はじめに
この記事では,事前学習済みモデルを使って犬猫判定AIを作って,ブラウザ上で動かすまでの流れをまとめます.犬猫判定AIは深層学習の勉強で初心者向けの課題としてしばしば登場するので,二番煎じどころか百番煎じくらいになるかと思いますがご了承ください...
大まかな手順
モデルを動かすまでの手順は以下の通りです.
- 学習用データを準備する
- Python+Pytorchでモデルを設計する
- モデルを学習させる
- ブラウザ上で動くようにする
ではさっそく始めましょう!
学習データの用意
今回は犬猫判定AIを作るため,犬と猫の画像を用意する必要があります.KaggleにあるCat and Dogデータセットを使ってみます.Kaggleは会員登録こそ必要ですが,さまざまな目的の機械学習・深層学習プロジェクトで用いることのできるデータが潤沢にしかも無料で用意されています!
このデータセットには犬と猫の画像が約1000枚ずつ格納されています.

無事に学習データをダウンロードできたら,作業用ディレクトリにデータを格納しましょう.今回は以下のようなディレクトリ構成にしています.細かいプログラムは後ほど解説します.
├training_set-cats-cat.1.jpg
| | └...
| └dogs-dog.1.jpg
| └...
├test_set (内部構造はtraining_setと同じ)
├network.py (モデルを定義するコード)
├train.py (学習ループを回すコード)
├model.pth (学習されたモデル)
├app.py (flaskを用いたバックエンド)
└templates-index.html (ブラウザ上で動く)
モデルの設計
深層学習のコードはPython上で動作する深層学習用フレームワークであるPyTorchを用いて実装されることが多いです.今回もPyTorchを利用します.(他のフレームワークとしてはTensorFlowや深層学習ではない古典的な機械学習だとscikit-Learnが有名です.)
Pytorchのインストール方法はネット上で調べてみましょう(GPU周りとの相性があるので自身の環境に応じて最適なインストールをしましょう).私はuvでPythonの環境構築をしているので,Astral社の公式資料を参考にしました.
前置きが長くなりましたが,モデルのコードを以下に示します.
import torch.nn as nn
from torchvision import models
from torchvision.models import ResNet18_Weights
def dog_cat_classifier(num_classes=2, freeze_features=True):
model = models.resnet18(weights=ResNet18_Weights.DEFAULT)
if freeze_features:
for param in model.parameters():
param.requires_grad = False
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, num_classes)
return model
model = dog_cat_classifier()
今回は画像認識の分野で著名なモデルであるResNet-18をファインチューニングする形で実装します.0から自分オリジナルのAIを作りたいという場合には畳み込みニューラルネットワークなどを自分で設計するのも良いと思いますが,早く実装したい!高い精度が欲しい!という人は有名な事前学習済みモデルを使用すると良いでしょう.
モデルの学習
学習済みモデルを利用するとはいえ,自身のタスクに応じてファインチューニングする必要があり,このときにはモデルの学習が必要です.私はAppleシリコンを搭載したMacを使用しており,学習にはAppleシリコンのGPUを利用できるため,ノートPCでもある程度の学習ができるようになったと感動しています.そんなことはどうでもいいですが,以下に学習を回すためのコードを示します.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import transforms
import wandb
from network import dog_cat_classifier
wandb.init(
project="dog-cat-classification",
config={
"learning_rate": 1e-3,
"epochs": 10,
"batch_size": 32,
"architecture": "dog_cat_classifier",
"dataset": "Dog-Cat-Dataset",
},
)
config = wandb.config
# 訓練用:ランダムな処理を加えて,データのバリエーションを増やす
train_transform = transforms.Compose(
[
transforms.RandomResizedCrop(224), # ランダムに切り抜いて224に
transforms.RandomHorizontalFlip(), # 左右反転
transforms.RandomRotation(15), # 15度以内の回転
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
# 検証用:ランダム性は入れず,中央切り抜きのみ
val_transform = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
if torch.backends.mps.is_available():
device = torch.device("mps")
elif torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
print(f"Using device: {device}")
train_dataset = torchvision.datasets.ImageFolder(
root="./training_set", transform=train_transform
)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=config.batch_size, shuffle=True
)
val_dataset = torchvision.datasets.ImageFolder(
root="./test_set", transform=val_transform
)
val_loader = torch.utils.data.DataLoader(
val_dataset, batch_size=config.batch_size, shuffle=False
)
model = dog_cat_classifier().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
epochs = config.epochs
wandb.watch(model, log="all") # wandbで学習の経過観察
# train_losses, val_losses = [], []
for epoch in range(epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * images.size(0)
train_loss = running_loss / len(train_loader.dataset)
# Validation
model.eval()
val_loss = 0.0
correct = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item() * images.size(0)
_, preds = torch.max(outputs, 1)
correct += torch.sum(preds == labels.data)
val_loss /= len(val_loader.dataset)
val_acc = correct.float() / len(val_loader.dataset)
wandb.log(
{
"epoch": epoch + 1,
"train_loss": train_loss,
"val_loss": val_loss,
"val_accuracy": val_acc,
}
)
print(
f"Epoch {epoch + 1}/{config.epochs} | Train Loss: {train_loss: .4f} | Val Loss: {val_loss: .4f} | Val Acc: {val_acc: .4f}"
)
torch.save(model.state_dict(), "model_weights.pth")
# wandb.save("model_weights.pth") 学習済みモデルをクラウドに保存したいとき
wandb.finish() # wandbの終了命令
ハイパーパラメータは以下のような設定です.
- 学習率: 0.001
- エポック数: 10
- バッチサイズ: 32
- 誤差関数: 交差エントロピー
- パラメータ更新アルゴリズム: Adam
至って普通のコードだと思いますが,工夫した点としてはWeights and Biases(WandB)を用いて学習結果の管理をしていることです.WandBを使うと,損失の推移や精度の可視化などの情報を簡単に取得し,クラウド上で保存することができ大変便利です.アカウント作成も無料で行うことができ,スマホなどから簡単に学習結果を見ることができるのでおすすめです.午前中モデルを設計し,学習をはじめ,午後から外出して遊んでいるときに,スマホから学習の様子を見ることができるというわけです(笑)
今回は学習にも時間がかからない(M4 MacBook airで10epoch学習させて10分程度)のであっという間にモデルが出来上がります.学習されたモデルは.pthファイルで保存しましょう.
学習が終わったら,いくつかのデータを用いてテストしてみましょう.例えば,ブラウザで犬か猫(もちろん自分の好きな芸能人の顔画像とかでも良いですが)の画像URLを取得してモデルに読み込ませるということができるかもしれません.
ブラウザ上で動かしてみる
ここが本記事の目的とも言える箇所です.私を含め,深層学習に興味のある方はモデルを作ってテストして良い精度が出たから満足という場合が多いかと思います.しかし,実用面を考えると,作ったモデルをwebアプリとして動くようにする(場合によってはデプロイして世界に公開する)までがゴールと言えるかもしれません.私はwebアプリケーションの作成経験が乏しいのでその練習も兼ねて作ろうと思います.
今回使うフレームワークはFlaskです.Pythonで動かすことができる,小規模なwebアプリケーション向けのフレームワークです.以下にバックエンドで動作するコードを示します.
from io import BytesIO
import requests
import torch
import torch.nn.functional as F
import torchvision.transforms as transforms
from flask import Flask, jsonify, render_template, request
from PIL import Image
from network import dog_cat_classifier
app = Flask(__name__)
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model = dog_cat_classifier()
model.load_state_dict(torch.load("model_weights.pth", map_location=device))
model.to(device)
model.eval()
def predict(url):
transform = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
response = requests.get(url)
img = Image.open(BytesIO(response.content)).convert("RGB")
img_transformed = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
output = model(img_transformed)
probability = F.softmax(output, dim=1)[0]
_, predicted = torch.max(output, 1)
class_names = ["Cat", "Dog"]
return {
"prediction": class_names[predicted.item()],
"cat_prob": f"{probability[0].item():.4f}",
"dog_prob": f"{probability[1].item():.4f}",
}
@app.route("/")
def index():
return render_template("index.html")
@app.route("/predict", methods=["POST"])
def run_predict():
data = request.json
url = data.get("url")
try:
result = predict(url)
return jsonify(result)
except Exception as e:
return jsonify({"error": str(e)}), 400
if __name__ == "__main__":
app.run(debug=True, port=5000)
web上にある画像のURLを取得し,画像をリサイズしてモデルに読み込ませ,画像を分類します.そして,フロントエンドのコードは以下のようにしました.
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>DogCatAI</title>
<style>
body {
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, sans-serif;
background-color: #fff;
color: #1a1a1a;
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
margin: 0;
}
.container {
width: 90%;
max-width: 400px;
text-align: center;
}
h1 {
font-weight: 300;
letter-spacing: 2px;
font-size: 1.2rem;
margin-bottom: 40px;
}
input[type="text"] {
width: 100%;
padding: 12px 0;
border: none;
border-bottom: 1px solid #ddd;
outline: none;
transition: border-color 0.3s;
font-size: 0.9rem;
margin-bottom: 20px;
}
input[type="text"]:focus {
border-bottom: 1px solid #1a1a1a;
}
button {
background: #1a1a1a;
color: #fff;
border: none;
padding: 10px 25px;
cursor: pointer;
font-size: 0.8rem;
letter-spacing: 1px;
transition: opacity 0.3s;
}
button:hover {
opacity: 0.8;
}
#result-area {
margin-top: 40px;
display: none;
}
#preview {
max-width: 100%;
height: auto;
margin-bottom: 20px;
filter: grayscale(20%); /* 少し落ち着いた色味に */
}
.info {
font-size: 0.9rem;
line-height: 1.6;
}
.label { font-weight: bold; }
</style>
</head>
<body>
<div class="container">
<h1>Dog or Cat</h1>
<input type="text" id="urlInput" placeholder="Paste image URL here...">
<br>
<button onclick="analyze()">Analyze</button>
<div id="result-area">
<img id="preview" src="" alt="Preview">
<div class="info">
<div id="res-class" class="label"></div>
<div id="res-prob"></div>
</div>
</div>
</div>
<script>
async function analyze() {
const url = document.getElementById('urlInput').value;
const resultArea = document.getElementById('result-area');
const preview = document.getElementById('preview');
if (!url) return;
preview.src = url;
resultArea.style.display = 'block';
document.getElementById('res-class').innerText = 'Analyzing...';
document.getElementById('res-prob').innerText = '';
try {
const response = await fetch('/predict', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ url: url })
});
const data = await response.json();
if (data.error) {
document.getElementById('res-class').innerText = 'Error';
document.getElementById('res-prob').innerText = 'Could not load image.';
} else {
document.getElementById('res-class').innerText = `RESULT: ${data.prediction}`;
document.getElementById('res-prob').innerText = `Cat: ${data.cat_prob * 100} / Dog: ${data.dog_prob*100}`;
}
} catch (e) {
console.error(e);
}
}
</script>
</body>
</html>
webデザインの知識は全くないのでAIにいい感じのデザインを作ってもらいました(笑)
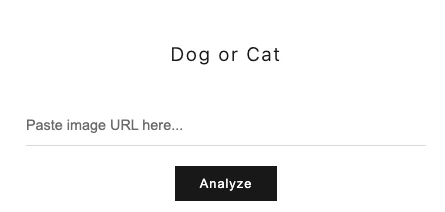
ここまでで,犬猫判定AIをブラウザ上で動かす準備ができました.コマンド上でuv run app.pyとするとアプリへのURLが表示されるのでそれをブラウザにコピペしましょう.以下のような画面になるはずです.
ここに適当な犬の画像をコピペし,Analyzeというボタンを押すと,以下のように画像分類が実施されます.
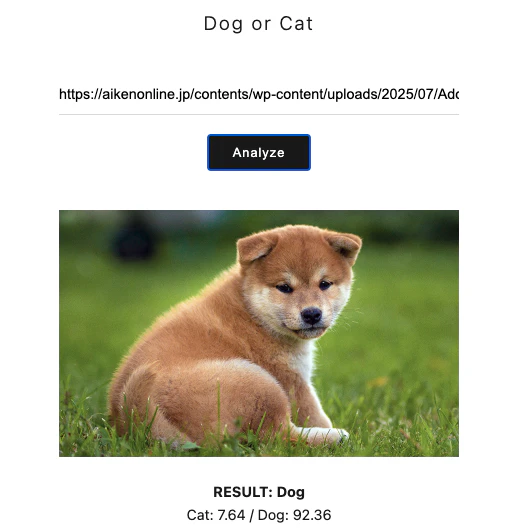
こちらの犬はAIにも「犬」として認識されたようです.おめでとうございます(?)
無事に犬猫判定AIをブラウザ上で動かすことができました!
おわりに
今回は学習されたモデルをwebアプリとして動かす方法を解説しました.正直,このタスクはChatGPTやGeminiに聞けば一発で犬か猫か教えてくれると思いますが,自分で作ってみるという経験も大切だと思います.何より自分オリジナルのモデルを作れたという喜びは大きいものです.ぜひ挑戦してみてください!