はじめに
テキストデータを合成音声に変換する手法をTextToSpeech(TTS)といいます。
今回、TextToSpeechの学習をしたわけではないのですがテキストデータが日本語入力の場合、Tacotron2系のtransliteration_cleanersでは上手くローマ字に変換できなかった失敗談を記録しておきます。
Tacotron2系
NVIDIAのTextToSpeechは下記があります。今回、自分はflowtronについて試しましたが、ほかのversionでも日本語入力に対するunidecodeの失敗は共通のものと思われます。
https://github.com/NVIDIA/flowtron
https://github.com/NVIDIA/mellotron
https://github.com/NVIDIA/tacotron2
(ちなみにこれらの違いを自分は詳しくは分かっていません)
日本語入力の自分のデータで学習する場合
自分は学習データを用意できておらずモデル学習はしていないのですが、オリジナルデータを学習するには下記のようにファイルリストを自前で作成します。
...
data_config['training_files'] = 'filelists/train_filelist.txt'
data_config['validation_files'] = 'filelists/validation_filelist.txt'
data_config['text_cleaners'] = ['transliteration_cleaners']
train(n_gpus, rank, **train_config)
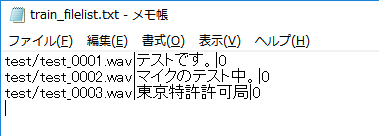
ここでファイルリストにはファイルの場所、音声のテキスト、speakerのIDを書く必要があるかと思います。複数の話者が混じった学習データではspeakerのIDが重複しないようにする必要があるかと思います。(多分)
def load_filepaths_and_text(filename, split="|"):
with open(filename, encoding='cp932') as f: #encodingをcp932に変更(windowsの場合)
...
def get_text(self, text):
print(text) # 追加
text = _clean_text(text, self.text_cleaners)
print(text) # 追加
def transliteration_cleaners(text):
'''Pipeline for non-English text that transliterates to ASCII.'''
text = convert_to_ascii(text)
text = lowercase(text)
text = collapse_whitespace(text)
return text
そして英語ではなく日本語を読む場合、エンコーディングをcp932にして、cleanersに['transliteration_cleaners']に変更する必要があるかと思います。
これは'''Pipeline for non-English text that transliterates to ASCII.'''**(英語以外のテキストをアスキーに音訳するパイプライン)**とあるため日本語入力ならこれが妥当かと一瞬思われるかと思います。
自分はそう思いました。
しかし、変換は上手く行かない
def get_textに追加したprint()文の出力結果です。
平仮名、片仮名の「テストです。」は上手く変換できているのが確認できました。一方、漢字は中国語の音韻に変換されてしまいました。
Epoch: 0
テストです。
tesutodesu.
東京特許許可局
dong jing te xu xu ke ju
マイクのテスト中。
maikunotesutozhong .
平仮名、片仮名だけならいいかといえばそうでもない
そもそも、日本語(ユニコード)からアスキーへの変換にはunidecodeというライブラリが使われています。
from unidecode import unidecode
def convert_to_ascii(text):
return unidecode(text)
このunidecodeの変換をいくつか確認しました。
# coding: cp932
from unidecode import unidecode
text1 = 'あいうえお'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'アイウエオ'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = '相性'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = '相談'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'こうてい'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'こぅてい'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'こおてい'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'こーてい'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'こ~てい'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'こ-てい'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'キャット'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'キヤツト'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'かんい'
text2 = unidecode(text1)
print(text1)
print(text2)
text1 = 'かに'
text2 = unidecode(text1)
print(text1)
print(text2)
......
あいうえお
aiueo
アイウエオ
aiueo
相性
Xiang Xing
相談
Xiang Tan
こうてい
koutei
こぅてい
koutei
こおてい
kootei
こーてい
kotei
こ~てい
ko~tei
こ-てい
ko-tei
キャット
kiyatsuto
キヤツト
kiyatsuto
かんい
kani
かに
kani
・漢字が中国語に変換される
・「ぁぃぅぇぉゃゅょっ」が「あいうえおやゆよつ」と同じ
・「ー」が認識されない。
・「かんい」と「かに」の変換が同じ
など多くに問題があります。
従ってunidecodeは日本語の変換にはそもそも向いていません。
pykakasiの例
pykakasiを使った場合は以下の様になりました。unidecodeの不完全な変換が改善されています。
また、.setMode('s', True)では自動で単語ごとにスペースを入れてくれます。
# coding: cp932
from pykakasi import kakasi
kakasi = kakasi()
kakasi.setMode('H', 'a')
kakasi.setMode('K', 'a')
kakasi.setMode('J', 'a')
kakasi.setMode('E', 'a')
kakasi.setMode('s', True)
conv = kakasi.getConverter()
text = 'あいうえお、とアイウエオ。'
print(conv.do(text))
text = '相性と相談'
print(conv.do(text))
text = 'キャットとキヤツト'
print(conv.do(text))
text = 'ファイルとフアイル'
print(conv.do(text))
text = 'こうてい と こぅてい と こおてい と こーてい と こ~てい'
print(conv.do(text))
text = '東京特許許可局'
print(conv.do(text))
text = '簡易とカニ'
print(conv.do(text))
aiueo, to aiueo.
aishou to soudan
kyatto to kiyatsuto
fairu to fuairu
koutei to koutei to kootei to kootei to ko ~ tei
toukyou tokkyo kyoka kyoku
kan'i to kani
pyopenjtalkの例
OpenJTalkのインストールが必要?
この場合は単語ごとではなく音節ごとに分解されるようです。
単語で分けるのとどちらが良いのかは分かりません(学習モデル次第かも?)
import pyopenjtalk
print(pyopenjtalk.g2p("こんにちは"))
'k o N n i ch i w a'
まとめ
Tacotron2系のunidecodeは日本語入力に向いてなく、**transliteration_cleanersを使うのは間違いです。**従って学習データを日本語にする場合、text/cleaners.pyにjapanease_cleanersを自作するとよいです。
(それか予めローマ字に変換した学習データを用意するか)