はじめに
「Pythonで儲かるAIをつくる」の著者です。社内で、この本を題材にした勉強会を主催しているのですが、5.3節の「時系列予測」用に作った、宿題の題材が結構面白いものだったので、qiitaでも共有することにします。
なお、ここで紹介するコードは、Githubにアップしてあります。
時系列予測とは
そもそも、「時系列予測」とはなんでしょうか。冒頭で紹介した私の書籍の中では、「分類」「回帰」と並んで学習方式「教師あり学習」の1パターンであると定義しています。
予測目的が「数値」という点は「回帰」と同じなのですが、予測の入力となる説明変数が「日付データのみ」(厳密にいうと例外もある)というのが一番の違いです。曜日、年などの周期性を持った数値データを予測するのに向いているモデルです。
ただ、 scikit-learnにライブラリがないため、Pythonでモデルを作るのはかなりハードルが高かったです。2017年にFecebook社がProphetというライブラリを公開して、このハードルはかなり下がりました。これから説明するサンプルコードもProphetを前提としたものになります。また、実行環境はGmailアドレスだけでセットアップなしに使えるクラウド環境である、Google Colabを前提にしています。
モデルの目的
普通はここで学習データの業務的な背景や、モデルの目的などを解説するのですが、このテーマに関しては、そうした説明は不要と思います。学習データは公開されている「コロナ陽性者数データ」、目的は直近のコロナ陽性者数の予測です。皆さんも毎日報道を通じて、コロナの陽性者数は週単位の周期性を持ったデータであることはご存じと思います。きっと「時系列分析」に向いている題材なのだろうなと思ってやってみたということになります。
ライブラリの導入とインポート・初期設定
書籍の実習コードと同じ流儀で、ライブラリの導入とインポートや諸々の初期設定をします。実装は以下の通りです。
# 日本語化ライブラリ導入
!pip install japanize-matplotlib | tail -n 1
# 余分なワーニングを非表示にする
import warnings
warnings.filterwarnings('ignore')
# 必要ライブラリのimport
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# matplotlib日本語化対応
import japanize_matplotlib
# データフレーム表示用関数
from IPython.display import display
# 表示オプション調整
# numpyの浮動小数点の表示精度
np.set_printoptions(suppress=True, precision=4)
# pandasでの浮動小数点の表示精度
pd.options.display.float_format = '{:.4f}'.format
# データフレームですべての項目を表示
pd.set_option("display.max_columns",None)
# グラフのデフォルトフォント指定
plt.rcParams["font.size"] = 14
# 乱数の種
random_seed = 123
データの取得
機械学習のコードを自分で組んだことがある人ならわかると思いますが、身近な題材でモデルを作るときに一番苦労するのがデータ取得です。今回は、下記の実装で、きれいなデータが取れることがわかりました。
日別陽性者数データ
厚生労働省のホームページにありました。次の実装をすることで、csvデータを DataFrameに取り込むことができます。
# 厚生労働省の公開データ
url = 'https://covid19.mhlw.go.jp/public/opendata/newly_confirmed_cases_daily.csv'
# データ読み込み
df = pd.read_csv(url, parse_dates=[0])
# 結果確認
display(df.head())
こんな結果になります。

2020年1月から、現在までの陽性者数が県別にまとめられているようです。すぐに時系列予測に使えそうな便利なデータですね。
データ加工
予測は、毎日テレビ・新聞で報道されている東京都の陽性者に対して行うことにします。取得したデータを東京都のものだけに絞り込んだ上で、項目名をProphet用に差し替えます。実装は以下のとおりです。
# 東京都で絞り込み
df3 = df[["Date", "Tokyo"]]
# 列名変更
df3.columns = ['ds', 'y']
# 結果確認
display(df3.tail())
最後、tailで出力しているので結果は日々変わっていきますが、記事を書いた2021年8月28日の時点では、以下の通りでした。

テレビ、新聞でおなじみの数字が出てきました。ちゃんとデータとして取れているようです。
時系列グラフ表示
せっかくなので、時系列グラフ表示をしてみます。実装コードは以下のとおりです。
# 時系列グラフの描画
import matplotlib.dates as mdates
fig, ax = plt.subplots(figsize=(10, 5))
# グラフ描画
ax.plot(df3['ds'], df3['y'])
# 日付目盛間隔
# 木曜日ごとに目盛りを表示
# weeks = mdates.WeekdayLocator(byweekday=mdates.TH)
# 月ごとに目盛りを表示
months = mdates.MonthLocator()
ax.xaxis.set_major_locator(months)
# 日付表記を90度回転
ax.tick_params(axis='x', rotation=90)
# 方眼表示など
ax.grid()
ax.set_title('東京都コロナ陽性者数')
# 画面出力
plt.show()
こんな結果になるはずです。

モデル構築、学習から予測まで
これでデータの準備は整いました。以下の条件で、モデルを作ってみます。
- 最終日の14日前を基準日に、訓練データと検証データを分割する
- 二週間先までの予測をする
- 結果をグラフ表示する
訓練データ・検証データの分割
最終日の14日前を基準日に、訓練データと検証データを分割します。
import pandas.tseries.offsets as offsets
# 分割日 mdayの設定 (最終日から14日前)
mday = df3['ds'].iloc[-1] - offsets.Day(14)
# 訓練用indexと検証用indexを作る
train_index = df3['ds'] <= mday
test_index = df3['ds'] > mday
# 入力データの分割
x_train = df3[train_index]
x_test = df3[test_index]
# 日付データの分割(グラフ表示用)
dates_test = df3['ds'][test_index]
モデルの生成・学習
モデルインスタンスを生成し、学習します。パラメータの意味については書籍「Pythonで儲かるAIをつくる」を参照して下さい。
# ライブラリのimport
from fbprophet import Prophet
# モデルインスタンス生成
m1 = Prophet(yearly_seasonality=False, weekly_seasonality=True,
daily_seasonality=False,
seasonality_mode='multiplicative')
# 学習
m1.fit(x_train)
予測と結果のグラフ化
# 予測用データの作成
future1 = m1.make_future_dataframe(periods=14, freq='D')
# 予測
# 結果はデータフレームで戻ってくる
fcst1 = m1.predict(future1)
# 訓練データ・検証データ全体のグラフ化
fig, ax = plt.subplots(figsize=(10,6))
# 予測結果のグラフ表示(prophetの関数)
m1.plot(fcst1, ax=ax)
months = mdates.MonthLocator()
ax.xaxis.set_major_locator(months)
# 日付表記を90度回転
ax.tick_params(axis='x', rotation=90)
# タイトル設定など
ax.set_title('陽性者数予測')
ax.set_xlabel('日付')
ax.set_ylabel('陽性者数')
# グラフ表示
plt.show()

グラフの見方ですが、点による表現が正解値、青い線が予測値です。青い線は信頼区間による幅を持っています。このグラフを見ると、予測の精度を議論する以前に、直近の予測値が感染爆発を起こしている実測値を表現できていないことがわかります。このままでは、正しく予測することは難しそうです。
チューニング
直近の動きを正確に予測するためには、過去データを捨てて、最近のデータのみを学習データとして利用するのがさそうです。今回は、最近の中で陽性者数が一番少なくなっている2021-06-15からにデータを限定することとします。
# 分割日 mdayの設定 (最終日から14日前)
mday = df3['ds'].iloc[-1] - offsets.Day(14)
# 訓練用indexと検証用indexを作る
train_index = df4['ds'] < mday
test_index = df4['ds'] >= mday
# 入力データの分割
x_train = df4[train_index]
x_test = df4[test_index]
# 日付データの分割(グラフ表示用)
dates_test = df4['ds'][test_index]
# モデルインスタンス生成
m2 = Prophet(yearly_seasonality=False, weekly_seasonality=True,
daily_seasonality=False,
seasonality_mode='multiplicative')
# 学習
m2.fit(x_train)
# 予測用データの作成
future2 = m2.make_future_dataframe(periods=9, freq='D')
# 予測
# 結果はデータフレームで戻ってくる
fcst2 = m2.predict(future2)
# 訓練データ・検証データ全体のグラフ化
fig, ax = plt.subplots(figsize=(10,6))
# 予測結果のグラフ表示(prophetの関数)
m2.plot(fcst2, ax=ax)
weeks = mdates.WeekdayLocator(byweekday=mdates.TH)
ax.xaxis.set_major_locator(weeks)
# 日付表記を90度回転
ax.tick_params(axis='x', rotation=90)
# タイトル設定など
ax.set_title('陽性者数予測')
ax.set_xlabel('日付')
ax.set_ylabel('陽性者数')
# グラフ表示
plt.show()
最後のグラフ表示の結果は、次のようになりました。

先ほどと比較して、直近の実測値ともよく適合していそうです。
最後に検証期間のみで、予測結果、実績のグラフ表示をします。
# ypred2: fcst1から予測部分のみ抽出する
ypred2 = fcst2[-14:][['yhat']].values
# ytest1: 予測期間中の正解データ
ytest2 = x_test['y'].values
# 時系列グラフの描画
import matplotlib.dates as mdates
fig, ax = plt.subplots(figsize=(8, 4))
# グラフ描画
ax.plot(dates_test, ytest2, label='正解データ', c='k')
ax.plot(dates_test, ypred2, label='予測結果', c='b')
# 日付目盛間隔
# 木曜日ごとに日付を表示
weeks = mdates.WeekdayLocator(byweekday=mdates.TH)
ax.xaxis.set_major_locator(weeks)
# 日付表記を90度回転
ax.tick_params(axis='x', rotation=90)
# 方眼表示など
ax.grid()
ax.legend()
ax.set_title('コロナ陽性者数予測')
# 画面出力
plt.show()
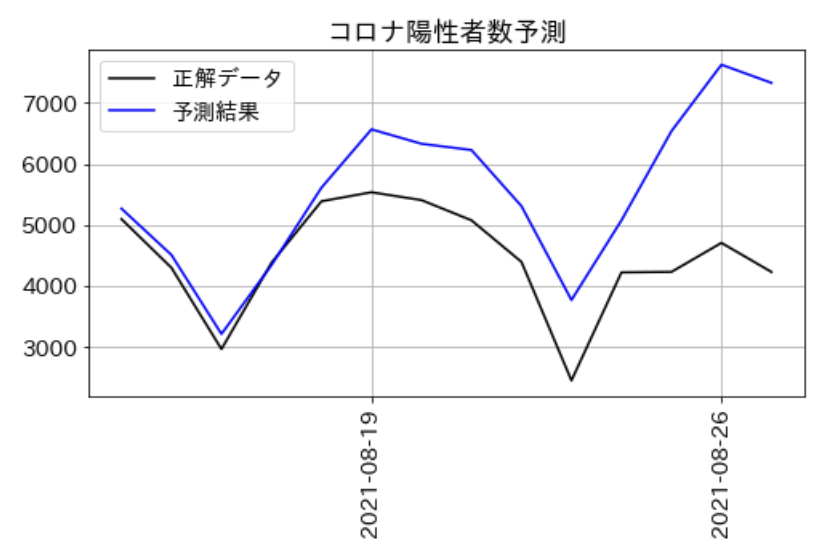
直近は、予測結果と比較して正解データの陽性者数の方が少ない傾向が読み取れます。何が効いたのかまではわかりませんが、コロナ抑止の社会の動きの効果なのだと思います。
おまけ
この記事では解説しませんでしたが、Prophetでは、holidaysというパラメータで休日などのイベントを定義することが可能です(書籍には記載があります)。日本の休日ってどうやったらわかるのか気になったので、そのデータを取得する方法をメモとして記載しておきます。
# 祝日データ取得
url2 = 'https://raw.githubusercontent.com/holiday-jp/holiday_jp/master/holidays.yml'
df5 = pd.read_csv(url2, sep=':\s+', parse_dates=[0],names=['日付','祝日名'])
df5 = df5[1:]
細かいテクニックがいくつかあるのですが、それは省略して結果だけいうと、このコードで休日リストを取得することが可能です。

上の結果のように、1970年から2050年までの祝日のリストが取得できました。
普通は、こんなに広い範囲のデータはいらないので、例えばこんな実装で絞り込んで使うといいでしょう。
# 2020-2021に絞り込み
df5 = df5.query('日付>"2019-12-31" & 日付<"2021-12-31"')

最後に
実データを使った、時系列分析の実装はいかがだったでしょうか?もっと詳しいことを知りたい方は、是非「Pythonで儲かるAIをつくる」を参照して下さい。5.3節により詳しい解説があります。
- Amazonへのリンク
単行本
Kindle - 関連リンク
書籍「Pythonで儲かるAIをつくる」サポートサイト
最短コースで機械学習を学べる 書籍「Pythonで儲かるAIをつくる」紹介