はじめに
「XX分でできるBERT」シリーズ第二弾です。
(第一弾の記事はこちら → 60分でできるBERT(英語テキストの感情分析))
今回は、事前学習モデルを使って、そのまま予測するので、学習が不要、よって、本当に10分かからずにBERTの予測モデルを動かすことができます。
Question-Answering予測とは
BERTが活用できるテキスト分析のパターンの一つです。入力として「ヒントとなる一連のテキスト」と「そのテキストを前提とした質問」の対になる文をモデルに入力します。すると、モデルはヒントとなるテキストの特定の範囲を FromとToのインデックスで示します。
この範囲の文章が、質問への回答となっている仕掛けです。

BERTでは、このような振る舞いをする事前学習済みモデルがすでにできあがっていて、モデルをロードするだけで、学習なしに予測ができるというのです。本当なのか、早速試してみましょう。
実習プログラムの前提
前回に引き続き、英語のテキスト分析を対象にしています。
実行環境は、だれでも簡単に構築できるように、Google Colabを前提としました。
フレームワークはPyTorchです。
検証データは。 CoQAデータセットを使いました。
CoQAは、質問応答システムを構築するための大規模なデータセットです。CoQAチャレンジの目標は、テキストのパッセージを理解し、会話に現れる一連の相互に関連する質問に答える機械学習モデルの性能を測定することです。
なお、サンプルプログラムの下敷きにしたコードは
https://bit.ly/3IJzzIb
に記載されていたものです。
コード解説
以下でサンプルコードの解説を行います。なお、コードの全量は、下記にアップしてあります。
ライブラリ導入
最初は、必要なライブラリの導入とインポートです。
# transformersの導入
!pip install transformers | tail -n 1
# ライブラリのインポート
import pandas as pd
import numpy as np
from IPython.display import display
import torch
from transformers import BertForQuestionAnswering
from transformers import BertTokenizer
テキストデータ準備
実は、今回のコード解説のかなりの部分は、テキストデータ準備に費やされています。しかし、テキスト分析系のモデルの場合、前処理に手間がかかることが多いので、省略せずに全部載せることにします。
CoQA訓練用データの読み込み
CoQAデータをインターネットサイトから読み込みます。データはjson形式になっているので、read_json関数を使います。
# 訓練用データ読み込み
coqa = pd.read_json('http://downloads.cs.stanford.edu/nlp/data/coqa/coqa-train-v1.0.json')
# データの確認
display(coqa.head())
結果は下のような形になるはずです。

読み込みデータ確認
このデータがどういう状態で入っているのか、先頭行を抜き出して確認してみます。
# データの先頭行の内容表示
item = coqa.loc[0,'data']
print(item)
{'source': 'wikipedia', 'id': '3zotghdk5ibi9cex97fepx7jetpso7', 'filename': 'Vatican_Library.txt', 'story': 'The Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, is the library of the Holy See, located in Vatican City. Formally established in 1475, although it is much older, it is one of the oldest libraries in the world and contains one of the most significant collections of historical texts. It has 75,000 codices from throughout history, as well as 1.1 million printed books, which include some 8,500 incunabula. \n\nThe Vatican Library is a research library for history, law, philosophy, science and theology. The Vatican Library is open to anyone who can document their qualifications and research needs. Photocopies for private study of pages from books published between 1801 and 1990 can be requested in person or by mail. \n\nIn March 2014, the Vatican Library began an initial four-year project of digitising its collection of manuscripts, to be made available online. \n\nThe Vatican Secret Archives were separated from the library at the beginning of the 17th century; they contain another 150,000 items. \n\nScholars have traditionally divided the history of the library into five periods, Pre-Lateran, Lateran, Avignon, Pre-Vatican and Vatican. \n\nThe Pre-Lateran period, comprising the initial days of the library, dated from the earliest days of the Church. Only a handful of volumes survive from this period, though some are very significant.', 'questions': [{'input_text': 'When was the Vat formally opened?', 'turn_id': 1}, {'input_text': 'what is the library for?', 'turn_id': 2}, {'input_text': 'for what subjects?', 'turn_id': 3}, {'input_text': 'and?', 'turn_id': 4}, {'input_text': 'what was started in 2014?', 'turn_id': 5}, {'input_text': 'how do scholars divide the library?', 'turn_id': 6}, {'input_text': 'how many?', 'turn_id': 7}, {'input_text': 'what is the official name of the Vat?', 'turn_id': 8}, {'input_text': 'where is it?', 'turn_id': 9}, {'input_text': 'how many printed books does it contain?', 'turn_id': 10}, {'input_text': 'when were the Secret Archives moved from the rest of the library?', 'turn_id': 11}, {'input_text': 'how many items are in this secret collection?', 'turn_id': 12}, {'input_text': 'Can anyone use this library?', 'turn_id': 13}, {'input_text': 'what must be requested to view?', 'turn_id': 14}, {'input_text': 'what must be requested in person or by mail?', 'turn_id': 15}, {'input_text': 'of what books?', 'turn_id': 16}, {'input_text': 'What is the Vat the library of?', 'turn_id': 17}, {'input_text': 'How many books survived the Pre Lateran period?', 'turn_id': 18}, {'input_text': 'what is the point of the project started in 2014?', 'turn_id': 19}, {'input_text': 'what will this allow?', 'turn_id': 20}], 'answers': [{'span_start': 151, 'span_end': 179, 'span_text': 'Formally established in 1475', 'input_text': 'It was formally established in 1475', 'turn_id': 1}, {'span_start': 454, 'span_end': 494, 'span_text': 'he Vatican Library is a research library', 'input_text': 'research', 'turn_id': 2}, {'span_start': 457, 'span_end': 511, 'span_text': 'Vatican Library is a research library for history, law', 'input_text': 'history, and law', 'turn_id': 3}, {'span_start': 457, 'span_end': 545, 'span_text': 'Vatican Library is a research library for history, law, philosophy, science and theology', 'input_text': 'philosophy, science and theology', 'turn_id': 4}, {'span_start': 769, 'span_end': 879, 'span_text': 'March 2014, the Vatican Library began an initial four-year project of digitising its collection of manuscripts', 'input_text': 'a project', 'turn_id': 5}, {'span_start': 1048, 'span_end': 1127, 'span_text': 'Scholars have traditionally divided the history of the library into five period', 'input_text': 'into periods', 'turn_id': 6}, {'span_start': 1048, 'span_end': 1128, 'span_text': 'Scholars have traditionally divided the history of the library into five periods', 'input_text': 'five', 'turn_id': 7}, {'span_start': 4, 'span_end': 94, 'span_text': 'Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, ', 'input_text': 'The Vatican Apostolic Library', 'turn_id': 8}, {'span_start': 94, 'span_end': 150, 'span_text': 'is the library of the Holy See, located in Vatican City.', 'input_text': 'in Vatican City', 'turn_id': 9}, {'span_start': 328, 'span_end': 412, 'span_text': ' It has 75,000 codices from throughout history, as well as 1.1 million printed books', 'input_text': '1.1 million', 'turn_id': 10}, {'span_start': 917, 'span_end': 1009, 'span_text': 'atican Secret Archives were separated from the library at the beginning of the 17th century;', 'input_text': 'at the beginning of the 17th century;', 'turn_id': 11}, {'span_start': 915, 'span_end': 1046, 'span_text': ' Vatican Secret Archives were separated from the library at the beginning of the 17th century; they contain another 150,000 items. ', 'input_text': '150,000', 'turn_id': 12}, {'span_start': 546, 'span_end': 643, 'span_text': ' The Vatican Library is open to anyone who can document their qualifications and research needs. ', 'input_text': 'anyone who can document their qualifications and research needs.', 'turn_id': 13}, {'span_start': -1, 'span_end': -1, 'span_text': 'unknown', 'input_text': 'unknown', 'turn_id': 14, 'bad_turn': 'true'}, {'span_start': 643, 'span_end': 764, 'span_text': 'Photocopies for private study of pages from books published between 1801 and 1990 can be requested in person or by mail. ', 'input_text': 'Photocopies', 'turn_id': 15}, {'span_start': 644, 'span_end': 724, 'span_text': 'hotocopies for private study of pages from books published between 1801 and 1990', 'input_text': 'only books published between 1801 and 1990', 'turn_id': 16}, {'span_start': 78, 'span_end': 125, 'span_text': 'simply the Vat, is the library of the Holy See,', 'input_text': 'the Holy See', 'turn_id': 17}, {'span_start': 1192, 'span_end': 1384, 'span_text': 'Pre-Lateran period, comprising the initial days of the library, dated from the earliest days of the Church. Only a handful of volumes survive from this period, though some are very significant', 'input_text': 'a handful of volumes', 'turn_id': 18}, {'span_start': 785, 'span_end': 881, 'span_text': 'Vatican Library began an initial four-year project of digitising its collection of manuscripts, ', 'input_text': 'digitising manuscripts', 'turn_id': 19}, {'span_start': 868, 'span_end': 910, 'span_text': 'manuscripts, to be made available online. ', 'input_text': 'them to be viewed online.', 'turn_id': 20}], 'name': 'Vatican_Library.txt'}
どんなキー項目があるので確認します。
# キーの確認
print(item.keys())
dict_keys(['source', 'id', 'filename', 'story', 'questions', 'answers', 'name'])
この中で重要なのがstory, questions, answers の3つです。
storyには、ヒントとなる文章が入っています。questionsとanswersは、その質問と回答の対です。一つの文章では、複数の質問、回答の対を含んでいます。
まず、storyを表示してみます。
# storyの表示
print(item['story'])
The Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, is the library of the Holy See, located in Vatican City. Formally established in 1475, although it is much older, it is one of the oldest libraries in the world and contains one of the most significant collections of historical texts. It has 75,000 codices from throughout history, as well as 1.1 million printed books, which include some 8,500 incunabula.
The Vatican Library is a research library for history, law, philosophy, science and theology. The Vatican Library is open to anyone who can document their qualifications and research needs. Photocopies for private study of pages from books published between 1801 and 1990 can be requested in person or by mail.
In March 2014, the Vatican Library began an initial four-year project of digitising its collection of manuscripts, to be made available online.
The Vatican Secret Archives were separated from the library at the beginning of the 17th century; they contain another 150,000 items.
Scholars have traditionally divided the history of the library into five periods, Pre-Lateran, Lateran, Avignon, Pre-Vatican and Vatican.
The Pre-Lateran period, comprising the initial days of the library, dated from the earliest days of the Church. Only a handful of volumes survive from this period, though some are very significant.
次にquestionsを1行ずつ表示してみます。
# questionsの表示
for text in item['questions']:
print(text)
{'input_text': 'When was the Vat formally opened?', 'turn_id': 1}
{'input_text': 'what is the library for?', 'turn_id': 2}
{'input_text': 'for what subjects?', 'turn_id': 3}
{'input_text': 'and?', 'turn_id': 4}
{'input_text': 'what was started in 2014?', 'turn_id': 5}
{'input_text': 'how do scholars divide the library?', 'turn_id': 6}
{'input_text': 'how many?', 'turn_id': 7}
{'input_text': 'what is the official name of the Vat?', 'turn_id': 8}
{'input_text': 'where is it?', 'turn_id': 9}
{'input_text': 'how many printed books does it contain?', 'turn_id': 10}
{'input_text': 'when were the Secret Archives moved from the rest of the library?', 'turn_id': 11}
{'input_text': 'how many items are in this secret collection?', 'turn_id': 12}
{'input_text': 'Can anyone use this library?', 'turn_id': 13}
{'input_text': 'what must be requested to view?', 'turn_id': 14}
{'input_text': 'what must be requested in person or by mail?', 'turn_id': 15}
{'input_text': 'of what books?', 'turn_id': 16}
{'input_text': 'What is the Vat the library of?', 'turn_id': 17}
{'input_text': 'How many books survived the Pre Lateran period?', 'turn_id': 18}
{'input_text': 'what is the point of the project started in 2014?', 'turn_id': 19}
{'input_text': 'what will this allow?', 'turn_id': 20}
全部で20個の質問が入っておました。次に同じように対応する answerを1行ずつ表示してみます。
# answersの表示
for text in item['answers']:
print(text)
{'span_start': 151, 'span_end': 179, 'span_text': 'Formally established in 1475', 'input_text': 'It was formally established in 1475', 'turn_id': 1}
{'span_start': 454, 'span_end': 494, 'span_text': 'he Vatican Library is a research library', 'input_text': 'research', 'turn_id': 2}
{'span_start': 457, 'span_end': 511, 'span_text': 'Vatican Library is a research library for history, law', 'input_text': 'history, and law', 'turn_id': 3}
{'span_start': 457, 'span_end': 545, 'span_text': 'Vatican Library is a research library for history, law, philosophy, science and theology', 'input_text': 'philosophy, science and theology', 'turn_id': 4}
{'span_start': 769, 'span_end': 879, 'span_text': 'March 2014, the Vatican Library began an initial four-year project of digitising its collection of manuscripts', 'input_text': 'a project', 'turn_id': 5}
{'span_start': 1048, 'span_end': 1127, 'span_text': 'Scholars have traditionally divided the history of the library into five period', 'input_text': 'into periods', 'turn_id': 6}
{'span_start': 1048, 'span_end': 1128, 'span_text': 'Scholars have traditionally divided the history of the library into five periods', 'input_text': 'five', 'turn_id': 7}
{'span_start': 4, 'span_end': 94, 'span_text': 'Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, ', 'input_text': 'The Vatican Apostolic Library', 'turn_id': 8}
{'span_start': 94, 'span_end': 150, 'span_text': 'is the library of the Holy See, located in Vatican City.', 'input_text': 'in Vatican City', 'turn_id': 9}
{'span_start': 328, 'span_end': 412, 'span_text': ' It has 75,000 codices from throughout history, as well as 1.1 million printed books', 'input_text': '1.1 million', 'turn_id': 10}
{'span_start': 917, 'span_end': 1009, 'span_text': 'atican Secret Archives were separated from the library at the beginning of the 17th century;', 'input_text': 'at the beginning of the 17th century;', 'turn_id': 11}
{'span_start': 915, 'span_end': 1046, 'span_text': ' Vatican Secret Archives were separated from the library at the beginning of the 17th century; they contain another 150,000 items. ', 'input_text': '150,000', 'turn_id': 12}
{'span_start': 546, 'span_end': 643, 'span_text': ' The Vatican Library is open to anyone who can document their qualifications and research needs. ', 'input_text': 'anyone who can document their qualifications and research needs.', 'turn_id': 13}
{'span_start': -1, 'span_end': -1, 'span_text': 'unknown', 'input_text': 'unknown', 'turn_id': 14, 'bad_turn': 'true'}
{'span_start': 643, 'span_end': 764, 'span_text': 'Photocopies for private study of pages from books published between 1801 and 1990 can be requested in person or by mail. ', 'input_text': 'Photocopies', 'turn_id': 15}
{'span_start': 644, 'span_end': 724, 'span_text': 'hotocopies for private study of pages from books published between 1801 and 1990', 'input_text': 'only books published between 1801 and 1990', 'turn_id': 16}
{'span_start': 78, 'span_end': 125, 'span_text': 'simply the Vat, is the library of the Holy See,', 'input_text': 'the Holy See', 'turn_id': 17}
{'span_start': 1192, 'span_end': 1384, 'span_text': 'Pre-Lateran period, comprising the initial days of the library, dated from the earliest days of the Church. Only a handful of volumes survive from this period, though some are very significant', 'input_text': 'a handful of volumes', 'turn_id': 18}
{'span_start': 785, 'span_end': 881, 'span_text': 'Vatican Library began an initial four-year project of digitising its collection of manuscripts, ', 'input_text': 'digitising manuscripts', 'turn_id': 19}
{'span_start': 868, 'span_end': 910, 'span_text': 'manuscripts, to be made available online. ', 'input_text': 'them to be viewed online.', 'turn_id': 20}
データ加工
今、確認した、 story, questions, answersをデータフレームから直接アクセスできるように加工します。ここは、今回の記事の本質でないので、コードのみ示します。
# テキスト(text)、質問(question)、回答(answer)の抽出
# 一つのテキストに対して質問、回答のペアは複数対応
cols = ["text","question","answer"]
# 抽出リストの1行分
comp_list = []
for index, row in coqa.iterrows():
# 質問の個数だけ繰り返し
for i in range(len(row["data"]["questions"])):
temp_list = []
# text
temp_list.append(row["data"]["story"])
# i番目の質問
temp_list.append(row["data"]["questions"][i]["input_text"])
# i番目の回答
temp_list.append(row["data"]["answers"][i]["input_text"])
# リストのリストを生成
comp_list.append(temp_list)
# comp_listからデータフレームを生成
data = pd.DataFrame(comp_list, columns=cols)
# 2度目以降のために、csvファイルとしても保存
data.to_csv("CoQA_data.csv", index=False)
加工後データ確認
データの先頭と最後の中身を確認してみます。
# 先頭と、最後の内容表示
display(data.head())
display(data.tail())
こんな結果になるはずです。

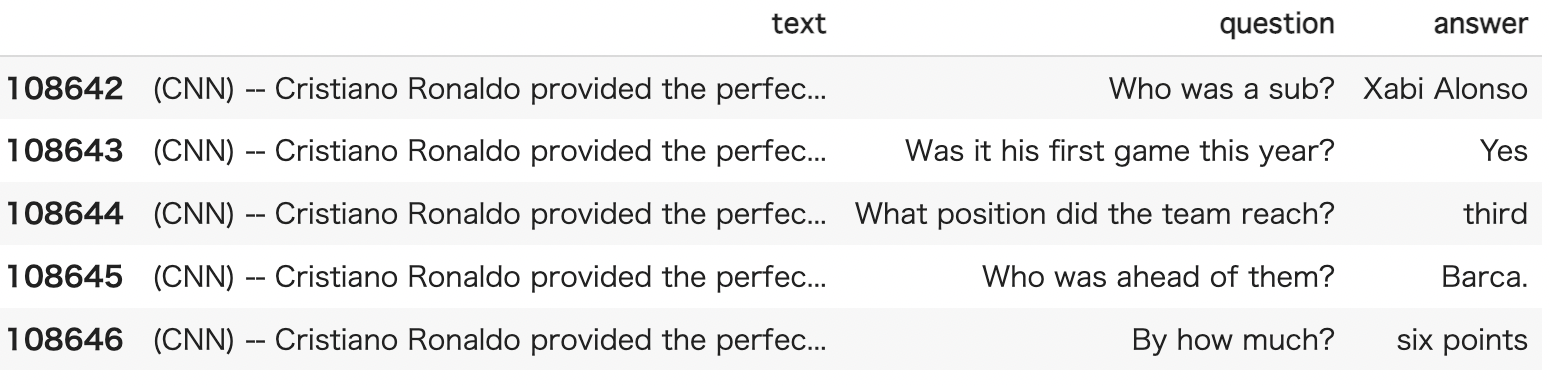
こうやって準備したデータセットのうち、10番目のものを取り出して表示してみます。
# 10番目の要素ののtext, question, answerの確認
index = 10
print(f'Text: \n{data.loc[index].text}\n' )
print(f'Question: {data.loc[index].question}\n' )
print(f'Answer: {data.loc[index].answer}\n')
Text:
The Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, is the library of the Holy See, located in Vatican City. Formally established in 1475, although it is much older, it is one of the oldest libraries in the world and contains one of the most significant collections of historical texts. It has 75,000 codices from throughout history, as well as 1.1 million printed books, which include some 8,500 incunabula.
The Vatican Library is a research library for history, law, philosophy, science and theology. The Vatican Library is open to anyone who can document their qualifications and research needs. Photocopies for private study of pages from books published between 1801 and 1990 can be requested in person or by mail.
In March 2014, the Vatican Library began an initial four-year project of digitising its collection of manuscripts, to be made available online.
The Vatican Secret Archives were separated from the library at the beginning of the 17th century; they contain another 150,000 items.
Scholars have traditionally divided the history of the library into five periods, Pre-Lateran, Lateran, Avignon, Pre-Vatican and Vatican.
The Pre-Lateran period, comprising the initial days of the library, dated from the earliest days of the Church. Only a handful of volumes survive from this period, though some are very significant.
Question: when were the Secret Archives moved from the rest of the library?
Answer: at the beginning of the 17th century;
このデータは、後ほど予測の時にも使うことにしますので、結果を覚えておいて下さい。
参考までに、今、準備したデータセットは、全部で10万件のQuestion/Answerの組を持っています。
# データの総数
print("Number of question and answers: ", len(data))
Number of question and answers: 108647
かなり長くなってしまいましたが、以上でデータ準備は完了です。最後に作ったデータフレームのデータはCSVにも落としてありますので、PCにダウンロードしておけば、2度目以降はこの面倒な加工はしなくても済みます。
BERT QAモデルの読み込み
いよいよ事前学習済みモデルを読み込みます。実装は、下記になります。
model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
モデルを読み込むと同時にtokenizerのインスタンスも生成します。これは、前回の時と同じで、BERTを使う場合のお作法みたいな感じです。
BERTによる予測
読み込んだモデルを使って、予測をしてみます。
特定の1セットの抽出
予測は、先ほど内容をしめした10番目のデータに対して行います。下記のコードでINDEXの値を差し替えれば、そのまま他のデータに対する予測になるので、読者の方は、各自でいろいろ試してみて下さい。
# 特定の1セットを抽出
index = 10
text = data["text"][index]
question = data["question"][index]
answer = data["answer"][index]
入力データのエンコード
tokenizerを使って、入力データを整数値の配列にエンコードします。
# 質問、テキストの組をエンコードする
input_ids = tokenizer.encode(question, text)
# エンコードの値から逆向きにトークンの一覧を取得
tokens = tokenizer.convert_ids_to_tokens(input_ids)
エンコード結果の確認
まず、input_idsの配列の長さを確認します。
# input_idsの長さを計算
input_len = len(input_ids)
print(f'入力文字列の長さ: {input_len}')
入力文字列の長さ: 294
次に先頭の20要素をinput_ids, tokensと対応づけて表示してみます。
# input_idsの先頭20要素
print(input_ids[:20])
# tokensの先頭20要素
print(tokens[:20])
# 先頭20要素をinput_ids, tokensと対応付けて表示
for token, id in zip(tokens[:20], input_ids[:20]):
print('{:8}{:8,}'.format(token,id))
[101, 2043, 2020, 1996, 3595, 8264, 2333, 2013, 1996, 2717, 1997, 1996, 3075, 1029, 102, 1996, 12111, 11815, 3075, 1006]
['[CLS]', 'when', 'were', 'the', 'secret', 'archives', 'moved', 'from', 'the', 'rest', 'of', 'the', 'library', '?', '[SEP]', 'the', 'vatican', 'apostolic', 'library', '(']
[CLS] 101
when 2,043
were 2,020
the 1,996
secret 3,595
archives 8,264
moved 2,333
from 2,013
the 1,996
rest 2,717
of 1,997
the 1,996
library 3,075
? 1,029
[SEP] 102
the 1,996
vatican 12,111
apostolic 11,815
library 3,075
( 1,006
segment_idsの計算
次のステップがQuestion-Answering予測で最も重要なsegment_idsの計算ステップです。
Question-Answering予測では、「質問」「ヒントテキスト」を一つにつないで入力とします。つながったテキストで、どこまでが「質問」でどこからが「ヒントテキスト」なのかを示す情報がsegment_idsになります。
最初の[SEP]トークンの位置を調べる
# [SEP] tokenの最初の位置
sep_idx = input_ids.index(tokenizer.sep_token_id)
print("SEP token index: ", sep_idx)
SEP token index: 14
質問にあたる部分をセグメントAと呼びますが、そのセグメントが何トーク分なのかを調べます。
# セグメントAのトークン数
# (pythonのindexはゼロから始まるので、sep token indexより1大きい)
num_seg_a = sep_idx+1
print("Number of tokens in segment A: ", num_seg_a)
Number of tokens in segment A: 15
次に、ヒント部分を示すセグメントBが何トークン分かを調べます。
# セグメントBのトークン数
num_seg_b = len(input_ids) - num_seg_a
print("Number of tokens in segment B: ", num_seg_b)
Number of tokens in segment B: 279
これで準備ができたので、segment_idsを生成します。
# segment_idsの計算
segment_ids = [0]*num_seg_a + [1]*num_seg_b
print(segment_ids)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
最後に念のため、segmeind_idsの長さとinput_idsの長さが一致していることを確認します。
# segmeind_idsの長さとinput_idsの長さが一致していることの確認
assert len(segment_ids) == len(input_ids)
予測の実施
これで、予測用の引数の準備が完了しました。次の実装で、予測を行います。
# inpit_idsとsegment_idsを用いて予測の実施
output = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([segment_ids]))
かえってきたoutputがどんなデータなのか、print関数で確認してみます。
# 結果の確認
print(output)
QuestionAnsweringModelOutput(loss=None, start_logits=tensor([[-4.7418, -6.1644, -8.3419, -8.5675, -9.0231, -9.4152, -7.4713, -7.6652,
-7.9159, -8.4479, -8.3411, -8.4345, -8.8540, -9.9689, -4.7418, -7.0036,
-6.0015, -7.4322, -7.4095, -9.0583, -8.3897, -8.6382, -7.5039, -8.0999,
-8.1766, -7.6513, -6.2807, -8.0295, -8.8092, -8.1086, -8.0572, -6.1988,
-8.8412, -8.8514, -7.6907, -7.9228, -7.0875, -8.6589, -8.3033, -6.9598,
-8.2578, -8.9226, -7.2532, -8.2714, -5.2682, -7.7425, -8.1994, -5.3182,
-6.1210, -6.2023, -2.2322, -5.5933, -8.2697, -7.2247, -7.7075, -8.3552,
-7.7833, -7.7108, -8.7252, -6.9845, -8.4068, -7.4159, -8.3782, -5.1614,
-7.2312, -7.7564, -8.5597, -8.5845, -7.6947, -9.1013, -7.5146, -7.6808,
-8.6196, -7.1953, -8.3952, -8.1451, -7.1554, -8.8171, -7.5913, -7.3029,
-8.5125, -7.4493, -8.1198, -6.9437, -8.6964, -8.6875, -7.1083, -8.3913,
-8.6075, -8.1642, -7.9004, -8.9003, -8.6015, -8.8966, -8.9606, -7.6191,
-8.8036, -8.4198, -8.8676, -7.8983, -8.1657, -9.0918, -8.7518, -8.5899,
-8.0777, -8.0645, -9.0120, -8.8259, -8.3497, -8.7531, -8.8923, -8.8465,
-7.2317, -6.1980, -8.1970, -8.5332, -8.0729, -6.9399, -7.8804, -8.5537,
-7.1325, -8.8340, -7.7071, -8.8981, -7.5359, -8.9375, -7.9260, -8.8311,
-6.8203, -8.6488, -7.2210, -6.8640, -8.3571, -8.6815, -7.0948, -8.7018,
-7.4361, -8.7493, -7.9940, -8.0281, -8.6575, -8.0252, -8.8798, -6.9775,
-7.9322, -8.0122, -7.0131, -8.5635, -7.8537, -8.6333, -7.7716, -8.3960,
-8.7485, -7.7210, -8.7467, -7.0034, -7.7953, -5.6417, -3.7515, -8.1642,
-4.5962, -8.4503, -8.6702, -8.1332, -8.5802, -8.4932, -8.8125, -8.0429,
-6.9637, -8.1593, -4.2520, -2.0703, -3.4607, -8.6067, -7.0282, -6.5533,
-8.1341, -7.5357, -7.7707, -7.5046, -6.6466, -5.0226, -7.6785, -6.8381,
-8.1684, -4.8936, -8.2662, -8.2519, -7.0892, -8.4670, -6.2041, -8.6657,
-7.5337, -8.2068, -7.5135, -7.4809, -6.7174, -4.7945, 3.5390, -0.1848,
0.6949, -1.9770, -0.1891, -0.1048, -4.0666, -4.7466, -3.6945, 4.7432,
5.3793, 7.1059, 0.8319, 4.8230, 5.5736, -1.0074, -4.8124, -5.7086,
-7.0135, -7.1159, -6.0316, -8.9009, -8.4165, -6.2579, -4.8445, -5.9570,
-8.4702, -6.9200, -7.4842, -7.4794, -6.4609, -8.4860, -6.8386, -7.0600,
-8.2010, -5.9352, -6.0013, -8.5247, -4.6454, -8.5037, -3.5180, -8.5468,
-8.6831, -5.0669, -8.9462, -9.0313, -6.8320, -8.7469, -9.1596, -6.3443,
-9.0991, -8.0343, -8.9318, -5.7116, -7.6503, -4.9813, -4.4821, -8.0262,
-5.0348, -7.7431, -6.7612, -8.4227, -6.1787, -6.7213, -5.9317, -6.9859,
-8.6391, -8.1868, -7.2844, -8.5143, -6.1592, -7.8558, -6.9636, -6.6165,
-7.7874, -8.9031, -8.7943, -7.8186, -7.9975, -7.5534, -8.6002, -8.3273,
-9.2958, -8.6070, -8.5543, -8.8651, -8.5713, -8.0735, -9.5498, -8.9248,
-8.3831, -9.2262, -9.0032, -8.6724, -9.4533, -4.7418]],
grad_fn=<CloneBackward0>), end_logits=tensor([[-2.1372e+00, -6.5415e+00, -6.7468e+00, -7.9211e+00, -7.8441e+00,
-7.1790e+00, -7.1689e+00, -6.4368e+00, -7.7441e+00, -7.1999e+00,
-7.4744e+00, -7.4297e+00, -6.4998e+00, -6.1132e+00, -2.1372e+00,
-7.5009e+00, -6.2783e+00, -5.5826e+00, -4.8740e+00, -7.1607e+00,
-6.1996e+00, -5.8151e+00, -7.8119e+00, -7.0992e+00, -7.3571e+00,
-7.6680e+00, -6.9385e+00, -5.5880e+00, -7.2571e+00, -7.6545e+00,
-7.7010e+00, -7.8240e+00, -5.5563e+00, -5.6317e+00, -7.4430e+00,
-7.5937e+00, -6.1830e+00, -7.5696e+00, -7.5348e+00, -7.0701e+00,
-5.2469e+00, -6.1202e+00, -7.7271e+00, -7.7996e+00, -6.9589e+00,
-4.5506e+00, -6.3651e+00, -7.5416e+00, -6.9027e+00, -7.3149e+00,
-4.9812e+00, -1.7695e+00, -4.7008e+00, -7.5232e+00, -7.7918e+00,
-7.9757e+00, -8.0492e+00, -6.1145e+00, -6.0938e+00, -7.6299e+00,
-7.6350e+00, -7.7147e+00, -7.7171e+00, -6.8392e+00, -6.1643e+00,
-6.2463e+00, -7.8295e+00, -7.9287e+00, -5.1669e+00, -7.3589e+00,
-8.2504e+00, -7.9091e+00, -7.8652e+00, -7.1057e+00, -7.7895e+00,
-7.5423e+00, -6.9189e+00, -7.9706e+00, -7.5654e+00, -5.3419e+00,
-6.1967e+00, -7.8334e+00, -7.9617e+00, -8.0025e+00, -7.6196e+00,
-7.1113e+00, -8.0107e+00, -5.7024e+00, -7.8620e+00, -7.8535e+00,
-5.6095e+00, -5.8091e+00, -7.9331e+00, -7.4261e+00, -7.5933e+00,
-8.0506e+00, -7.9977e+00, -7.8895e+00, -7.2513e+00, -7.0572e+00,
-6.0523e+00, -6.2280e+00, -7.7601e+00, -7.8574e+00, -8.1535e+00,
-7.8973e+00, -7.6145e+00, -7.1768e+00, -7.9886e+00, -7.6459e+00,
-6.3258e+00, -6.0516e+00, -8.0911e+00, -7.5696e+00, -6.5981e+00,
-7.7956e+00, -7.9252e+00, -7.0181e+00, -6.3919e+00, -7.7094e+00,
-6.6789e+00, -7.4055e+00, -7.0587e+00, -7.2958e+00, -6.7702e+00,
-7.1722e+00, -6.8433e+00, -7.8329e+00, -5.0585e+00, -6.2364e+00,
-8.3002e+00, -8.0029e+00, -6.7717e+00, -7.9869e+00, -7.6427e+00,
-7.8885e+00, -6.5878e+00, -7.4872e+00, -7.6413e+00, -7.3514e+00,
-7.3651e+00, -6.3849e+00, -8.2234e+00, -7.3007e+00, -5.6396e+00,
-5.1305e+00, -8.0719e+00, -8.1981e+00, -6.8160e+00, -8.1865e+00,
-7.6563e+00, -6.8941e+00, -8.2184e+00, -7.1222e+00, -8.3379e+00,
-6.9368e+00, -7.5765e+00, -7.8309e+00, -4.1628e+00, -8.1085e+00,
-2.8785e+00, -7.6785e+00, -7.7084e+00, -6.9307e+00, -7.9776e+00,
-6.9193e+00, -7.9039e+00, -8.3454e+00, -4.8037e+00, -5.2443e+00,
-6.9808e+00, -4.8193e+00, -1.3384e+00, -5.2235e+00, -7.9479e+00,
-7.6351e+00, -6.5409e+00, -7.1695e+00, -7.3235e+00, -7.2122e+00,
-6.9379e+00, -6.6906e+00, -6.1345e+00, -5.9673e+00, -7.7745e+00,
-6.5966e+00, -5.6210e+00, -7.4548e+00, -6.5048e+00, -7.6919e+00,
-4.3539e+00, -5.3377e+00, -7.5013e+00, -7.5261e+00, -7.6604e+00,
-6.8932e+00, -4.2771e+00, -4.0790e+00, -4.8065e+00, -5.0912e+00,
-4.7686e+00, -3.5779e+00, -4.9283e+00, -3.0455e+00, -4.6396e+00,
-5.4179e+00, -1.8160e+00, -1.7983e+00, -2.2632e+00, -7.5898e-03,
-8.2884e-01, -2.0297e+00, 1.1604e+00, 8.1595e+00, 4.4418e+00,
-3.9454e+00, -5.5629e+00, -6.0199e+00, -6.2408e+00, -6.5517e+00,
-4.7782e+00, -1.3143e+00, 9.5203e-01, -6.8245e+00, -7.3238e+00,
-6.6793e+00, -7.3783e+00, -7.9138e+00, -5.9885e+00, -7.8447e+00,
-7.7673e+00, -5.9804e+00, -7.8019e+00, -5.9000e+00, -4.2028e+00,
-6.9388e+00, -6.4715e+00, -7.8296e+00, -6.7817e+00, -5.1416e+00,
-6.5337e+00, -7.7222e+00, -5.6049e+00, -6.4977e+00, -8.0866e+00,
-5.4420e+00, -6.8776e+00, -7.3002e+00, -7.8166e+00, -5.5962e+00,
-8.0624e+00, -4.2998e+00, -4.2429e+00, -7.6452e+00, -6.7363e+00,
-7.6442e+00, -7.1858e+00, -4.1160e+00, -4.0065e+00, -6.3501e+00,
-7.5430e+00, -8.0762e+00, -6.4182e+00, -5.5783e+00, -8.1366e+00,
-7.9731e+00, -5.2589e+00, -6.2660e+00, -7.2256e+00, -8.0899e+00,
-8.2653e+00, -6.9285e+00, -6.6403e+00, -8.2373e+00, -8.1622e+00,
-5.2054e+00, -5.9793e+00, -8.2591e+00, -8.4825e+00, -7.5800e+00,
-8.0940e+00, -7.6288e+00, -7.5035e+00, -8.3565e+00, -8.1402e+00,
-6.5691e+00, -6.8255e+00, -8.4641e+00, -8.0810e+00, -8.2080e+00,
-8.5770e+00, -6.9444e+00, -7.6794e+00, -2.1372e+00]],
grad_fn=<CloneBackward0>), hidden_states=None, attentions=None)
start_logitsとend_logitsの2つのベクトル値がかえってきていることがわかります。
この2つの変数は、それぞれ「答えの可能性の高い」部分のインデックス開始、終了地点を示しています。以下の実装で、このベクトルから整数のインデックスを計算し、更に、解答と予測されるフレーズも求めてみます。
# answer_start と answer_endの計算
answer_start = torch.argmax(output.start_logits)
answer_end = torch.argmax(output.end_logits)
if answer_end >= answer_start:
answer = " ".join(tokens[answer_start:answer_end+1])
else:
answer = ("I am unable to find the answer to this question. Can you please ask another question?")
# 結果の確認
print(answer_start, answer_end, answer)
tensor(209) tensor(213) beginning of the 17th century
先頭の単語の第1文字を大文字にしてもう少し本当の文章っぽくしてみましょう。実装と結果は下記になります。
question_cap = question.capitalize()
answer_cap = answer.capitalize()
print(f"\nQuestion:\n{question_cap}")
print(f"\nAnswer:\n{answer_cap}")
Question:
When were the secret archives moved from the rest of the library?
Answer:
Beginning of the 17th century
モデルによる予測結果は「Beginning of the 17th century」でした。
元々のデータセット上の正解データは「at the beginning of the 17th century」だったので、ほぼ正解が得られていることがわかります。
ファインチューニングなどのカスタム学習は一切なしで、この結果が得られているので、確かにBERTは凄いということが実感できます。