学習ライブラリなど、分散処理を必要としないワークロードに適しています。Databricks の課金単位である DBU も低くなることから、コストの最適化が可能となります。

単一ノード コンピューティングは、少量のデータを使用するジョブや、単一ノードの機械学習ライブラリなどの非分散ワークロードを対象にしています。
引用元:コンピューティング構成リファレンス - Azure Databricks | Microsoft Learn
シングルノードを利用する際の制限事項が下記のドキュメントに記載されており、利用時には確認してください。
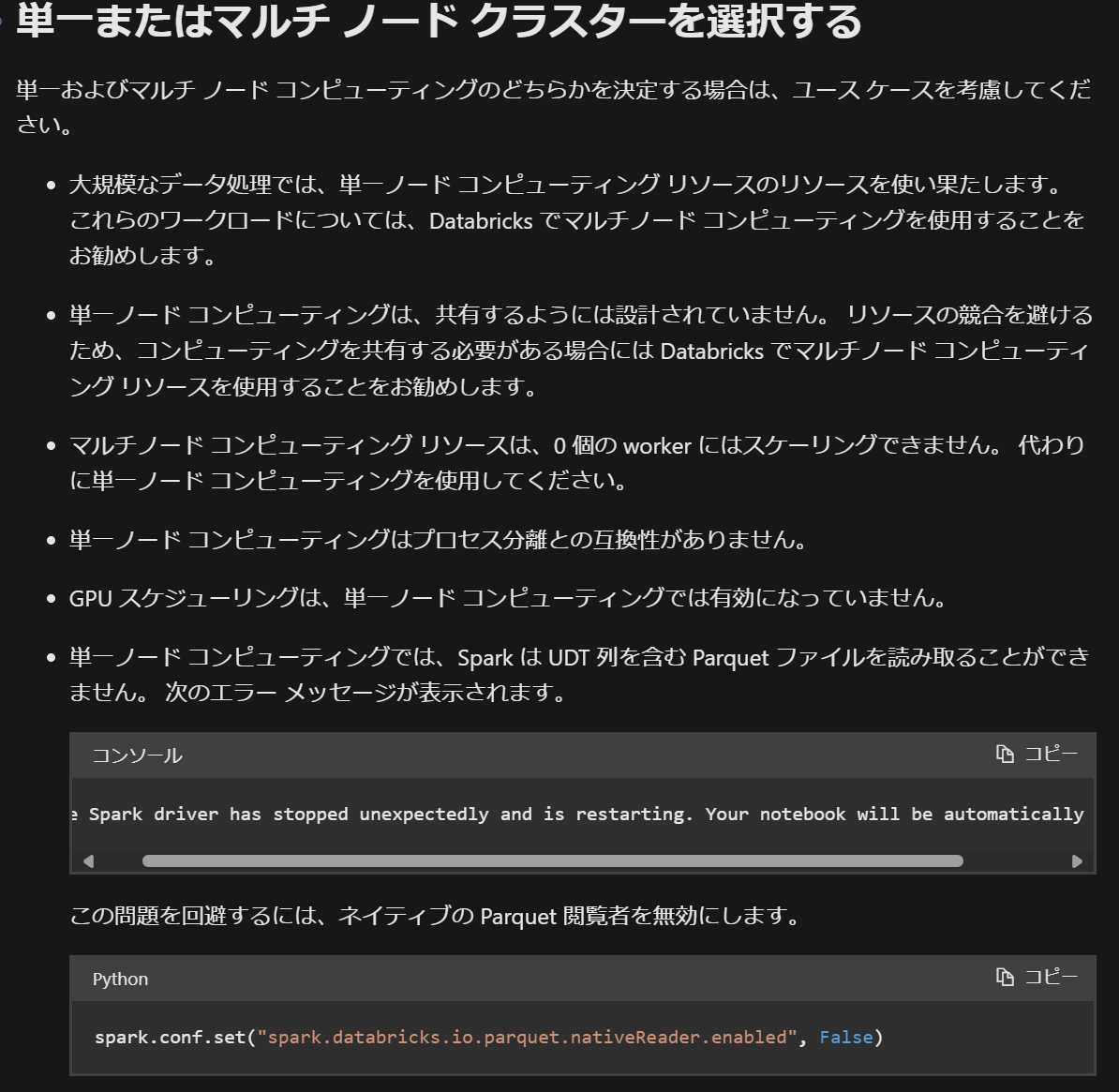
引用元:コンピューティング構成リファレンス - Azure Databricks | Microsoft Learn
実行手順
1. 事前準備
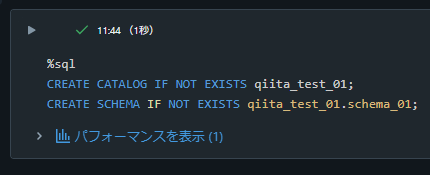
1-1. カタログとスキーマを作成
以下のSQLコマンドでカタログとスキーマを作成します。
%sql
CREATE CATALOG IF NOT EXISTS qiita_test_01;
CREATE SCHEMA IF NOT EXISTS qiita_test_01.schema_01;
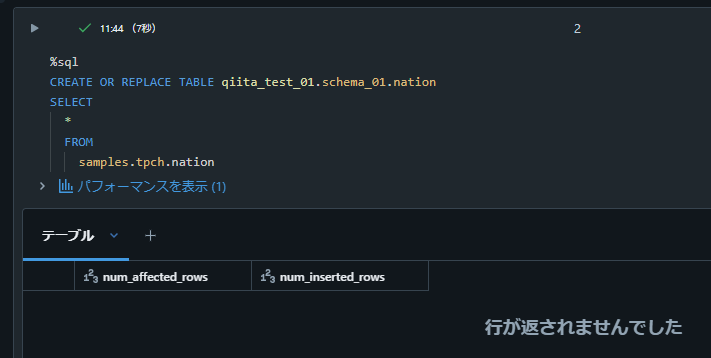
1-2. テーブルを作成
サンプルデータを使用してテーブルを作成します。
%sql
CREATE OR REPLACE TABLE qiita_test_01.schema_01.nation
SELECT
*
FROM
samples.tpch.nation
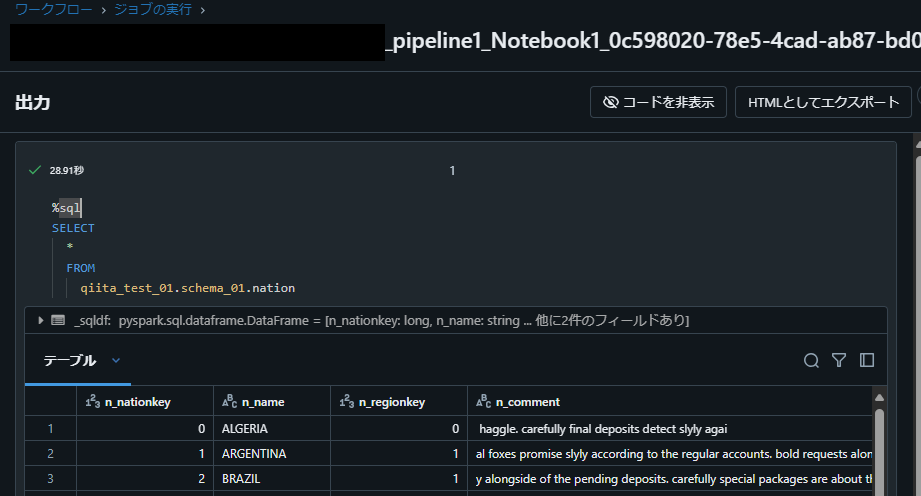
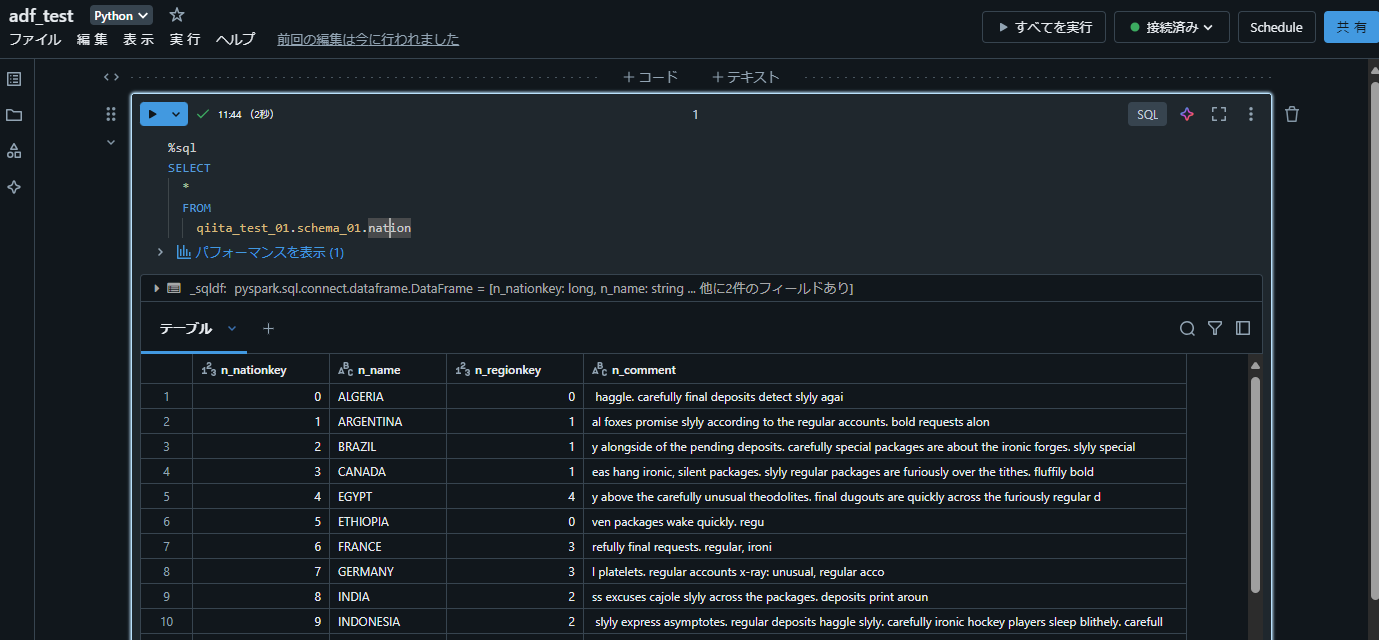
1-3. 実行するノートブックを作成
作成したテーブルからデータを SELECT するノートブックを作成します。
%sql
SELECT
*
FROM
qiita_test_01.schema_01.nation
2. Azure Data Factory にてパイプラインを作成
2-1. Databricks のリンクサービスを作成
追加のクラスター設定を以下のように設定します。
| # | 分類 | キー | 値 |
|---|---|---|---|
| 1 | クラスター Spark conf | spark.databricks.cluster.profile | singleNode |
| 2 | クラスター Spark conf | spark.master | local[*] |
| 3 | クラスターのカスタム タグ | ResourceClass | SingleNode |
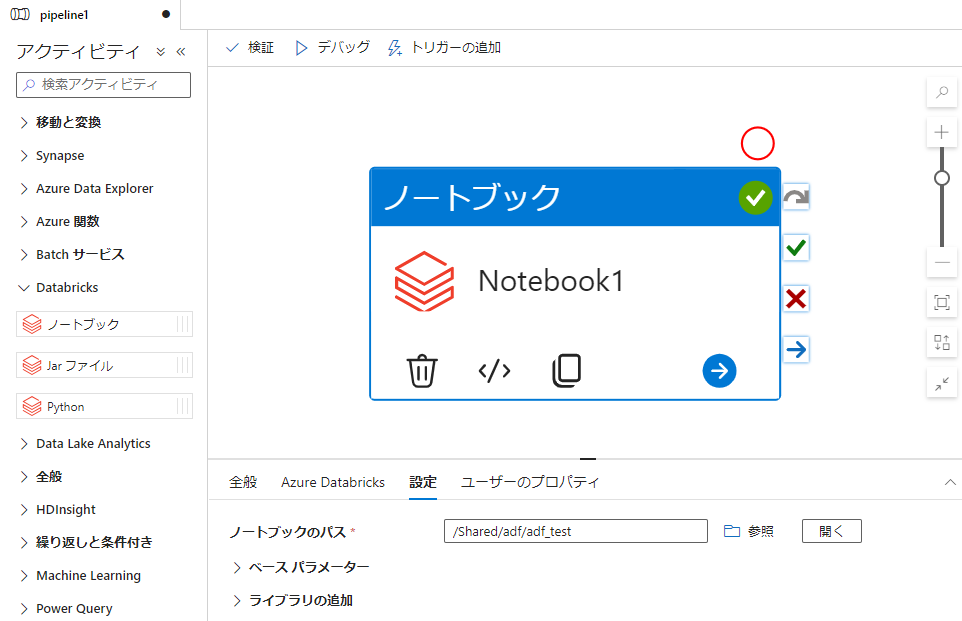
2-2. Databricks Notebook アクティビティをもつパイプラインを作成
3. Azure Data Factory から Databricks のノートブックを実行と確認
3-1. パイプラインを実行
パイプラインを実行してノートブックを起動します。
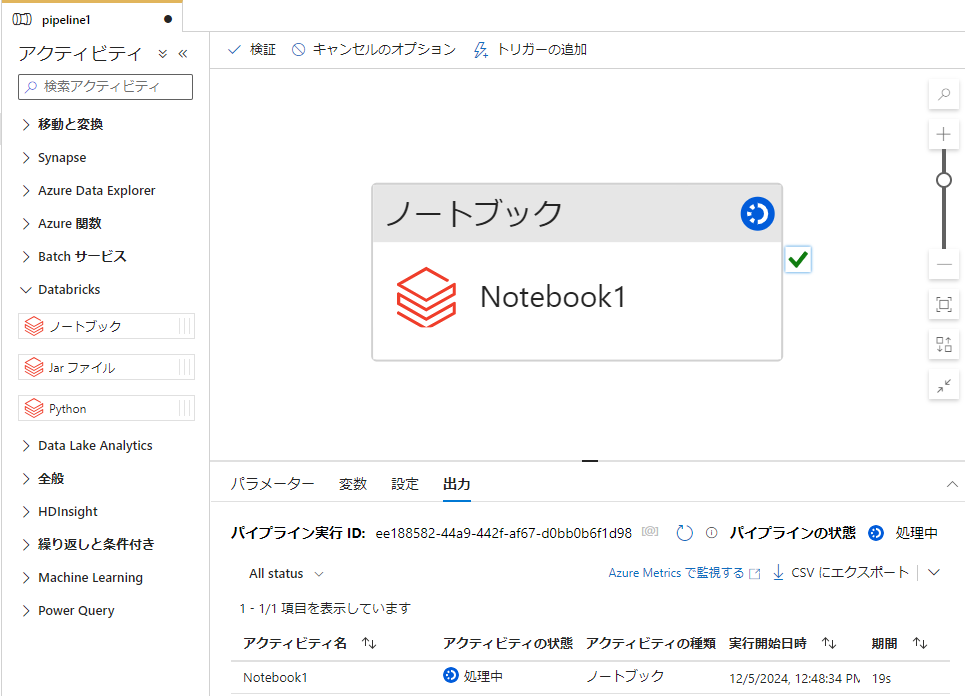
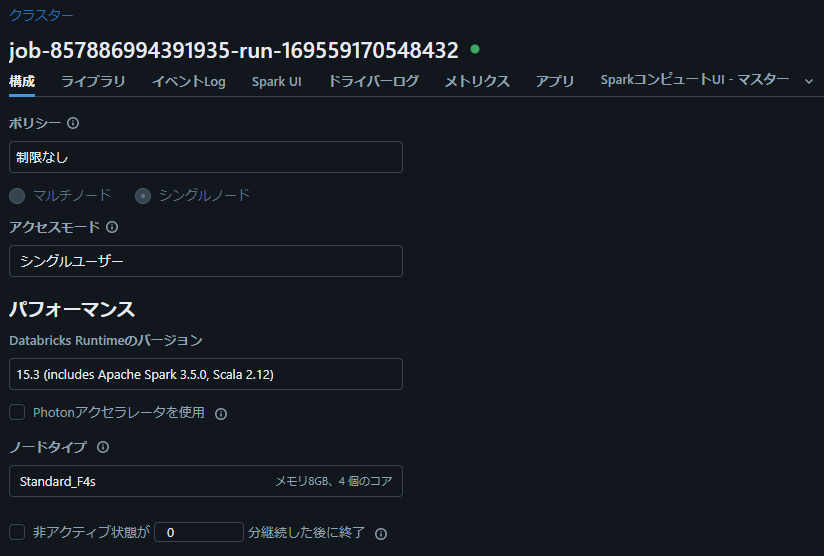
3-2. シングルノードのクラスターが作成されたことを確認
実行時にシングルノードのクラスターが作成されていることを確認します。
3-3. ノートブックが実行されたことを確認
ノートブックが正常に実行されたことを確認します。