GoogleColaboratryやKaggleKernelでしか機械学習のコードを書いたことがない
実際に仕事として機械学習を使う際には、
- 学習データの準備
- モデルのトレーニング
- モデルの提供
- REST APIなどで使えるような状態にすること
などが必要なのかなぁと思う今日この頃(他にもたくさんあるっぽいが割愛。こちらのサイトにいろいろ書いている)
そこで今回はAWSのSageMakerを使って少しだけ勉強してみた。
まずはSageMakerEndPointを作るとこまで
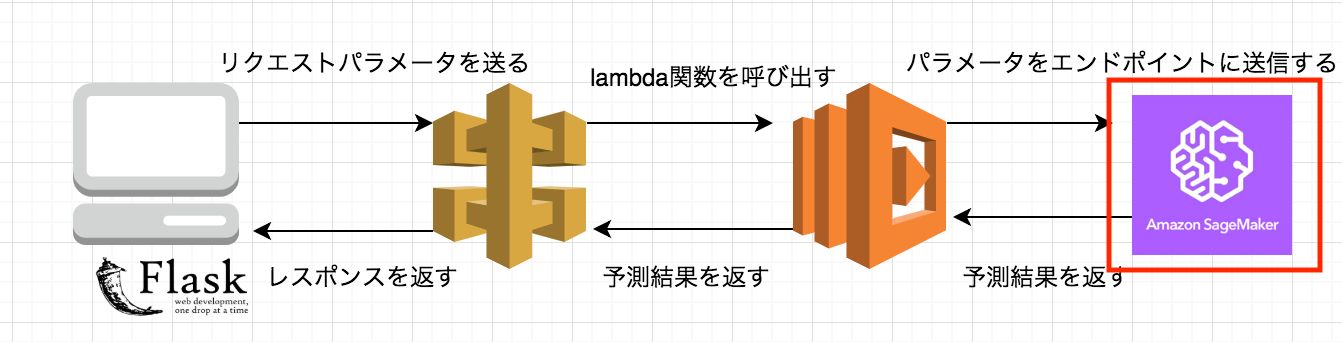
最終的なイメージは上記の画像のような感じ。このうちの赤枠の部分だけをやってみました。
画像はこちらの記事より拝借しました。
具体的には、こちらの公式サンプルに沿って理解しながら実装を進めました。
SageMakerのノートブックインスタンスを立ち上げ
- AWSマネジメントコンソールからSageMakerを検索して選択
- ノートブックインスタンスの作成
- ノートブックの作成
AWSマネジメントコンソールからSageMakerを検索して選択
サービスを検索するから検索するだけです。

ノートブックインスタンスの作成
以下のような画面が出てきますので、ノートブックインスタンス(赤枠)を押します。

次に右上にあるノートブックインスタンスの作成を押します。

作成する際にはノートブックインスタンス名とIAMロールを設定する必要があるので適宜設定してください。
そして作成をすると、ノートブックインスタンスの画面に新たなインスタンスが追加されます。ステータスがPendingからInServiceとなるまで待ってください。
InServiceとなったらJupterを開くを押して次への準備完了です。
ノートブックの作成
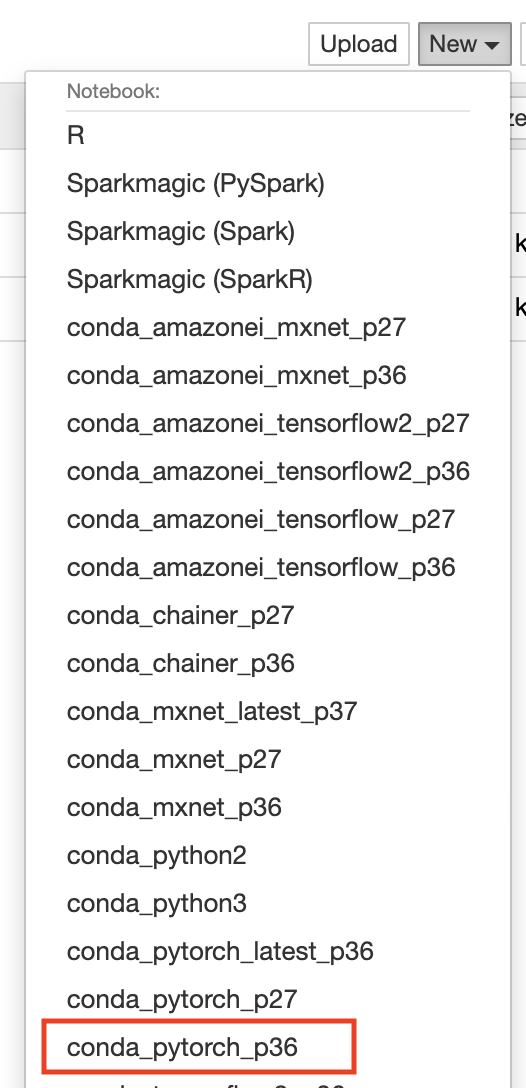
Newからconda_pytorch_p36を選択肢作成する。以下の画像を参照。

学習データ準備
- S3バケットを準備(こちらは解説を省略する)
- mnistの画像をダウンロードとS3バケットへ保存
mnistの画像をダウンロードとS3バケットへ保存
torchvisionのdatasetsを使用してmnistをダウンロードする。
datasets.MNIST()の第一引数でダウンロード先のpathを指定する。
from torchvision import datasets, transforms
datasets.MNIST('data', download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
sagemakerのupload_dataを使用して、作成したS3バケットにmnistを保存します。
import sagemaker
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
region = boto3.Session().region_name
bucket='作成したS3のバケット名'
prefix = 'sagemaker/mnist'
inputs = sagemaker_session.upload_data(path='data', bucket=bucket, key_prefix=prefix)
学習用スクリプトの作成
- モデルの構築
- SageMakerで扱える学習スクリプトに変換
モデルの構築
モデルは以下のように定義しました
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
学習部分は以下のように書きました。
epoch_num = 5
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
for epoch in range(epoch_num):
running_loss = 0.0
for data in trainloader:
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('Finished Training')
SageMakerで扱える学習スクリプトに変換
SageMakerではsagemaker.pytorchのPytorch()を使うことで、学習時に別インスタンスを指定することができます。
estimator = PyTorch(entry_point='mnist.py',
role=role,
framework_version='1.4.0',
py_versions='py3',
instance_count=2,
instance_type='ml.c4.xlarge',
hyperparameters={
'epochs': 6,
'backend': 'gloo'
})
モデルや学習部分を、ここのentry_pointに渡すPythonスクリプトとして作成する必要があります。
ちなみにサンプルでは以下の引数がdeprecatedな形で定義されていたのと、requiredな引数があったので追加しました。
- train_instance_count → instance_count
- train_instance_type → instance_type
- 未指定 → py_versions
SageMakerで読み込むPythonスクリプトとして以下が必要となります。
- スクリプトの引数として指定されたものを受け取る
- 学習用のコードは
if __name__ == '__main__'に入れる - 学習後のモデルの保存先を環境変数
SM_MODEL_DIRにする - 保存したモデルをロードする
model_fn(model_dir)を実装する
スクリプトの引数として指定されたものを受け取る
これは変更する必要がないので以下のように書きました。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=100, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--backend', type=str, default=None,
help='backend for distributed training (tcp, gloo on cpu and gloo, nccl on gpu)')
parser.add_argument('--hosts', type=list, default=json.loads(os.environ['SM_HOSTS']))
parser.add_argument('--current-host', type=str, default=os.environ['SM_CURRENT_HOST'])
parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR'])
parser.add_argument('--data-dir', type=str, default=os.environ['SM_CHANNEL_TRAINING'])
学習用のコードはif __name__ == '__main__'に入れる
私は学習部分はtrain()メソッドとして分けました。
def train(args):
# 学習データ読み込み部分は省略
tainloader = _get_train_data_loader(args.batch_size, args.data_dir, is_distributed, **kwargs)
device = torch.device("cuda" if use_cuda else "cpu")
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
for epoch in range(1, args.epochs + 1):
model.train()
for inputs, labels in trainloader:
inputs, labels - inputs.to(device), labels.to(device)
optimizer.zero_grad()
utputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('Finished Training')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# argparser周りの記述は省略
train(parser.parse_args())
学習後のモデルの保存先を環境変数SM_MODEL_DIRにする
モデルの保存先をargsでもらってきたSM_MODEL_DIRにする
def save_model(model, model_dir):
path = os.path.join(model_dir, 'model.pth')
torch.save(model.cpu().state_dict(), path)
def train(args):
# 学習部分は省略
save_model(model, args.model_dir)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# argparser周りの記述は省略
train(parser.parse_args())
保存したモデルをロードするmodel_fn(model_dir)を実装する
おそらく、予測するときにこのメソッドが内部的に呼ばれるのかなぁという感じです。
実装はサンプルを参考にして以下のように実装しました。
def model_fn(model_dir):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.nn.DataParallel(Net())
with open(os.path.join(model_dir, 'model.pth'), 'rb') as f:
model.load_state_dict(torch.load(f))
return model.to(device)
学習とエンドポイントの作成と削除
ここまでやると、学習ができる状態になります。
あと残るは、以下のことだけ!
- 学習
- エンドポイントの作成と確認
- エンドポイントの削除と確認
学習
SageMakerで扱える学習スクリプトに変換の際に宣言したestimatorを使うと以下のように書くだけで簡単に学習が開始されます。
estimator.fit({'training': inputs})
エンドポイントの作成と確認
エンドポイント作成時にはエンドポイントとなるインスタンスタイプを指定することができます。
推論時にもある程度マシンの性能が必要なのでハイレベルなインスタンスにする必要があります。
predictor = estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
上記のように実行すると、エンドポイントが作成されます。
作成されたかを確認する時は、AWSコンソールのSageMakerのダッシュボードの以下の部分へ進むと、確認できます。

エンドポイントの削除と確認
エンドポイントを利用後はお金がかかってしまうため、エンドポイントを削除する必要があります。
predictor.delete_endpoint()
また、先ほどと同じ画面から、エンドポイントが削除されたことが確認できます。
おわりに
はじめてSageMakerを触ってみましたが、デプロイが楽であることに感動しました。
この勢いでREST APIとして利用できるところまで勉強したいと思います。