はじめに
Watson Studioは多くの製品・サービスの集合体なのですが、その1つとしてSPSS Modelerのクラウド版があります。
この機能を使って簡単な機械学習モデルを作ってみます。
[2018-07-23] サンプルアプリケーションデプロイ手順の追加
[2018-10-26] モデルのPythonからの呼出し手順追記
[2020-04-25] 初期セットアップ手順修正
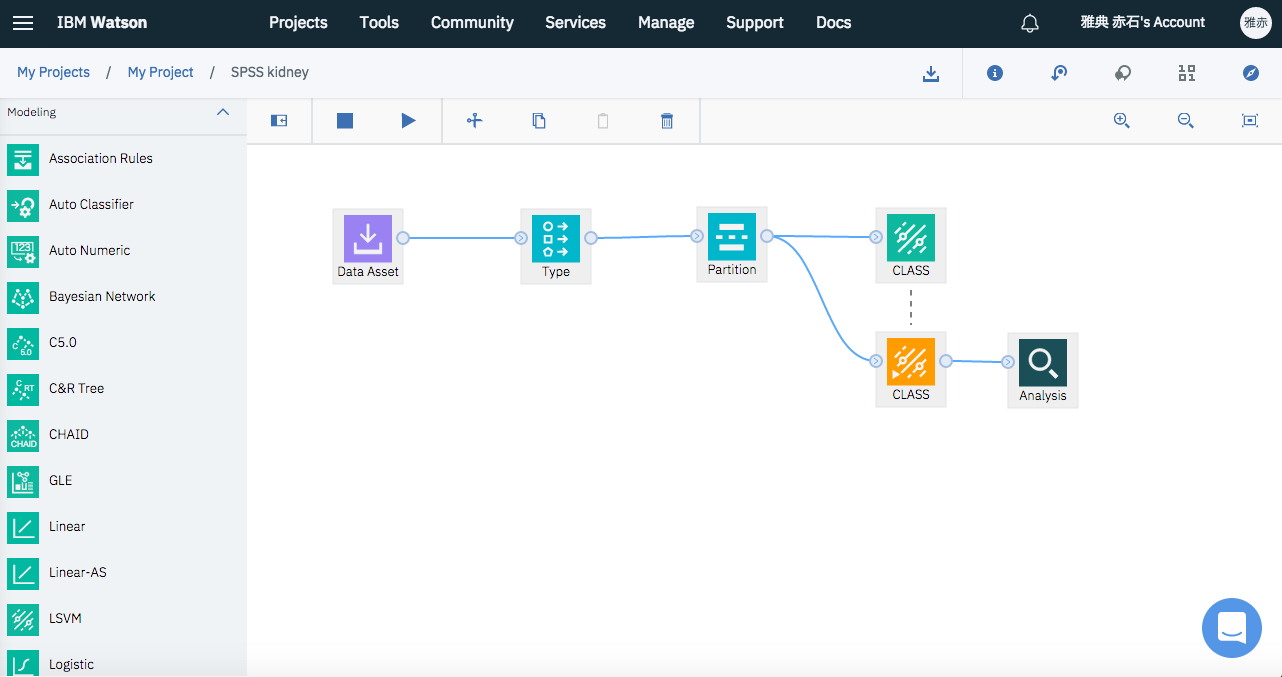
例題
例題として、https://archive.ics.uci.edu/ml/datasets/Chronic_Kidney_Diseasに公開されている慢性腎疾患データを使い、検査データから該当者がこの病気にかかっているかどうかを判定するモデルを作ります。
オリジナルのデータは検査項目が24項目あるのですが、簡単にするため項目数をAGE(年齢)、BP(血圧)、AL(アルブミン)、SC(クレアチニン)、POT(カリウム)、PCV(ヘマトクリット値)の6つに減らしました。
元のデータが非常に性質のいいものなので、これぐらい項目数を減らしても十分に精度のいい結果が得られます。
前提
Watson Studioが使えるようになっていることが前提です。
手順は、
無料でなんでも試せる! Watson Studioセットアップガイド
を参考にして下さい。
この記事ではオプション扱いになっているWatson Machine LearningとSparkとの連携も必要ですので、注意して下さい。
CSVファイルのアップロード
実習で使うCSVファイルはダウンロード元からダウンロード可能です。
ダウンロードした CSVファイルは、Watson Studioのプロジェクト管理画面から、「Add to project」->「Data asset」でアップロードします。
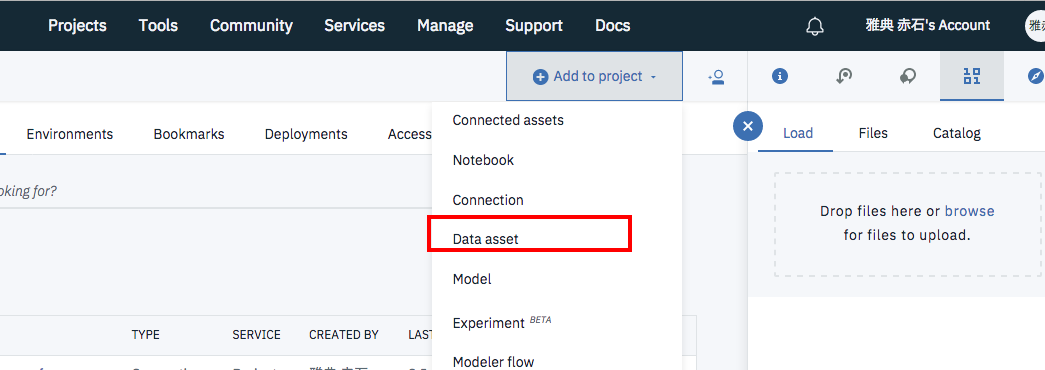
モデラーの起動
Watson Studio管理画面から「Add to project」->「Modeler flow」を選択します。
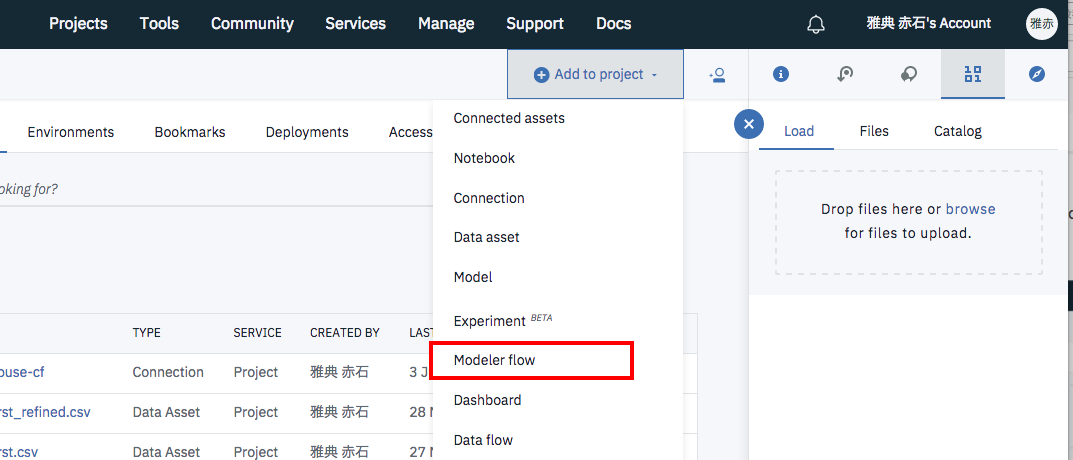
下のような画面になるので、名前を「SPSS Kidney」として、他のオプションはデフォルトのままで画面右下の「Create」ボタンをクリックします。
CSVデータの取込み
下のような初期画面が表示されるので、まずCSVデータ取込みを行います。
左のパレットから「Import」をクリックし、「Data Asset」のアイコンを作業エリアにドラッグアンドドロップします。
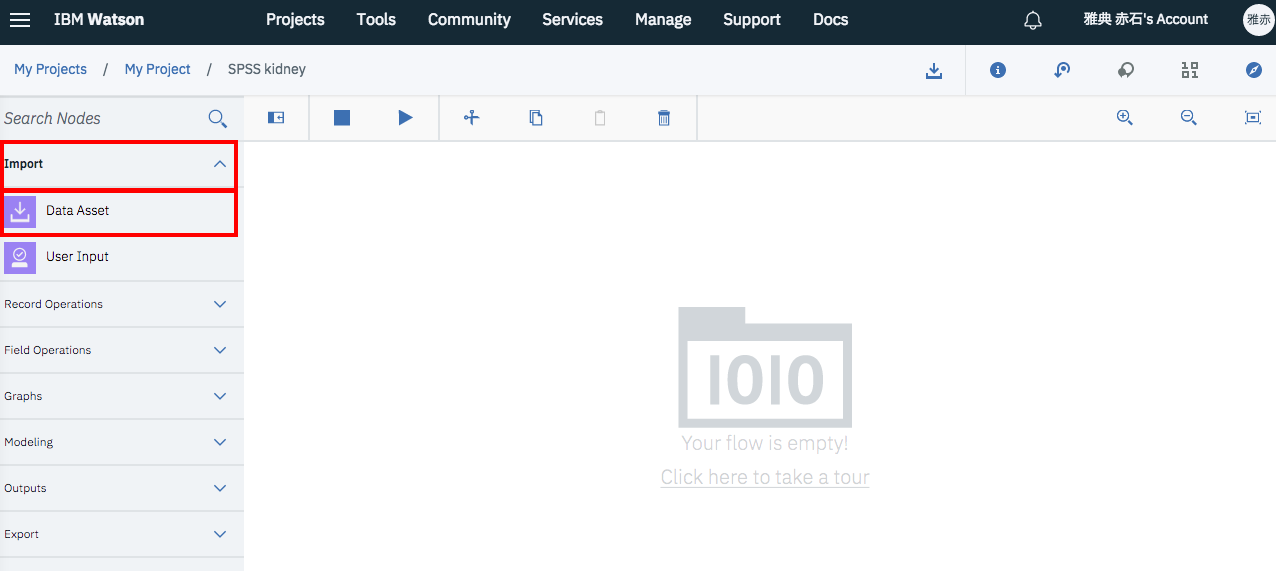
作業エリア上のアイコンでマウス右ボタンクリックするとメニューが表示されます。
メニューから「Open」を選択すると、下のような編集画面が、右側に現れます。
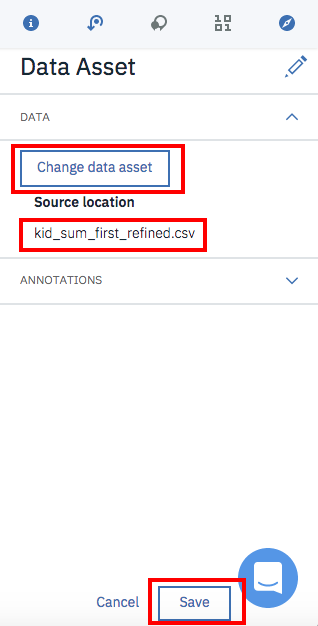
「Change data asset」で先ほどアップロードした「kid_sum_first_refined.csv」を選択し、画面右下の「Save」ボタンをクリックします。
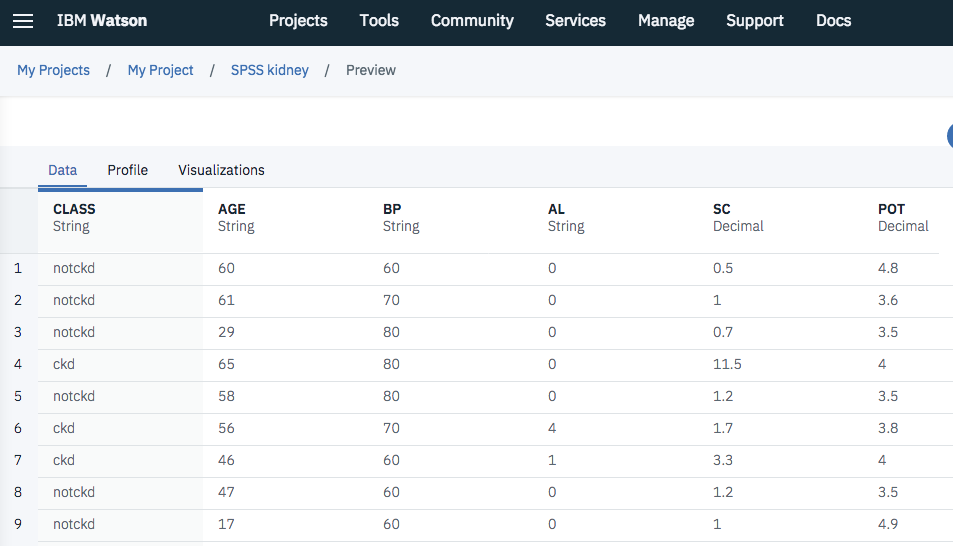
読み込んだデータの中身を確認するため、再度「Data asset」アイコンでマウス右クリックを行い、今度は「Preview」を選択します。
しばらくすると、下の図のように、データの内容が表示されます。
Typeアイコンの追加
次にCSVデータを入力データ列と正解データ(教師データ)列に仕分けます。
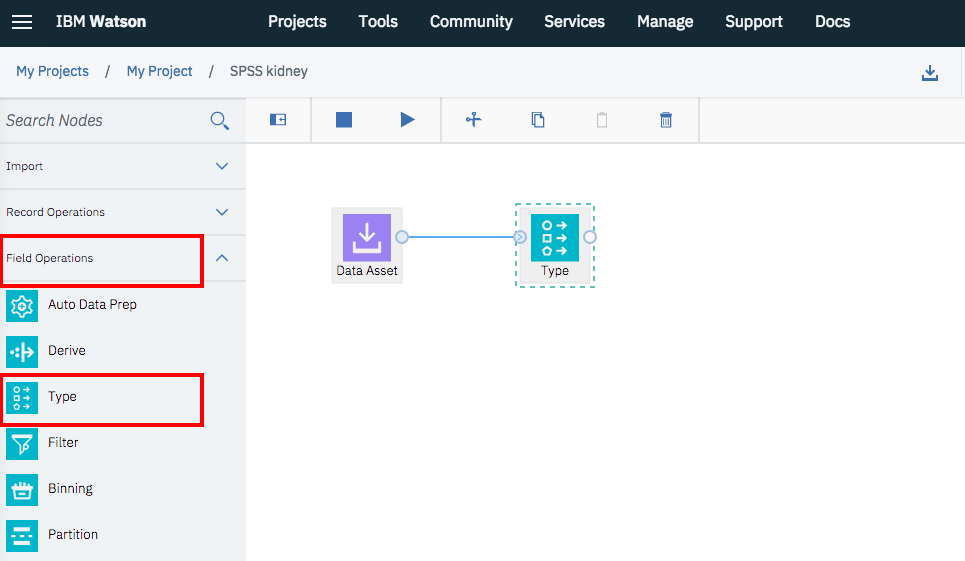
このために使うのが「Type」アイコンです。
「Field Operations」から「Type」アイコンを追加し、「Data Asset」アイコンと接続します。
その後で、Typeアイコン上にマウスを移動して右ボタンクリック->「Open」として下のような属性設定の画面を開きます。
ここで「Configure Types」のリンクをクリックします。
下の画面が出てきたら、「Read Values」のボタンをクリックしてCSVの属性チェックをします。
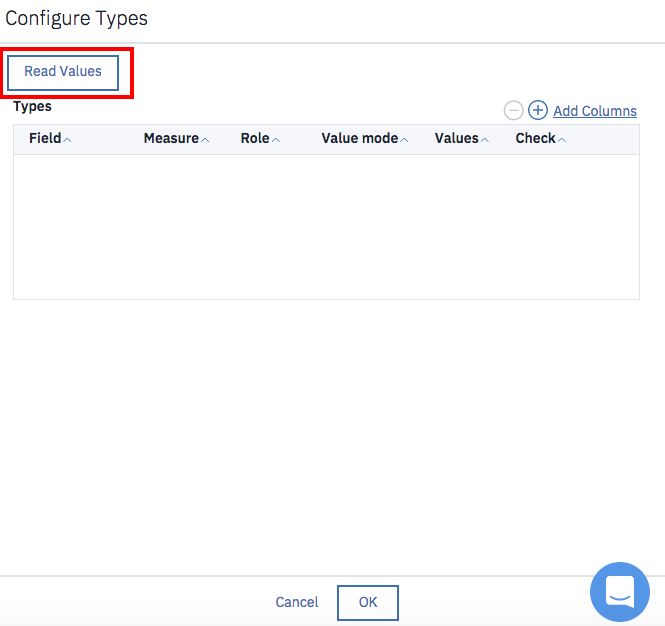
チェック後に下のような画面になります。
ちょっとわかりにくいのですが、項目のリストはスクロール可能な画面になっています。
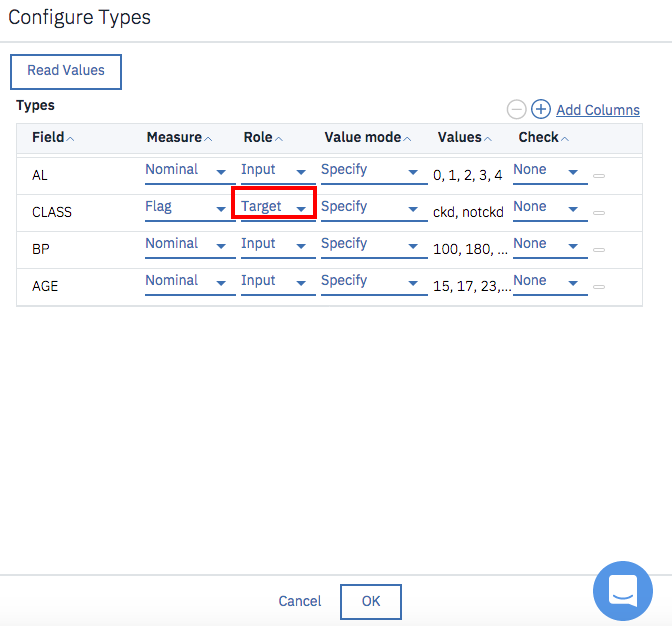
下の方にスクロールして、CLASSの「Role」を「Target」に変更して「OK」をクリックして下さい。
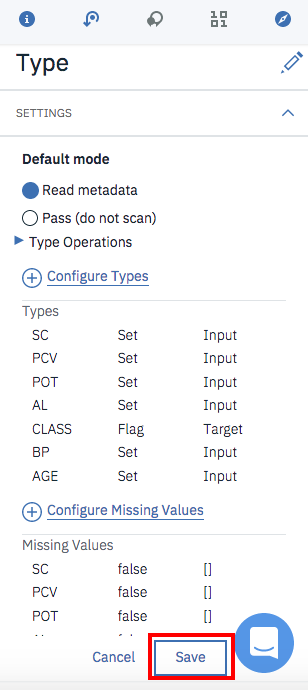
属性設定の画面が下のように変わっていることを確認した上で、「Save」をクリックします。
Partitionアイコンの追加
次に入力のCSVデータを学習データと検証データに分けるための処理を行います。
そのため、Partitionアイコンの追加を行います。
Partitionアイコンは、Field Operationsグループにあるので、今までと同じように作業エリアにドラックアンドドロップし、下の図のようにTypeアイコンを線で結んで下さい。
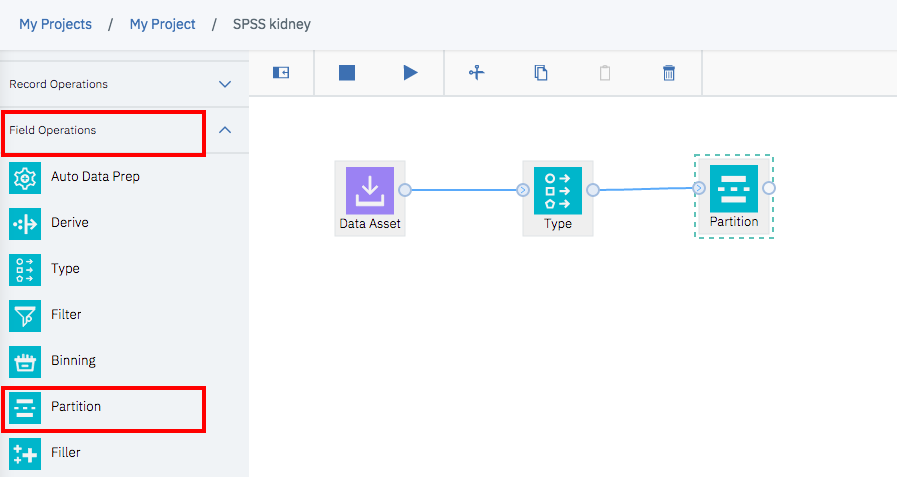
先ほどと同じように、Partitionのアイコンにマウスを動かして右ボタンクリックし、「Open」を選択します。
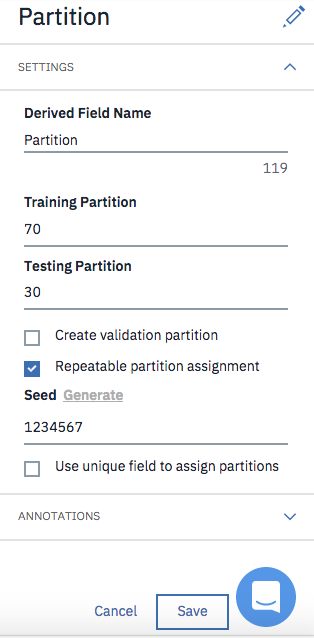
「Training Data」と「Testing Data」の比率は70対30に変更して、「Save」をクリックします。
モデルの作成・学習
今までのステップで、機械学習に必要なデータの前加工はすべて終了しました。
次にいよいよモデルのアイコンを配置して、学習を行います。
モデルのカテゴリーには多数のモデルがありますが、今回は「LSVM」(Liniear Support Vector Machine)を利用します。
モデルのリストは、「Modeling」グループに含まれています。
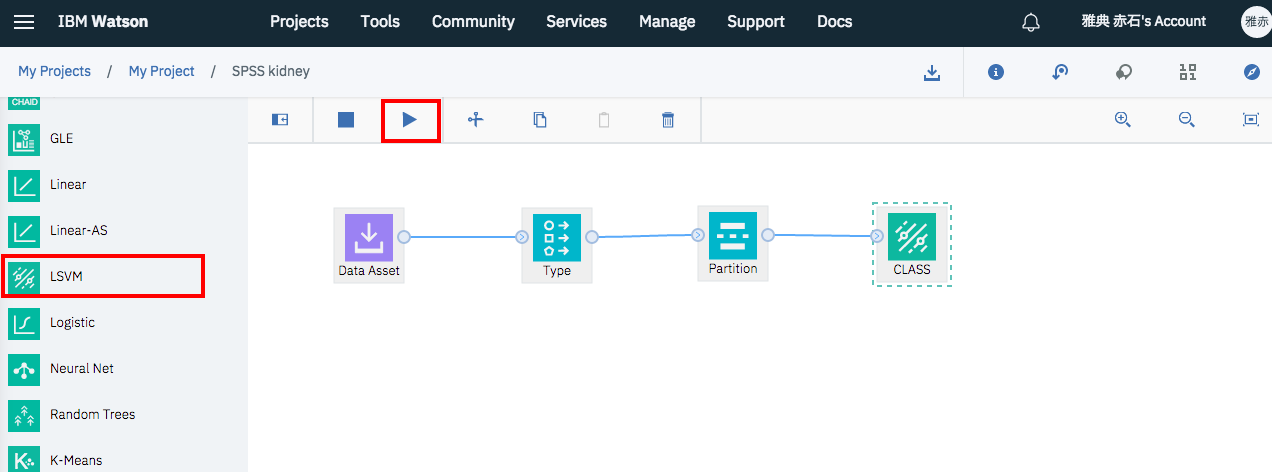
リストを下にスクロールして赤枠で囲まれた「LSVM」をドラッグアンドドロップして、図のようにPartitionアイコンと結線して下さい。
モデルアイコンに関しては、属性の設定は行わず全部デフォルト値で学習することにします。この状態で、赤枠で囲んだ「Run」アイコンをクリックし、学習を開始して下さい。
学習中は次のような画面が表示されます。
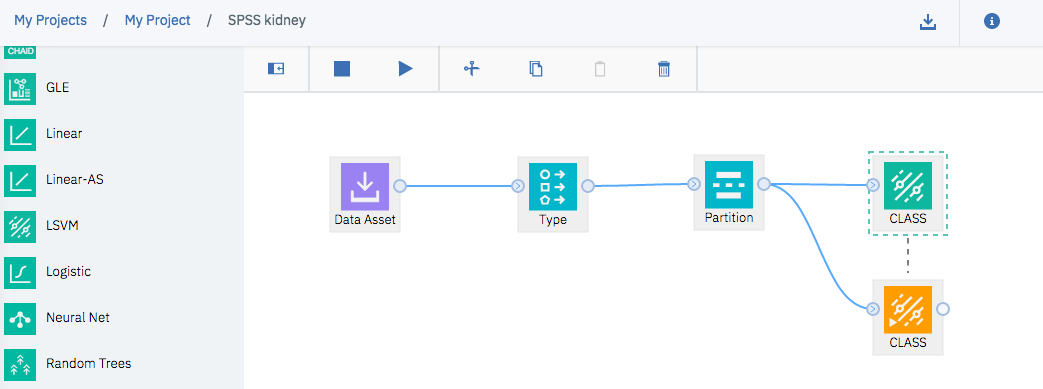
しばらく待っていると、下記のように新しく黄色のアイコンが追加されます。
これはSPSSでは学習済みのモデルを意味しています。
モデルの確認
新しくできた黄色のアイコンにマウスポインタを動かし、右ボタンクリックすると、「View Model」のメニューがあるので、こちらを選択します。すると、下の図のようなモデルの詳細情報を確認できるようになっています。
(このメニューは、モデル毎に異なっています)
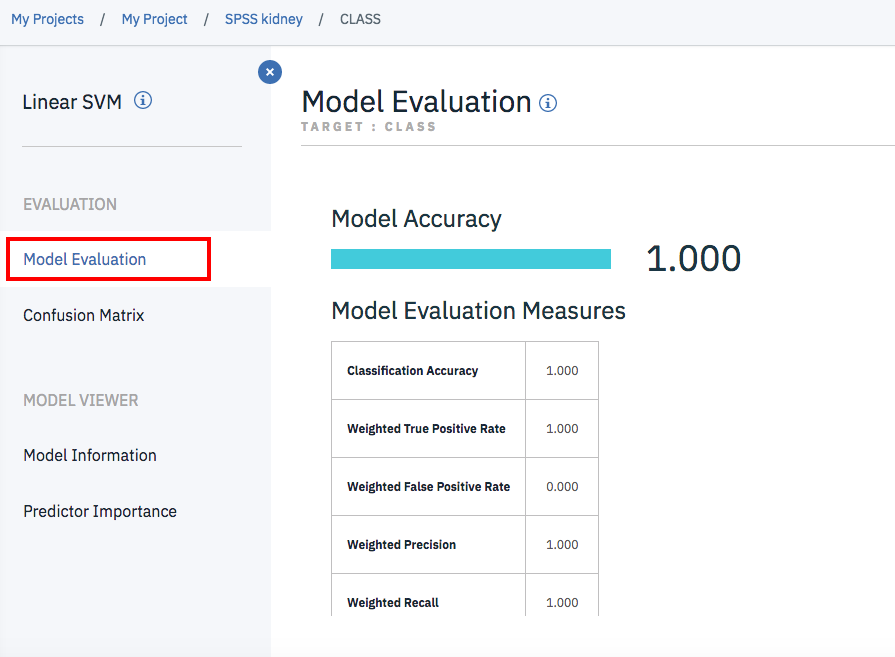
Model Evaluation
「Model Evaluation」は学習データを利用したモデルの評価結果です。
(検証データに対する評価は後ほど別途行います)
今回は学習データに対しては100%の精度が出たようです。
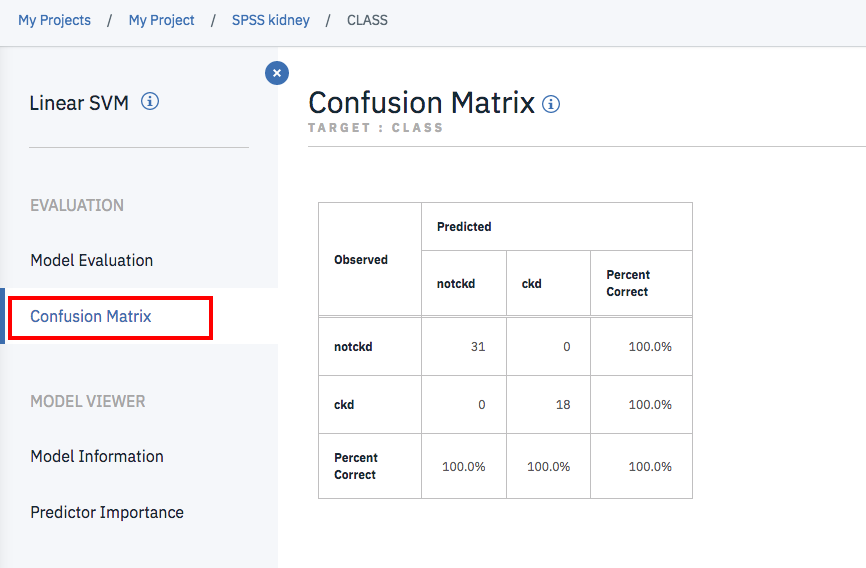
Confusion Matrix
分類型のモデルは「Confusion Matrix」という名前のマトリックスを使って評価する手法もあります。(対角線上のデータが正解にあたる)
このページはこの手法による評価結果を表示しています。
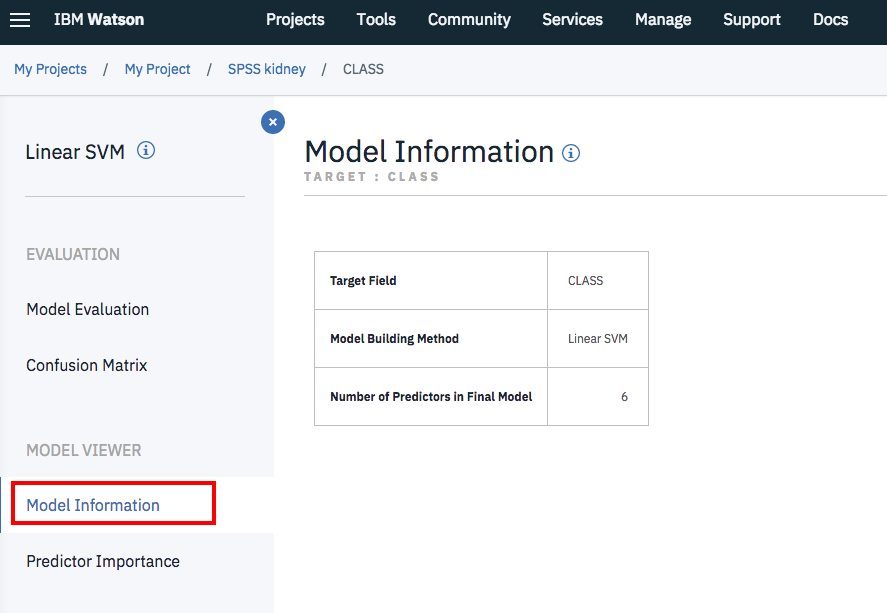
Model Information
このページはどういうモデルを使っているかのサマリーが表示されます。
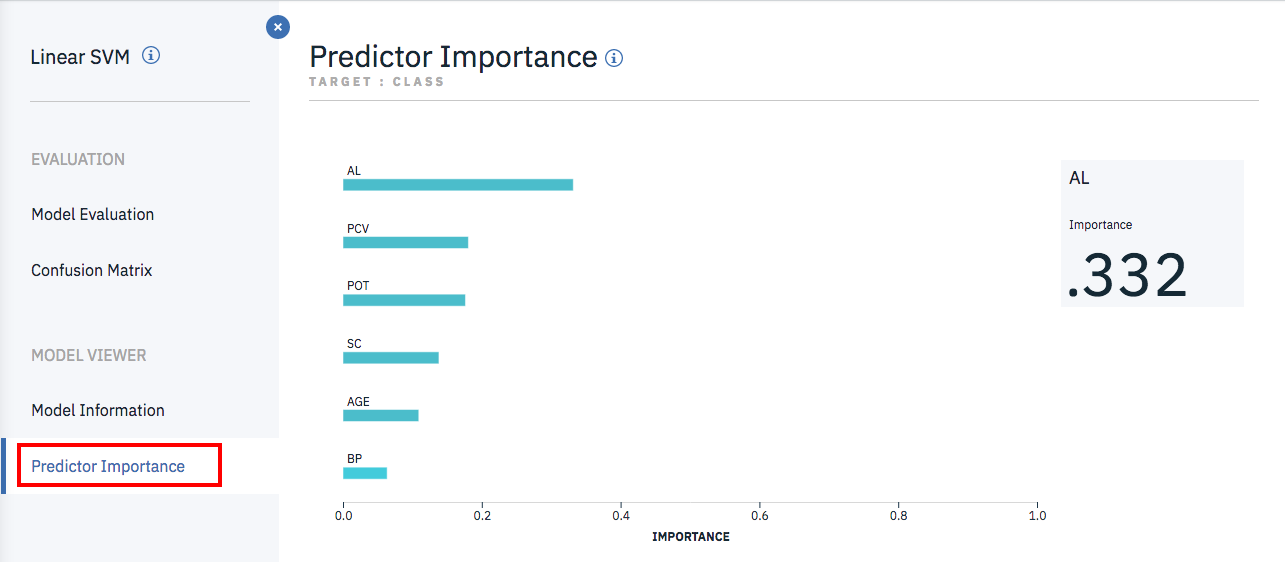
Predictor Importance
このページは、6つの入力データが、それぞれ結果の判断にどの程度寄与しているかの寄与率が表示されます。
モデルの評価
モデルの評価を行うため、Outputsグループから「Analysis」ノードをドラッグアンドドロップして、生成された黄色のモデルアイコンと接続します。
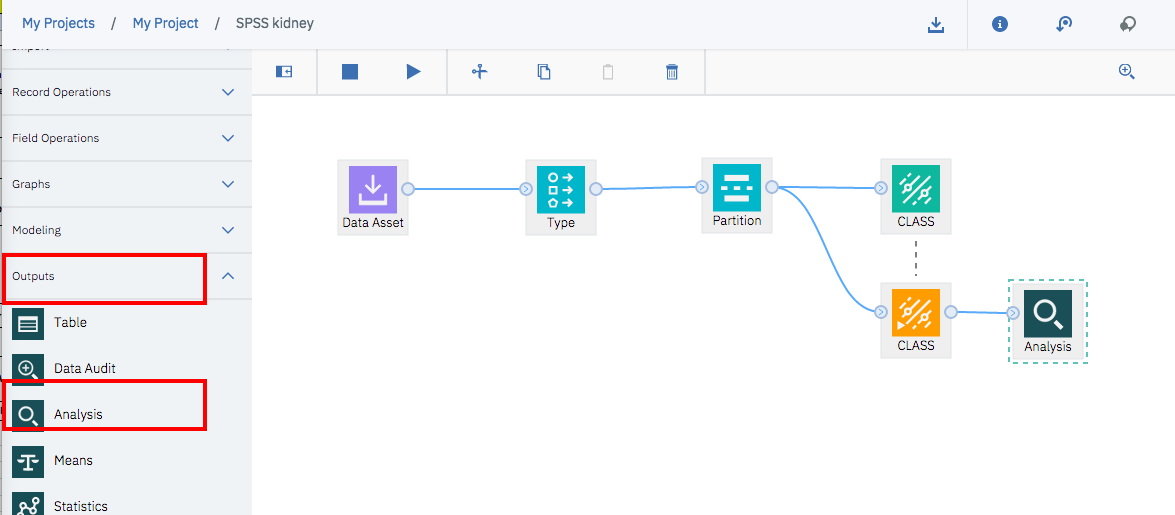
実行アイコンを再度クリックすると、下のような画面が右側に出るので、「Analysis」のアイコンをダブルクリックして結果を確認します。
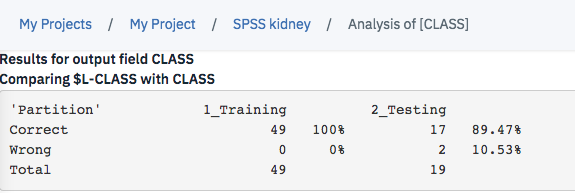
次のような、検証データに対する精度が表示されます。
今回は約90%程度の精度が出たようです。
モデルの保存
精度のいい機械学習モデルができたので、再利用するためにこのモデルをWatson MLのリポジトリに保存します。
「Analysis」アイコンでマウス右ボタンクリックをして、「Save branch as a model」をメニューから選択します。
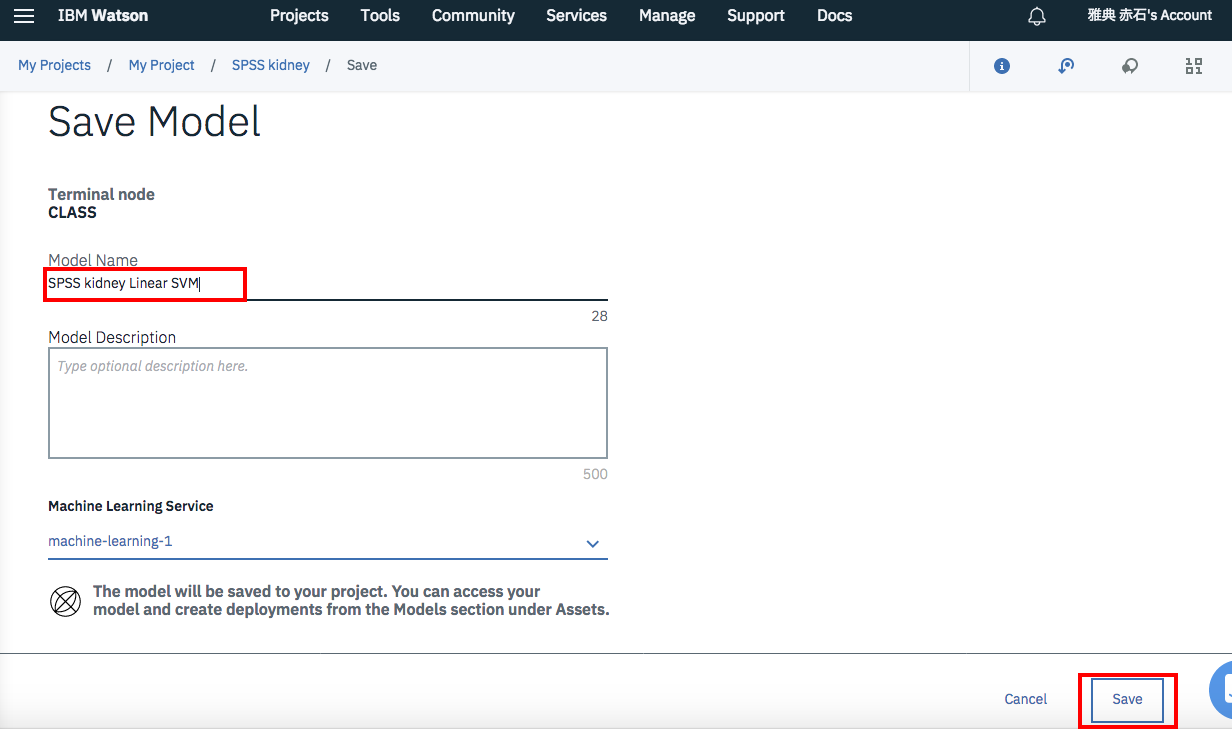
下のようなパネルが表示されるので、「SPSS kidney Linear SVM」など適当な名前を設定し、「Save」ボタンをクリックします。
下のような画面が出れば、モデルの保存に成功しています。
モデルの確認とWebサービスのデプロイ
モデルの保存に成功している場合、プロジェクト管理画面の「Watson Machine Learing」の欄に、先ほど登録した「SPSS Kidney Linear SVM」が追加されているはずです。赤枠で囲まれた部分をクリックして、モデルの詳細画面を表示します。
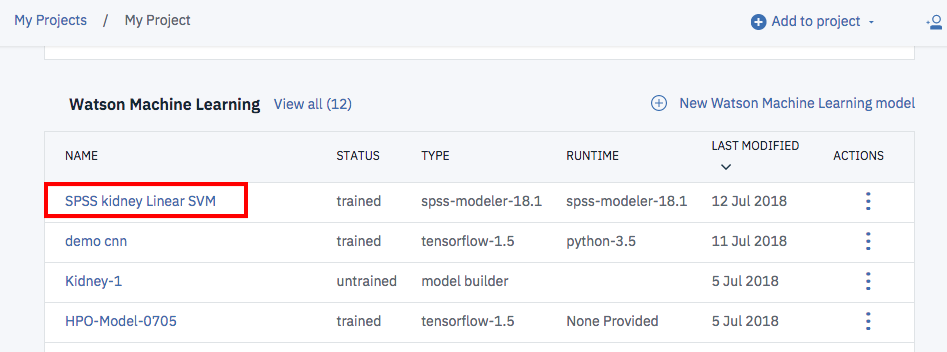
下のような形でモデルの詳細情報が表示されます。
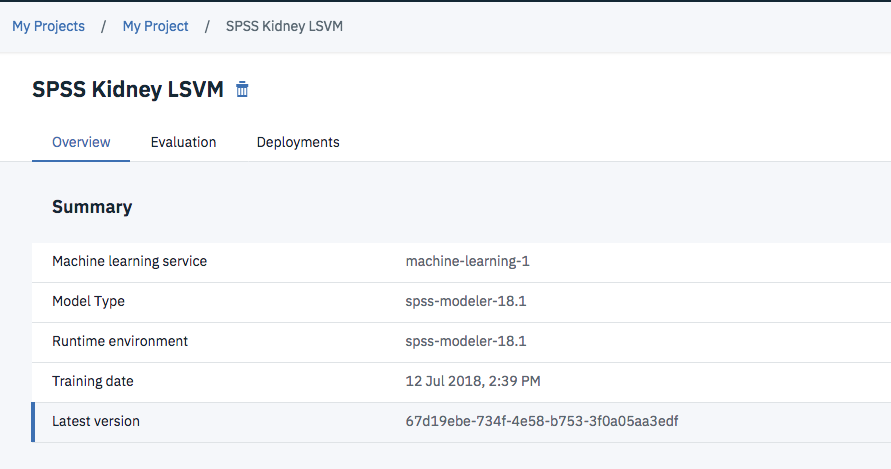
下にスクロールすると、パラメータの一覧が型付きで表示されます。
画面を上部に戻し、一番右の「Deplotments」タブをクリックします。
Deploymentsタブでは、画面右の「Add Deployment」をクリックします。
図のようなパネルが表示されるので、「SPSS Kidney Linear SVM web」などと適当に名前を設定して「Save」をクリックします。
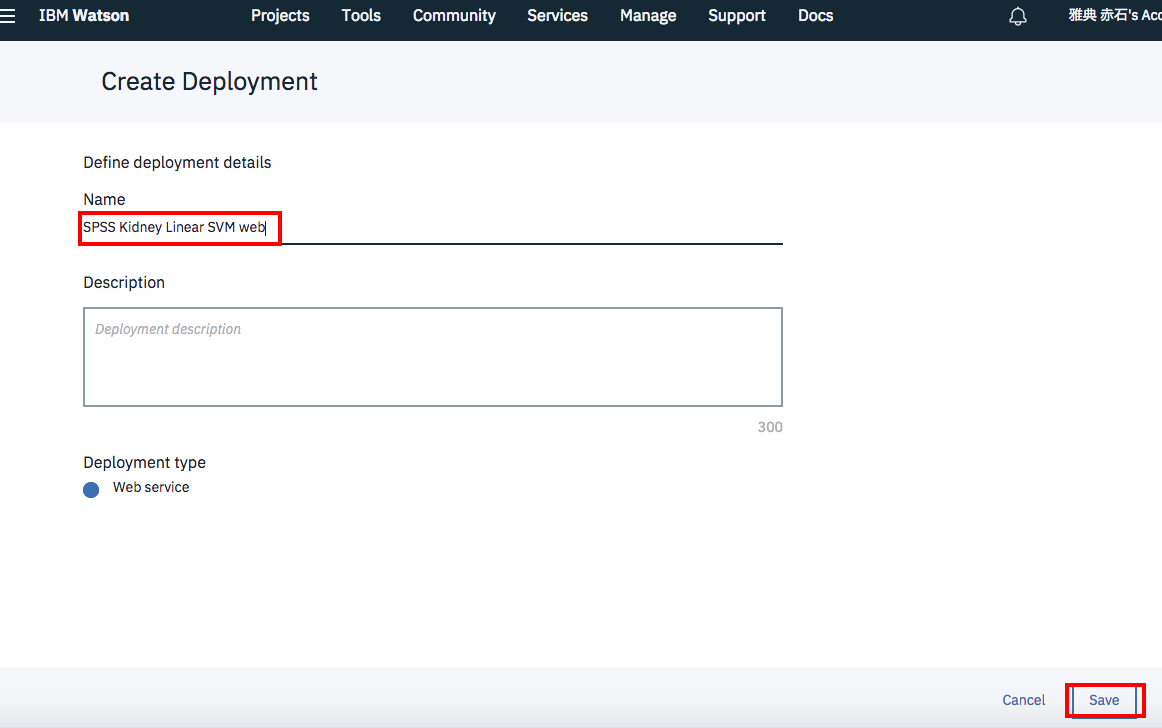
下の画面に遷移します。ステータスがいろいろと変わっていきますが、最後は「DEPLOY_SUCCESS」となります。
この状態で、赤枠で囲まれたリンクをクリックすると、Webサービスの管理画面に遷移します。
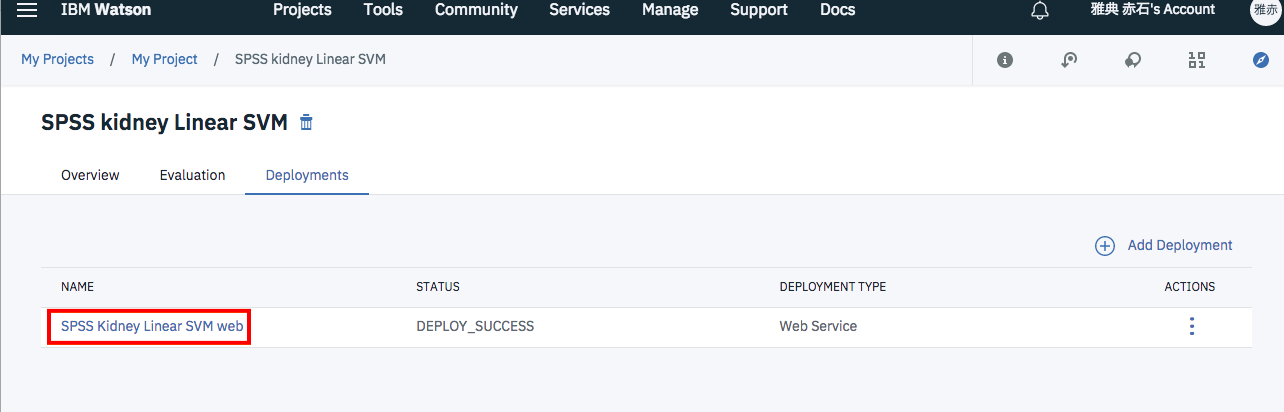
Webサービスのテスト
Webサービスの管理画面で、一番右の「Test」タブをクリックすると、テスト用の画面が表示されます。
学習に使っていない、下記のデータでテストを行ってみます。(正解クラスはckd)
| 項目名 | 値 |
|---|---|
| CLASS | (ブランク)出力データなので指定不要 |
| AGE | 21 |
| BP | 90 |
| AL | 4 |
| SC | 1.7 |
| POT | 3.5 |
| PCV | 23 |
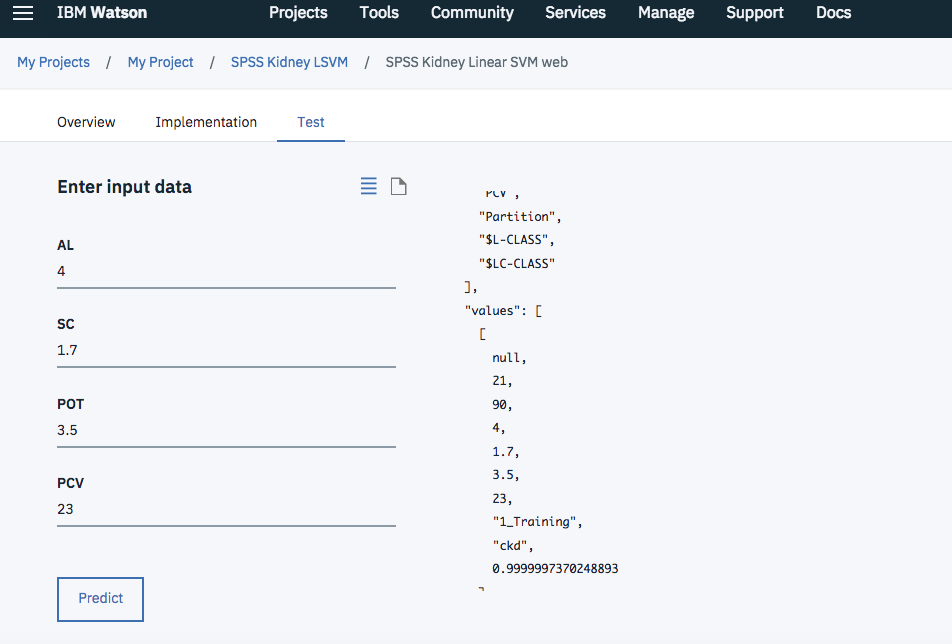
全部入力が終わったら「Predict」をクリックします。
結果のデータのうち、$L-CLASSが予測クラスを、$LC-CLASSが確信度を示します。
下の図ではそれぞれ 'chd'、'0.9999997370248893'となっていますので、かなりの確信度で正解していることがわかります。
アプリケーションへのデプロイ
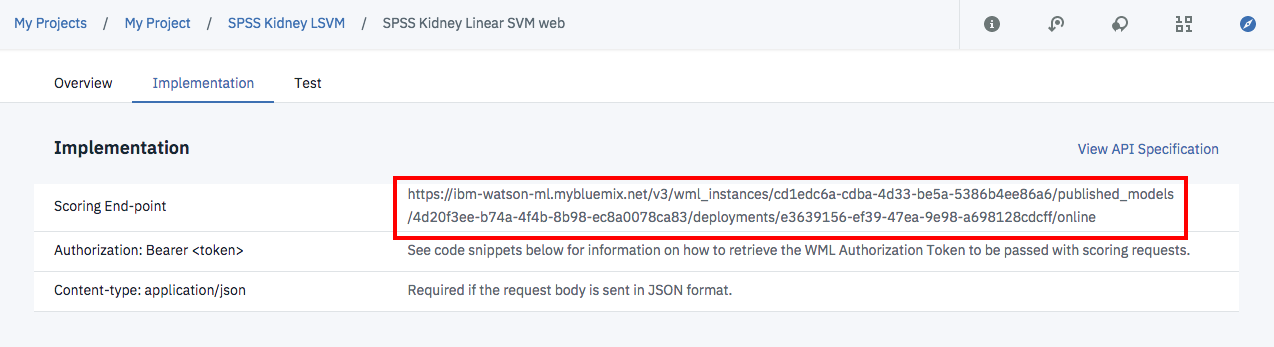
作ったWebサービスをアプリケーションから呼び出すときは、WebサービスのエンドポイントURLが必要となります。
このURLはWebサービス管理画面「Implementation」タブの赤枠の部分に表示されています。このURLをテキストエディタなどのコピペして保存して下さい。
サンプルアプリケーションはGithub URLからダウンロード可能です。
この後の手順は Github上のReadme.mdに記載されていますが、概要は以下のとおりです。
- ソースのダウンロード
- Watson MLのサービス名確認 (ml_nameとします)
- 以下のcfコマンド実行
$ cf login
$ cf push <service_name>
$ cf bs <service_name> <ml_name>
$ cf se <service_name> SCORING_URL <endpoint_url>
$ cf rg <service_name>
モデルのPythonからの呼出し手順
上記の方法でWatson Machine Learingに登録したモデルは、Pythonから呼び出すことが可能です。その手順を以下に記載します。
scoring_urlの取得
ます、次のコマンドで deploymentsの一覧を表示します。
from watson_machine_learning_client import WatsonMachineLearningAPIClient
wml_credentials = {
"apikey": "xxx",
"iam_apikey_description": "xxx",
"iam_apikey_name": "xxx",
"iam_role_crn": "xxx",
"iam_serviceid_crn": "xxx",
"instance_id": "xxx",
"password": "xxx",
"url": "https://us-south.ml.cloud.ibm.com",
"username": "xxx"
}
client = WatsonMachineLearningAPIClient(wml_credentials)
client.deployments.list()
次のような結果がかえってくるはずです。
------------------------------------ --------------------------------------- ------------------------ -----------------
------------------------------------ --------------------------------------------------------------------- ------ -------------- ------------------------ ----------------- -------------
GUID NAME TYPE STATE CREATED FRAMEWORK ARTIFACT TYPE
8a45a9b4-f7eb-4b07-8cc6-c4eb2e7ae4a6 kidney-spss-web online DEPLOY_SUCCESS 2018-10-26T01:54:15.555Z spss-modeler-18.1 model
3c80f474-6011-442e-8e11-876e48bc0063 CARS4U - Satisfaction Prediction Model Deployment online DEPLOY_SUCCESS 2018-10-25T03:52:23.370Z tensorflow-1.5 model
687ad643-a9f9-4d74-9318-ba7de4c7de03 best-drug model deployment online DEPLOY_SUCCESS 2018-10-19T08:26:45.774Z mllib-2.3 model
bf7e898f-3ed2-40ba-b001-25a30cf7ae53 CARS4U - Satisfaction Prediction - AI Function Deployment online DEPLOY_SUCCESS 2018-10-19T04:42:38.500Z n/a function
063d9ff9-264f-4481-aea8-4027457af7cc CARS4U - Satisfaction Prediction Model Deployment online DEPLOY_SUCCESS 2018-10-19T04:39:39.439Z tensorflow-1.5 model
f9ec45c7-b7ae-4a3a-b6a9-7416ae37dc69 CARS4U - Satisfaction Prediction - AI Function Deployment online DEPLOY_SUCCESS 2018-10-15T08:34:17.399Z n/a function
2a0bd461-c882-482e-95c1-22b60df3e36f CARS4U - Satisfaction Prediction Model Deployment online DEPLOY_SUCCESS 2018-10-15T08:31:35.817Z tensorflow-1.5 model
346915ed-8490-4830-9f6d-b590900d6115 CARS4U - Business area and Action Prediction - AI Function Deployment online DEPLOY_SUCCESS 2018-10-15T08:18:38.625Z n/a function
e35b4759-cd29-4568-8866-c31878de5e50 CARS4U - Business Area Prediction Model Deployment online DEPLOY_SUCCESS 2018-10-15T08:13:18.405Z mllib-2.1 model
e11236ba-ce9b-408f-8688-29d8f97439ec CARS4U - Action Model Deployment online DEPLOY_SUCCESS 2018-10-15T08:00:26.381Z mllib-2.1 model
------------------------------------ --------------------------------------------------------------------- ------ -------------- ------------------------ ----------------- ------------------------------------------------- --------------------------------------- ------------------------ -----------------
該当するdeploymentsのguidを確認後、以下の手順でscoring_urlを入手します。
deployment_uid = '8a45a9b4-f7eb-4b07-8cc6-c4eb2e7ae4a6'
deployment_details = client.deployments.get_details(deployment_uid)
scoring_url = deployment_details['entity']['scoring_url']
print(scoring_url)
パラメータ設定と呼出し
パラメータの設定とWebサービス呼出しは次の形で行います。
params = {
"fields": ["CLASS", "AGE", "BP", "AL", "SC", "POT", "PCV"],
"values": [[None, 75, 70, 0, 0.8, 3.5, 46]]}
scores = client.deployments.score(scoring_url, params)
print(scores)
呼出しが正常に終わり、こんな形で結果が返ってくれば成功です。
{'fields': ['CLASS', 'AGE', 'BP', 'AL', 'SC', 'POT', 'PCV', 'Partition', '$L-CLASS', '$LP-CLASS'], 'values': [[None, 75, 70, 0, 0.8, 3.5, 46, '1_Training', 'ckd', 0.998594297142512]]}