こんにちは自称計量東村アキコ学第一人者の @makito です。前回投稿した「東村アキコ作品を自然言語処理して分析した話 - やっぱり「かくかくしかじか」はすごかった - d3.js と Excel と weka」が10回以上ストックされました ![]() ありがとうございます
ありがとうございます ![]() 今回は、CaboChaというフリーの日本語構文解析ソフトと同じくフリーの統計解析ソフトWekaを使用して、漫画キャラクターのセリフの特徴を計量的に分析してみます。
今回は、CaboChaというフリーの日本語構文解析ソフトと同じくフリーの統計解析ソフトWekaを使用して、漫画キャラクターのセリフの特徴を計量的に分析してみます。
 これまで
これまで
まんが大賞へのノミネート5作品目「かくかくしかじか」で大賞を受賞した東村アキコ作品を分析し、ともだちに勧めたくなる漫画作品を計量的に把握しようとしています。
- 漫画の文字情報を使用した漫画作品の特徴抽出方法の検討
- d3.js の集計処理が強力 - 計量東村アキコ学の挑戦 - 漫画の文字情報を使用した漫画作品の特徴抽出方法の検討 その2
- 東村アキコの「主に泣いてます」のセリフからキャラクター設定をWekaを使用して分析する
- 東村アキコ作品を自然言語処理して分析した話 - やっぱり「かくかくしかじか」はすごかった - d3.js と Excel と weka

以前の分析では**「主に泣いてます」**コミック第一巻のセリフを分析し、キャラクターの特徴が発言頻度とセリフ末の記号に表れていることを確かめ、また、
- 各話で主役級の発言頻度のキャラクターは入れ替わる
- ストーリーの進行役を務めるつねは発言頻度が安定している
- セリフ末の記号をキャラクター毎に使い分けている
- こももは例外でセリフ末の記号の使い方にあまり特徴が無い
ということがわかりました。
 「主に泣いてます」の計量分析
「主に泣いてます」の計量分析
今回も引き続き「主に泣いてます」第一巻のセリフを対象とします。
 分析に使用したデータ
分析に使用したデータ
すでにデータ化されている「主に泣いてます」コミック版一巻(第一話~十一話収録)のセリフ(1202件)を使用します。このデータは次のルールに従ってデータ化されタブ区切りファイル(TSV)として保存されています。
- 吹き出しが連なった団子型の場合は団子毎に分けそれぞれひとつのセリフとする
- オノマトペはセリフに含めない
- 背景に同化している発音されてなさそうな文字(気持ちやラベル)はセリフとして扱わない
- 長い点々や波線は一文字として扱う
- 複数ビックリマークは「!」に、「!?」は「!」として扱う
- セリフ毎に話番号、ページ番号、発言者をデータとして持たせる
- ナレーター/解説もセリフとして扱い、発言者は「ナレ」とする
TSVファイルの例
book chapter page name dialogue
1 1 4 不明 お願いしまーす
1 1 4 泉 つねちゃん|あのね
1 1 4 泉 わたしね
1 1 4 泉 明日|面接なの
 自然言語処理を使用した分析方法
自然言語処理を使用した分析方法
データ化された1202件のセリフをCaboChaを使い構文解析し、品詞の使用頻度と各話のキャラクターについて分析します。分析に数量化理論III類を使用したかったのですが、手元にツールが無かったので主成分分析で代用しています。
表1.「主に泣いてます」第一巻に使用される品詞数
| 品詞 | 個数 |
|---|---|
| 名詞 | 2583 |
| 助詞 | 1811 |
| 動詞 | 1124 |
| 記号 | 868 |
| 助動詞 | 698 |
| 副詞 | 225 |
| 感動詞 | 177 |
| 形容詞 | 142 |
| フィラー 1 | 113 |
| 連体詞 | 89 |
| 接続詞 | 79 |
| 接頭詞 | 56 |
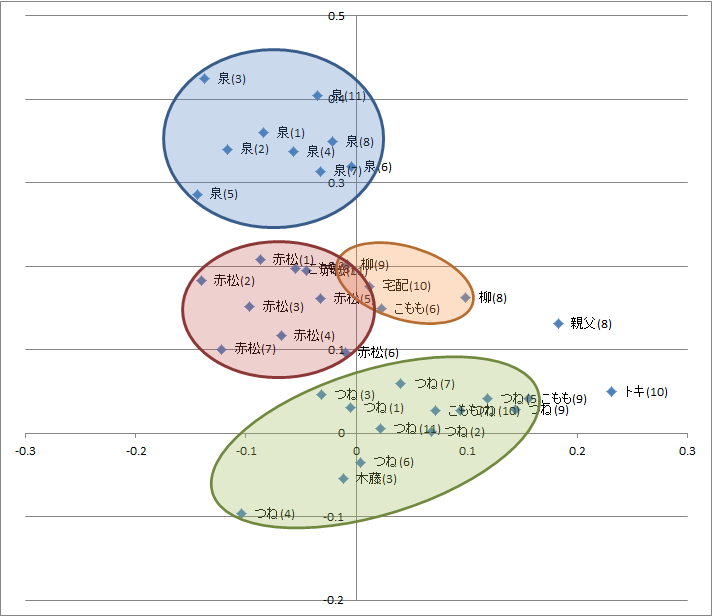
図1.セリフ末の記号使用頻度データを主成分分析した結果散布図
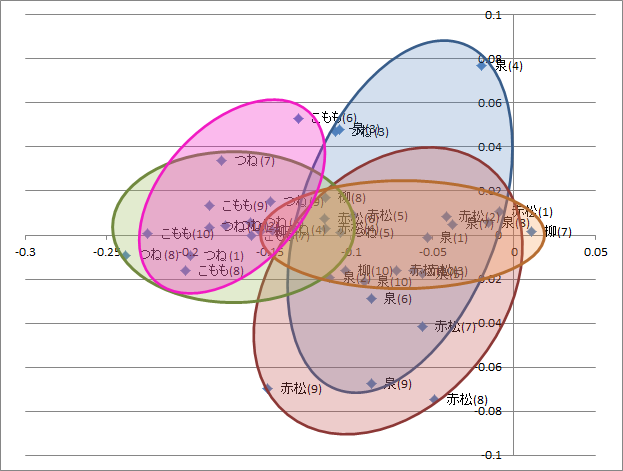
図2.品詞の使用頻度データを主成分分析した結果散布図
表2.品詞使用頻度の主成分分析結果
| 品詞 | 第一主成分 | 第二主成分 |
|---|---|---|
| 名詞 | -0.1442 | 0.0969 |
| 助詞 | -0.4885 | -0.1604 |
| 動詞 | -0.1900 | 0.2732 |
| 記号 | 0.5043 | -0.0796 |
| 助動詞 | -0.1592 | -0.3745 |
| 副詞 | 0.3100 | -0.3709 |
| 感動詞 | 0.3733 | 0.3634 |
| 形容詞 | -0.1277 | 0.4269 |
| フィラー | 0.2956 | 0.3286 |
| 連体詞 | -0.1240 | 0.1873 |
| 接続詞 | -0.2340 | 0.1108 |
| 接頭詞 | 0.1248 | -0.3694 |
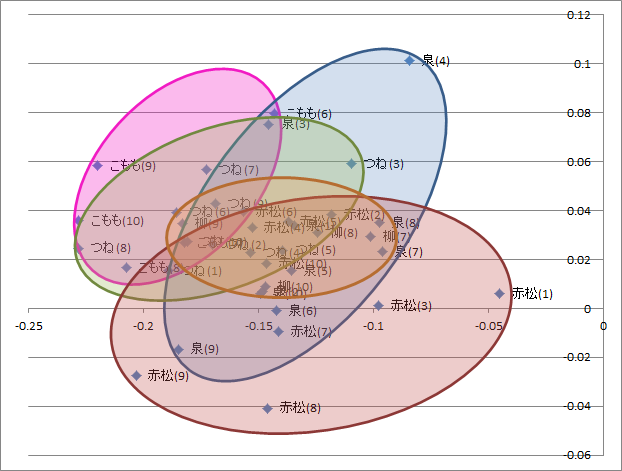
図2-2.記号を除いた品詞の使用頻度データを主成分分析した結果散布図
表2-2.記号を除いた品詞使用頻度の主成分分析結果
| 品詞 | 第一主成分 | 第二主成分 |
|---|---|---|
| 名詞 | -0.0086 | 0.0345 |
| 助詞 | -0.5657 | -0.0352 |
| 動詞 | -0.1641 | 0.3265 |
| 助動詞 | -0.2647 | -0.2977 |
| 副詞 | 0.3162 | -0.4612 |
| 感動詞 | 0.436 | 0.298 |
| 形容詞 | -0.0124 | 0.4199 |
| フィラー | 0.4243 | 0.2389 |
| 連体詞 | -0.1397 | 0.2474 |
| 接続詞 | -0.2971 | 0.2104 |
| 接頭詞 | 0.0696 | -0.4024 |
CaboChaを使用してセリフを処理して品詞について分析しました。「主に泣いてます」一巻の品詞個数は全部で7,966語で、名詞が最も良く使用され、助詞、動詞の順になります(表1)。品詞使用頻度で主成分分析した結果を見ると記号が第一主成分に強く寄与していることが(表2)わかります。この結果をもとに散布図を作成すると(図2)、つねとこももがよくまとまっています。第一主成分の結果から、つねとこももは助詞が多く記号が少ない、より説明的なセリフが多いことが読み取れます。逆に泉と赤松、柳は感情表現のセリフが多い傾向がありそうです。前回の分析でセリフ末の記号がキャラクターによって使い分けられていましたが、この結果も「主に泣いてます」では記号の使い方をキャラクターの特徴付けに重視していることを裏付けていそうです。
記号頻度が強く寄与しているので、記号の使用頻度を除き、セリフの日本語文の構造についてみてみます。同じように主成分分析(表2-2)をし散布図を作成する(図2-2)すると、セリフ末記号の使い方では特徴の無かったこももが他のキャラクターと違う傾向を示すことがわかります。セリフの日本語構造に特徴を持たせキャラクターを演出する可能性をうかがわせます。
 結論
結論
「主に泣いてます」第一巻に登場する主要なキャラクターの泉、赤松、つね、柳、こももはセリフにそれぞれの特徴が出ていると言えそうです。前回の分析と合わせると、泉、赤松、つね、柳はセリフ末の記号に、こももはセリフの文体に特徴がありそうです。
前回のセリフ末記号の傾向と比べると、今回の結果はインパクトが薄い気がします。もう少し掘り下げてセリフの特徴を見ていこうと思っています。
 おまけ
おまけ
CaboChaの使い方
パソコンはWindows7を使っています。セリフデータは文字コードがUTF8なので、CaboChaをセットアップするときに使用する文字コードをUTF8にしました。CaboChaには対話的な構文解析を行うコンソールモードがありますが、UTF8にすると使えないようです。そのため、一文を構文解析する場合でもファイルを経由します。
% cabocha.exe caboin.txt -o caboout1.txt -f1
とか
% cabocha.exe caboin.txt -o caboout2.txt
というコマンドを使います。分析対象のcaboin.txtはセリフ毎に改行したテキストファイルです。もちろん文字コードはUTF8です。
うん…
普通の事務職…
表に出ないしいいかなと思って…
実行オプションの -f1 の有無で、出力されるファイルの形式が変わります。より視覚的に係受けを見たい場合には -f1 無しのコマンドで、品詞等の詳細データを取得するときには -f1 をつけます。
-f1 オプション有の場合
* 0 -1D 0/0 0.000000
うん 感動詞,*,*,*,*,*,うん,ウン,ウン
… 記号,一般,*,*,*,*,…,…,…
EOS
* 0 -1D 2/2 0.000000
普通 名詞,形容動詞語幹,*,*,*,*,普通,フツウ,フツー
の 助詞,連体化,*,*,*,*,の,ノ,ノ
事務職 名詞,一般,*,*,*,*,事務職,ジムショク,ジムショク
… 記号,一般,*,*,*,*,…,…,…
EOS
* 0 1D 0/1 2.614200
表 名詞,一般,*,*,*,*,表,ヒョウ,ヒョー
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
* 1 2D 0/2 0.844823
出 動詞,自立,*,*,一段,未然形,出る,デ,デ
ない 助動詞,*,*,*,特殊・ナイ,基本形,ない,ナイ,ナイ
し 助詞,接続助詞,*,*,*,*,し,シ,シ
* 2 3D 0/3 0.844823
いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ
か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ
な 助詞,終助詞,*,*,*,*,な,ナ,ナ
と 助詞,格助詞,引用,*,*,*,と,ト,ト
* 3 -1D 0/1 0.000000
思っ 動詞,自立,*,*,五段・ワ行促音便,連用タ接続,思う,オモッ,オモッ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
… 記号,一般,*,*,*,*,…,…,…
EOS
-f1 オプション無の場合
うん…
EOS
普通の事務職…
EOS
表に-D
出ないし-D
いいかなと-D
思って…
EOS
 CaboChaの出力結果を分析に使うまで
CaboChaの出力結果を分析に使うまで
CaboChaを使って構文解析した結果データを分析に使える形にするために、Javascriptを使ってプログラムを書いています。グラフ作成にはExcelのピボットテーブルとピボットグラフを使っていますので、Excelが扱いやすい形にデータを加工するのがJavascriptで作ったプログラムの目的です。
Javascriptを使ったファイルの読み書きはいろいろな方法があるようで、どの方法が一番スマートなのかよくわかっていないので、適当にネットで見つけたサンプルを参考にしています。
CaboChaの解析結果ファイルの特徴は
- EOSで一文が終わることを示す
- 行頭のアスタリスク*で係受けデータを示す
- その他の行は形態要素解析した結果
のようになっていますので、それに合わせて分析しやすいデータをつくっていきます。
// ファイルを読み込んでタブ区切りをsplitしてArrayに格納していく
var cabochadata_tsv = fs.readFileSync(program.cabochadatafile, 'utf8');
var cabochadata = [];
cabochadata_tsv.split('\n').forEach(function(d){
cabochadata.push(d.split('\t'));
});
// 細かいバグが残ってますが、こんな感じでArrayに品詞データを格納
var index = 0
c = [];
cabochadata.forEach(function(d){
var src = rows[index];
if(d[0].lastIndexOf('EOS', 0) === 0) { // 単語がEOSだったらバグになるよ orz
index+=1;
} else if(0 === d[0].indexOf('*') || d[0].length === 0) { // 単語が*だったらバグになるよ orz
// ignore line format like "* 0 -1D 3/3 0.000000"
} else {
// console.log(d[0]);
var wordinfo = d[1].split(',');
var wordclass = wordinfo[0];
c.push({
chapter: src.chapter,
page: src.page,
name: src.name + '(' + src.chapter + ')',
wordclass: wordclass,
// word: d[0],
word: wordinfo[6], // 活用前の基本形
count: 1
});
}
});
これで配列cに品詞データが入るので、あとはExcelで分析しやすいデータ形式に出力できるようにします。
1 4 不明(1) 名詞 お願い 1
1 4 不明(1) 名詞 しま 1
1 4 不明(1) 名詞 ー 1
1 4 不明(1) 動詞 す 1
1 4 泉(1) 名詞 つね 1
1 4 泉(1) 名詞 ちゃん 1
1 4 泉(1) フィラー あの 1
1 4 泉(1) 助詞 ね 1
1 4 泉(1) 名詞 わたし 1
1 4 泉(1) 助詞 ね 1
1 4 泉(1) 名詞 明日 1
1 4 泉(1) 名詞 面接 1
1 4 泉(1) 助動詞 な 1
1 4 泉(1) 助詞 の 1
こんなデータをつくることで、Excelのピボットを使った集計がとても捗ります。
主成分分析の前に発言率でデータを絞る理由とか
主成分分析をする前に分析に使うデータをキャラクターの発言比率によって絞り込みました。この理由について簡単に説明します。
カラス役(カラスが「カア」と泣いて夕刻を告げる程度の発言)のキャラクターの発言が分析結果に影響するのを避けるためですが、どんな影響があるのでしょうか?今回の主成分分析にはセリフ末尾の記号比率を使用しました。例えば、つねのセリフが全部で10回あったとき
今日はいい天気だ
げっ
いいかげんにしろ!
お茶してやれよ
生徒一人ゲット!
マジで
えっ
あ
どお?
いいよ
「!」が2回、「?」が1回ですので、次の表のような記号の使用頻度になります。
| ! | ? | ッ | |
|---|---|---|---|
| つね | 20.0% | 10.0% | 0% |
これに、カラス役の店員がいらっしゃいませーッと発言してたりすると
| ! | ? | ッ | |
|---|---|---|---|
| つね | 20.0% | 10.0% | 0% |
| 店員 | 0% | 0% | 100% |
というデータができます。これを主成分分析にかけると、**「ッ」**の使用頻度がよりキャラクターの特徴を表す項目として扱われます。このような影響を避けるために、発言頻度が極端に低いキャラクターをカラス役として落とし、ストーリーに重要なキャラクターの特徴づけの分析を行うようにしています。
末尾の促音**「っ」「ッ」**
漫画のセリフの末尾には促音が良く使用されます。いつの頃からか興味ありますが、カタカナの促音「ッ」が記号的に利用されるようになりました。
ふざけんなーッ
という感じです。長音と合わせて使われることが多いようです。店員は
いらっしゃいませー
とは言いますが
いらっしゃいませーッ
とは言いません。この片仮名の促音は?や!と同じ記号として扱うようにしています。ひらがなの促音「っ」を記号扱いすべきかどうか、まだ悩んでいます。
データ化作業
これがとてもつらい作業なのです。終わらないです。セリフを書きうつすだけの単純作業なのですが、漫画を読むスピードほどには速くできませんので、とにかくつらいです。しかしセリフデータが無いことには、分析もできませんし、避けて通ることができません。
眠い目をこすりながら、コーラとコーヒーのカフェインで補充し何とかデータ化しています。こうして出来上がったデータを分析して何になるのか?といったら、特に何もならないわけでして。そういう現実に気づくとですね、ますます辛さに拍車がかかります。こうなるとアルコール ![]() が必要になります。
が必要になります。
描いても描いても…
全く終わる気が
しねェ!
とは「かくかくしかじか」第四巻の主役林の言葉ですが、
写しても写しても…
全く終わる気が
しねェ!
ということです。「海月姫」なんて発行済みの巻数を見るだけで絶望しそうですので、いずれの作品も第一巻が終わったら最新刊をデータ化するという感じで行くことにしました。
それでも「かくかくしかじか」は本当に良い作品だと思いますので、全巻データ化して計量分析をしてみたいと思います。
漫画のセリフに関する諸研究
少女マンガにみる女ことば
http://www.urayasu.meikai.ac.jp/japanese/meikainihongo/8/aizawa.pdf
オブジェクト指向 FRBR を基礎としたマンガオントロジーの設計
http://dl.slis.tsukuba.ac.jp/DLjournal/No_38/1-son/1-son.pdf
コミック工学の可能性
http://amateras.wsd.kutc.kansai-u.ac.jp/wordpress/wp-content/uploads/2013/05/WI22nd-mat-63-68.pdf
コミックを対象とした質問応答システムのための質問タイプ分類の検討
http://must.c.u-tokyo.ac.jp/sigam/sigam07/sigam0706.pdf
アニメ・マンガの日本語授業への活用
http://www.nkg.or.jp/kenkyu/Forumhoukoku/2011forum/2011_RT3_kawashima.pdf
アニメ・マンガの日本語~ジャンル用語の特徴をめぐって~
http://www.jfkc.jp/clip/images/page/anime/animemanga_2011c.pdf
まんがの描き方
http://www.white.umic.jp/manga/files/mangatext1.pdf
マンガにおける表現技法の進化
http://ci.nii.ac.jp/els/110008146952.pdf?id=ART0009662869&type=pdf&lang=jp&host=cinii&order_no=&ppv_type=0&lang_sw=&no=1429452860&cp=
-
フィラーというのは、会話の途中に挟まれる「ああ」「えーと」のような、スキマを埋める言葉のことです。CaboChaで構文解析した結果では、単にフィラーとされますが、ポーズフィラーとも呼ばれます。ここでのポーズは「一時停止」のポーズ(pause)の意味です。 ↩