はじめに
AutoAIは、最近(2019年6月)発表されたばかりの、IBM Cloud上で稼働する機械学習モデルの自動生成・最適化を行うツールです。
機械学習モデルのベンチマークとして有名な、Kaggleから提供されているTitanic Data を元ネタにその精度を実際に測ってみました。
[2020-04-25] 初期セットアップ手順修正
問題設定
オリジナルデータは、Kaggleサイトからダウンロードしています。
元の学習用データ train.csvは下のような構造のデータです。

いろいろなKaggleベンチマーク挑戦サイトを見るとName, Ticket, Cabinといった項目からも頑張って情報をとってきているようですが、AutoAIの仕組みを見る限りそこまでのことはできていない模様。
そこで、割り切ってこの3列を落とした形でツールにかける方針としました。
最終的には、次のような問題設定としています。
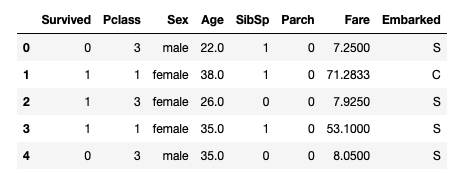
学習用データ train_titanic.csv
元学習データtrain.csvから、PassengerId, Name, Ticket, Cabinを落としたもの。
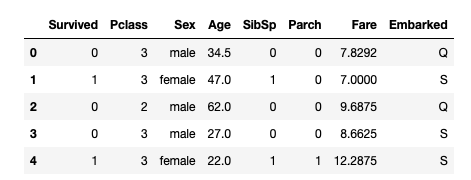
検証用データ test_titanic.csv
元データ test.csvとgender_submission.csvをPassengerIdでJOINした後、PassengerId, Name, Ticket, Cabinを落としたもの。
必要ファイルのダウンロード
以下の実習では、次の3つのファイルを利用します。
どのファイルもgithubにアップしてあってダウンロード可能ですので、事前にダウンロードしておいて下さい。
| ファイル名 | 目的 | URL | 短縮URL |
|---|---|---|---|
| train_titanic.csv | 学習用 | https://raw.githubusercontent.com/makaishi2/sample-data/master/data/titanic_train.csv | http://bit.ly/2MnDW3R |
| autoai-test.ipynb | 精度検証用 | https://raw.githubusercontent.com/makaishi2/sample-data/master/notebooks/autoai-test.ipynb | http://bit.ly/2L9ZZJ5 |
| titanic-autoai.json | Webサービステスト用 | https://raw.githubusercontent.com/makaishi2/sample-data/master/data/titanic-test-web-autoai.json | http://bit.ly/2N3k9XD |
なお、上で紹介した正解データtest_titanic.csvに関してはJupyter Notebookの内部で取得しています。短縮URLは http://bit.ly/2Y6SF4C ですので、こちらから直にダウンロードして確認することも可能です。
また、検証用Jupyter Notebookをきれいな形で見たい場合は Jupyter リンクを参照して下さい。
クラウド環境の準備
これでデータの準備は整いました。いよいよ先ほど説明した学習データを使って、AutoAIによりタイタニックのモデルを作ってみたいと思います。
そのためには、IBM Cloudでアカウントを作って、IBM Studioのプロジェクトを準備する必要があります。
しかし、今回のモデルを作るための準備としてはIBM Cloudの中で一番簡単に作ることのできるLite Acount(クレジットカードなしで登録でき、しかも無期限に利用可能)で対応可能です。
そのための手順については、別記事
無料でなんでも試せる! Watson Studioセットアップガイド
に書いておきましたので、こちらを参照して下さい。
ちなみに、この手順でAutoAIのために必要なのは、「Studioのプロジェクト作成」までと「Watson MLの登録」です。
「Notebookの作成、ファイルの読み込み」は、Jupyter環境を自分のPCに持っていない場合は、後半の検証プログラム実行環境として利用できます。Jupyer環境をすでに自分のPCに持っている場合は使わなくても結構です。
モデル作成
IBM Cloudの準備もできたので、モデルの作成にとりかかります。Watson Studioのプロジェクトの準備までできていたら、モデルを作るのは本当に簡単です。
AutoAIの呼出し
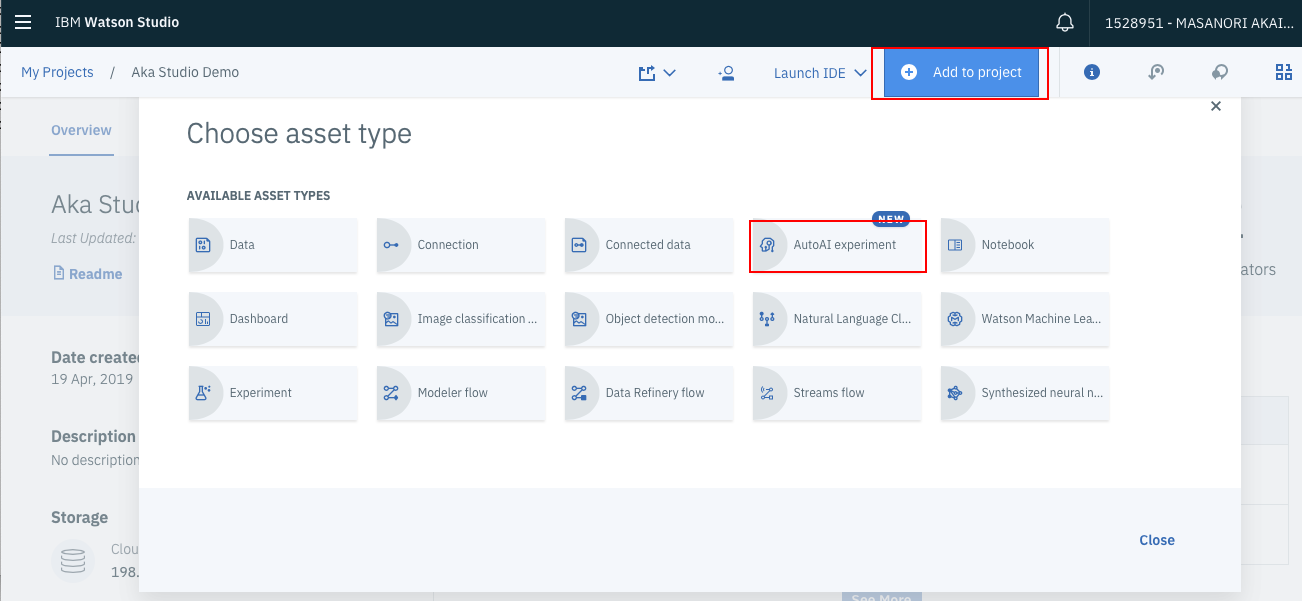
まず、プロジェクト管理画面上部の「Add to project」のリンクをクリックします。下のようなメニューが出てくるので、AutoAI Experimentsを選択します。
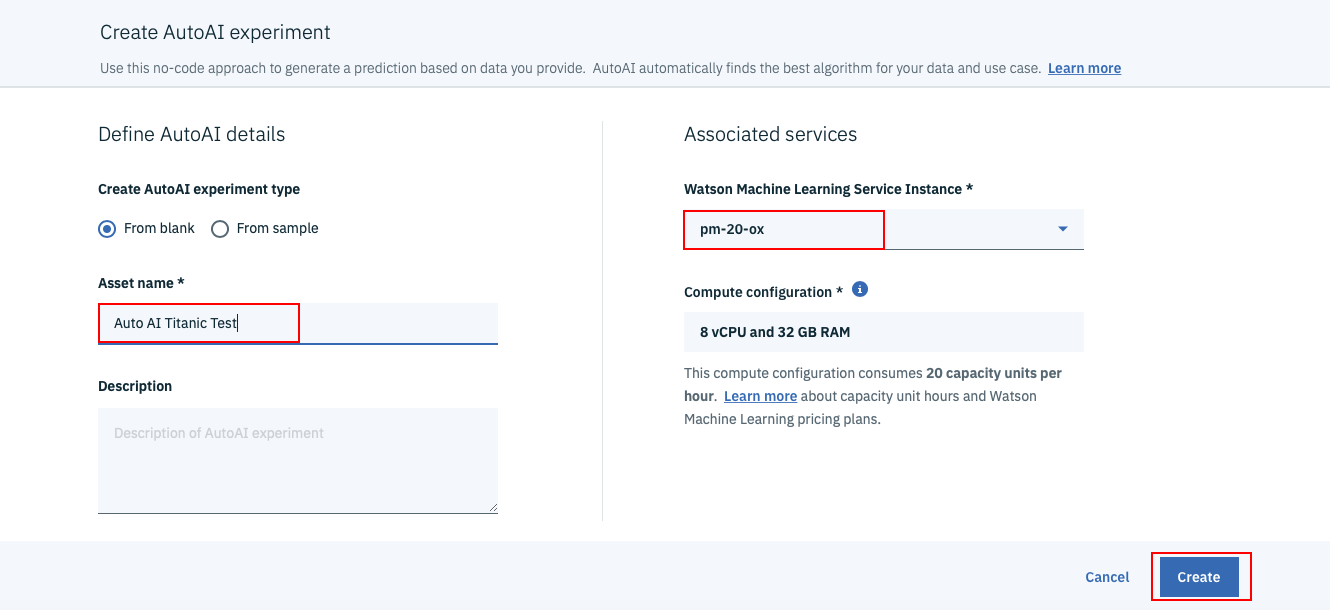
下のような画面が出てくるので、まず画面左中程のAsset Nameの欄に「AutoAI Titanic Test」など適当な名前を入力します。
「Watson Machine learning Service Instance」に先ほど設定したWatson MLの名前が設定されていることを確認した上で、画面右下のCreateボタンをクリックします。
学習用データの指定
すると下のような画面が出てくるので、前のステップで用意したtitanic_train.csvファイルをdrag and dropします。
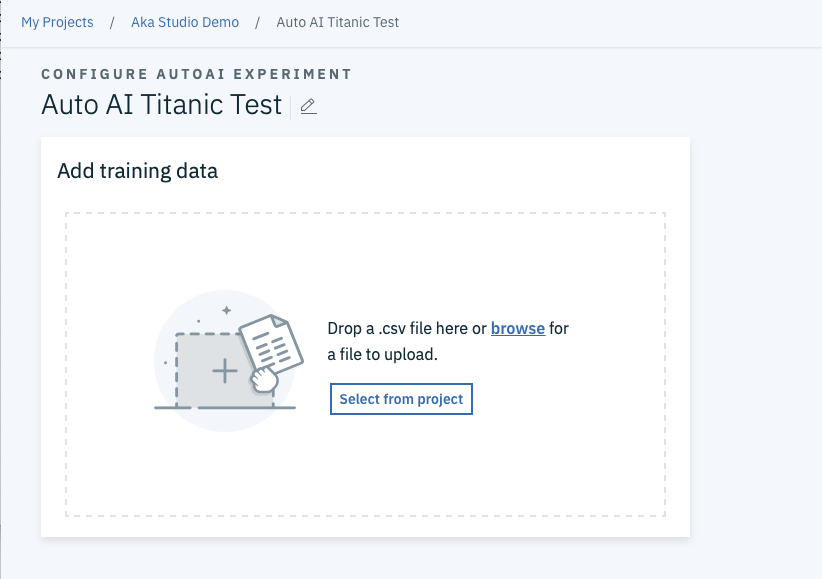
目的変数の指定
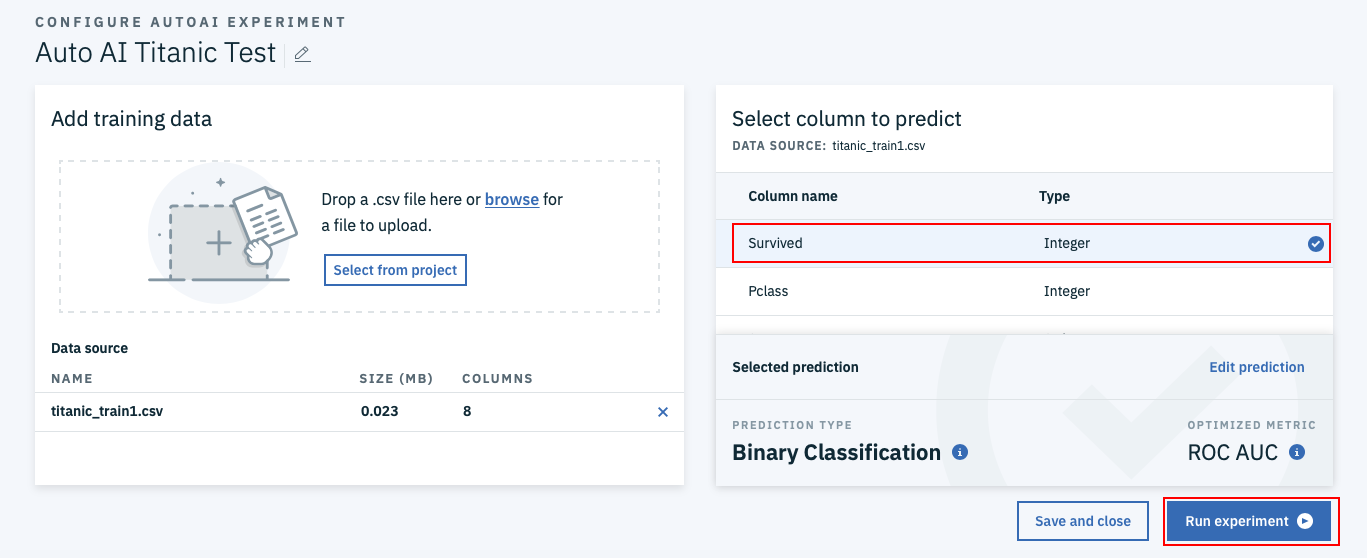
今度は、下のような画面になります。まず、画面右の「Select column to predict」の質問に答えます。目的変数が何かという質問ですので、Survivedをクリックします。
画面下のselected predictionsとOPTIMIZATION METRICはそれぞれ事前に選ばれているBinary ClassificationとROC AUCで構いません。最後に画面右下のRun experimentsのボタンをクリックします。
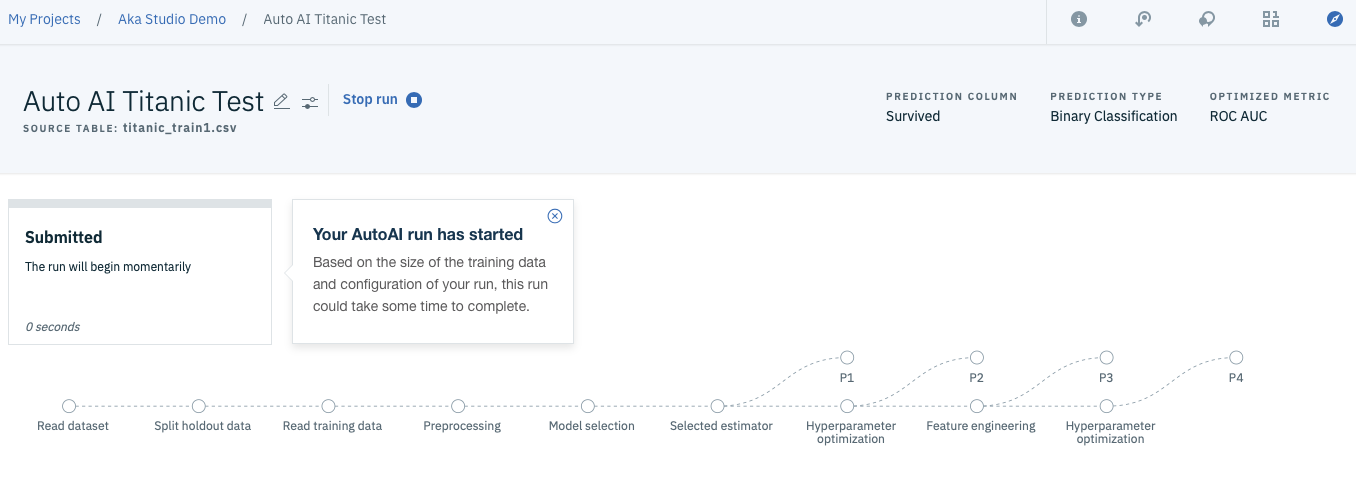
これでモデル作成のための入力はすべて完了です。下のような画面が出てきたら、あとはすべてWatsonに任せて下さい。
最適なモデルの選定と保存
10分程度待っていると、下のような画面になります。これで4つのモデル候補がすべてできあがりました。
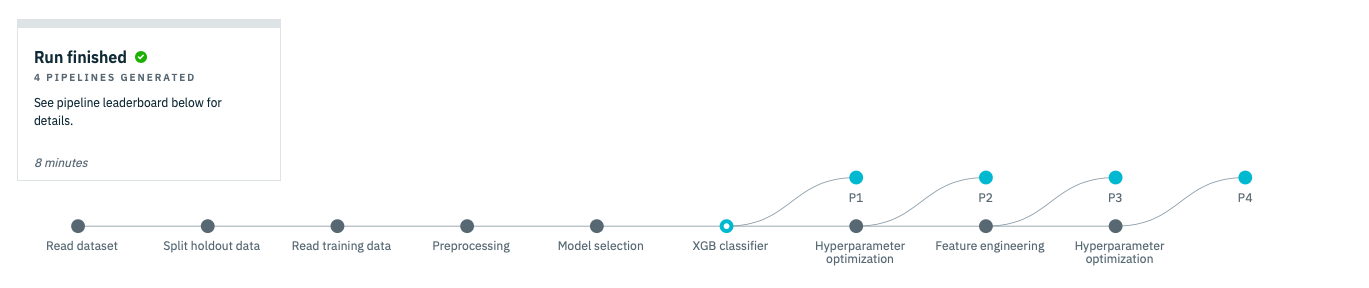
画面を下の方にスクロールすると、次のような画面が出てきます。これは、4つの候補の精度を比較している画面になります。
この中で一番精度のいいモデルをリポジトリに登録し、Webサービス化することにします。そのため、画面赤枠の「Save as model」をクリックします。
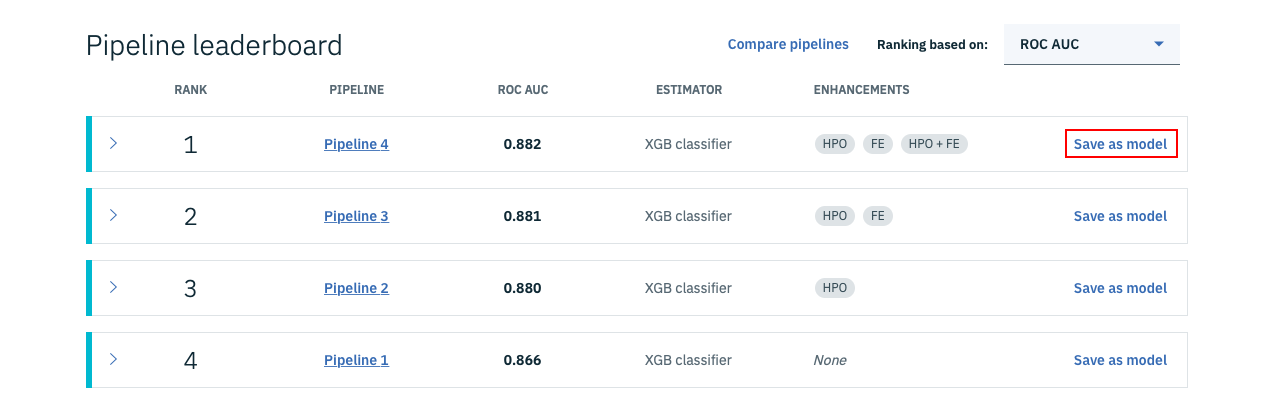
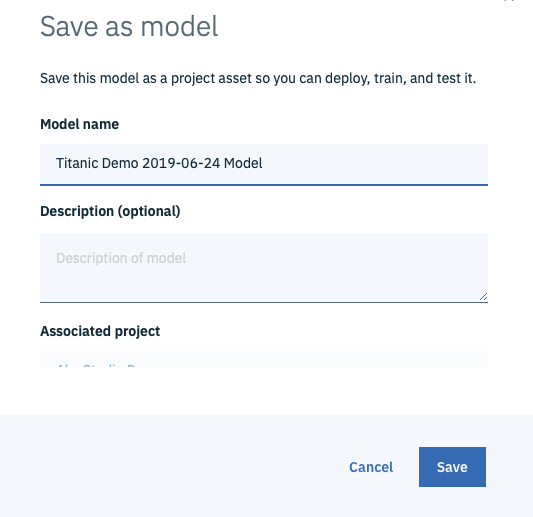
すると、下のような画面になるので、Model nameを適当に入力し、画面右下の「Save」ボタンをクリックします。
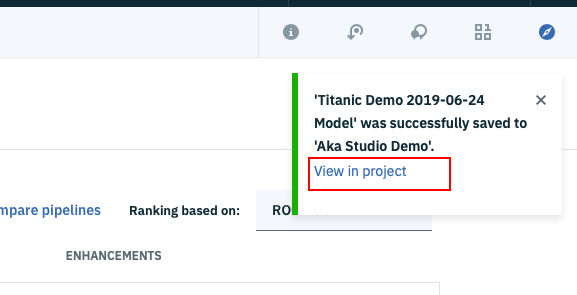
正常に登録ができると、下の画面になるはずです。ここで、赤枠で囲んだ「View in project」をクリックします。
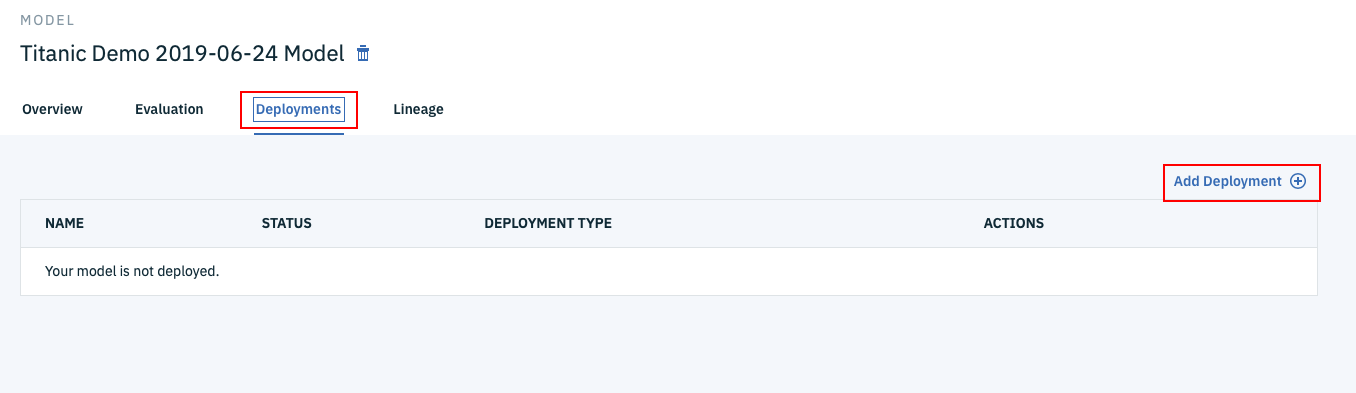
Webサービスの生成
下のように、ML Modelの管理画面になったら、まずDeploymentsタブをクリックし、次に画面右下のAdd Deploymentのリンクをクリックします。
次の画面がでてきたら、Nameの欄に「Titanic AutoAI Web」など適当な名前を入力し、画面右下の「Save」ボタンをクリックします。
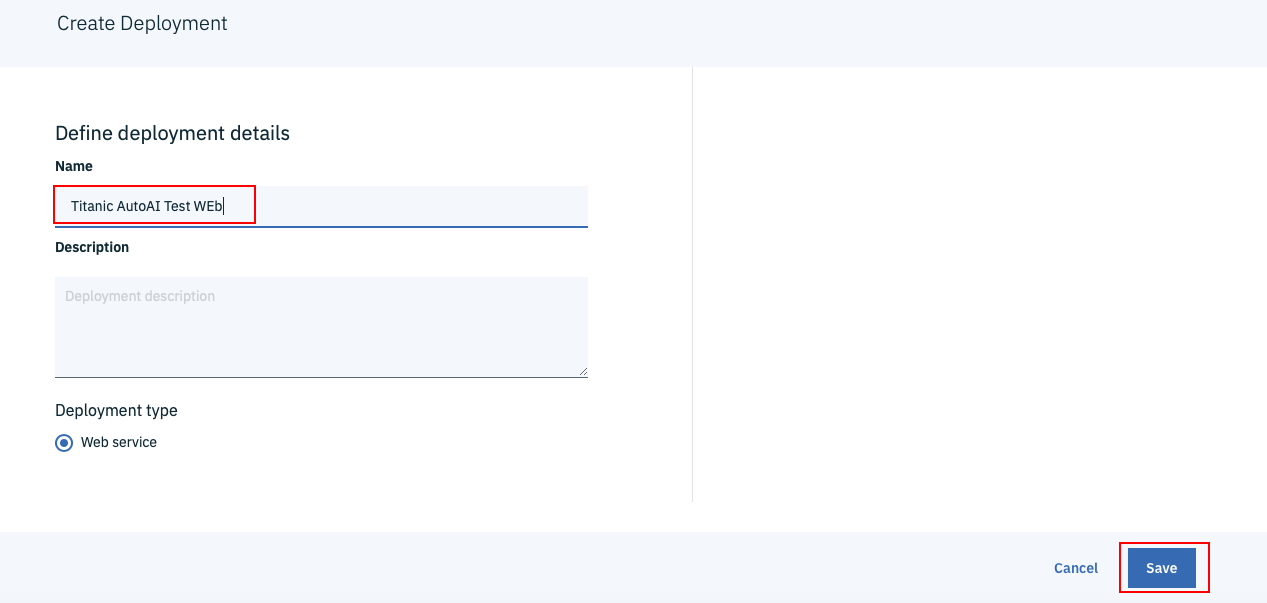
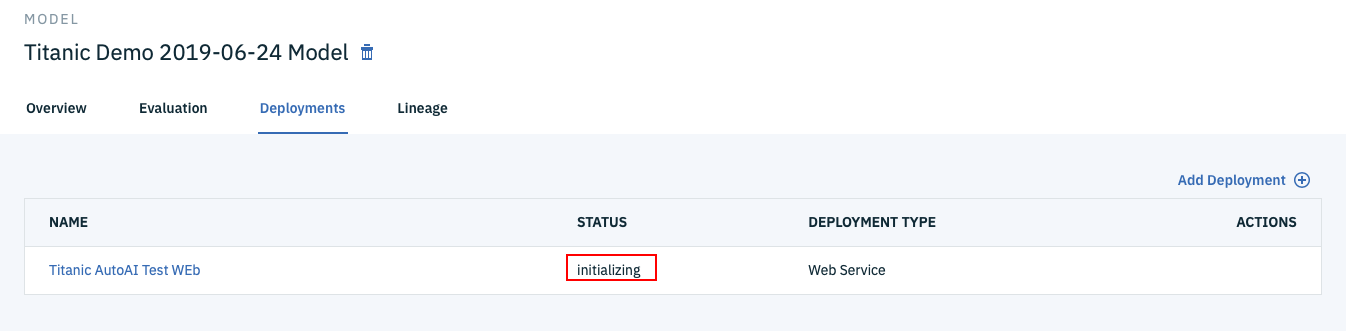
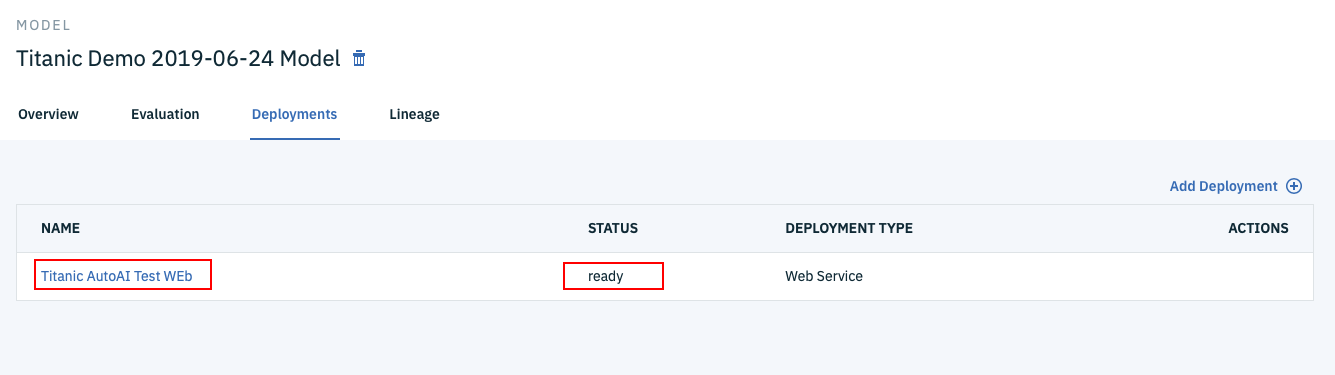
すると下の図のようなDeploymentsタブの画面に遷移します。ブラウザを時々リフレッシュすると、Statusが「initializing」から「ready」に変わっていくはずです。「ready」になったら準備完了なので、一番左のWebサービス名のリンクをクリックします。
Webサービスのテスト
今度はWebサービスの管理画面に遷移しますので、事前にダウンロードしておいたファイルtitanic-autoai.jsonを利用して動作テストをします。
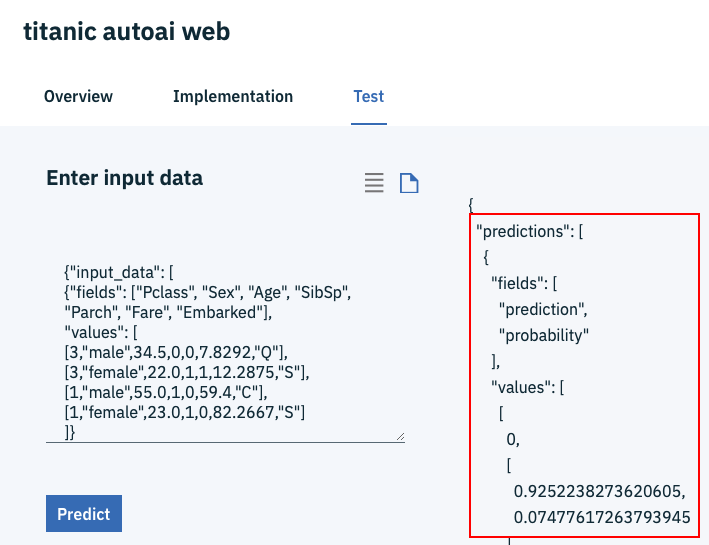
①一番右の「Test」タブを選択します。
②titanic-autoai.jsonをテキストエディタで開いて、ファイルの中身を丸ごと②の場所にコピペします。
③「Predict」ボタンをクリックします。
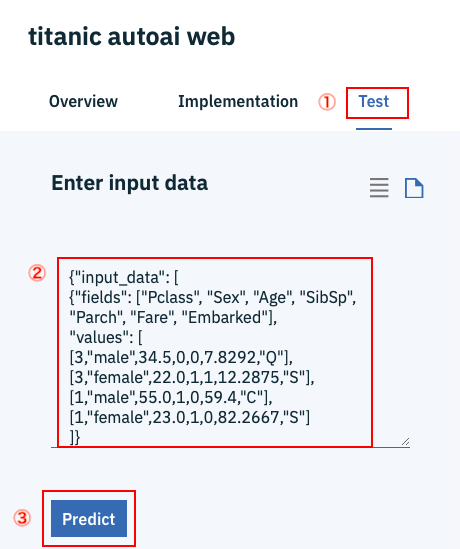
下の画面右のように、prediction(=予測値)、probability(=確信度)の値が返ってくればテストは成功です。
いよいよ次のステップとして、Jupyter Notbook上のPythonプログラムで、Kaggleで提供されているテストデータを利用して、テストデータ全量の精度を検証してみます。
認証情報の確認
これからはPythonプログラムで精度検証を行うのですが、その際、Watson Machine LearningのWebサービスAPIを呼び出します。そのため、Watson Machine Learningの認証情報を事前に確認しておく必要があります。認証情報取得の手順を以下で説明します。
Watson Machine Learningのサービス名の確認
まず、今までのセットアップ手順で自動的に一つ作られているはずである、Watson Machine Learingのサービス名を確認します。
下の図のようにプロジェクト管理のメイン画面で、一番右の「Settings」タブをクリックします。
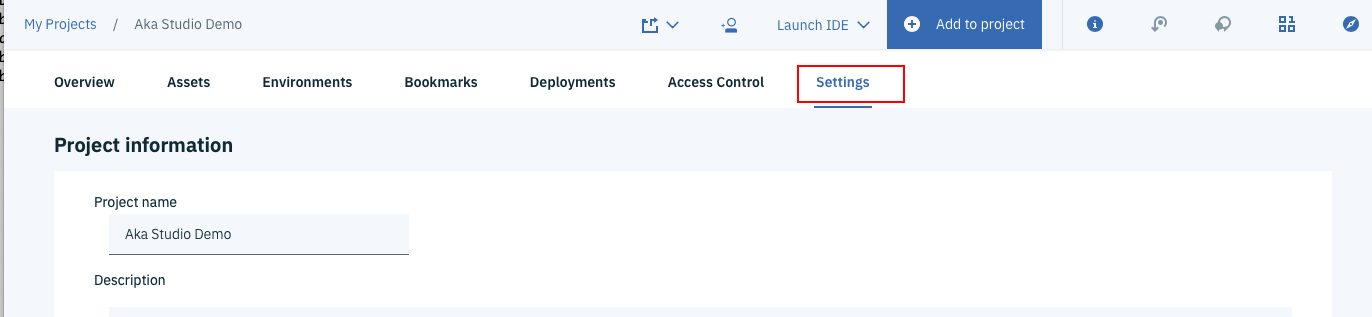
下の方にスクロールすると、次のような画面になりますので、SERVICE TYPEがWatson Machine LearningのサービスのNAMEの欄を調べて下さい。下の図の場合だと、pm-20-oxになります。
Watson ML管理画面の表示
管理画面右上の「三」の場所をクリックします。
下のようなメニューが表示されますので、一番下のIBM Cloudをクリックします。
下のメニューになったら、上から2つめの「Resource List」を選択します。
リソース一覧の画面では「サービス」の欄をクリックして下さい。先ほど調べたWatson Machine Learningのサービス名があるはずので、それをクリックします。

下のようなWatson Machine Learningサービスの管理画面になります。
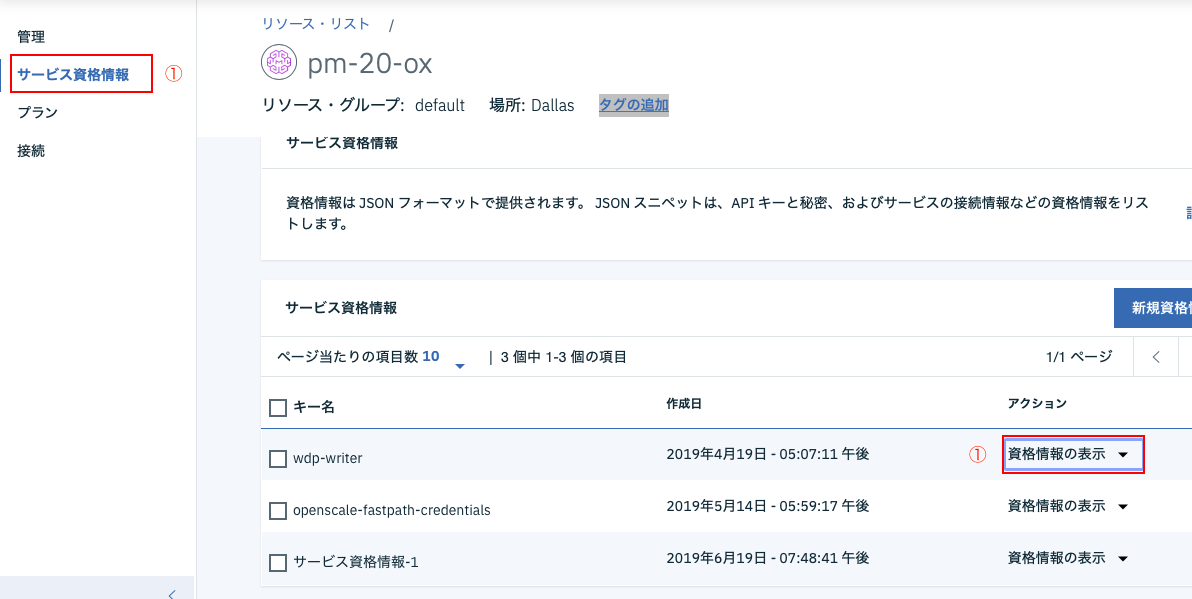
① 左のメニューからサービス資格情報を選択します。
② 資格情報の一覧の中から適当なものを選び(複数ある場合はどれでも可)画面右の資格情報の表示の欄をクリックします。
下のような画面になるはずなので、左上のアイコンをクリックして下さい。これで資格情報全体がクリップボードにコピーされました。
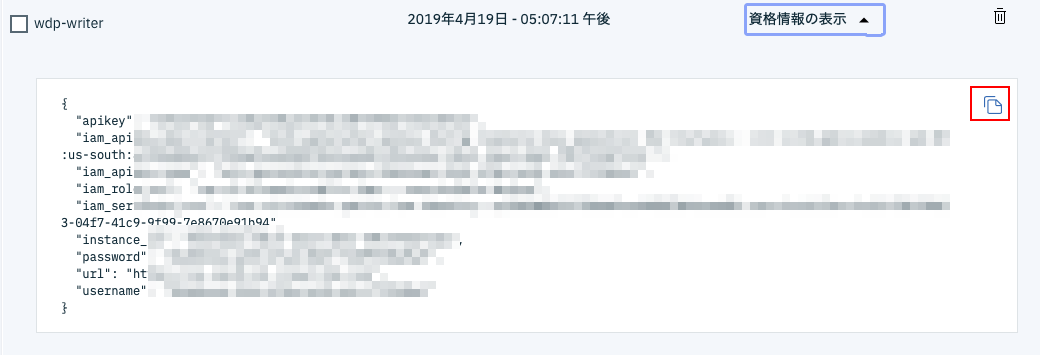
テキストエディタを開いて、先ほどコピーした内容を張り付けます。これから使う精度検証プログラムで必要なのは、下の4項目(instance_id, password, url, username)だけなので
それ以外は削除していったん保存しておきます。
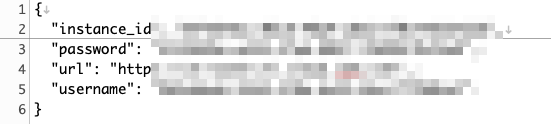
ちょっと手順は長かったですが、これで認証情報の取得は完了です。もう一つ必要な設定情報としてWeb ServiceのScoring URLがあります。以下の手順でこちらを確認します。
Scoring URLの確認
Watson Studioログイン画面から再度Watson Studioにログインします。
下の画面になったら、左上の「三」のアイコンをクリックします。
プロジェクトの一覧が表示されます。先ほど作業したプロジェクトが表示されている場合は、それを選択して下さい。
もし、なかった場合は「View All Projects」を選択し、そこから先ほど作業していたプロジェクトを見つけます。
プロジェクト管理の画面になったら、右から3つめの、「Deployments」タブを選択します。
先ほど作ったTitanic用のWebサービスがあるはずなので、そのリンクをクリックして下さい。
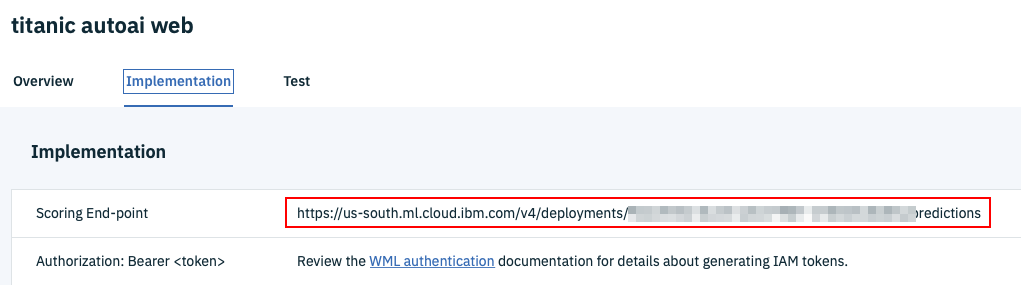
Webサービスの管理画面になったら、真ん中の「Implementation」タブをクリックします。
一番上にある、「Scoring End-point」のURLをコピーして、テキストエディタなどに保存しておいて下さい。
これで、精度検証用のプログラムを動かすための準備は全部整いました。それではいよいよ精度検証を実際に行ってみましょう。
Jupyter Notebookによる精度検証
これからWatson Machine Learning上に登録されたWebサービスを呼び出すことで、Kaggleデータセットの検証を行います。
Watson APIを呼び出す場合は、そのためのライブラリをPython環境に事前に導入する必要があったのですが、これから実行するWatson MLの呼出しコードで使っているライブラリは、デフォルトで入っていると思われるurllib3, requests, jsonのみです。
なので、これからご紹介するサンプルコードは、Watson Studio上のJupyter環境ではもとより、パソコン(検証はMacで行っています)のanaconda環境でも簡単に試すことができます。
サンプルnotebookの読み込み
事前にダウンロード済みのnorebookファイルautoai-test.ipynbをJupyter環境に読み込んで下さい。
認証情報の設定
読み込んだ直後のnotebookは下の図のようになっているはずです。この中のwml_credentailsのセルを、事前準備した認証情報で置き換えて下さい。

Scoring URLの設定
もう一箇所設定が必要なのが、Web Service呼出しのためのScoring URLです。こちらについても事前準備したURLの文字列をセルにコピーして下さい。
テスト実行
お待たせしました。これで、AutoAIテストのための準備はすべて完了です。
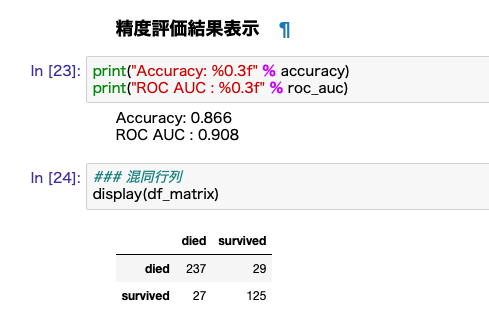
ここまでの設定がすべて正しく行われていれば、すべてのセルを上から順番に実行すれば、Kaggleのテストデータ全418件に関するAUtoAIモデルの予測結果が取得され、それに基づいた精度と混同行列が表示されます。
乱数を使っている関係でいつも同じ結果になるわけではありませんが、私が試した結果をご参考までに添付しておきます。この例だと精度(Accuracy)86.6%、ROC AUC値0.908ということになります。相当高い精度ですね。
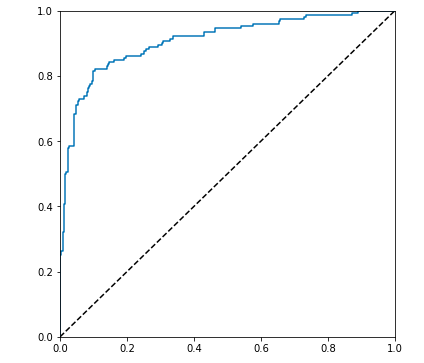
(※) https://www.kaggle.com/c/titanic/leaderboard で調べてみたら、11,300人中170位くらいでした。(2019-06-25現在)
(参考)検証用データからWebサービスを呼び出すサンプルコード
Watson ML上のサービスを呼び出すやりかたは多少クセがあります。
細かい実装はjupyter notebookをみてもらえばその中に全部書かれているのですが、ポイントになるパラメータの作り方を簡単に解説します。Titanic Dataでなく、独自のモデルで同じように精度検証を行う場合にも適用できるよう、汎用的なコードにしていますので、参考とされて下さい。
# テスト用csv読み込み
df_titanic_test = pd.read_csv('titanic_test.csv')
# 正解データ correctの抽出
correct = df_titanic_test['Survived'].values
# API呼出し用入力データ配列の作成
df_sub = df_titanic_test.copy()
# 目的変数列の削除
df_sub = df_sub.drop('Survived', axis=1)
# np.nan値をNoneに置き換え
df_sub = df_sub.where((pd.notnull(df_sub)), None)
# DataFrameから項目名Listの生成
fields = df_sub.columns.tolist()
# DataFrameから入力用Listの生成
values = df_sub.values.tolist()
# payload変数の組立
payload_scoring = {"input_data": [{
"fields": fields,
"values": values
}]}
# APIの呼出し
response_scoring = requests.post(scoring_url, json=payload_scoring, headers=header)
# 戻り値のparse
res = json.loads(response_scoring.text)
pred = res['predictions'][0]
pred_values = pred['values']
pred_fields = pred['fields']
df_res = pd.DataFrame(pred_values, columns = pred_fields)