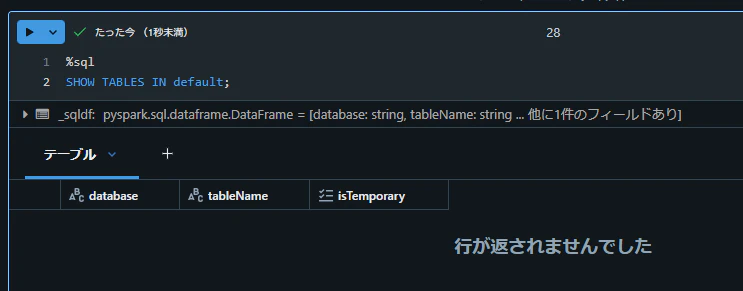
概要
Databricks にて Hadoop Catalog 管理下にある Apache Iceberg テーブルに対して DROP TABLE 文を実行したところ下記のエラーが発生したため、対応方法を共有します。
AnalysisException: [TABLE_OR_VIEW_NOT_FOUND] The table or view
spark_catalog.default.ICEBERG_TBL_5cannot be found. Verify the spelling and correctness of the schema and catalog.
If you did not qualify the name with a schema, verify the current_schema() output, or qualify the name with the correct schema and catalog.
To tolerate the error on drop use DROP VIEW IF EXISTS or DROP TABLE IF EXISTS.
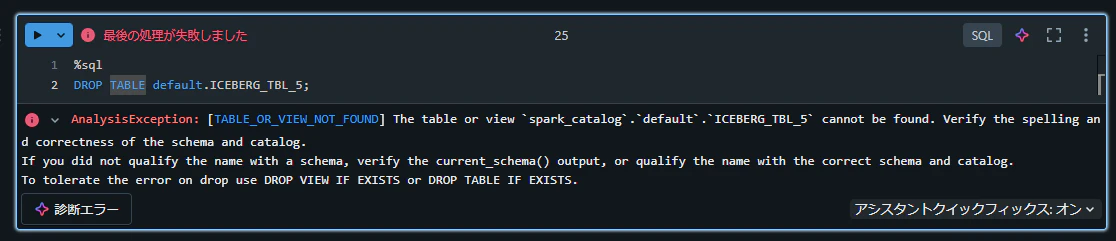
DROP 文が想定通りに動作していないようなので、テーブルのディレクトリを直接削除後に、テーブルの更新を実施することで対応しました。
# ディレクトリ、 Namespace、テーブル名を変数にセット
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
namespace_name = "default"
table_name = "ICEBERG_TBL_5"
# テーブルのディレクトリごと削除
table_dir = f"{wh_dir}/{namespace_name}/{table_name}"
dbutils.fs.rm(table_dir, True)
# Hadoop Catalog を更新
spark.sql(f"REFRESH TABLE {namespace_name}.{table_name}")
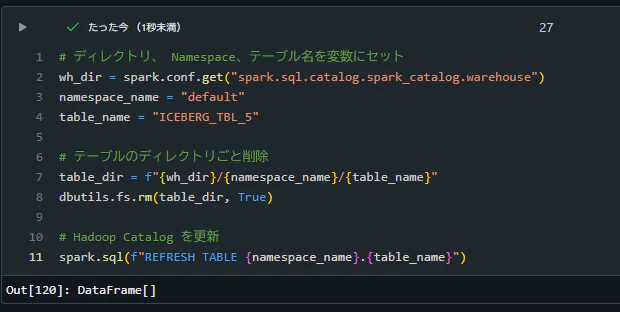
エラーの再現方法
テーブル作成後にテーブルの存在確認を実施
%sql
CREATE TABLE ICEBERG_TBL_5(ID INT,NAME STRING) USING ICEBERG;
SHOW TABLES IN default;
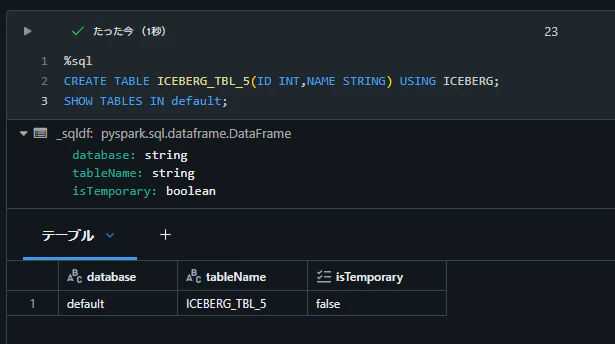
DROP TABLE 文がエラーとなることを確認
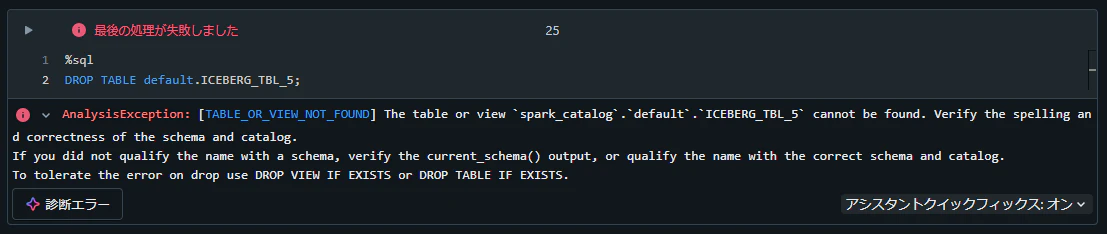
%sql
DROP TABLE default.ICEBERG_TBL_5;
AnalysisException: [TABLE_OR_VIEW_NOT_FOUND] The table or view
spark_catalog.default.ICEBERG_TBL_5cannot be found. Verify the spelling and correctness of the schema and catalog.
If you did not qualify the name with a schema, verify the current_schema() output, or qualify the name with the correct schema and catalog.
To tolerate the error on drop use DROP VIEW IF EXISTS or DROP TABLE IF EXISTS.
DROP TABLE PURGE 文がエラーとなることを確認
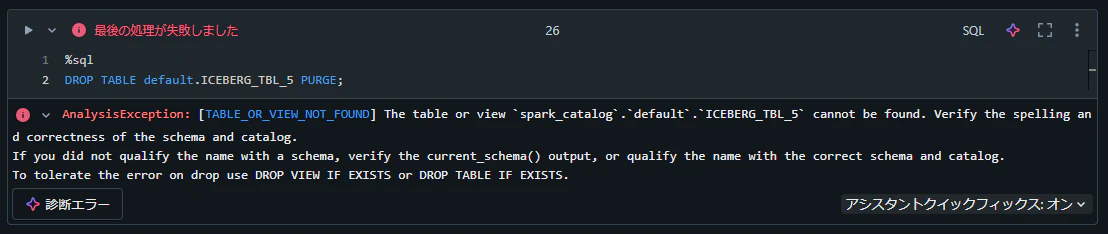
%sql
DROP TABLE default.ICEBERG_TBL_5 PURGE;
AnalysisException: [TABLE_OR_VIEW_NOT_FOUND] The table or view
spark_catalog.default.ICEBERG_TBL_5cannot be found. Verify the spelling and correctness of the schema and catalog.
If you did not qualify the name with a schema, verify the current_schema() output, or qualify the name with the correct schema and catalog.
To tolerate the error on drop use DROP VIEW IF EXISTS or DROP TABLE IF EXISTS.
エラーへの対応方法
テーブルのディレクトリを削除してカタログを更新
# ディレクトリ、 Namespace、テーブル名を変数にセット
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
namespace_name = "default"
table_name = "ICEBERG_TBL_5"
# テーブルのディレクトリごと削除
table_dir = f"{wh_dir}/{namespace_name}/{table_name}"
dbutils.fs.rm(table_dir, True)
# Hadoop Catalog を更新
spark.sql(f"REFRESH TABLE {namespace_name}.{table_name}")
テーブルがなくなったことを確認
%sql
SHOW TABLES IN default;