自己紹介
私はKaggleであまり結果を残せていない修士一年です(私のkaggleアカウント).
実装もあまり得意な方ではなく,少しずつ理解に努めています.
本日は,
初学者がKaggleを継続的に参加するための励みになれば良いと思い記事を書きます.
結論から言うと,自作moduleを作成することだと考えました.
0. 私(atcoder茶色レベル)にとってのKaggle
私のCodingの経験はインターンや授業,趣味,競技プログラミングくらいの中でKaggleをやろうとする場合のハードルは少し高いように感じました.
理由としては,以下があります:
- notebookでのcode管理が手間. (あ)
- modelの管理を行うのが手間. (い)
- GPUの関係でlocalで作業がしづらい. (う)
- 使用するライブラリの動作を覚えるのが手間. (え)
この観点から,どのコンペにも参加しやすくなるための自作moduleをコンペへの参加を通してupdateしながら,作成するのがベストではないかと感じました.
0. (あ) notebookでのcode管理が手間
これは,notebookが長くなると出力とコードが一対一で見れないことがあるため,なるべく関数やクラスを事前に作って実装できるようにすれば良いと思います.
0. (い) modelの管理を行うのが手間
これは,毎回実装していると非常に手間であり,どこにモデルが保管されているかも管理しづらい状況であると感じているため,wandbというものを使用します.これを使用することでcloud上にモデルのweightを保存することができ,APIでいつでも取り出すことができます.
0. (う) GPUの関係で**localで作業がしづらい.
これは,localのVS-codeで自作モジュールを管理することで実装できます.またwandbなどの実験管理を使ったり、kaggleのnotebookを使用して実行をしたりするため、使用データの容量やモデルの容量はlocalの容量に置く必要はありません。
0. (え) 使用するライブラリの動作を覚えるのが手間
これは,調べたり覚えたりすれば良いのですが,毎回調べるのは面倒であるためある程度自作のmoduleを作成することで学習や作業コストを減らせると考えます.
1. 今回参加するコンペ
実際に自作moduleを作成しながら,コンペに参加してみます.
Sign Language MNIST : こちらのコンペに参加していきたいと思います(内容としてはハンドサインのアルファベットの識別です).
また,今回は自作moduleをどのように作成するかをメインと置いているため,
モデルや可視化は
コードの書き方は
- PyTorch Lightning TUTORIAL 4: INCEPTION, RESNET AND DENSENET
- PyTorch Lightning 2021 (for MLコンペ) by @fam_taro
- [Pytorch + W&B] Jigsaw Starter by Debarshi Chanda
- [講座#2] EDA・モデルの改善 by @nyk510
を参考にしました.
2. Updateを重ねるためのmoduleとは
今回参加するコンペに作成した関数やクラスが次回に参加するためのコンペに必要であるかどうかは不明です.
そのため,実質的にUpdateを重ねることは不可能な気がします.
そのため,現代回では後のアップデートを意識せず,お気持ちとして関数やクラスの前に今回のコンペという意味づけをするために,# handとコメントを残しておきます.
そして他のコンペに参加する際には,cp my_module/ new_moduleといった形でcopyをしてから必要なもの追加したり削除したりして,そのコンペ用にmoduleを作り直すことを行う必要があります.
しかし,将来的に画像系のコンペか自然言語系のコンペかといった形で,自分なりの共通点がわかり任意のコンペ用のmoduleを作ることができるかもしれません(総称型をイメージ?).
3. 自作moduleをkaggleにあげる.
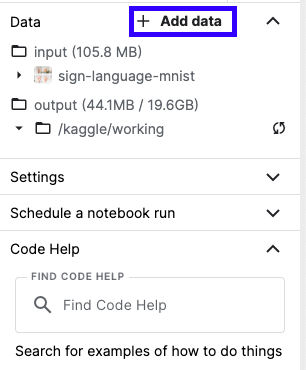
3.A. notebookの右のところから +Add data を押す.
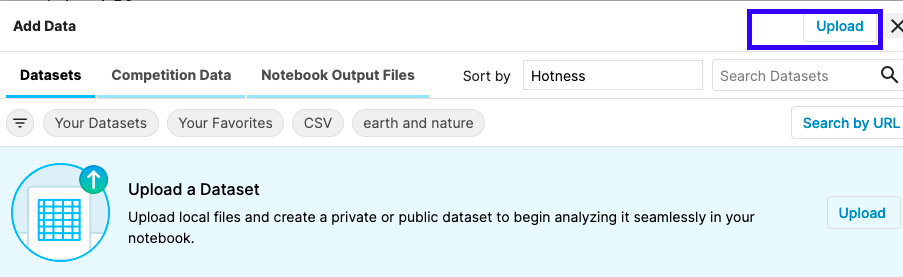
3.B. Uploadする
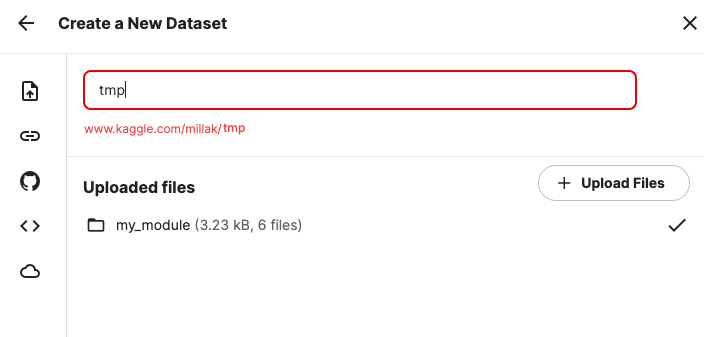
3.C. 名前を決める
Kaggleのnotebookにおける,file構成を見てみましょう(!tree ..).
..
├── input
│ ├── sign-language-mnist
│ │ ├── amer_sign2.png
│ │ ├── amer_sign3.png
│ │ ├── american_sign_language.PNG
│ │ ├── sign_mnist_test
│ │ │ └── sign_mnist_test.csv
│ │ ├── sign_mnist_test.csv
│ │ ├── sign_mnist_train
│ │ │ └── sign_mnist_train.csv
│ │ └── sign_mnist_train.csv
│ └── tmptmptmp
│ └── my_module
│ ├── 1_hand.md
│ ├── README.md
│ ├── __init__.py
│ ├── config.ini
│ ├── model.py
│ ├── preprocessing.py
│ ├── requirements.txt
│ ├── sam.py
│ ├── set_seed.py
│ ├── train.py
│ └── visualize.py
├── lib
│ └── kaggle
│ └── gcp.py
└── working
└── __notebook_source__.ipynb # 今作業しているnotebook
ここのworkingにsubmission.csvなどが作成されるようになってます.
ここからは実際のコンペのデータセットを確認していきたいと思います.
4. 可視化 A-visualize.ipnb
データを実際に可視化することを行います.
また,それと同時にvalidとtrainで分けた際の画像も表示させます.
また,labelの分布も確認します.
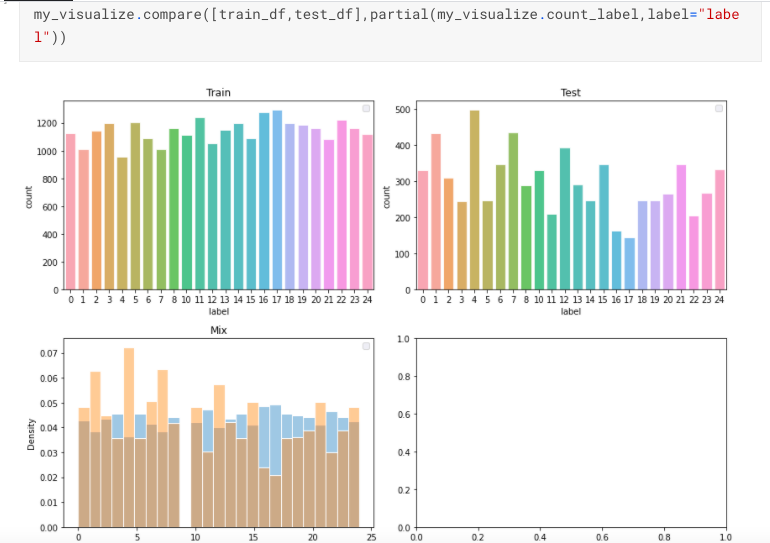
訓練データとテストデータ(普通はない可能性が高い)のhistgram
5. 訓練 B-training.ipynb
深層学習(CNN)で学習する際はGPUを用いるため,一般人の私にとってはするのは大変な気がします.
そのため,まずはtrainとvalidを一度分けて実装をしていきます.
そして良いモデルだと判断されたモデルを用いてCVを実装します.
ただ,Kaggleは時間制約があるため,あまり実装経験がない場合の人にとってはじめに作るアーキテクチャは(時間があれば論文や)Discussion,Codeを参考にするのが良いと思います.
また,慣れていない時期に自作のmodelを作成する場合はサイズが異なっている可能性があるので,試しで まず実際に動くか実装する必要があると思います.
my_models.set_seed(42)
for _ in range(1):
for one_iteration in trainloader:
xs,ys=one_iteration
break
print(xs.shape) # torch.Size([64, 1, 28, 28])
m=nn.Sequential(nn.Conv2d(1,75,3,stride=1),nn.ReLU())
inp=m(xs) # torch.Size([64, 75, 26, 26])
print(inp.shape)
今回はwandbといったものを使って,cloud上でmodelを保存します.
また,このアプリを用いることでmodelの学習過程も記録することができます.
モデルのbatchごとの勾配の様子
6. 訓練後のloadと可視化 C-after.ipynb
訓練後にloadをして可視化をしていきます.
モデルのload
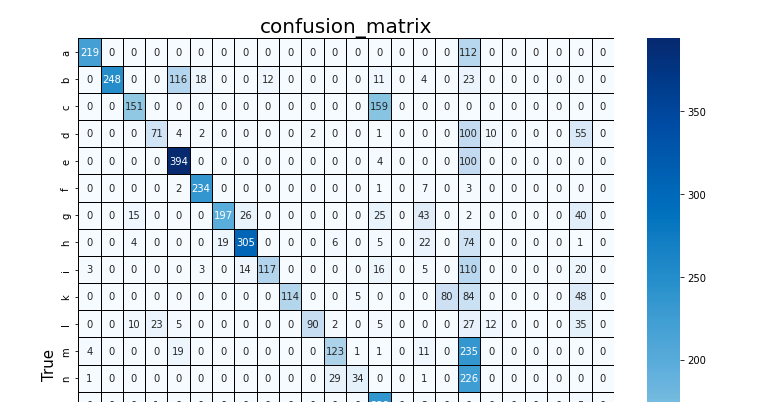
confusion matrixの可視化
そして,csvの作成ができる状態となりました.
7. ハイパーパラメータのチューニング
今回実装はしないですが,様々なtuning方法があると思います:
- 5-fold-CVの結果をもとにtuning(*)
- 訓練データを分割せずに学習する元でのtuning
ただ,現状の私の調べ的に(*)の実装をwandbで管理することは困難であることが窺えるため後者の方法のtuningが実装としては可能であると思います.
これをどうtuningするかはoptunaといったベイズ最適化の理論tuningのライブラリを使うのが良いと思います(この記事を書く前にcatch upできなかったため今後勉強します).
参考 : 『Optunaでハイパーパラメータの自動チューニング -Pytorch Lightning編-』, はやぶさの技術ノート
8. アンサンブル学習
こちらも今回は実装しないですが,学習後にアンサンブル学習を加える必要も出てくるかもしれません.
今回実装はしないですが,例えば以下があると思います.
- 画像Aと画像Bの予測が不安定だから,そのlabelづけのデータにだけモデルを加える.
- 強いモデルの予測結果を平均する.
- スタッキング(k-CVの全てのモデルの平均)を用いる.
9. 肝心なmoduleの作成方法
moduleを作成することにより,notebook自体は比較的きれいになったと思います.
ただ,作成自体は正直大変でした.
kaggle notebookで実行をしてErrorが出て,moduleを訂正してuploadをする...
といった作業の繰り返しで,その量は多く慣れていない分だけ大変でした.
(moduleの作成方法に関して,何かあればコメントください🙇♂️)
しかし,一度moduleを作って終えば,
notebookに直書きするよりかは,綺麗にコードをまとめながら実装できると思いました.
また,moduleをコンペを参加するごとに訂正するとなれば,読みやすいコード(変数の型やコメントをしっかり残すなど)を作成することなどコーディングの基礎(というか根幹?)となる部分を自ずと意識できて,データ分析のみならずコーディング全般の勉強にもなるのかなと思いました.
10. 最後に
最後までお読みいただきありがとうございます.
読んでいただいた方の参考になれば幸いです。
今後は,Kaggleの参加を通して,moduleの内容や可読性を上げつつ積極的にnotebookを読みモデルや分析する時間を設けていきたいと思います。