こんにちは自称計量東村アキコ学第一人者の @makito です。今回は東村先生の「かくかくしかじか」のすごさを、先生のすごさを一人でも多くのひとに伝えようと。まんが大賞受賞したので、そんな必要もないかもしれませんが。
どうしよう…
こんなの
見せたら…
「天才がやってきた」
ってびっくりされちゃう…
みなさん、びっくりしないで読んでね![]()
 これまで
これまで
まんが大賞へのノミネート5作品目「かくかくしかじか」で大賞を受賞した東村アキコ作品を分析していますが、セリフのデータ化が終わる気がしないんですよ。全く。漫画読むのって楽しいはずなのに、データ化は肩がこります。
- 漫画の文字情報を使用した漫画作品の特徴抽出方法の検討
- d3.js の集計処理が強力 - 計量東村アキコ学の挑戦 - 漫画の文字情報を使用した漫画作品の特徴抽出方法の検討 その2
- 東村アキコの「主に泣いてます」のセリフからキャラクター設定をWekaを使用して分析する
これまで分析を通して感じるのは、「あぁ上手いなぁ」。売れてる漫画家なので当たり前ですが、うまいんです。某巨大掲示板ではアンチが湧いて、作品がひどくけなされていたりしますが、作品と言うか人間性批判が多かったり、まぁ、いいじゃないですか。サッカー選手の体脂肪率が高くても、点とって点取られず勝てばいいんですから。つまりそういうことです。
あくまでセリフ関係の分析をしていきますので、絵が上手いとか、コマ割りがとか、集中線がとか、フキダシがとか、フォントがとか、トーンの使い方がとか、ここは○○先生の××をパロってて、とかそういうものは取り扱えません。
 おさらい
おさらい
これまで、「主に泣いてます」第一巻のセリフ文末記号の使用頻度を分析して(こちら)、キャラクターの特徴をみました。
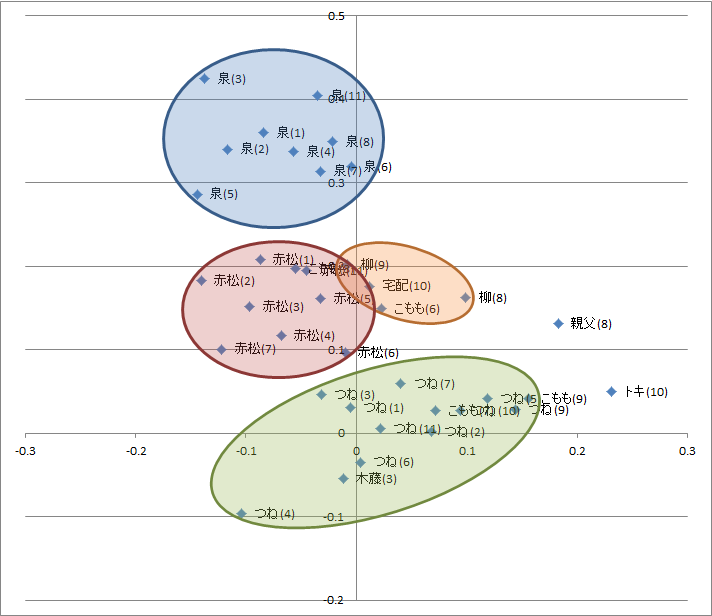
図1.「主に泣いてます」第一巻のセリフ末記号使用頻度データを主成分分析した散布図
主要キャラクターの泉、赤松、つね、柳の特徴が良くあらわれています(図1)。キャラクターのセリフ回し、セリフ末の記号に気をつけていることがうかがえます。さすがですね。神は細部に宿るのです。
「主に泣いてます」(モーニング 2010年14号 - 2013年4・5合併号)はすでに完結していますが比較的新しい作品です。今回はそれより新しいまんが大賞を受賞した「かくかくしかじか」(Cocohana 2012年1月号 - 2015年3月号)を分析してみましょう。
 「かくかくしかじか」の計量分析
「かくかくしかじか」の計量分析
「かくかくしかじか」は作者の東村アキコの自伝的エッセイギャグ漫画で、爆発的に売れた「ママはテンパリスト」と同じように自身がネタになっています。ストーリーは、絵の恩師を見捨てて自分の好き勝手に生きたこれまでの反省を描いたもので、これ読んでヒドイと思うのは世の中きれいごとで生きてるアマちゃんだけと言いますか、もっとドロドロしたこともあったと思いますが、その辺は綺麗にそぎ落とされた見事な作品だと思います。
興味のある方は是非読んでみてください。
 分析に使用したデータ
分析に使用したデータ
「かくかくしかじか」コミック版一巻(第一話~七話収録)全てとコミック版四巻の第二十二話~二十四話のセリフを次のルールに従い手でデータ化(2318件)しました。
- 吹き出しが連なった団子型の場合は団子毎に分けそれぞれひとつのセリフとする
- オノマトペはセリフに含めない
- 長い点々や波線は一文字として扱う
- 複数ビックリマークは「!」に、「!?」は「!」として扱う
- ナレーター/解説もセリフとして扱い、発言者は「ナレ」とする
最近は、アルコールやカフェインが無いと、データ化作業を続けられないような気がしています ![]() 「かくかくしかじか」の第四巻をデータ化対象にしたのは、まんが大賞選考時の最新刊として第一巻との差異を分析するためです。作品自体は第五巻で完結しています(先月の2015年3月に第五巻が出ました)。
「かくかくしかじか」の第四巻をデータ化対象にしたのは、まんが大賞選考時の最新刊として第一巻との差異を分析するためです。作品自体は第五巻で完結しています(先月の2015年3月に第五巻が出ました)。
途中で力尽きたので、第四巻は二十二~二十四話のみのデータを使います。
 セリフ末記号から見るキャラクターの役割
セリフ末記号から見るキャラクターの役割
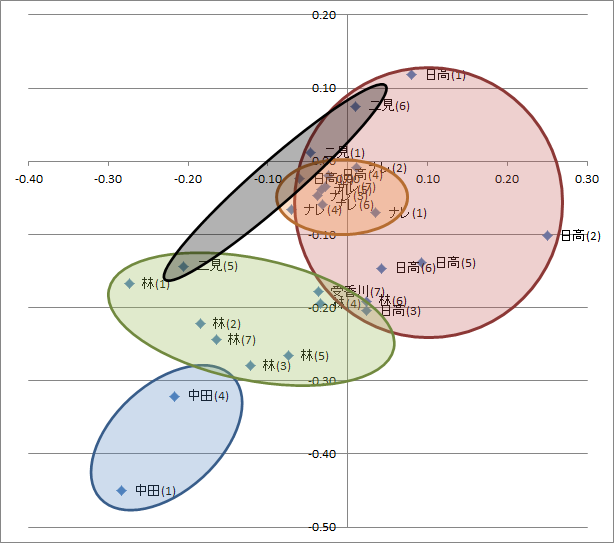
図2.「かくかくしかじか」第一巻のセリフ末記号使用頻度データを主成分分析した散布図
はい。見事にキャラクター毎に特徴が出ました。素晴らしいですね。ナレは淡々と物語を進行するのでセリフ末の記号はかなり少ない特徴があります。
中田先生いい味出してますね。二見もそのつかみどころのないキャラの特徴があらわれています。
日高先生は竹刀を持って厳しく絵の指導をするメチャクチャな先生として描かれます(第二話)が、違った一面も描かれます(第四話、七話)。その特徴も現れていて、さすがです。
第二話の熱血日高先生
ホラ
ここ!
この線
パース違います
この線もこの線も
この線も!
今 言ったとこ
全部消して
書き直して下さい
オラよし子ーッ
しっかり見て描かんか
本物と全然違うやろが
たかしもやぞ!
適当に描くなお前
絵の具がもったいない
やろが!
マジメに
やれ!
…何やとォ…?
お前まだそんなとこやっとるとか
一体そのデッサンに何時間かかっとるとか
遅い遅い遅すぎやノロマーッ
ここ見ろ お前
これ先週の水曜の
夜6時から
描いとるぞ
一体何時間
かかっとるか
計算せい!
第四話の現実的で落ち着いた日高先生
お前
知らんのか
国立でも私立でも
最近は学科の点が
悪いと いくら実技が
上手くても落とされるぞ
それにお前
国公立狙いやろが
センター試験
あるやろが
いいか
林
センター
9割取れよ
センター9割とか無茶なこと言ってますが、第二話と第四話ではまるで別人のようです。
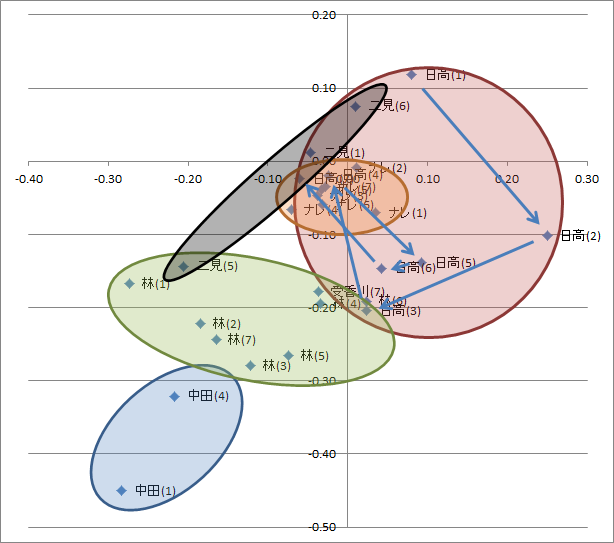
図2’.図2に日高先生の巻毎の変化に矢印を追加
図2’を見てください、見事にいろんな日高先生を描いています。竹刀でビシバシやる絵画教師、誰よりもお人好しの宮崎人気質、入試対策に現実的とかまぁいろいろです。先生の人間性を描こうとしている作者の一生懸命さが伝わってくるようです。いや~、計量分析って素敵ですね☆。
第四巻と第一巻との比較
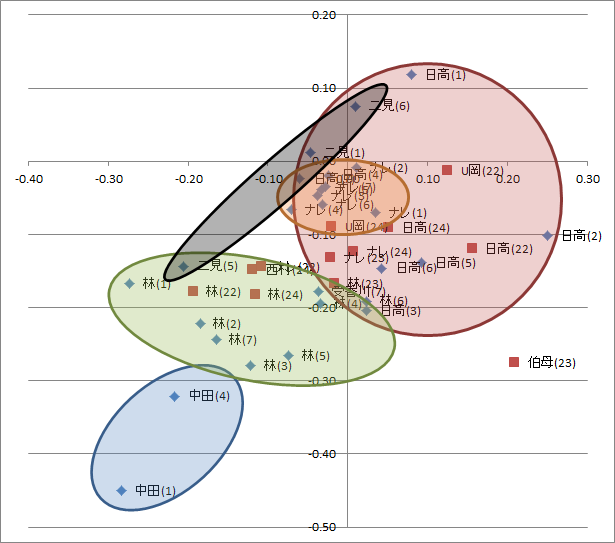
図3.第四巻二十二話~二十四話の主要キャラを追加した散布図
図3は図2に第四巻二十二話~二十四話の主要キャラクターのセリフ末記号の使用頻度のデータをもとに同じ主成分分析結果を使って散布図上に表記したものです。(※主成分分析はやり直していません、ゆるい計量分析ということでお許しを)
林、日高は第一巻と同じ傾向です。主役、準主役としてぶれてません。
興味深いのがナレと新登場のU岡です。ナレがより林に近くなった分、U岡がナレっぽい淡々とした口調で第三者的な視点をストーリーに与え、進行します。「これボツだから次よろしくね」という役をU岡がこなします。逆にナレは物語中の林の年齢が現在の年齢に近くなった分、ツッコミや批判をするようになり、第一巻のような淡々としたナレとは違う側面を見せています。そこに電話口で淡々とダメだし、ボツだしをするU岡がいることでストーリーの流れを引き締めているようです。
ナレは東村自身の声ですが、昔のボツにされた作品が恥ずかしくて口調が林化しているところも良くあらわれてます。
この辺のバランスのとり方はさすがです。
 結論
結論
というわけで、非常に面白い「かくかくしかじか」では東村アキコ先生のセリフ回しのバランス感覚といいますか、作品を締めるキャラクター設定・配置の絶妙さを見ることができるので、教科書的な作品と言ってもいいかもしれませんね。
「主に泣いてます」、「かくかくしかじか」とみてきましたが、明らかに進化していて、今後の作品も楽しみです。今は、「東京タラレバ娘」という作品の連載進行中のようです。「海月姫」も連載再開したのかな。
時間がありましたら、マン喫でも本屋でもamazonでも、東村アキコ先生の作品に触れてみてください。
あたしが世界一
おいしいと思う
食べ物なんよ!
「あたしが世界一おもしろいと思うマンガなんよ!」
 おまけ
おまけ
分析に使用したExcel
分析にExcelが欠かせません。データをざーっとグラフにして、特徴が出そうなデータにあたりをつけるときに、ぱぱぱっとグラフにしてくれるExcelが無かったら何もできません。世界一の金持ちゲイツに感謝しながらExcelのピボットテーブルとピボットグラフを使っています。
このピボットテーブルとピボットグラフは超強力です。データをセットしてしまえば
- 話毎の文字数の変化
- ページ毎の変化
- キャラクター毎の変化
とかを、数クリックでグラフ化してくれる神機能です。このピボットを使いこなすには、データの形をこんな
1 4 セリフ数 4
1 4 発言者数 2
1 4 文字数 25
1 4 平均文字数 6.25
1 5 セリフ数 20
1 5 発言者数 2
1 5 文字数 165
1 5 平均文字数 8.25
1 6 セリフ数 10
1 6 発言者数 2
感じで、[話数] [ページ] [項目] [値] のデータをつくる必要があります。データを作る時に [話数] [ページ] [セリフ数] [発言者数] [文字数] [平均文字数] みたいな形式(悪い例参照)にしてしまいそうですが、そうしないのがコツです。
悪い例:
1 4 4 2 25 6.25
1 5 20 2 165 8.25
1 6 10 2 以下続く
データ化に使ったライブラリ d3.js
手でデータを作成した後、プログラムを使ってExcelのピボットテーブルに使えるデータをつくっています。その時に使っているのが超便利な集計ライブラリd3.jsです。d3.jsはブラウザ上でのグラフ生成ライブラリとしてかなりぶっ飛んで有名ですが、集計処理だけでも素晴らしい機能を備えています。
book chapter page name dialogue
1 1 5 ナレ その古い家は|森を抜けた海の|すぐ側に建っていた
1 1 5 ナレ 皆様 初めまして|私の名前は東村アキコです|漫画家やってます
1 1 5 ナレ 昭和生まれの|現在36歳
こんなデータを、
{
"5" : [
{"book":"1", "chapter":"1", "page":"5", "name":"ナレ", "dialogue":"その古い家は|森を抜けた海の|すぐ側に建っていた"},
{"book":"1", "chapter":"1", "page":"5", "name":"ナレ", "dialogue":"皆様 初めまして|私の名前は東村アキコです|漫画家やってます"},
{"book":"1", "chapter":"1", "page":"5", "name":"ナレ", "dialogue":"昭和生まれの|現在36歳"}
]
}
という形式のオブジェクトにさっと変換できます。特にグループ化の機能が強力だと思います。
// data は読み込んだtsvファイルの内容
var rows = d3.tsv.parse(data);
// ページでグループ化する
var c = d3.nest()
.key(function(d) { return d.page; })
.map(rows);
分析に使用したWeka
主成分分析にWekaというツールを使っています。あまり使い勝手が良くないので、きっとそのうちRにかえると思いますが。Wekaでは日本語を取り扱えないので、分析の際に日本語を適当なアルファベットに置き換え、結果が出た後に日本語に戻すという作業が必要です。面倒です。
マンガ表現について思うこと
マンガが読まれるようになって一世紀もたっていないのです。若い文化です。表現手法も進化を続けているし、それは新しい挑戦をする漫画家の先生方あってのものだと思います。漫画もアニメも50年程度で日本らしいものとして定着して、すごいですね。
おまけのおまけ
身の回りにあるものを量的に分析すると新しい知識を得た感覚になったりしますが、超自己満足なんです。たいてい、感覚的というか質的に分かっていたことを確かめる作業です。それでも暇に飽かして、いろいろやって、ビール飲まなきゃやってられん ![]() と追い込まれてそれでも投げ出さないで、黙々と続けています。
と追い込まれてそれでも投げ出さないで、黙々と続けています。