はじめに
Watson Studioをお使いの皆様、「プロジェクトに追加」で出てくる下記のメニューで「Streamsフロー」とは何だろうと思ったことはないでしょうか?
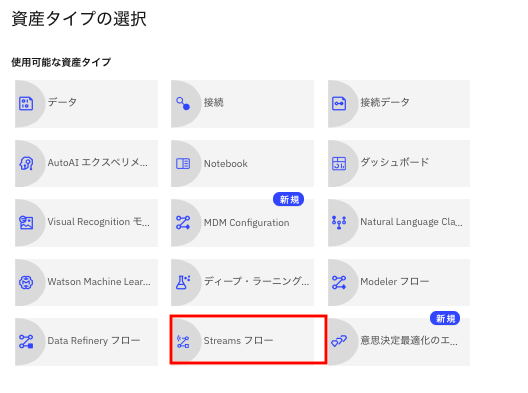
これは、Watson Studioの1機能である、Streams Flowのメニューです。
IoT系のリアルタイムデータ処理をUIの画面から作るサービスになっています。実は、利用形態によっては有名なNode-REDより便利な点もある、かなりすごいサービスなのですが(※)、今までドキュメントが少なかったこともありあまり知られていない存在でした。
かくいう私もその一人で、この機能、どうやって使うのだろうと思っていたのですが、最近チュートリアルが日本語化されました。
このチュートリアルを参考に簡単なガイドを作ってみましたので、皆さんも是非お試し下さい。
Streams Analyticsというサービスが追加で必要ですが、例によってライトプランがあるので、クレジットカードなしのライトアカウントでもお試し可能です。
また、これも例によって、この機能もOpenShiftベースの製品であるCloud Pak for Dataでも利用可能です。
下記は、本記事の最後にできる、Streams Flowの画面です。この実習を動かしてみたい方は、ちょっと長いのですが、是非この記事に最後までお付き合いいただければと思います。

ちなみに、このStreams Flowも他のWatson Studioの機能と同様に、OpenShift上で稼働する製品CP4Dでも提供されています。
(※) 細かいところまで機能比較したわけでなく、あくまで第一印象です。
Node-REDは多目的に利用可能な汎用的RADツールです。
これに対してStreams Flowはリアルタイムデータ処理に特化したサービスです。構造化データのリアルタイム処理を目的としているので、例えば、SPSS Modeler Flowで作った予測モデルと連携したアプリを作りたい場合、専用のノードが利用可能という点がメリットです。また、リアルタイムで流れているデータのトランザクション量の確認やデータブラウズまでできてしまうのも便利な点です。
逆に、実際に実習をやっていただくとわかりますが、お手軽にフローを作れるという点ではNode-REDの方がかなり先を行っている認識です(Streams Flowでは、現段階ではフロー作成後ビルド・実行まで5分以上かかります)。
環境準備
前提 (Watson Studioのプロジェクト作成まで)
前提として、Watson Studioのプロジェクトまでは作成済みであることとします。
この前提を満たしていない方は、次の記事を参照して下さい。
無料でなんでも試せる! Watson Studioセットアップガイド
Streaming Analytics インスタンス作成
前提を満たしている場合の、最初のステップは、Streaming Analyticsのインスタンス作成です。
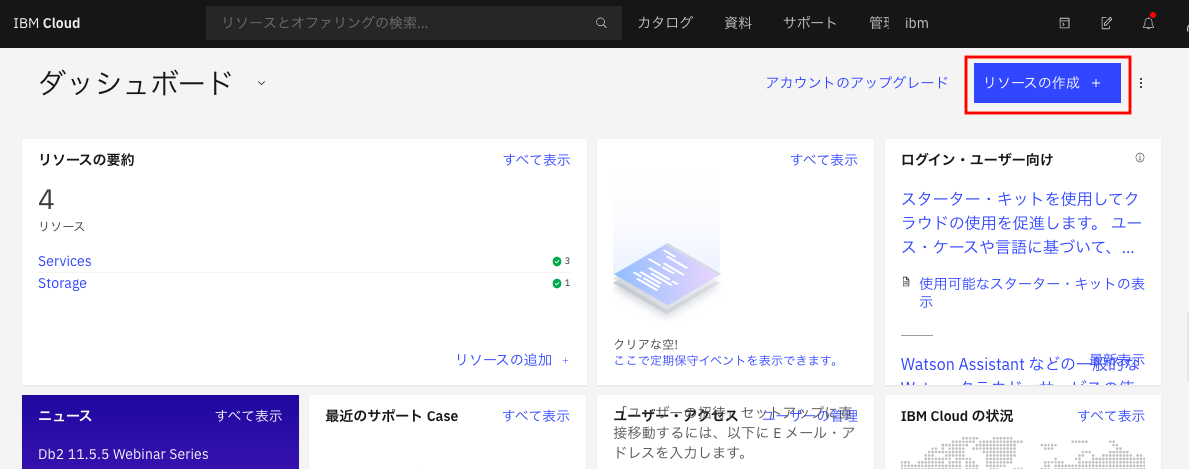
まず、
のリンクからログインして、下記のIBM Cloud ダッシュボードの画面を表示させます。そして、画面右上の「リソースの作成」ボタンをクリックします。
下の検索画面にStreamingと入力し、Enterを押して下さい。

下のように、Streaming Analyticsのタイルが表示されるので、そこをクリックします。

下の画面になります。すべてデフォルトのままで、画面右下の「作成」ボタンをクリックします。
すると、下のようにリソース・リストにStreaming Analyticsの行が増えているはずです。

しばらく待って、下のようにActiveになれば、準備完了なので、次のステップに移ります。

Cloud Object Storageのバケット作成
次にCloud Object Storageに新しいバケットを作成します。
これから作るストリームは、データをCloud Object Storage上に保存します。そのための保存場所をこれから作ることになります。
(備考 以下の手順はチュートリアルに抜けている箇所です。このチュートリアル、それ以外にも何カ所かトラップがあり、改善の余地ありという感じです。)
まず、下のようなIBM Cloudのリソース・リストの画面から、「Storage」の欄をクリックして、その内容を表示させます。cloud-object-storage-xxという項目があるはずなので、そのリンクをクリックして下さい。これでCloud Object Storageの管理画面に遷移します。

下の画面になったら、画面右上の「バケットの作成」をクリックします。
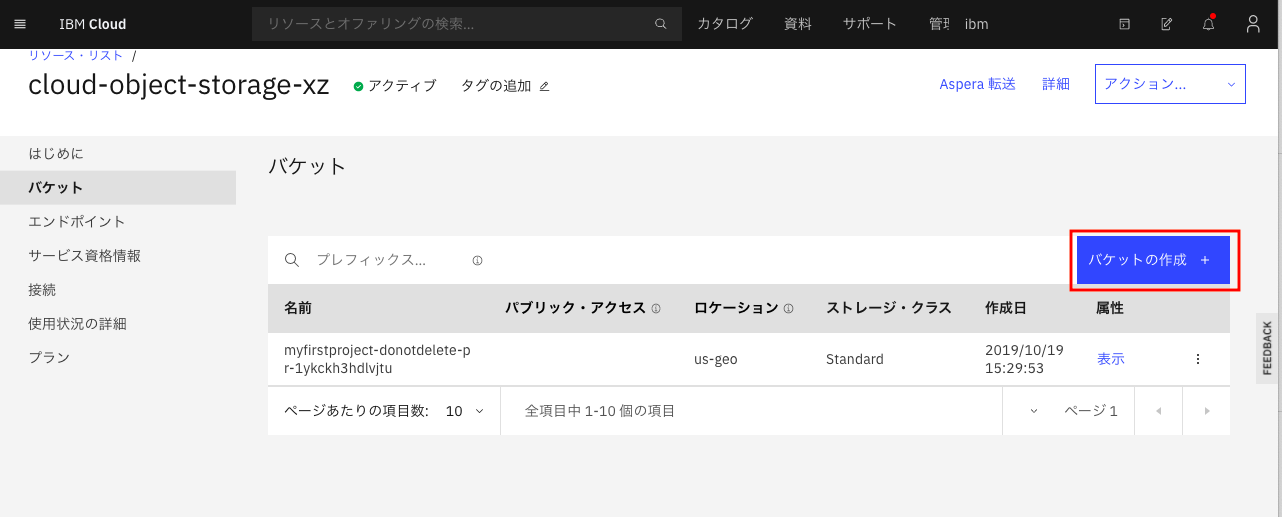
下の画面になったら、カスタム・バケットのタイルの矢印の部分をクリックします。
(タイル全体でなく、矢印の領域しか反応しないので要注意です)

下記の画面になるので、下の3つの項目を入力、設定します。、
①バケット名 クラウド全体でユニークな名称にする必要があるので注意して下さい。例ではiot-makaishi2-data-01としています。
②回復力 デフォルトではRegionalになっているはずですが、左のCorss Regionに変更します。
③ロケーション us-geoに変更します。

三つの入力が終わったら、画面を一番下までスクロールして下さい。「バケットの作成」というボタンがあるので、ここをクリックします。

下のような画面になれば、バケット作成に成功しています。

Watson StudioのプロジェクトとStreaming Analyticsサービスの関連付け
次に、先ほど作ったサービスと、Watson Studioのプロジェクトの関連付けをします。
次のリンクからWatson Studioの初期画面を表示させます。
下の画面になったら、自分のプロジェクトを選択し、プロジェクト管理画面を表示させます。
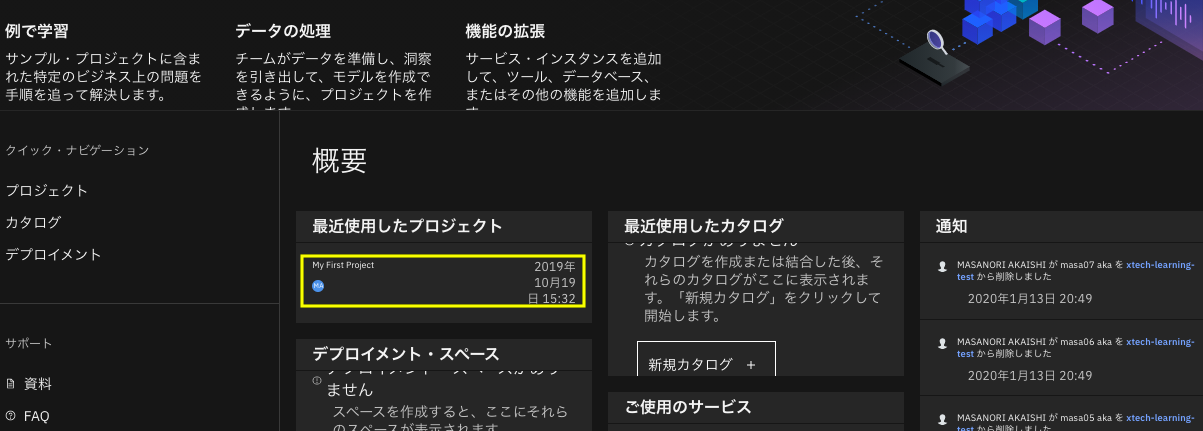
下のプロジェクト管理の画面になったら、画面上部一番左の「設定」タブをクリックします。
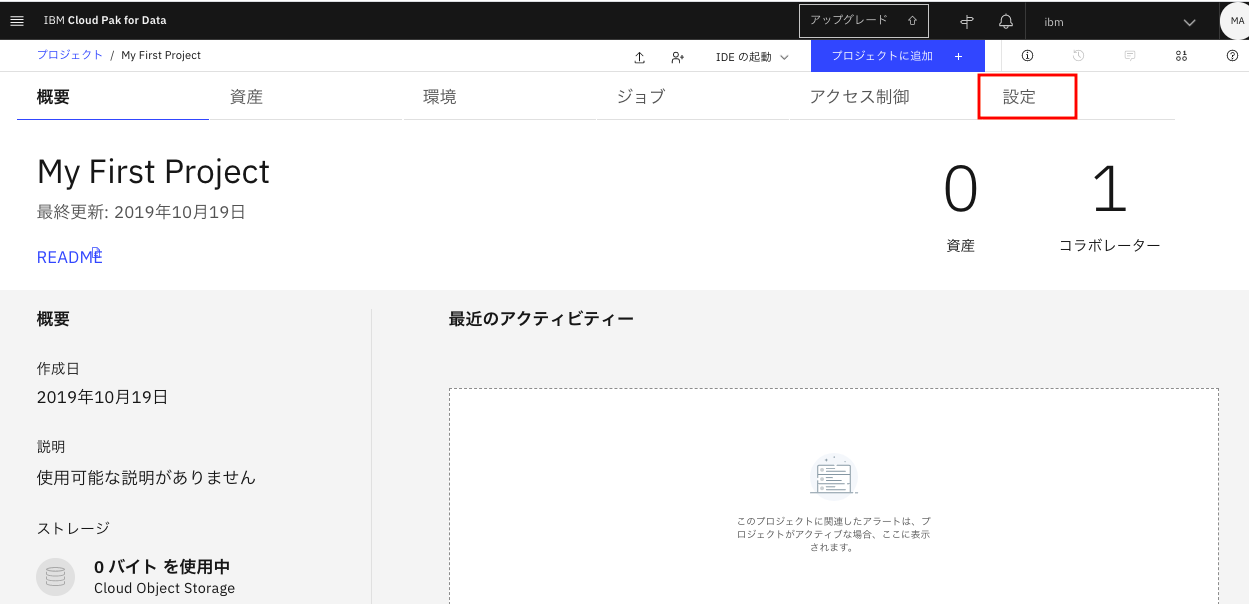
設定タブで画面を下にスクロールさせて、下の画面の「サービスの追加」をクリックします。
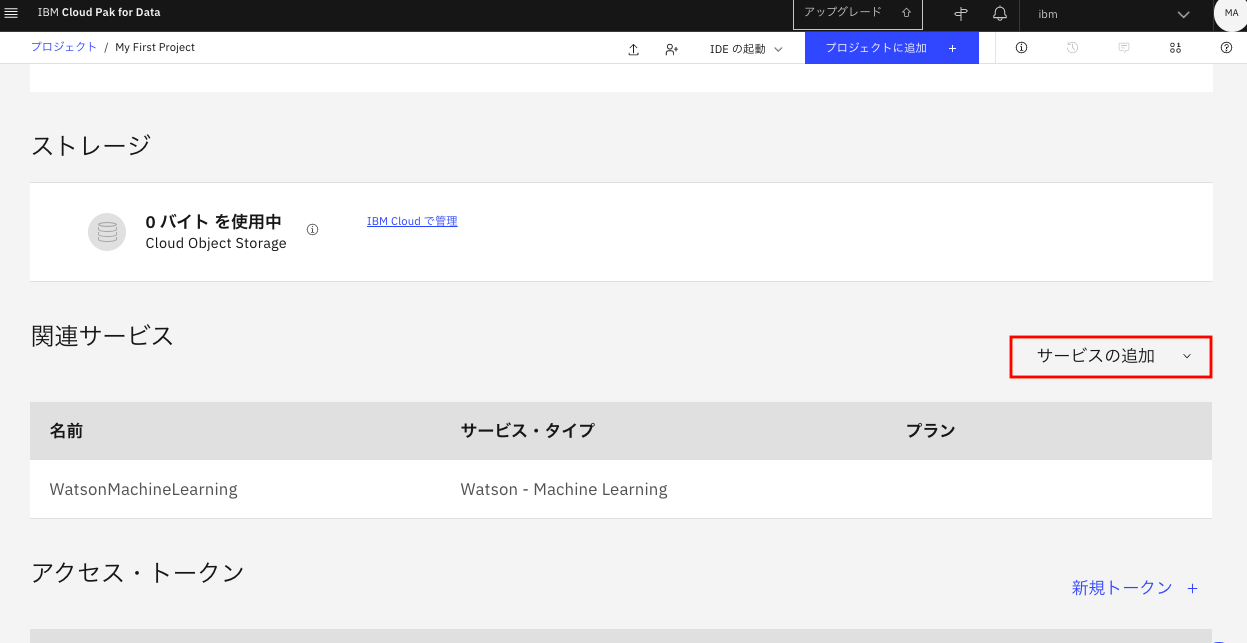
ドロップダウンメニューから「Streaming Analytics」を選択します。
「Associate service」の画面になったら、チェックボックスにチェックを入れ、画面右の「Associate service」のリンクをクリックします。

下のようにStatusがAssociatedになっていれば関連付けに成功しています。画面右上の閉じるアイコンで設定画面を閉じます。

元の画面に戻りますが、Steaming Analyticsがサービスとして増えているはずです。
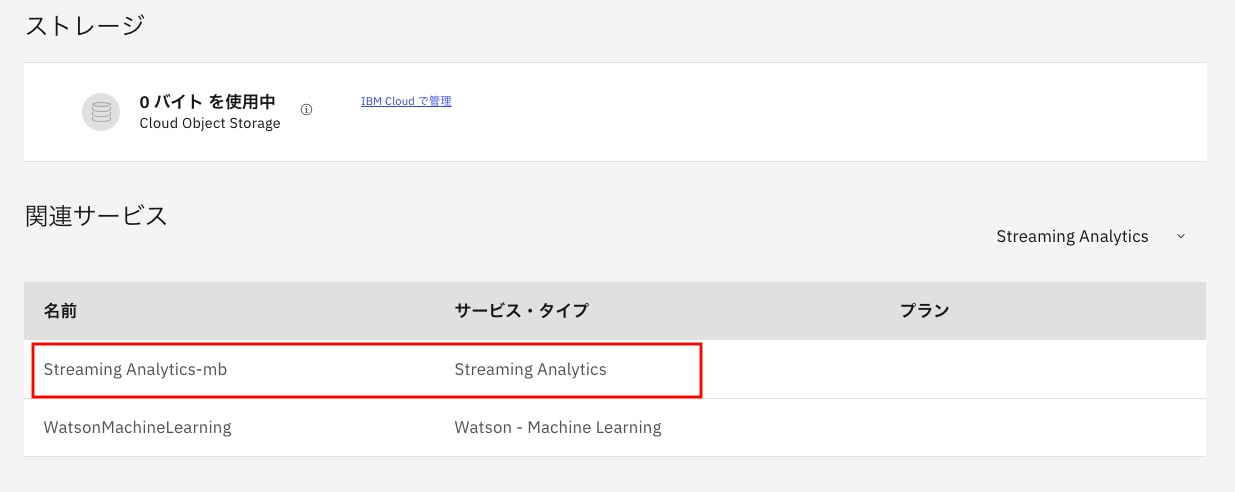
お疲れ様でした。これで、実習に必要な環境の準備はすべて終わりました。
いよいよ、当初の目的であるStreaming Flowの作成に入ります。
Streaming Flowの作成
初期画面の表示まで
プロジェクト管理画面で「資産」タブを表示した状態で、画面上部の「プロジェクトに追加」をクリックします。
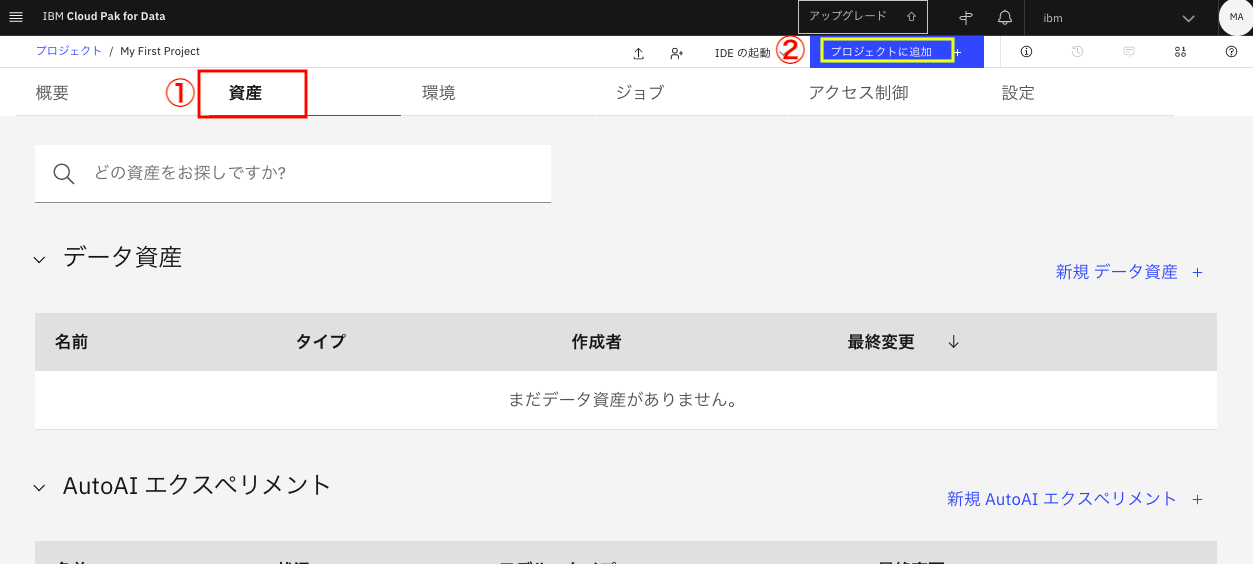
下のメニューで「Streams フロー」を選択します。
下のような「新規Streams フロー」の画面になります。ここで
①「My First Stream」など適当な名前を入力します。
②その下のStreaming サービスには、先ほど新規作成・プロジェクトとの関連付けをしたStremingサービスが設定されていることを確認します。
③フロー作成方法を「手動」に変えます
④画面右下の「作成」ボタンをクリックします。

これで、下のようなStreams Flow編集画面が表示されるはずです。
ノードの生成と接続
この画面の使い方は、基本的にSPSS Modeler Flowと同じです。画面左のパレットから必要な部品をDrag and Dropして、部品間を結線し、必要に応じて部品のプロパティを設定します。
今回は、最初のフローなので、ソース一つ、ターゲット一つという最も簡単なフローを作成します。
ソースノードの生成
画面左のパレットから一番上の「ソース」をクリックします。すると、下のようにソースデータのアイコン一覧が表示されます。この中で「サンプル・データ」を編集画面にドラックアンドドロップします。
このメニューはIoT処理する対象の入力データソースを表しています。
普通は、基盤側の準備が必要なのですが、開発テスト用に、準備なしで利用できるダミーデータソースが、今選んだ「サンプル・データ」になります。

ターゲットノードの生成
今度は、パレット上上から2番目の「ターゲット」をクリックします。
中のメニューから「Cloud Object Storage」のアイコンをdrag and dropします。

ノード間の結線
次に2つのノード間を下の図のように結線します。ここが妙にやりにくくて要注意です。コツとしてノード内の小さな円の領域ぴったりにマウスポインタを合わせた上で、drag and dropするのがいいみたいです。

結線が終わった段階では、両方のノードに赤い点が表示されていて、これはプロパティが未設定でこのままでは実行できないことを意味しています。これから、両ノードのプロパティ設定を行っていきます。
ソースノードのプロパティ設定
まず、サンプル・データノードをクリックします。下のように、右側にノードの設定情報が表示されます。
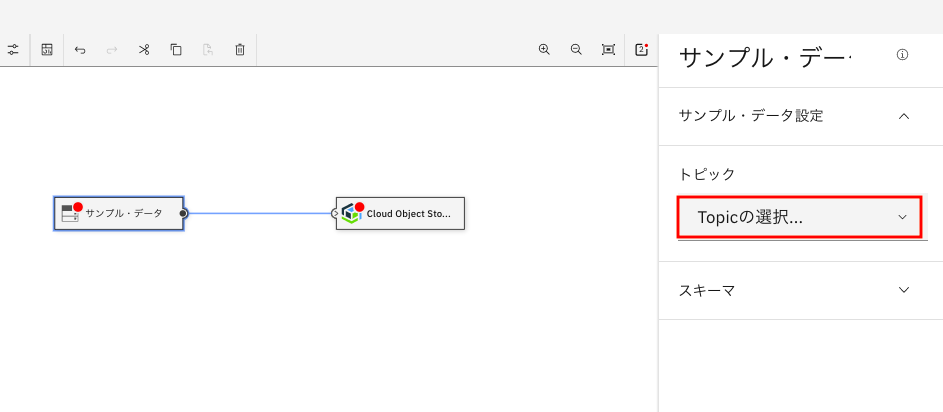
ここで、トピックのドロップダウンをクリックし、「データ・ヒストリアン」を選択します。選択が終わったら、編集領域の空白の箇所をクリックし、画面を元の状態に戻します。
下の図のようになるはずです。

この段階で、ソースノード側は赤い点が消えたのがわかります。これは設定が正常にできたことを意味しています。
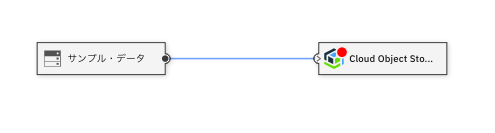
次に、ターゲットノードの設定を行います。
ターゲットノードのプロパティ設定
次に同様にCloud Object Storeのノードをクリックします。下の画面になるので、「接続の追加」を選択します。
(備考 以下の操作は最初の一回のみです。1度接続の登録ができると、2度目以降はメニューから選択するだけでOKです。)

下の画面になるので、一番上部の「Your service instances in IBM Cloud」の直下のアイコンを選択して下さい。
(備考 一般的なCloud Object Storageに接続する場合は、認証情報をすべてセットする必要がありますが、同一イアカウント内であれば、簡単に接続できます。以下の手順はこのことを利用します)

次に画面を一番下までスクロールします。下のような画面になるので、
① Discover data assets のチェックを付ける
② Createボタンをクリック
します。これで、Object Storageとの接続情報が設定されたはずです。

設定がうまくいくと、下のように、「接続」の欄が cloud-object-storage-xxに設定されています。
次にその直下の「ファイルパス」右下の枠で囲んだアイコンをクリックします。

下の画面になるので、先ほど事前準備で用意したバケットを選択します。
(参考までにもう一つのバケットはStudioのプロジェクトデータ保存用に自動的に作られたものです)
画面が切れてしまっていますが、その後で右下の「選択」ボタンをクリックします。

下のように、ファイルパスに/<バケット名>が入っているのがわかると思います。
(ここは、タイプミスしないのであれば手で入れてもOKです)
次に、このバケット名の直後に次の文字列を入力して下さい。
/DH_%TIME.csv

最終的に、次のような形になります。
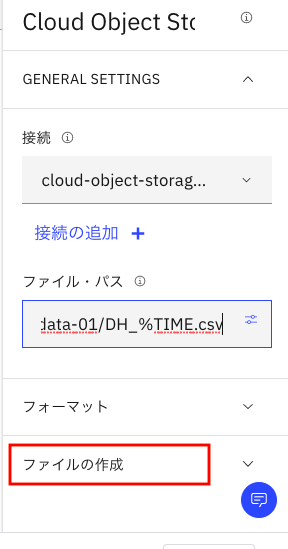
ちなみに、以上の設定は、Object Storage上にIOTデータをどういうファイル名で保存するかを指定するためのものです。%TIMEというキーワードを含めることで、タイムスタンプをファイル名に追加して、2度目以降も上書きされないようになります。
ここまでできたら、あと一歩です。その下の「ファイルの作成」をクリックします。
下の画面になったら、
wrirePolicy; 「イベント数」
イベント数: 100
を入力して下さい。入力が終わったら、ファイルの作成の欄を非表示にして、元の画面に戻します。
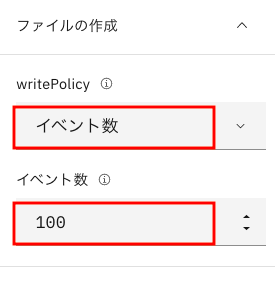
さらに、編集エリアを再度クリックして、設定画面も非表示にして下さい。
すべての設定がうまくいくと、下の図のように、2つのノードの赤い点が両方消えているはずです。
念のため、画面右上のアラートアイコンをクリックして、アラートの状況を確認します。一番上部に下の図のような緑のアイコンが出ていれば、すべて設定がうまくいったことを意味しています。

確認できたら、アラートアイコンを再度クリックして、非表示に戻します。
お疲れ様でした。これでStreamsの最初のデモを動かすための準備はすべて完了しました。
次の章でいよいよ今作ったStream Flowを実際に動かしてみます。
ストリームの実行
ストリームの保存とメトリックス・ページの表示
まず、今まで作ったストリームを①「保存」アイコンをクリックして保存します。
次に②「メトリックス・ページ」アイコンをクリックして下さい。

ストリームの実行
下のような画面になるかと思います。ここで画面上部のPlayアイコンをクリックすると、ストリームが実行されます。早速このボタンをクリックしてみましょう。
1分ほど待っていると、下の画面が表示されるので、「はい」で答えます。

すると、ストリームのデプロイが始まります。ここはものすごく時間がかかります。
(自分の環境ではかったときは約6分。)
一休みして、辛抱強く待っていて下さい。
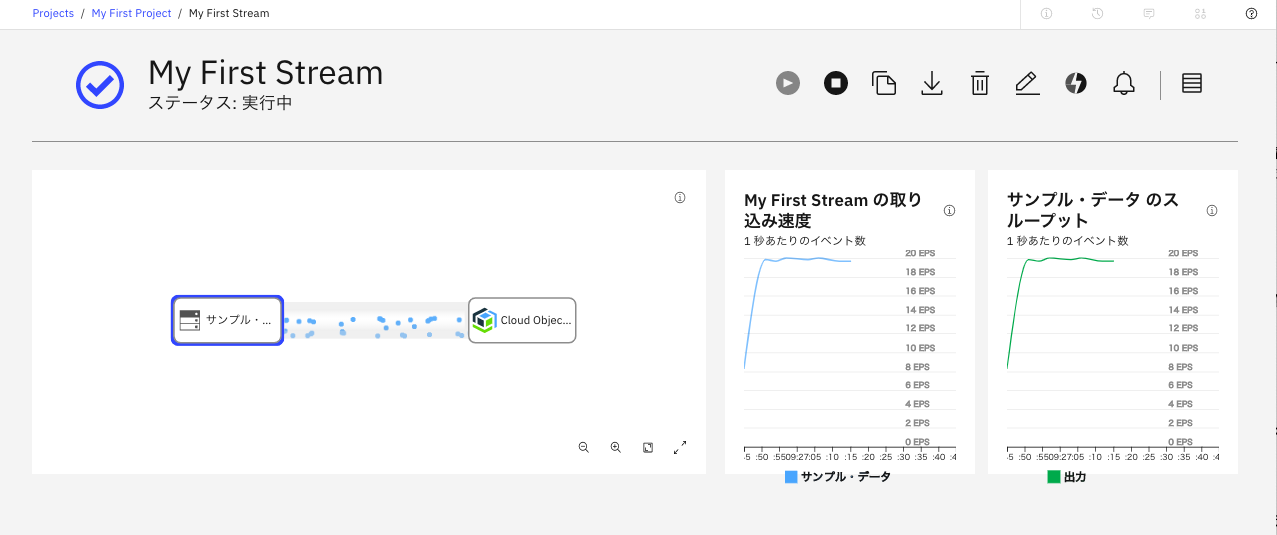
うまくいくと、下のような画面に変わります。
データの流れていく様子がアニメージョン表示されていて、初めてみたときは結構感動しました。
ノード間をクリックすると、下の図のようにデータの詳細情報が表示されます。

もう一回クリックすると、個々のトランザクションデータの詳細まで表示されます。これは結構すごいと思いました。

出力の確認
最後に、このデモで作ったCSVファイルを確認してみましょう。
Cloud Object Storageの管理画面から、該当バケットをクリックすると、その確認ができます。


おわりに
このチュートリアルは、単にStreams Flowエディタの使い方を理解するだけのもので、まだ、本当のIoT処理ができたわけではありません。しかし、ノードの一覧をみればどんなことができそうか想像が付くので、最後にノード一覧を紹介します。
ソースノード一覧
IoTデータでデファクトのKaftaとMQTTはもちろんサポートされています。WatsonIoTというIBMのクラウド用サービスのアイコンもあるので、このサービスを使っている場合は、簡単にそこからデータを取ってこれそうです。

ターゲットノード一覧
今の実習では、Cloud Object Storageに保存しましたが、Db2 / Event Streams / Redis などがあり、普通にIOTの処理結果をデータ保存することもできそうです。

処理及び分析ノード一覧
最後は「処理及び分析」ノードです。
「SPSSモデル」というのは、SPSS Modeler Flowで作った予測モデルをこのストリームに取り込む機能です。これを使ったチュートリアルもあるので、機会があれば別途紹介したいと思います。
また、「Cloud Function」なんてものもあるので、活用すると、外部APIを呼び出す面白いアプリケーションも作れそうです。
