はじめに
はじめまして!
NAIST修士1年生のmakolonです。
この記事は、基盤モデル×Roboticsのカレンダー16日目になります。
12/1日から12/15日までにも基盤モデル×Roboticsについて素晴らしい記事がたくさんあるので、ぜひご覧ください。
今回は、University of Southern Californiaの方がNVIDIAにインターン中に書かれた論文『PROGPROMPT: Generating Situated Robot Task Plans using Large Language Models』を紹介したいと思います。この論文はNeurIPS2022 WorkshopのLanguage and Reinforcement Learning (LaReL)に採択されているようです(best paperは逃してるみたい)。
目次
ProgPromptとは?
ProgPromptを一言で表すと、エージェントが置かれる環境の状況を理解した上で大規模言語モデルによってTask Planを生成する手法です。以下のFig. 2のようにImport文やObject List、Example Taskを大規模言語モデルに与えてあげることで、後に続くTaskをPythonicにプログラミングしてくれます。
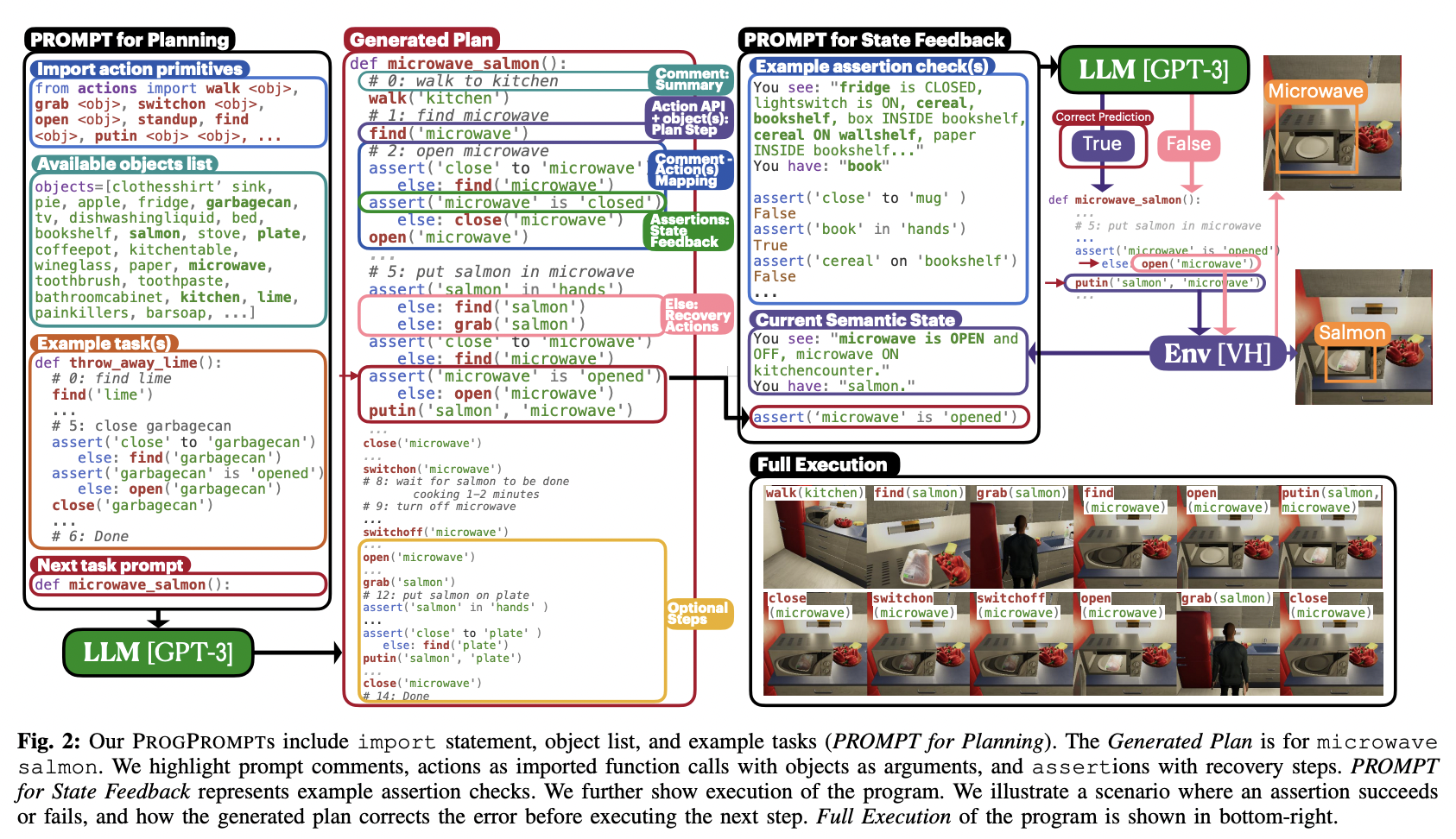
ProgPromptの何がすごい?
ProgPrompt以前にも大規模言語モデルを用いたTask Planning手法はいくつか提案されています。それらの手法は次の二つに分類されます。
- Scoreing next steps
- 次のステップに取りうるActionに対してスコアを割り当てる。
- Generating new steps
- 次ステップのActionに関する一文を直接生成する。
代表的な例としてSayCanは一つ目に分類されます。
これらの大規模言語モデルを用いた従来のTask Planning手法の問題点として、エージェントが置かれる環境からのフィードバックがないことが挙げられます。"Make dinner"という指示が与えられた際、冷蔵庫の中にチキンやソーダ、ピクルスがあるかわからない状況下では与えられた指示も達成することはできません。
一方で、ProgPromptの強みとして、次の2点が挙げられます。
- PythonプログラムのAssertとしてActionのPreconditionを明示的に定義することでフィードバックを得る。
- これから行うActionの目的を説明するためのCommentを追加する。
まず一つ目のPreconditionを明示的に定義することで、例えば冷蔵庫を開く前に冷蔵庫の前にいるなどの状況を理解するActionを取ることを可能にします。
二つ目に、これから行うActionの目的をコメントとしてプログラムに追加することで、タスクの成功率が向上するように言語的な補助を可能にします。
ProgPromptの概要
ProgPromptは従来のText-Generation Modeをより構造化したPythonicなコード生成にしたものと考えられます。
以下のFig.3のようにタスクとして"put_salmon_in_microwave"が与えれらた際、生成されるTask PlanはAction、Actionを要約するComment、実行を追跡するAssertionによって構成されます。Actionは引数として物体名を受け取り、閉ループなコントローラによって実行されます。Commentによって後続のActionを言語的に要約し、タスクをより細かなサブタスクに分割します。AssertionによってPreconditionが満たされていることを検証し、満たされていない場合は環境からのフィードバックを受け取るような動作を実行します。

実験結果
以下の実験では、評価指標としてSuccess Rate $(SR)$、Goal Conditions Recall $(GCR)$、Executability $(Exec)$を用いています。
Success Rate $(SR)$はProgPromptによって生成されたTask Planを実行することで事前に与えられたゴールをどれくらい達成できたかを表しています。また、Goal Conditions Recall $(GCR)$は、真の最終状態と生成されたTask Planで達成された最終状態との差を、タスク固有のゴール条件の数で割った値で測定されます。Executability $(Exec)$は、タスクに関連しないActionであっても、環境中で実行可能なActionの割合を表しています。
シミュレーションでの実験

シミュレーション環境としてVirtualHomeを使用しています。大規模言語モデルとしてはGPT3、CODEX、DAVINCIを使用しています。
Actionとしては"grab", "putin", "putback", "walk", "find", "open", "close", "switchon", "switchoff", "sit", "standup"の11種類を想定しています。また、3種類のVirtualHome環境で実験を行っています。各環境にはカテゴリーレベルの重複を含む115個のユニークな物体を配置しています。そのうち、いくつかの物体は、加熱、洗浄、使用などの状態も持っています。
シミュレーションでの実験結果
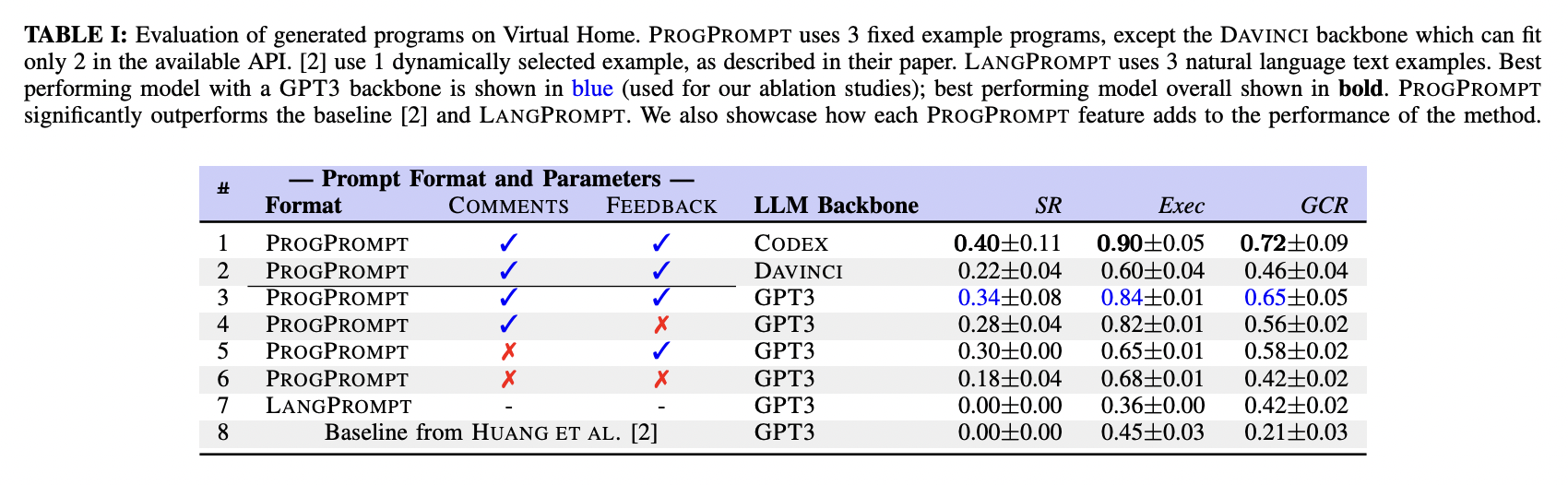
以下のTABLE IはVirtualHomeにおいて10個のタスクをそれぞれ5回ずつ実験した結果から、それぞれの評価指標ごとの平均を示しています。
TABLE Iを見ると、ProgPromptはベースライン手法をすべての指標で上回っていることが確認できます。特に、CommentsとFeedbackを加えた場合に、最も性能が良いことがわかります。
また、GPT3の代わりにCODEXやDAVINCIを大規模言語モデルとして採用した場合、CODEXの方は性能が上がっていることがわかります。
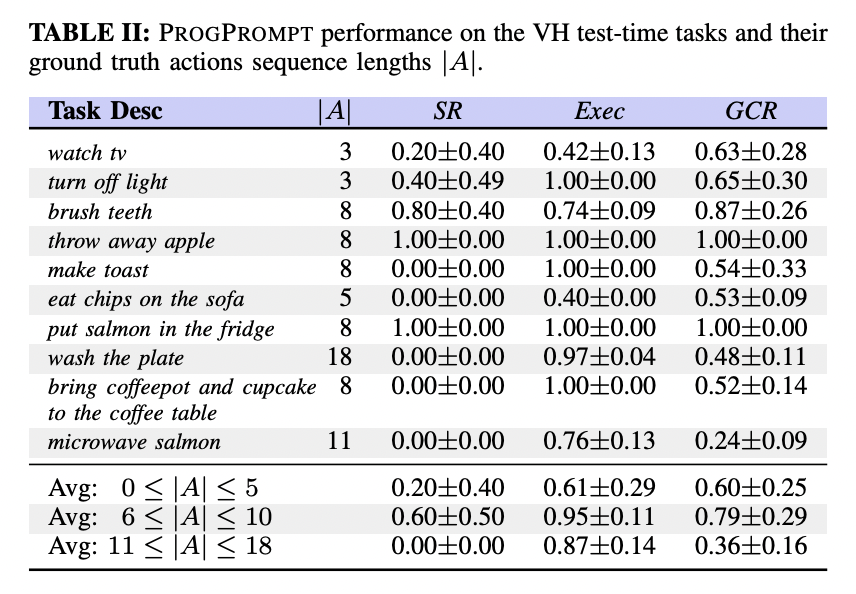
以下のTABLE IIでは、タスクごとの実験結果が示されています。
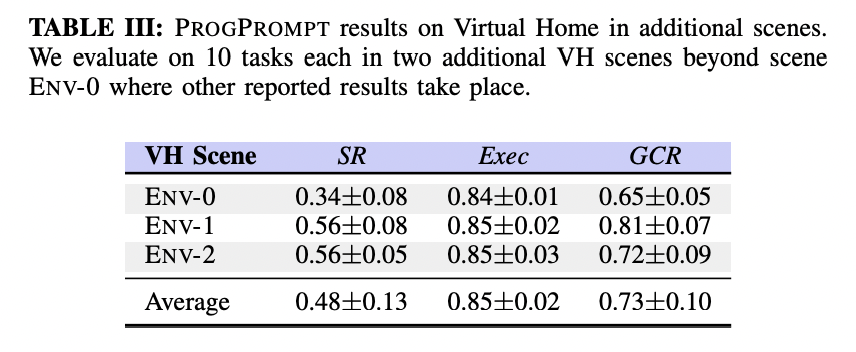
また、TABLE IIIではEnv-0に追加して、2つの新規のVirtualHome環境で評価を行なっています。
実機での実験
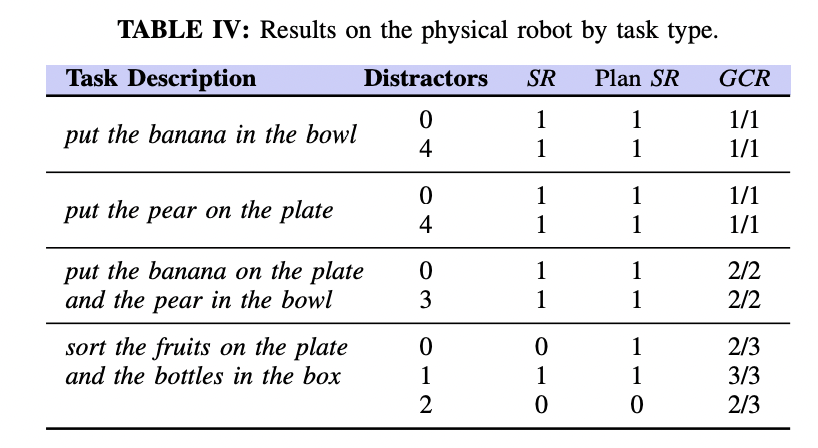
Franka-Emika Panda Robotを使用し、以下の4つのタスクで実験しています。
- Task1: "put the banana in the bowl"
- Task2: "put the pear on the plate"
- Task3: "put the banana on the plate and pear in the bowl"
- Task4: "sort the fruits on the plate and the bottles in the box")
Pick-and-Placeを行うことが可能なコントローラはMPPIで実装され、Collision Avoidanceを行うためにSceneCollisionNetを使用しています。また、把持姿勢を生成するためにContact-GraspNetを使用しています。

実機での実験結果
以下のTABLE IVはそれぞれのタスクにおいてタスクに関係のある物体のみを配置した実験と、タスクに関係のない、阻害となる物体(Distractors)を追加した実験の結果を表しています。また、新たな指標として実機特有の失敗を除いた成功率を表すPlan $SR$を導入しています。TABLE IVの下段のソートタスクを除いて、ほとんどのタスクに成功しています。
これらの実験の動画はYoutubeで見ることができます。
まとめ
今回紹介したProgPromptは、環境やロボットの状況を理解した上で直接実行可能なプログラムを生成することができる手法でした。
ProgPromptのGoogle Colabのデモや実装はまだ公開されていないので、現状は動かせないところが残念です。
最近では、大規模言語モデルなどを用いてTask Planningを行う手法が増えてきたように思えます。大規模言語モデルを使用することで、これまでPDDLやADLといった汎用ドメイン記述言語を使用した記号的な記述を避けることができ、人の居住環境のような人の手ですべてを記号的に表現できない場合に重要になってくると思います。
特に、Roboticsの分野では研究が盛んなTask And Motion Planning (TAMP)と大規模言語モデルを用いた研究は、これからもたくさん出てくると思います。