はじめに
書籍「Pythonで儲かるAIをつくる」の著者です。当記事でこの本の特徴をご紹介します。

Amazonリンク(単行本)
https://www.amazon.co.jp/dp/4296106961
Amazonリンク(Kindle)
https://www.amazon.co.jp/dp/B08F9P726T
本書サポートサイト (Github)
https://github.com/makaishi2/profitable_ai_book_info/blob/master/README.md
まずは、下記の目次をご覧下さい。
タイトルで誤解を受けることが多いのですが、目次を見ていただければわかるとおりいたって真面目な書籍です。「AIを使ってFXや株で大儲けをしよう」という本ではありませんので、誤解なきようお願いします。
主な対象読者
本書は、主に次の2つの読者層を想定しています。

業務専門家
IT部門でなく、実業務を担当しているリーダークラスの責任者。これから自分の業務のAI化を進めたいが、どこから手をつけたらいいかわからない人。
この場合、本書の1章、2章、3章を読んだ後、自分の業務に適用できそうな処理パターンにあたりをつけて、5章の該当節を読み進めて下さい。4章はオプションになりますが、4.1節、4.4節はできるだけ読んでほしいです。6章は重要なので是非読んで下さい。
データサイエンティスト志望者
元々プログラミングが得意で、これからデータサイエンティストとしてのスキルを伸ばしていきたい人。
この場合は、飛ばさずに最初から全部読み進めて下さい。
本書の本文のサンプルコーディングは、Python、Pandas、matplotlibといった言語、ライブラリはある程度理解している前提で書かれています。このあたりの知識が不十分な場合は、本書巻末の「講座2 機械学習のためのPython入門」にこれらのライブラリの簡潔な解説があるので、そちらから先に読んで下さい。本書のコーディングで出て来る必要最小限の機能を最短コースで説明しています。
ライブラリ以前にPythonの経験もない方もいるかもしれませんが、心配は無用です。こういう人向けには本書のサポートページ(Github)上にPython入門を公開しました。こちらも書籍の実習で出てくる必要最小限の文法に絞り込んだ最短コースのPython入門になっています。
書籍の特徴
業務専門家にとって
今までAIと接点がなかった業務専門家にとってAIとは「なんだか得体の知れないもの」あるいは「何でもできるすごいもの」といったイメージを持ちがちです。実は、現在のAI技術でできることはかなり限定されています。
本書を通読することで、AIでできることがなんであるか理解できます。本書の中で「処理パターン」と呼んでいる、「分類」「回帰」「クラスタリング」といった、AIでできることと、自分の業務の対応付けができるようになります。このことこそが、AI化を推進する第一歩になります。下の図は、本書5章でまとめている処理パターン一覧です。
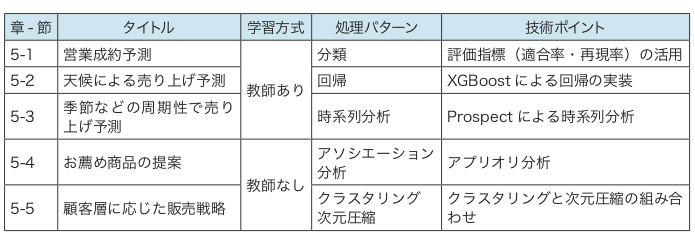
1行1行のコーディングの意味は必ずしも理解できなくて構わないので、5章のうち、自分が業務で適用してみたい処理パターンについては、必ずPython実習も流してみるようにして下さい。処理の流れをPythonコードを通じて理解することで、機械学習モデルの適用パターンをより具体的にイメージすることができます。
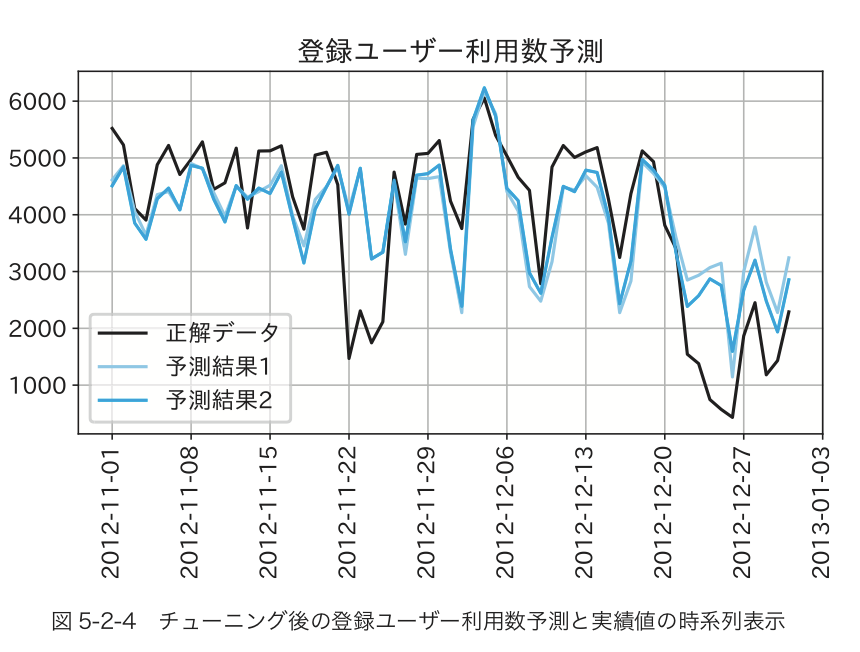
例えば、下の図は、5.2節の例題(回帰)の実習中に出てくるモデルの予測結果と正解を重ねがきしたグラフになります。
また、6章ではAI化を進めるにあたって陥りがちな落とし穴についても解説があります。ここに書かれていることを十分に理解することで、初めて実業務適用が可能なPoC(Proof of Conceptの略。AI化を着手するにあたった最初に行う技術検証のこと)を間違いなく選択できるようになります。具体的な6章の内容は以下の通りです。

データサイエンティスト志望者にとって
データサイエンティスト志望者にとっての本書の最大の特徴は、機械学習モデルをPythonで構築するために何をしたらいいかが最短コースで理解できる点にあります(この点を指してSNS上で「超爆速カリキュラム」と評していただいた読者もいます)。
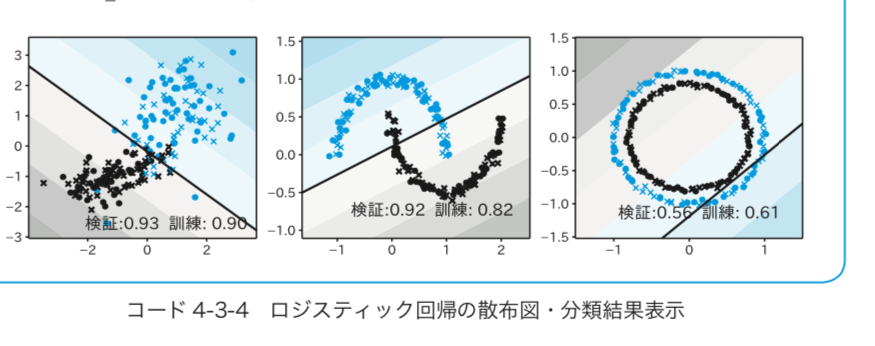
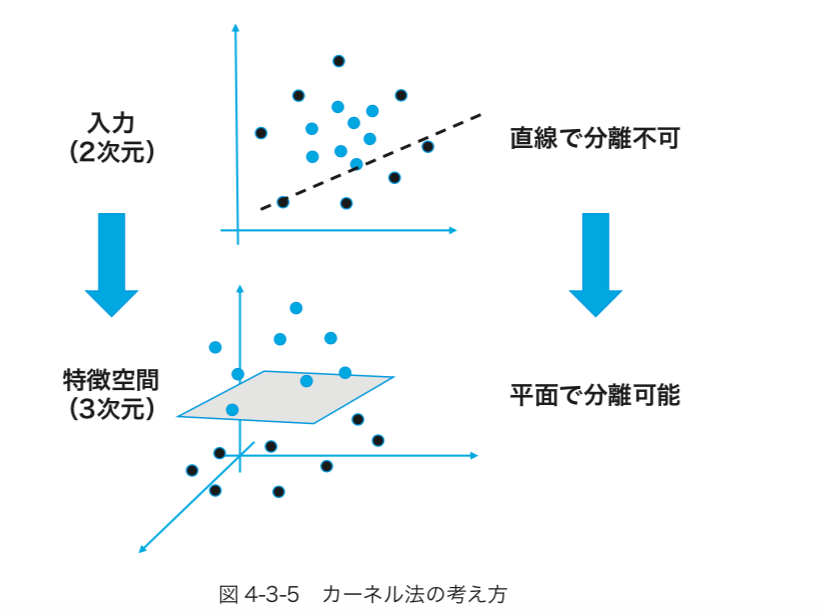
この目的を実現するため、従来の機械学習の解説書で多くのページを割きがちであったアルゴリズムの数学的説明は、図を多用したイメージによる最小限のものに限定し、数式は加減乗除のみとしました。そして、具体的にどうしたら機械学習モデルを作れるかという点に力点を置きました。こうすることで、従来の機械学習・データサイエンス本にありがちだった、数学的なハードルが低くなりました。
難しい数学の話は省略した一方で、教師あり機械学習で重要な評価については、1節(4.4節)を割いて、かなり詳しく解説しました(具体的には精度(Accuracy)と適合率(Precision)、再現率(Recall)をどのように使い分けるかなど)。数式としては分数式だけで理解できる節なので、是非、この節は完全に理解するようにして下さい。
データサイエンティスト・プログラマー向けの従来の入門書では、モデルの技術的説明と実装コードで話が終わってしまい、業務観点の解説が少ない傾向があったかと思います。
本書の5章では、必ず冒頭に「この処理パターンはこのような業務のこのような箇所で使える」という点を説明するようにしています。データサイエンティスト志望者は、章の冒頭のこの説明を念頭において実装コードを読み進めることで、「処理パターンと業務の対応付け」を含めて理解することができるようになります。
その他の特徴
その他、本書の特徴として次のようなことがあります。
-
実習コードはGoogle Colab前提
Google Colabとは、Gmailのアカウントさえ持っていれば、セットアップ手順なしにすぐに使えるクラウド上のPython(Jupyter Notebook)環境です。実習コードそのものもすべてインターネット(Github)に公開されているので、今までPython、Jupyter Notebookの導入が手間が大変で書籍の実習ができなかった読者も、すぐに実習コードを動かすことができます。
具体的な手順については、qiitaに別記事を記載していますので、そちらを参照されて下さい。
Google Colaboratoryで書籍「Pythonで儲かるAIをつくる」の実習コードを動かす方法 -
最新技術の採用
5.2の回帰でXGboostを使ったり、5.3の時系列分析でProphetを使ったり、機械学習の最新技術も取り入れています。この場合も高度な利用方法には踏み込まず、あまり利用経験のないユーザーがすぐに使えるレベルにとどめているので、「最新技術なので難しいのでは」という心配はありません。 -
アソシエーション分析も事例化
マーケティング分析で多用されるアソシエーション分析(教師なし学習の一種)は、Python機械学習のデファクトスタンダードであるscikit-learnにライブラリがないことから、従来あまりPythonで実習ガイドがなかった領域です(R言語が用いられることが多かった)。本書ではscikit-learnと別のライブラリであるmlextendを利用することで、この領域の実習も実現しています。その概要については、qiitaで別記事を記載しましたので、関心がある方は参照して下さい。
Pythonでアソシエーション分析
更に詳しく知りたい方は
本書のサポートページに、5章と同じ書きぶりの追加事例と、Python文法の解説であるPython入門を公開しています。こちらを読んでいただくと、より本書のイメージがよりつかめるかと思います。