佐伯です。
46歳。最近、東京の台東区から京都へ引っ越しました。
元々は音楽業界にいましたが、28歳からチームラボでインフラやアーキテクトを10年ほど経験。
直近はHexabaseという会社でAIチームのPdMをしていましたが、資金が尽きてチーム解散という憂き目に遭いました。
現在は心機一転、株式会社PKSHA Infinityで、DevelopDivisionのLLM検証チームに所属しています。

そこで私に課せられたミッションは3つ。
1つ目は「最新技術の追跡」、2つ目は「プロンプトエンジニアリングの属人化解消」。
そして3つ目が
「生成されるアウトプットの評価の難しさ、これをなんとかしろ」
という課題です。
私はこの3番目の課題に真っ先に取り組むことにしました。

そもそも、世の中ではAIの出力の品質をどう計測しているのでしょうか。
一般的には、
- Benchmark(定量的評価)
- UX Feedback(感覚的評価)
- Battle Arena(比較評価)
の3つしかありません。

まずBenchmarkですが、MMLUやGSM8Kといった有名なテストセットがあります。
しかしこれらは、明確な正解がある「一問一答形式」の試験問題集に過ぎません。
学校のテストで満点が取れても仕事ができるとは限らないのと同じで、実務で役立つかは別問題です。
なぜなら仕事には正解がないからです。
つまり良いベンチ出せるAIモデルがビジネス的に正解とは全く言えない。
それに、モデルの進化が早すぎてスコアが飽和(頭打ち)しており、もはや差別化要因になりにくくなっています。

そもそもBenchmarkはモデルを作るプロバイダが気にすべきことであって、我々ユーザー企業がやってもあまり意味がありません。
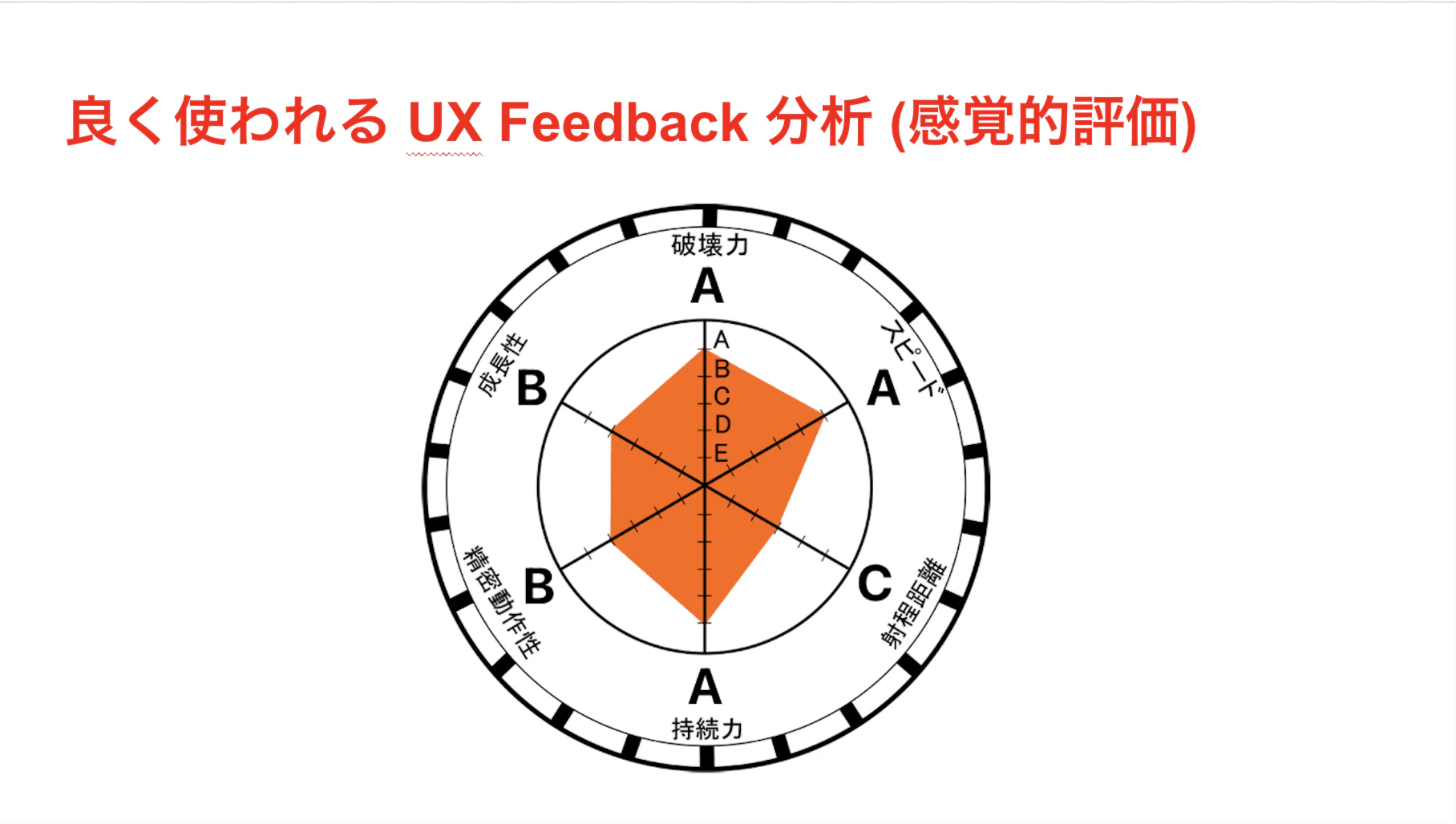
さて、次にAIの出力をどう評価するかという話で、現場で一番よく見かけるのがこれです。
「UX Feedback 分析」、いわゆる感覚的評価ですね。
このレーダーチャート、見てください。かっこいいですよね。
「破壊力 A」とか「スピード B」とか。
まるで某・奇妙な冒険のスタンドパラメータみたいで、資料としての見栄えは最高です。
「あぁ、分析してる感あるな」ってなりますよね。

でも結論から言います。
これ、ダメです。
エンジニアリングの観点から言うと、この評価手法には何の意味もありません。
今すぐやめてください。

「点数をつける分析」はダメです。
なぜなら、定性評価というのは結局のところ、「ユーザーのお気持ち」を「数字の皮」で包んでいるだけだからです。そこに統計的な信頼性も再現性もありません。
同じ出力でも、明日聞けば「82点」になるかもしれないし、「厳しめに評価して」と言えば中身が同じでも「60点」になるかもしれない。これではエンジニアリングの指標になりません。

じゃあ、人間による評価は全部ゴミなのか? というと、唯一許される例外があります。
それがこの定量的な UX Feedbackです。
先ほどのような「80点」とか「70点」みたいな、個人のグラデーションが入る曖昧な評価は一切禁止します。
その代わりに何をするか。
「TRUE(良い)」か「FALSE(悪い)」か。
あるいは右か左か。
この「二択(Binary)」まで選択肢を削ぎ落とし、強制的に白黒つけさせる投票だけは、エンジニアリングの指標として機能します。
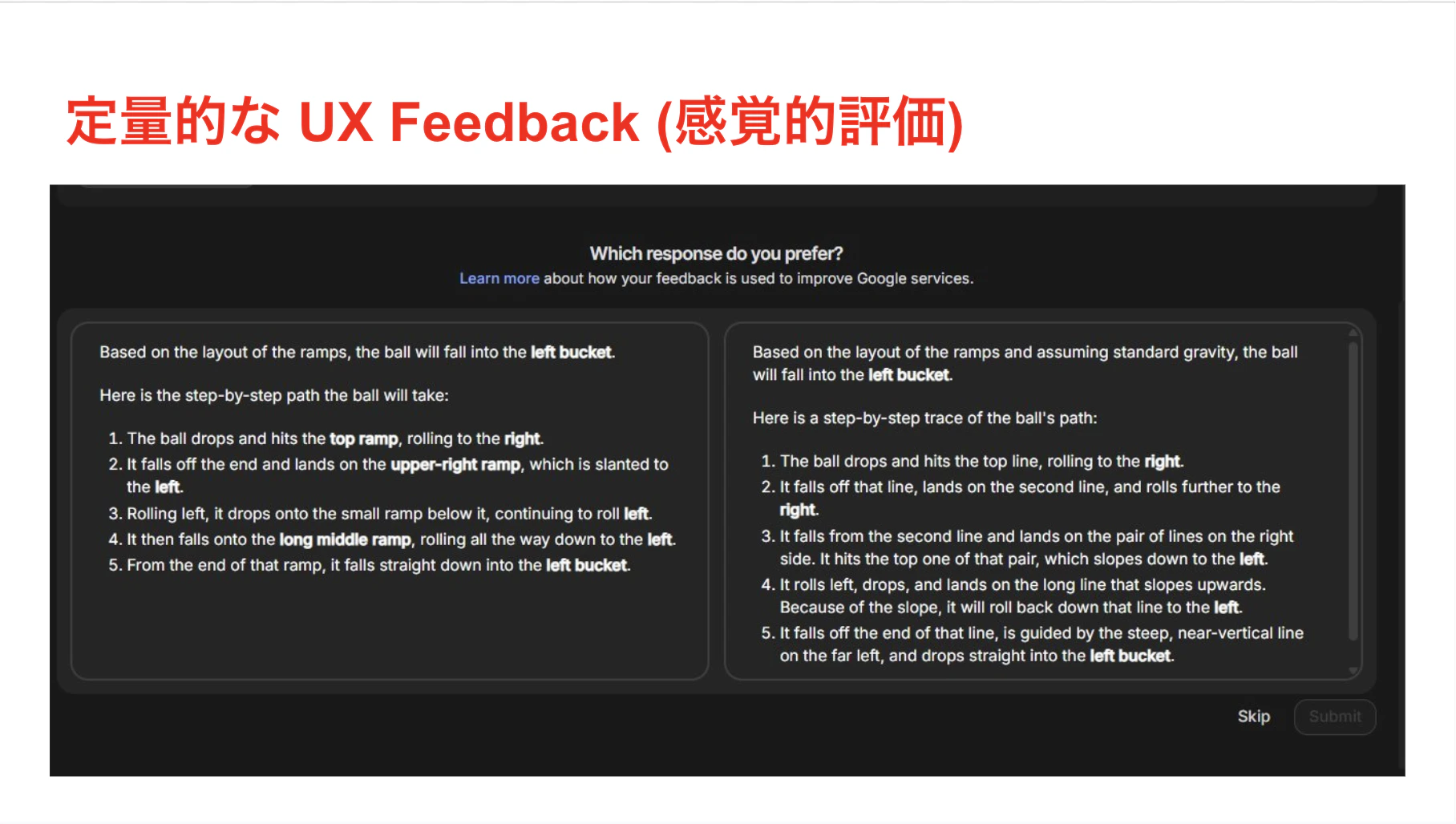
具体例を見たほうが早いですね。次のスライドです。
これ、皆さんも親の顔より見たことありますよね。
ChatGPTやGeminiを使っていると出てくる、「どっちの回答が優れていますか?」というやつです。
これは確かに「ユーザーのお気持ち」を聞いています。
でも、なぜこれが成立するかというと、GoogleやOpenAIには「数億人のユーザー」がいるからです。
一人の人間が「右が好き」と言ってもそれはただの感想ですが、100万人が「右が好き」と言えば、それは「統計的な正解」になります。「数の暴力」で、個人の主観というノイズをねじ伏せることができる場合のみ有効なんです。
裏を返せば、我々が社内で使う業務アプリの開発でこれをやっても、せいぜい10票か20票しか集まりません。
そんな少ないサンプル数で多数決をとっても、統計的には何の意味もない。
つまり、このやり方はプラットフォーマーの特権であって、我々一般企業の現場でそのまま真似できるものじゃないんです。

既存のテストデータもダメ。
人間の感覚評価もダメ。
数の暴力も使えない。
じゃあ、我々はどうやって評価をすればいいのか?
その答えが、この「LLM-as-a-Judge」です。
読んで字のごとく。
「AIが生成したアウトプットを、別のAI(LLM)に『裁判官』として評価させる」。
これです。
「AIの書いたものをAIにチェックさせるなんて、泥棒に鍵を預けるようなものじゃないか?」
直感的にはそう思うかもしれません。
しかし、人間のように「疲れない」、人間のように「気分で点数を変えない」。
そして何より、「24時間365日、文句も言わずに大量のデータを裁いてくれる」。
この圧倒的な「スケーラビリティ」こそが、LLM-as-a-Judgeの真価です。
ただし、これには「絶対に守らなければならない作法」があります。
次のスライドで、その具体的なやり方を見ていきましょう。

では、具体的にどうやってAIを「裁判官」にするのか。
ここが、今日の話で一番持ち帰ってほしい「技術」の核心部分です。
まず、絶対にやってはいけないのが、スライド上段のやり方です。
「この要約は何点ですか?」「80点です、理由は...」
これ、さっき否定した「人間のお気持ち評価」と全く同じですよね。
AIにこれをやらせても、結局はサイコロを振って適当な数字を出させているだけです。
これではエンジニアリングになりません。
じゃあどうするか。
評価という行為を、感想から事実確認(ファクトチェック)へと解体するんです。
下段を見てください。
「良い要約か?」なんて曖昧なことは聞きません。
代わりに、極限まで具体的なチェックリストを渡して、Yes(1) か No(0) の二択だけで答えさせます。
「期限の日付は含まれているか?」→ Yes
「担当者の名前はあるか?」→ No
「嘘(ハルシネーション)は混ざってないか?」→ Yes
このように、AIに採点ではなく検品をさせるんです。
白か黒か、1か0か。ここから「曖昧さ」を徹底的に排除します。
そして、ここからが重要なんですが、これを1回やって満足しないでください。
この厳格な検品を、n=100以上の大量のデータに対して自動でぶん回すんです。
100以上でなければいけない理由は、単純に%と言う単位の解像度が、100以上からでないとまともに機能しないからです
そうして初めて、
「このプロンプトは、平均85%の確率で正しく日付を抽出できる」
「でも、まだバラつきがあるな」
という「統計的な事実」としての数値が手に入ります。
ここまでやって初めて、我々は「プロンプトの性能」を科学的に議論できるようになるんです。

さて、最後のトピックである「Battle Arena(比較評価)」についてお話しします。ここが、多くの現場で最も誤解されているポイントです。

まず、スライドにある「間違ったArenaの使い方」を見てください。
「俺の最強プロンプト」vs「私の超高品質プロンプト」。
これ、やってしまいがちなんですが、実はこれ、「闇鍋の味比べ」と同じなんです。
どちらも大量の指示やテクニック(調味料)を投入していて、結果的にAが勝ったとしても、「何が効いて勝ったのか」が全く分かりません。たまたまモデルの機嫌が良かっただけかもしれない。これはエンジニアリングではなく、単なる「作品の品評会」です。

ここで、少し視点を変えて新薬の開発(治験)をイメージしてください。
皆さんが製薬会社の研究員だとして、新しい薬(プロンプト)の効果を証明したいとします。その時、ライバル会社の薬と比較する前に、絶対にやらなければならないことがありますよね?
そう、偽薬(プラセボ)との比較です。
何も成分が入っていない薬(ただの水)を飲んだグループと、新薬を飲んだグループ。
この2つを比べて初めて、「薬効成分(=エンジニアリング)」の効果が証明されます。もし、両方のグループで治癒率が変わらなければ、その薬はただの気休めであり、開発コストの無駄です。
これをLLMの現場に戻しましょう。
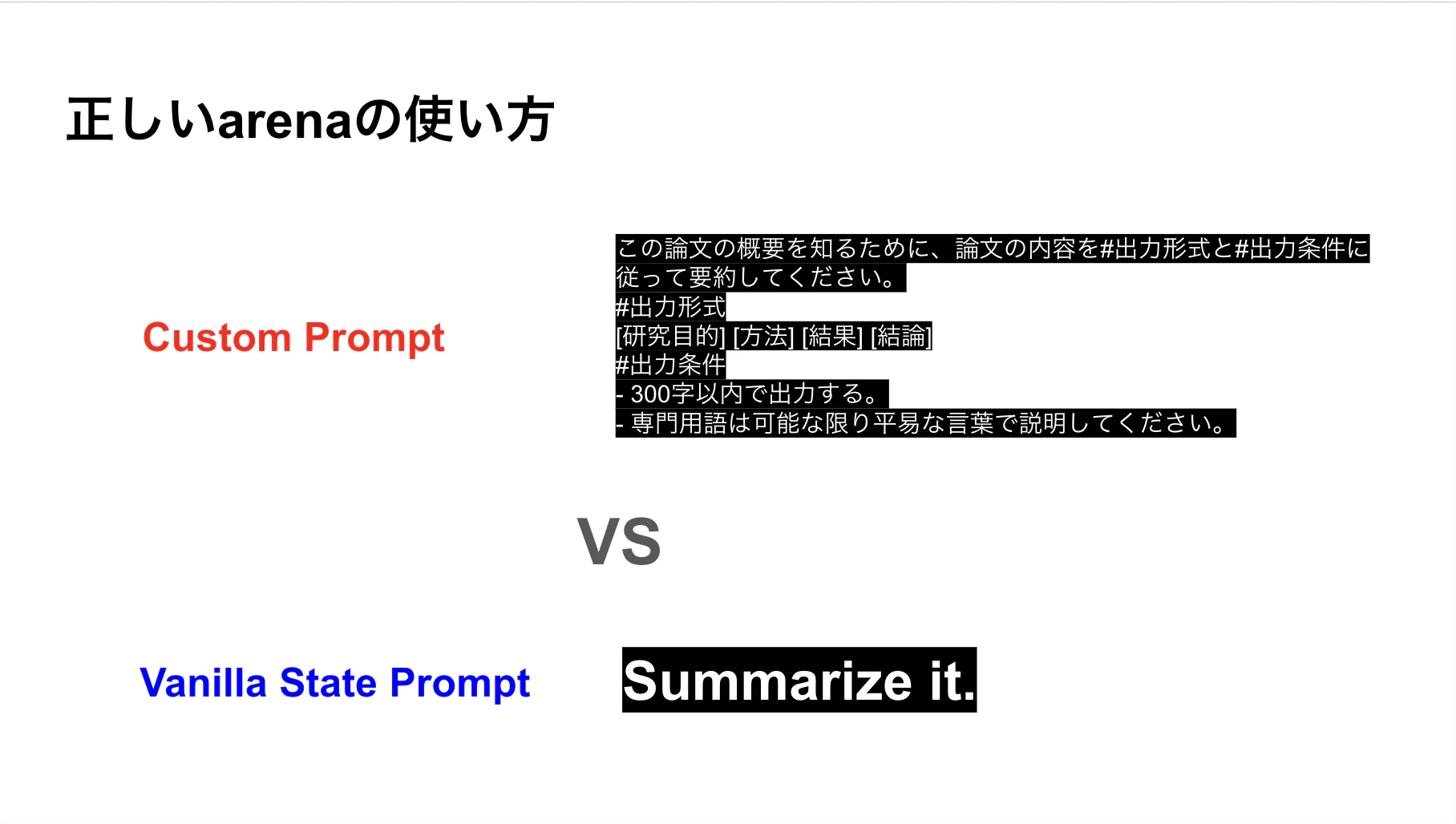
「正しいArenaの使い方」とは、まさにこの
対照実験=コントロール・エクスペリメント
を行うことです。
対照群(Placebo): Vanilla State Prompt。「要約して」の一言だけ。素のモデルの能力。
実験群(New Drug): Custom Prompt。出力形式や制約条件をガチガチに固めたもの。
この2つを戦わせるのです。
もし、皆さんが3日かけて作った「超大作プロンプト」が、「要約して」という3文字の「素のプロンプト」と比べて、勝率が50:50だったらどうでしょうか?
それは、「皆さんの3日間の仕事には、統計的に意味がなかった」という残酷な事実を意味します。
逆に、素のモデル(Vanilla)では精度が40%しかないタスクに対し、カスタムプロンプトで80%まで引き上げられたなら、そこには明確な「+40%のエンジニアリング価値」が存在します。
Battle Arenaは、プロンプトの優劣を競う場ではありません。
「モデルの素の実力(ベースライン)」に対して、我々の介入がどれだけの「付加価値(ROI)」を生んだのか。
それを測定する場こそが、Battle Arenaなのです。
素のモデルが進化して賢くなればなるほど、「余計な指示をしない方がマシ」というケースも増えてきます。
だからこそ、常にVanilla(何もしない状態)という原点と比較し続ける。
これが、プロのエンジニアが持つべき「評価の物差し」です。

最初に与えられた課題は
1つ目は「LLM情報の追跡」、2つ目は「プロンプトエンジニアリングの属人化解消」、そして3つ目が今回深掘りした「評価の難しさの解決」でした。
今日、なぜ私がここまでしつこく「評価」の話ばかりしたのか。
それは、この「統計的な評価サイクル」さえ回せるようになれば、残りの2つの課題もドミノ倒しのように自然と解決されるからです。
まず、「属人化の解消」です。
これまでは「プロンプト職人」の勘と経験に頼っていました。しかし、LLM-as-a-Judgeによる定量的なスコアがあれば、話はシンプルになります。
「誰が書いたか」は重要ではありません。「テストをパスしたか」だけが正義になります。
新人が書いても、ベテランが書いても、スコア85点が出ればそれは「合格」です。評価基準が明確になることで、プロンプトは個人の「作品」から、チームの「資産」へと変わります。これで、再現性の問題は解決です。
次に、「最新情報の追跡」です。
毎日新しいモデルが出てくるこの界隈で、全てのニュースや論文を追うのは不可能です。
しかし、我々には「Battle Arena」があります。
新しいモデルがAPI公開されたら、ニュースを読む前に、既存の「Vanilla Prompt」でArenaに放り込めばいいんです。
「GPT-4o」と「Claude 3.5 Sonnet」、どっちがいいのか?
Twitterの評判を気にする必要はありません。自社のテストセットを実行し、勝率を見れば、「我々のタスクにおいて」どちらが優秀かは10分で判明します。
モデルの選定が、情報のキャッチアップではなく、自動化された回帰テストに変わるのです。
つまり、「評価環境を作る」ということは、「迷いを捨てる」ということです。
お気持ち評価を捨て、統計的事実に従う。
そうすれば、最新技術への追随も、チーム内でのナレッジ共有も、全てが自律的に回り始めます。

しかし。
これで「めでたしめでたし」かと言うと、現実はそう甘くありません。
この「最強の評価サイクル」を回そうとした瞬間、我々は最後に、あまりにも巨大で、かつ根本的な壁にぶち当たります。
課題:データセットが全然足りない
これです。これがオチであり、現在の我々の最大の悩みです。
先ほど私は、「n=100以上の大量データで検証しろ」「統計的事実を見ろ」と偉そうに言いました。
理論は完璧です。システムも作りました。裁判官役のLLMも準備万端です。
でも、肝心の「テスト問題」はどこにあるんでしょうか?
業務に特化した「適切な入力データ」と、それに対応する「理想的な正解データ(Ground Truth)」。
これを100件、1000件と用意するのは誰なのか。
結局、人間が泥臭く作るしかないのか。それともそこもAIに作らせるのか。
評価の「仕組み」は整いました。
しかし、その仕組みに流し込む「燃料(データセット)」が圧倒的に不足しています。
評価の旅はここで終わりではありません。
「評価手法」という武器を手に入れた我々が、次に挑まなければならないのは、この「データセット構築」という新たな泥沼です。