こんにちは自称計量東村アキコ学第一人者の @makito です。今回は d3.js を使うと集計処理が簡単に書けるというお話です。前半は計量東村アキコ学に関することなのでソースコードを見たい方は後半のこちらへどうぞ。続きは→「東村アキコの「主に泣いてます」のセリフからキャラクター設定をWekaを使用して分析する」。
 これまで
これまで
前回の「漫画の文字情報を使用した漫画作品の特徴抽出方法の検討」では、2015年のまんが大賞を受賞した東村アキコ先生の「かくかくしかじか」の第一話の文字データから作品の特徴を把握しようと試みました。まんが大賞は「ともだちに勧めたくなるマンガ」という基準で選考され、東村アキコ先生の作品は過去4作品がノミネートされ5作品目の「かくかくしかじか」で大賞の受賞となりました。「かくかくしかじか」と他4作品の差異を抽出することでともだちに勧めたくなる漫画の構成要素を把握できるかもしれません。

 第一話のおさらい
第一話のおさらい
過去の類似研究を参考にしつつ、第一話を分析することで次の特徴案を考えました。
- セリフの無いページを上手く使用するという特徴がある可能性
- 品詞の使用頻度が特徴となる可能性
- キャラクター毎のセリフ表現(特に記号の使用頻度)が特徴となる可能性
ところで
漫画の文字情報を分析するにはどのようなアプローチを取るべきでしょうか?文化計量学に詳しい村上征勝先生が著作の中で次のように解説されています。
一般に、文化現象を理解するためのデータの種類は無数に考えられる。たとえば、作家の文体に注目した場合、文体に関する情報として、文長、単語長、単語の出現率、品詞の出現率、品詞の接続関係、語彙量、読点の付け方、などの膨大な種類のデータを生成することが可能である。しかし、仮に、そのような膨大な種類のデータが生成できたとしても、計量分析でそれらすべてを用いることは実際には不可能であるし、また現象を理解するうえで役立たないデータが多く含まれていることも考えられる。
また、適切なデータを見極めるために重要なこととして
現象の大局的把握のためにどのような種類のデータが必要かを決めるには、現象を深く掘り下げ、現象の理解にはどのような切り口が考えられ、そのなかでもとりわけ、どの切り口が重要かという的確な判断が要求される。つまり、データ生成以前の文化現象に対する鋭い洞察によってもたらされる着眼のよさが重要となる。
と指摘されています。と、言うことは、東村アキコ先生の5作品に対する鋭い洞察、特に「かくかくしかじか」と他4作品の比較に見られる差異に対する鋭い洞察が重要となりそうです。そういうわけで先生のコミックを読み鋭い洞察というものを次回以降に挑戦してみたいと思います。
今回は「かくかくしかじか」第一話から四話までのデータ集計結果とデータ集計に使用したプログラムを紹介します。
東村アキコ先生の過去のまんが大賞ノミネート作品
| 主に泣いてます 2011年 12位 |
海月姫 2010年 7位 |
ママはテンパリスト 2009年 8位 |
ひまわりっ 〜健一レジェンド〜 2008年 11位 |
|---|---|---|---|
 |
 |
 |
 |
 文字情報の特徴抽出方法
文字情報の特徴抽出方法
第一話と同じようにセリフを手入力でデータ化していきます。話番号を追加で取得するようにし、レコードに巻番号、話番号、ページ、発言者、セリフの項目を含めるようにしました。
レコードの形式(タブ区切りのテキストファイルとして保存)
1 2 29 日高 形 おかしいやろ|自分で気付け|バータレ
※セリフ中の|(縦棒)は改行
このデータをExcelで加工しやすい形式(主にピボットテーブル及びピボットグラフ)にするプログラムをJavascriptで書きました(ソースコード count2.js)。d3.js を利用することで少ないコードで集計をすることができました。コマンドラインから汎用的に使用できるようにしたので同じような分析をされる際にご利用ください。
各ページ毎のセリフ数と発言者数をカウントします。カウントした結果データを使いExcelでグラフを作成しました。
第一話から第四話までのセリフ数に関するデータ
| セリフ数と発言者数 | 発言者毎のセリフ数 |
|---|---|
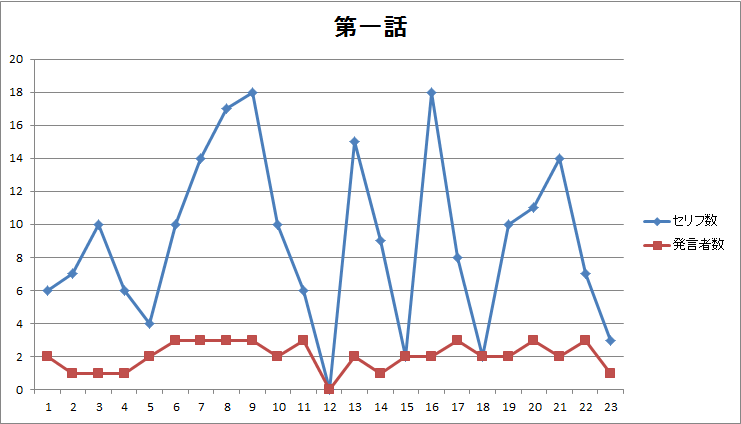 図1.第一話のページ毎のセリフ数・発言者数 |
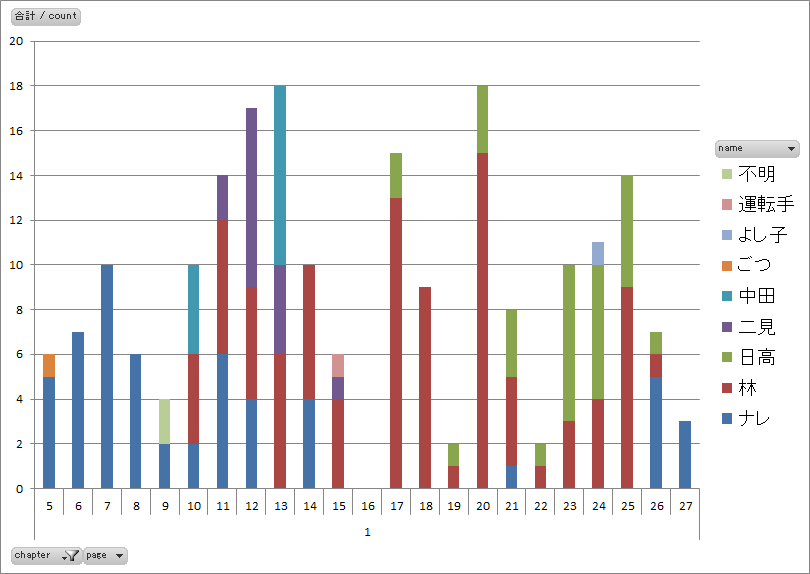 図2.第一話のページ毎の発言者別セリフ数 |
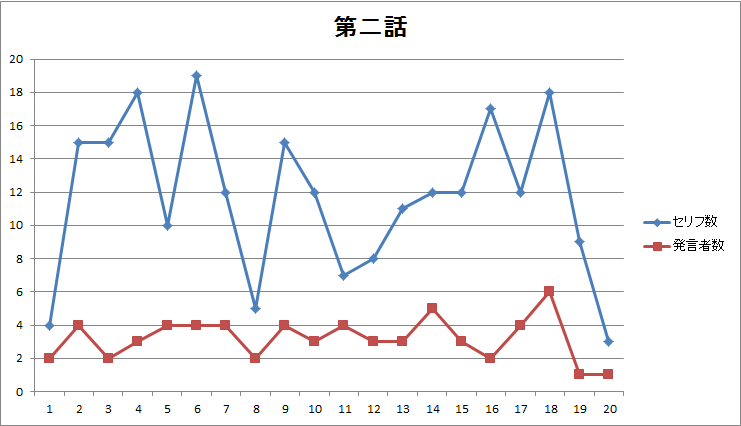 図3.第二話のページ毎のセリフ数・発言者数 |
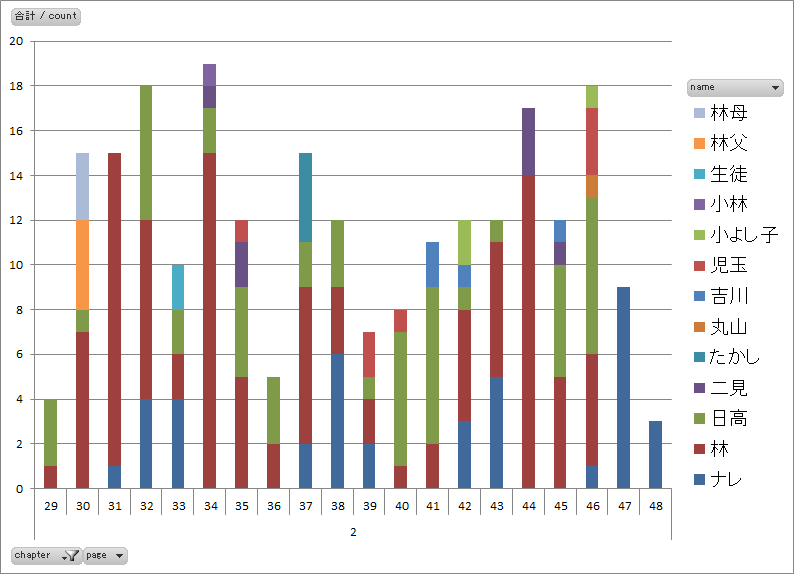 図4.第二話のページ毎の発言者別セリフ数 |
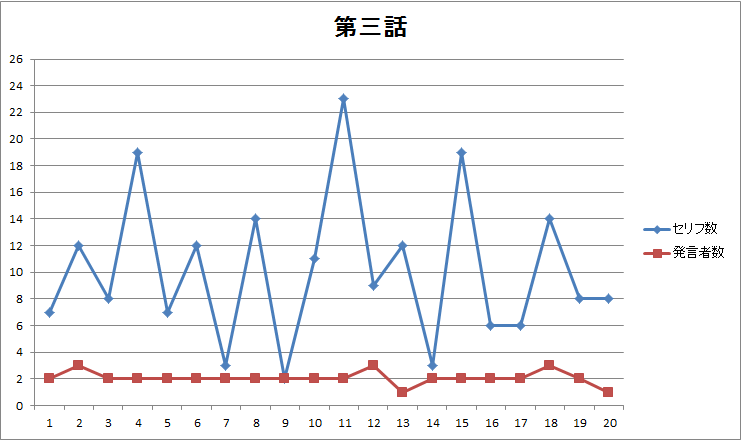 図5.第三話のページ毎のセリフ数・発言者数 |
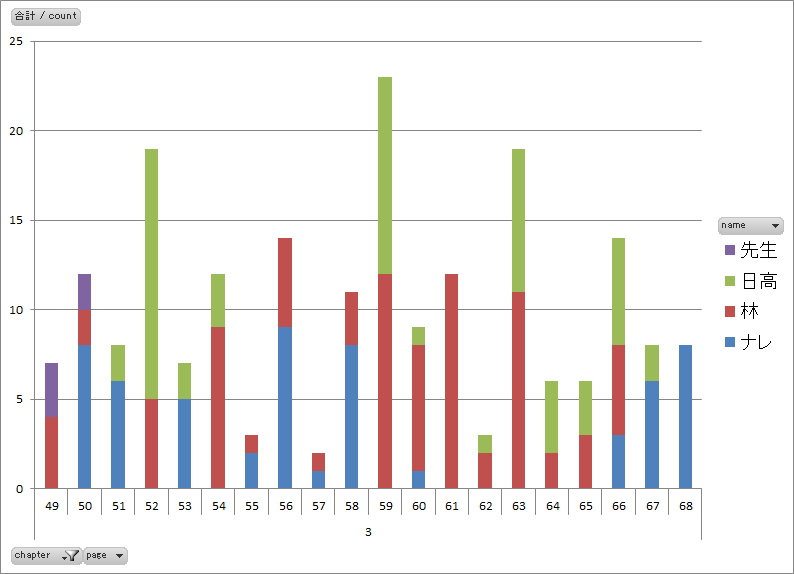 図6.第三話のページ毎の発言者別セリフ数 |
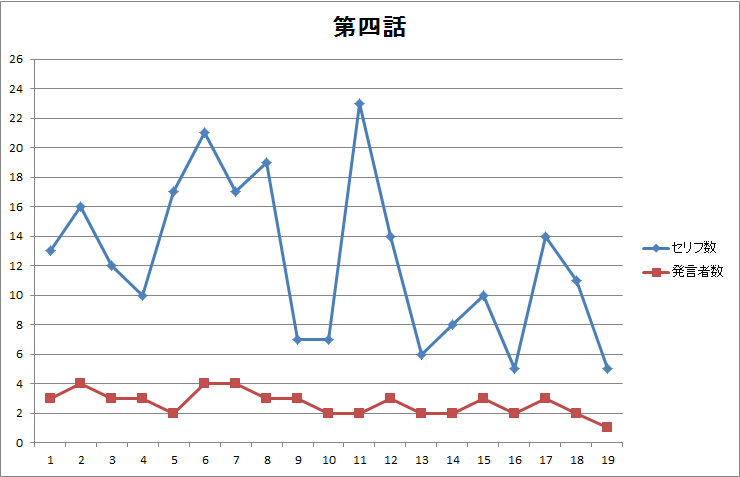 図7.第四話のページ毎のセリフ数・発言者数 |
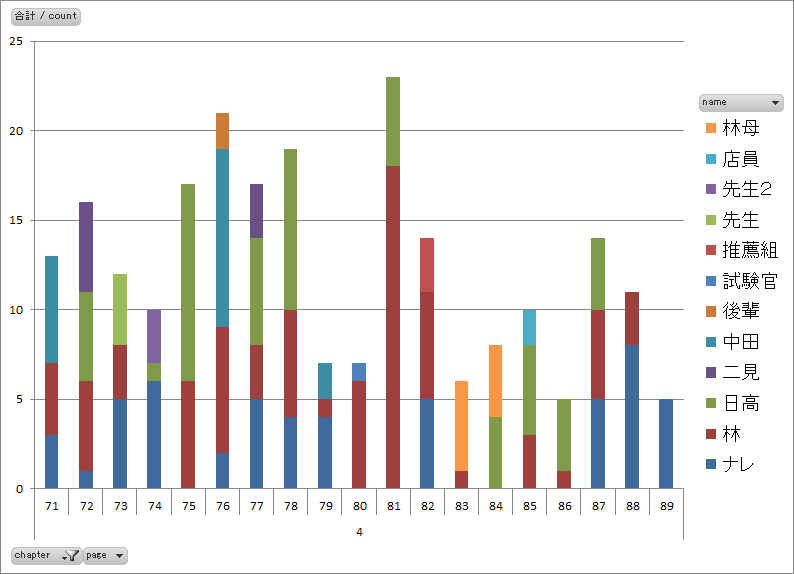 図8.第四話のページ毎の発言者別セリフ数 |
- 第一話に見られた前後半の差(図1、図2)は第二~四話には見られません。
- 第一話にあったセリフ無しページは第二~四話にはありません(図1、図3、図5、図7)。
- 話によって発言者数に大きな差異(図6)がありそうです。発言者数で話の特徴を出しているかもしれません。
- 四話まで共通してナレーションのみで終わる表現をしています(図2、図4、図6、図8)。
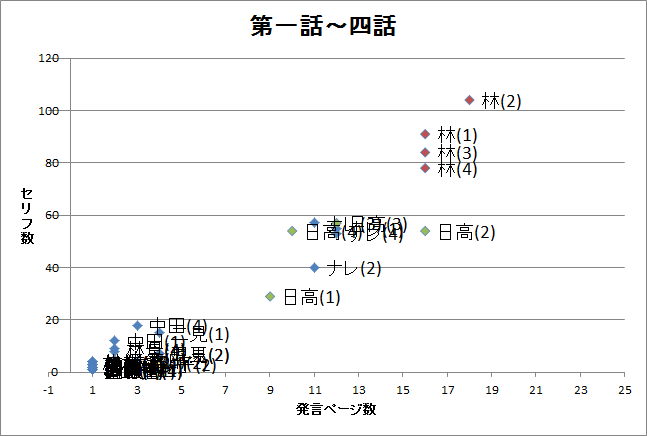
図9.各話毎の発言者の発言ページ数と発言回数
- キャラクターの発言頻度でキャラクターの特徴づけをしているようです(図9)。主役の林に対して、準主役の日高、日高と同程度のナレーション、ちょい役の中田、二見というグループがつくれそうです。
-
 無口のキャラクターが登場する作品にこのデータが使用できるのか検討の余地はありそうです。
無口のキャラクターが登場する作品にこのデータが使用できるのか検討の余地はありそうです。
クラスター分析の結果
Group 1
ごつ(1),不明(1),中田(1),運転手(1),よし子(1),たかし(2),丸山(2),吉川(2),児玉(2),小よし子(2),小林(2),生徒(2),二見(2),林父(2),林母(2),先生(3),後輩(4),試験官(4),推薦組(4),先生(4),先生2(4),店員(4),二見(4),林母(4),
Group 2
日高(3),ナレ(3),ナレ(1),日高(2),日高(4),ナレ(4),ナレ(2),
Group 3
林(2),林(1),林(3),林(4),
Group 4
日高(1),中田(4),二見(1),
主役はGroup3、準主役はGroup2、脇役はGroup4、残りはおまけのGroup 1といった具合でしょうか。ナレーションに準主役並みの働きをさせているとも言えるかもしれません。このようなキャラクターの発言傾向について、他作品も同様に分析して比較してみようと思います。
第一話から第四話までの文字数に関するデータ
| 総文字数と平均文字数 | 総記号数と文末記号数 |
|---|---|
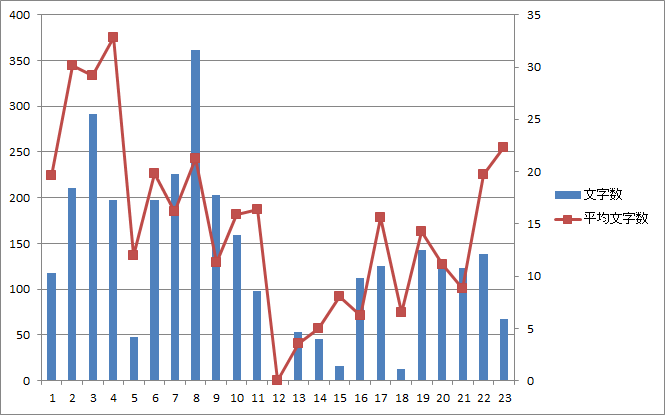 図10.第一話のページ毎の総文字数と平均文字数 |
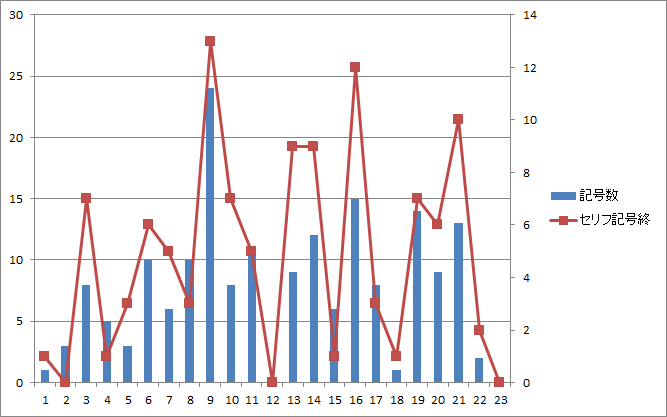 図11.第一話のページ毎の総記号数とセリフ末記号数 |
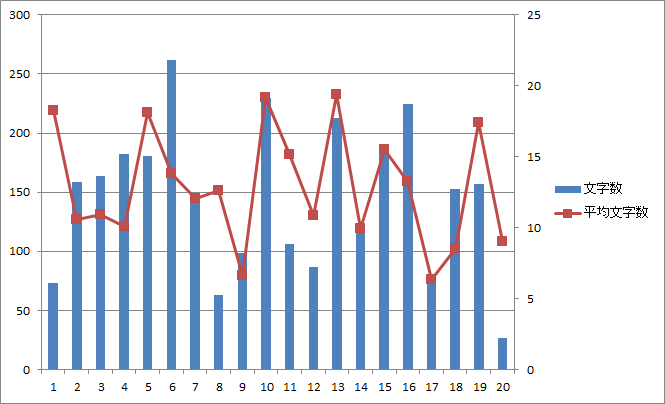 図12.第二話のページ毎の総文字数と平均文字数 |
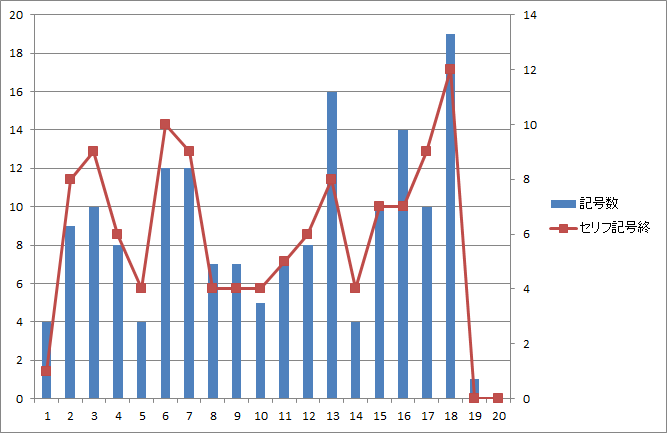 図13.第二話のページ毎の総記号数とセリフ末記号数 |
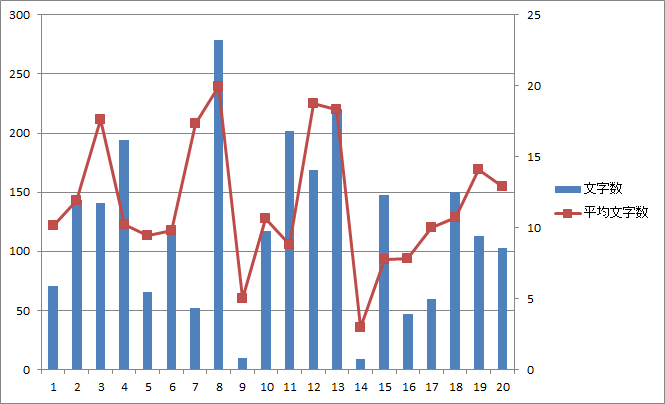 図14.第三話のページ毎の総文字数と平均文字数 |
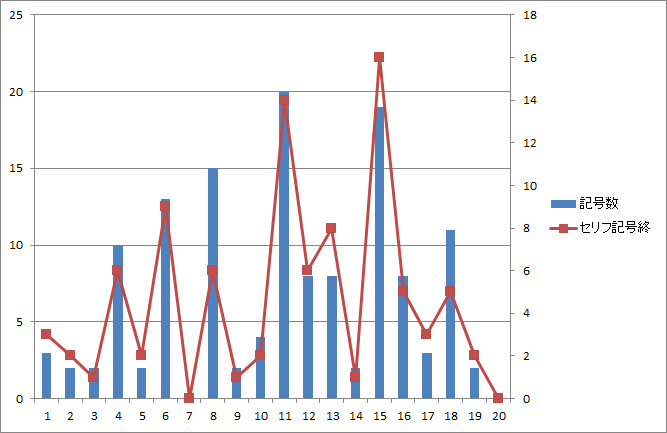 図15.第三話のページ毎の総記号数とセリフ末記号数 |
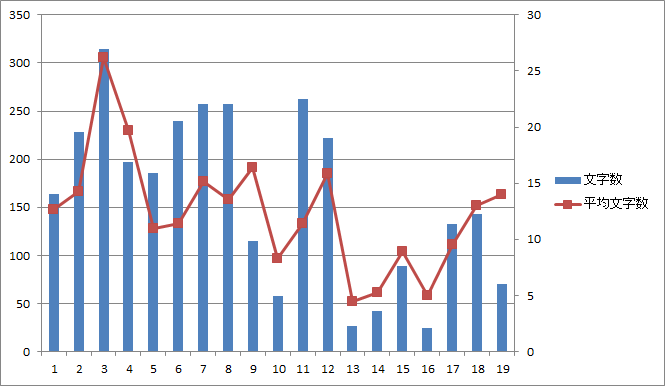 図16.第四話のページ毎の総文字数と平均文字数 |
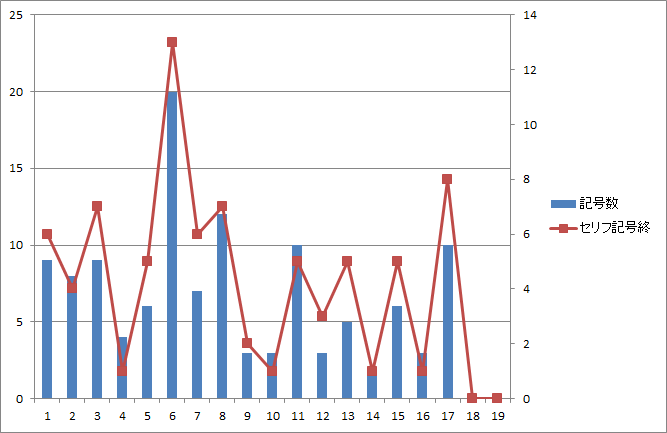 図17.第四話のページ毎の総記号数とセリフ末記号数 |
以下の文字を記号としてカウントした(片仮名の小さいツを外すべきか要検討)
?,…,!,ッ,~
 分析に使用したプログラムのコード(Javascript)
分析に使用したプログラムのコード(Javascript)
count2.js
commander.js と d3.js を使用して汎用的にコマンドラインから集計用データを作成できるようにしました。コマンドラインから二つのオプションを受け付けます。-dで元になるtsvデータファイルのパスを指定、-tで出力時のフォーマット(tsv または markdown)、-cで計算方法(page|character|plot|char|symbol)を指定できるようにしました。commander.jsを使用すると、コマンドオプションの拡張が楽なので重宝します。
次のフォーマットのtsvファイルからExcelで使いやすい形に出力していきます。ちなみにタブ区切りにしているのはExcelに直接コピー&ペーストしやすいという理由です。
[巻番号] [話番号] [ページ] [発言者] [セリフ]
プログラムが扱いやすいように1行目にヘッダー行をつけています。
book chapter page name dialogue
-cでpageが指定された場合には
[話番号] [ページ] [セリフ数] [発言者数]
-cでcharacterが指定された場合には
[話番号] [ページ] [発言者] [セリフ数]
を出力します。
分析対象データ(tsv)の例
book chapter page name dialogue
1 1 5 ナレ その古い家は|森を抜けた海の|すぐ側に建っていた
1 1 5 ナレ 皆様 初めまして|私の名前は東村アキコです|漫画家やってます
1 1 5 ナレ 昭和生まれの|現在36歳|
コマンドラインからの使い方の例
ページ毎のセリフ数と発言者数のデータを作成する場合
% node count2.js -c page -d data.tsv > result.tsv
ページ毎、発言者毎の発言数のデータを作成する場合
% node count2.js -c character -d data.tsv > result.tsv
散布図(図9)作成用の話毎の発言者の発言回数、発言ページ数のデータを作成する場合
% node count2.js -c plot -d data.tsv > result.tsv
ページ毎の文字数、平均文字数(図10等)のデータを作成する場合
% node count2.js -c char -d data.tsv > result.tsv
ページ毎の記号数、セリフ末記号数(図11等)のデータを作成する場合(※事前に記号として扱う文字をcsvで作成)
?,…,!,ッ,~
% node count2.js -c char -d data.tsv -s symbol.csv > result.tsv
ソースコード Javascript
// commander example
var program = require('commander'),
d3 = require('d3'),
fs = require('fs');
program
.version('0.0.1')
.option('-t, --format [value]', 'Output format [tsv|markdown]', 'tsv')
.option('-c, --calc [value]', 'Data file path [page|character|plot|char|symbol]', 'page')
.option('-d, --datafile [value]', 'Data file path')
.option('-s, --symbolfile [value]', 'Symbol file path')
.parse(process.argv);
var formats = {
page: {tsv: '%d\t%d\t%d\t%d', markdown: '|%d|%d|%d|%d|'},
character: {tsv: '%d\t%d\t%s\t%d', markdown: '|%d|%d|%s|%d|'},
plot: {tsv: '%d\t%s\t%d\t%d', markdown: '|%d|%s|%d|%d|'},
char: {tsv: '%d\t%d\t%d\t%d\t%d', markdown: '|%d|%d|%d|%d|%d|'},
symbol: {tsv: '%d\t%d\t%d\t%d\t%d', markdown: '|%d|%d|%d|%d|%d|'}
}
var fmt = formats[program.calc][program.format];
//console.log(program.format);
//console.log(program.datafile);
fs.readFile(program.datafile, 'utf8', function (err, data) {
var rows = d3.tsv.parse(data);
// console.log(rows);
if('page' === program.calc) {
var c = d3.nest()
.key(function(d) { return d.page; })
.rollup(function(v){
// count character on this page
var ch = d3.nest().key(function(d) { return d.name}).rollup(function(v){return v.length}).map(v);
return {
chapter: v[0].chapter,
count: v.length, // dialog count per page
character: Object.keys(ch).length // character count per page
};
})
.map(rows);
// console.log(c);
for(key in c){
console.log(fmt, +c[key].chapter, +key, +c[key].count, +c[key].character);
}
} else if('char' === program.calc) {
var c = d3.nest()
.key(function(d) { return d.page; })
.rollup(function(v){
// count character on this page
var char_count = d3.sum(v, function(d) { return d.dialogue.replace('|', '').length;} );
return {
chapter: v[0].chapter,
count: v.length, // dialog count per page
char_count: char_count, // char(letter) count per page
ave_char_count: (char_count / v.length)
};
})
.map(rows);
// console.log(c);
for(key in c){
console.log(fmt, +c[key].chapter, +key, +c[key].char_count, +c[key].count, +c[key].ave_char_count);
}
} else if('symbol' === program.calc) {
// read symbol file
var symbols = fs.readFileSync(program.symbolfile, 'utf8').split(',');
console.log(symbols);
// [chapter] [page] [total_symbol_count] [symbol_at_end_count] [ave_symbol]
var c = d3.nest()
.key(function(d) { return d.page; })
.rollup(function(v){
// count character on this page
var total_symbol_count = d3.sum(v, function(d) {
var ct = 0;
for(var i=0; i < d.dialogue.length; i++){
if (symbols.indexOf(d.dialogue[i]) != -1) ct += 1;
}
return ct;
});
var symbol_at_end_count = d3.sum(v, function(d) {
var s = d.dialogue.replace('|', '');
if (symbols.indexOf(s[s.length - 1]) != -1) {
return 1; // the dialogue ends with a symbol
} else {
return 0;
}
});
return {
chapter: v[0].chapter,
count: v.length, // dialog count per page
total_symbol_count: total_symbol_count, // char(letter) count per page
symbol_at_end_count: symbol_at_end_count,
ave_symbol: (total_symbol_count / v.length)
};
})
.map(rows);
// console.log(c);
for(key in c){
console.log(fmt, +c[key].chapter, +key, +c[key].total_symbol_count, +c[key].symbol_at_end_count, +c[key].ave_symbol);
}
} else if('character' === program.calc) {
var c = d3.nest()
.key(function(d) { return d.page; })
.rollup(function(v){
// count character on this page
var ch = d3.nest().key(function(d) { return d.name}).rollup(function(v){return v.length}).map(v);
return {
chapter: v[0].chapter,
count: v.length, // dialog count per page
data: ch
};
})
.map(rows);
// console.log(c);
for(key in c){
for(name in c[key].data){
console.log(fmt, +c[key].chapter, +key, name, +c[key].data[name]);
}
}
} else if('plot' === program.calc) {
var c = d3.nest()
.key(function(d) { return d.chapter; }) // group by chapter
.rollup(function(v){
// count group by name
return d3.nest().key(function(d) { return d.name }).rollup(function(v){
var pg = d3.nest().key(function(d) { return d.page }).rollup(function(v){ return v.length; }).map(v);
return {
chapter: v[0].chapter,
dialogue_count: v.length,
page_count: Object.keys(pg).length
}
}).map(v);
})
.map(rows);
// console.log(c);
for(key in c){
for (name in c[key]) {
console.log(fmt, +c[key][name].chapter, name, +c[key][name].dialogue_count, +c[key][name].page_count);
}
}
}// program.calc
});
count.js
最初にd3.jsを使わずに![]() つくったプログラムです。読みにくいです。途中で
つくったプログラムです。読みにくいです。途中でd3.jsを見つけてcount.jsは棄てました。count2.jsと比べるとd3.jsがとてもよくできていることがわかります。
// COMMAND LINE
// the first : tsv file path
// the second: output format (optional) (tsv|markdown)
// OUTPUT DATA
// [page#],[character#],[sentense#]
// parse and count tsv file
// ex) 1 1 5 ナレ その古い家は|森を抜けた海の|すぐ側に建っていた
// [series#] [chapter#] [page#] [character] [sentense]
var tab = require('ya-csv');
var filepath = process.argv[2],
outputFormat = process.argv[3];
if (outputFormat === undefined) outputFormat = 'tsv';
var fs = require('fs');
try {
// Query the entry
stats = fs.lstatSync(filepath);
var reader = tab.createCsvFileReader(filepath, {
'separator' : '\t'
});
var data = [];
var result = {
pages: [],
chapters: {}
};
reader.on('data', function(record) {
data.push(record);
}).on('end', function() {
for (var i=0; i<data.length; i++) {
// create object if not exists
var vals = data[i];
if(!result.chapters.hasOwnProperty('chapter' + vals[1])){
result.chapters['chapter' + vals[1]] = {};
}
// create object if not exists
if (!result.chapters['chapter' + vals[1]].hasOwnProperty('p.' + vals[2])) {
result.chapters['chapter' + vals[1]]['p.' + vals[2]] = {total: 0};
}
// create object if not exists
if (!result.chapters['chapter' + vals[1]]['p.' + vals[2]].hasOwnProperty(vals[3])) {
result.chapters['chapter' + vals[1]]['p.' + vals[2]][vals[3]] = 0;
}
// increments
result.chapters['chapter' + vals[1]]['p.' + vals[2]][vals[3]] += 1;
result.chapters['chapter' + vals[1]]['p.' + vals[2]]['total'] += 1;
} // for
// console output
console.log(result);
for (var chapter in result.chapters) {
for (var page in result.chapters[chapter]) {
if ('markdown' === outputFormat) {
console.log('|' + page.replace('p.', '') + '|' + ch + "|" + result.chapters[chapter][page][ch] + '|');
} else {
console.log(chapter.replace('chapter','') + '\t' + page.replace('p.', '') + '\t' + result.chapters[chapter][page]['total'] + "\t" + (Object.keys(result.chapters[chapter][page]).length - 1));
}
}
}
});
}
catch (e) {
console.log('error occurred');
}