概要
Databricks にて NULL 列を保持する Pandas データフレームから Spark データフレーム変換する際に、アクセスモード(シングルユーザーモードと共有アクセス モード)による挙動が異なる事象を確認したため共有します。2024年1月22日時点では、シングルユーザーモードでは void 型のカラムとしてスキーマを推論するのですが、共有アクセスモードではスキーマを推論できないというエラーとなってしまいました。
PySparkValueError: [CANNOT_DETERMINE_TYPE] Some of types cannot be determined after inferring.

本記事では、実行したコードとその結果、その対処方法を共有します。
実行したコードとその結果
1. シングルユーザーモードでの実行
1-1. 事前準備
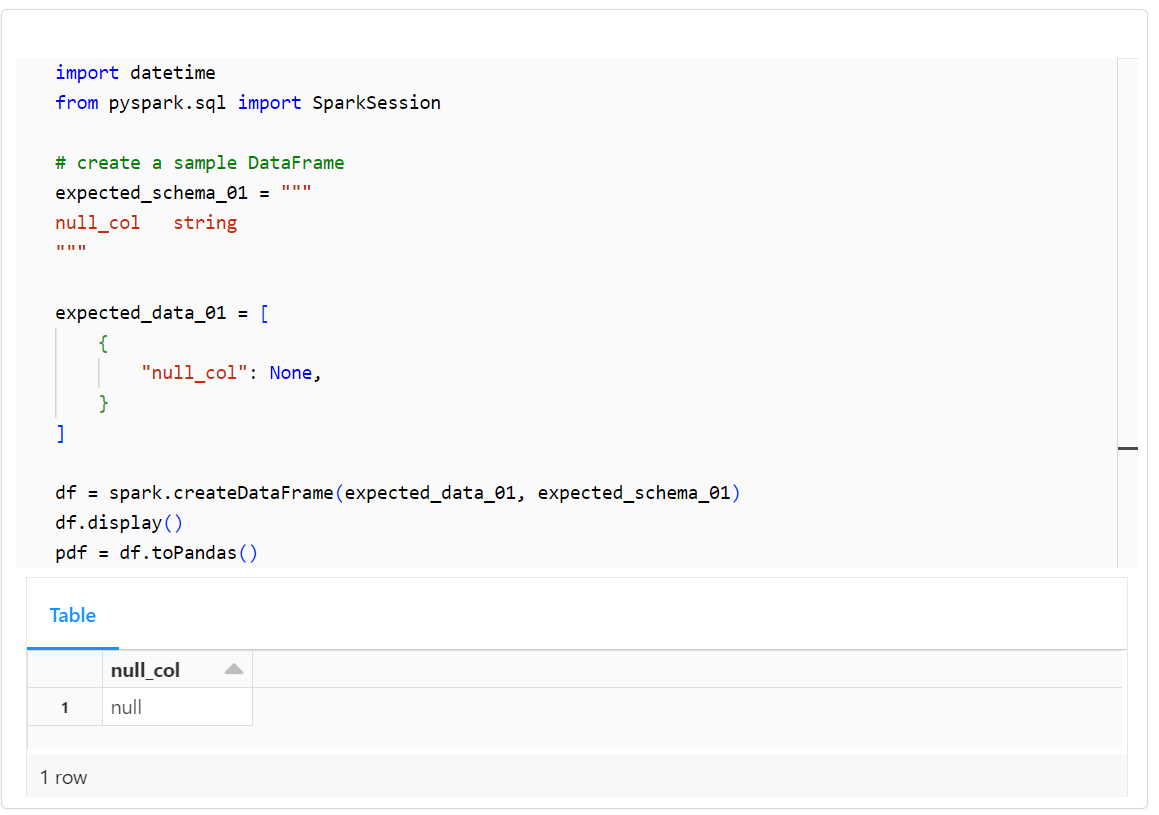
import datetime
from pyspark.sql import SparkSession
# create a sample DataFrame
expected_schema_01 = """
null_col string
"""
expected_data_01 = [
{
"null_col": None,
}
]
df = spark.createDataFrame(expected_data_01, expected_schema_01)
df.display()
pdf = df.toPandas()
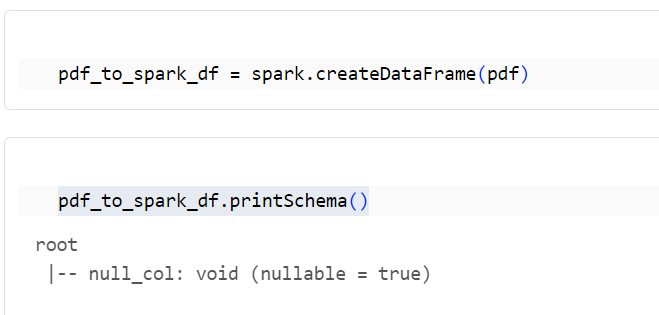
1-2. Pandas データフレームから Spark データフレームへの変換
pdf_to_spark_df = spark.createDataFrame(pdf)
pdf_to_spark_df.printSchema()
2. 共有モードでの実行
2-1. 事前準備
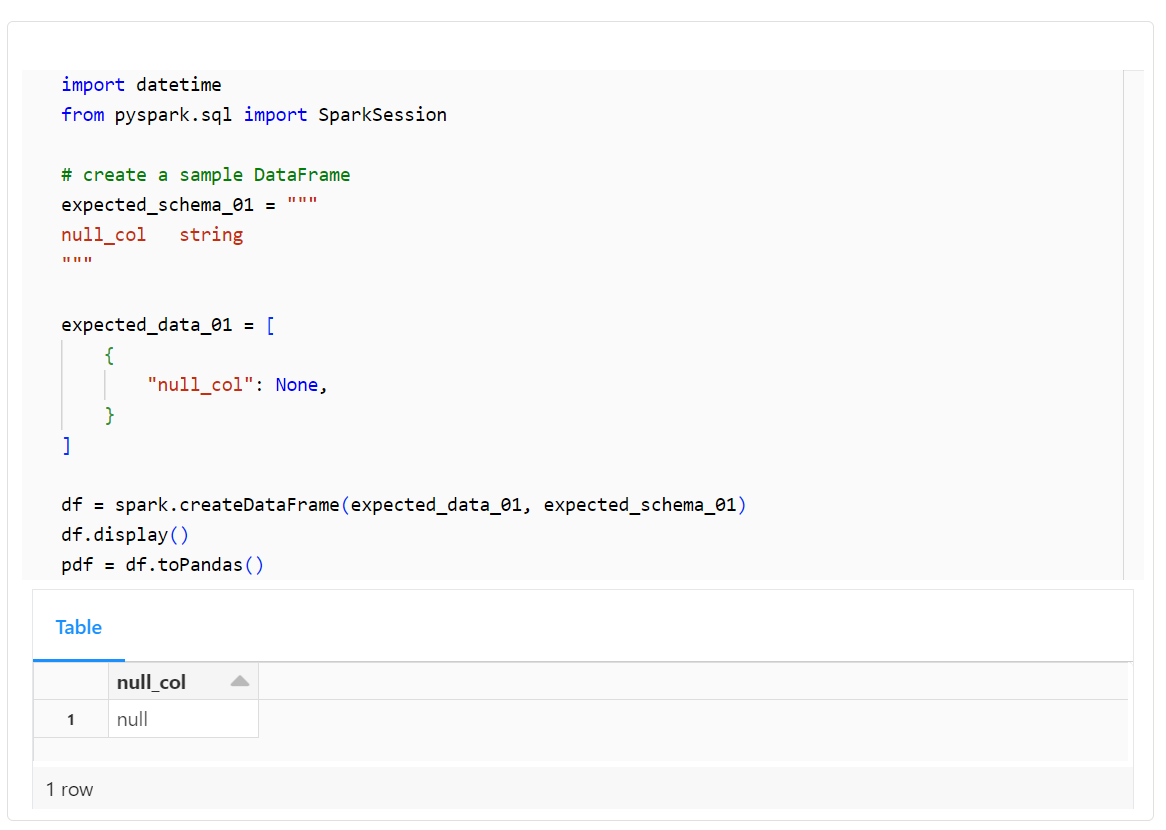
import datetime
from pyspark.sql import SparkSession
# create a sample DataFrame
expected_schema_01 = """
null_col string
"""
expected_data_01 = [
{
"null_col": None,
}
]
df = spark.createDataFrame(expected_data_01, expected_schema_01)
df.display()
pdf = df.toPandas()
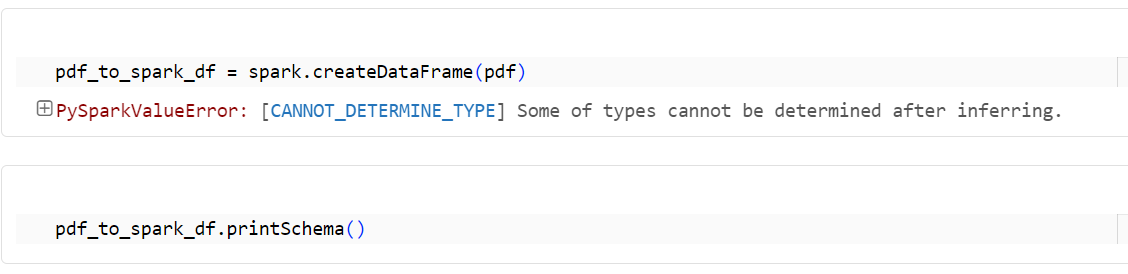
2-2. Pandas データフレームから Spark データフレームへの変換
pdf_to_spark_df = spark.createDataFrame(pdf)
pdf_to_spark_df.printSchema()
PySparkValueError: [CANNOT_DETERMINE_TYPE] Some of types cannot be determined after inferring.
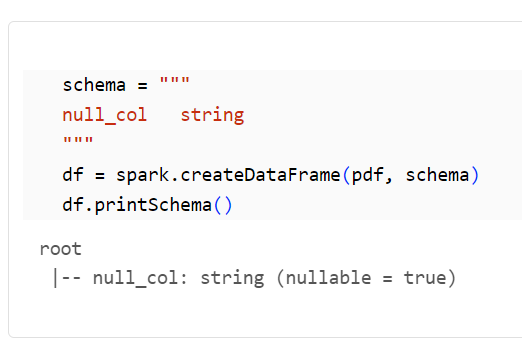
共有モードでの対処方法
スキーマを指定する方法
schema = """
null_col string
"""
df = spark.createDataFrame(pdf, schema)
df.printSchema()