はじめに
最も気になるのはやはりどの程度のものができるのかだと思うので、まずはこちらをお聞きください。
このモデルは
- pre-trained model を使用した転移学習
- 約一時間の前処理済みのデータ
- WaveGlow (published model)
で学習、推論しています。
これから始める方の参考になるように私のやり方を紹介します。
Tacotron2についてはこちらが参考になります。
Tacotron2を用いた日本語TTS(Text-to-Speech)の研究・開発【まとめ】
※デモを既に動かしていることを前提としています。
用意するもの
音声ファイル
- 22050Hz 16bit モノラル wav
- 音声区間毎に分割
ノイズが多いもの、笑い声等のテキストにしづらいものは除外します。
長過ぎるものは学習時にメモリエラーが出ることがあります。私は10秒以内のもののみにしています。
テキスト
train.txt val.txt を作成
ljs_audio_text_val_filelist.txt を参考に
FILE PATH|TEXT
と表記していきます。
trainとvalのバランスは私は9:1にしています。音素バランスなどは考慮していません。
音素表記
TEXTは下記を参考に音素で表記していきます。
wiki 日本語の音素
声優統計コーパス 音素バランス文
使用できる文字はsymbols.pyの要素のみです。
このとき注意する点としてkoNnichiwaと入力するとTacotron2の内部では['k','o','n','n','i','c','h','i','w','a']と変換されます。
もし['k','o','N','n','i','ch','i','w','a']としたいのであれば{}で囲う必要があります。
ただし使用できるのはcmudict.pyのvalid_symbols内の要素のみです。
ですのでko{N}ni{CH}iwaとする必要があります。
またk o {N} n i {CH} i w aというような表記でも良いかとおもいます。私はkonnnichiwaとしています。
文末にEOSを追加
Model can not converge #254
学習時にattentionの収束が加速されるそうです。
例
私はこのようにしています。
/wav/0126.wav|na&tanndesukedo-.
/wav/0022.wav|biyo-inndake-yoyakuwasimasita.
/wav/0149.wav|tasikani,ari!.
/wav/0092.wav|sositara-.
/wav/0063.wav|teyu-ne.
/wav/0202.wav|donndonn,tama&tekunndesuyo.
設定
hparams.pyを編集
- iters_per_checkpoint
好きな数値に変更 - training_files
train.txtのpath - validation_files
val.txtのpath - text_cleaners
['basic_cleaners']に変更
transliteration_cleaners についてはこちらが参考になります。
Tacotron2系における日本語のunidecodeの不確かさ - batch_size
私は32にしています。issuesなどを見ると8~16くらいにしてる方が多いようです。GPUと相談して決めてください。
train.pyにexponential learning rate decayを追加
学習
pre-trained model を使用して学習していきます。
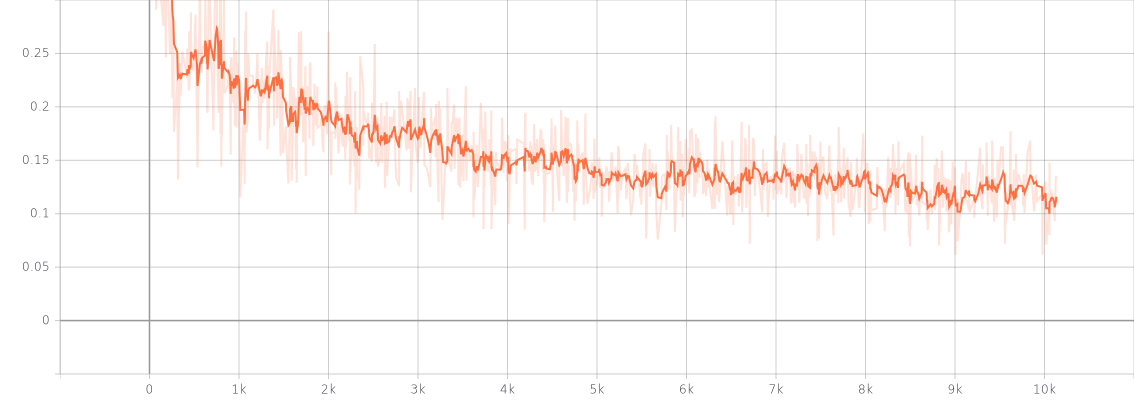
10k iterの結果です。Colab T4で約6時間半でした。
grad.norm
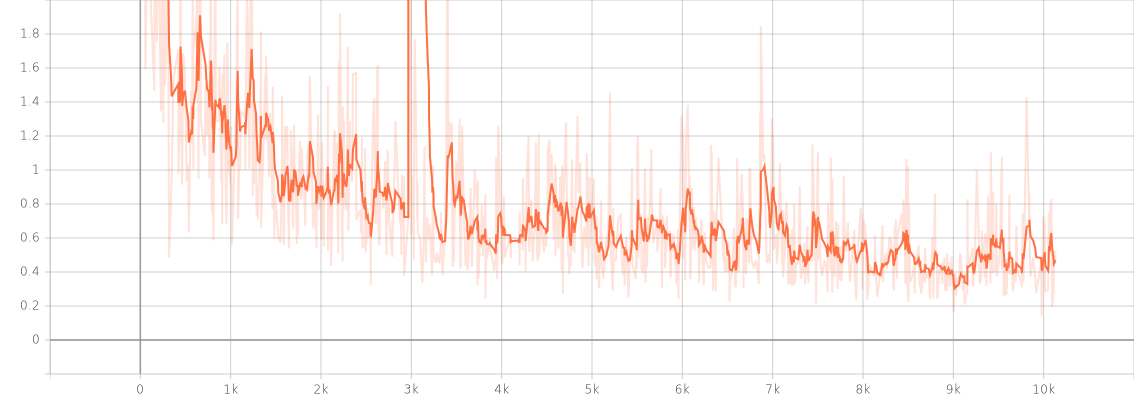
training.loss
推論
各checkpointの結果です。
sigma=1,denoiser未使用