はじめに
無料でなんでも試せる! Watson Studioセットアップガイド
で関連記事をまとめたとき、Konwledge Catalogに関する記事がないことに気付き、簡単なガイドを作ることにしました。
Knowledge Catalogとは
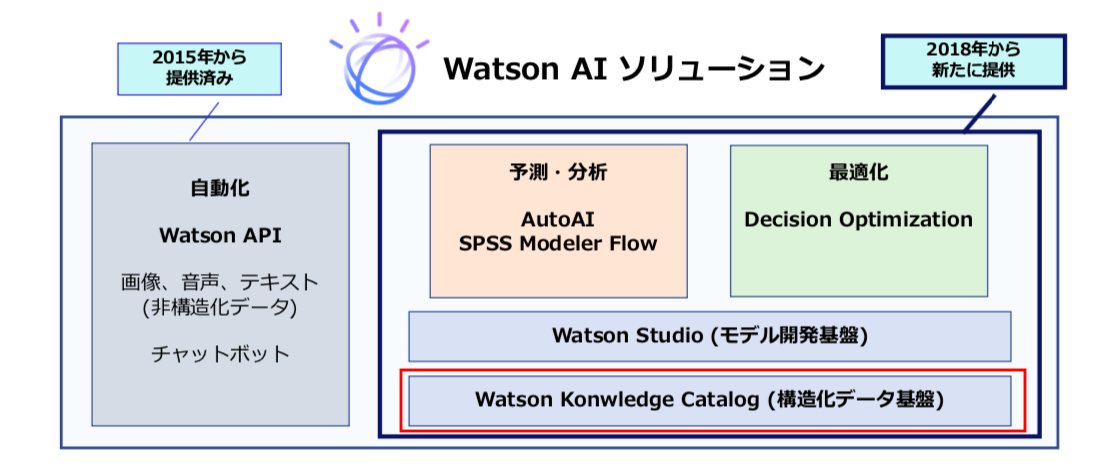
そもそも、Knowledge Catalogとはなんぞやという話ですが、上の図を見て下さい。
これは、現在のAI系Watsonサービスの全体図です。構造化データを使った予測モデル開発の統合プラットフォームがWatson Studioなのですが、構造化データの場合、データベースへのアクセスということが必須になります。
データ接続、データの探索、データ加工などの部分を引き受けるサービスが、Knowledge Catalogということになります。
前提
上のリンクでIBM Cloudのアカウント登録、Watson Studioのインスタンス作成、Watson Studioのプロジェクト作成まで済んでいること。
事前準備
それでは、これから実際に機能を試すのですが、参照先のデータベースが必要になります。
IBM Cloudでは、無料でDB2も使えるので、まず、そのサービスを作るところから始めます。
DB2サービスの作成
下のダッシュボードの初期画面で「リソースの作成」をクリックします。
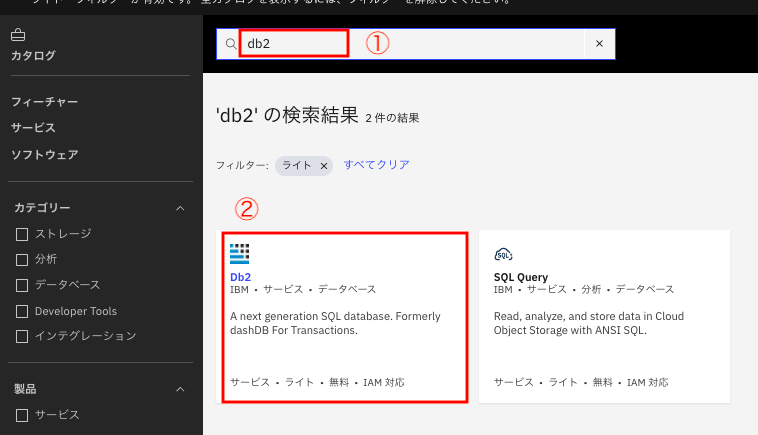
① 検索文字としてdb2を入力し、Enter
② 出てきたリストからDb2を選択します。
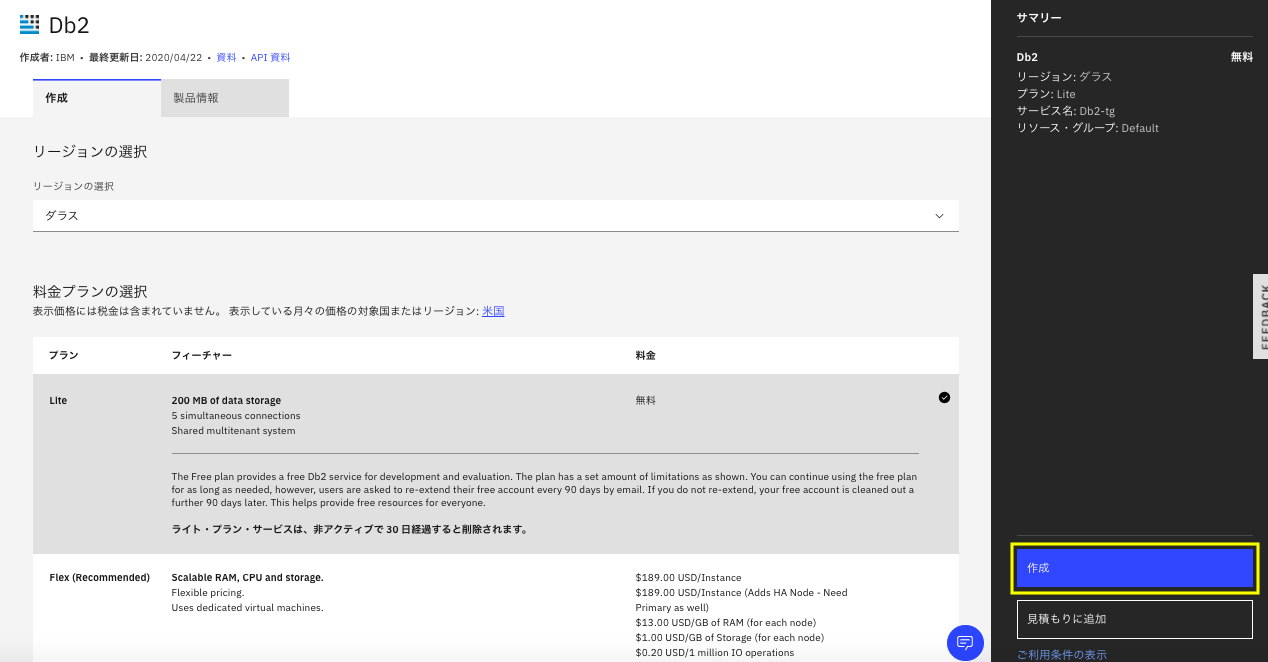
下の画面になったら全部デフォルトで、右下の「作成」をクリックします。
資格情報の作成・確認
下のような画面になったら、Db2のインスタンスができています。最初に資格情報を作成し、結果を確認します。
① サービス資格情報のメニューをクリック
② 「新規資格情報」をクリック
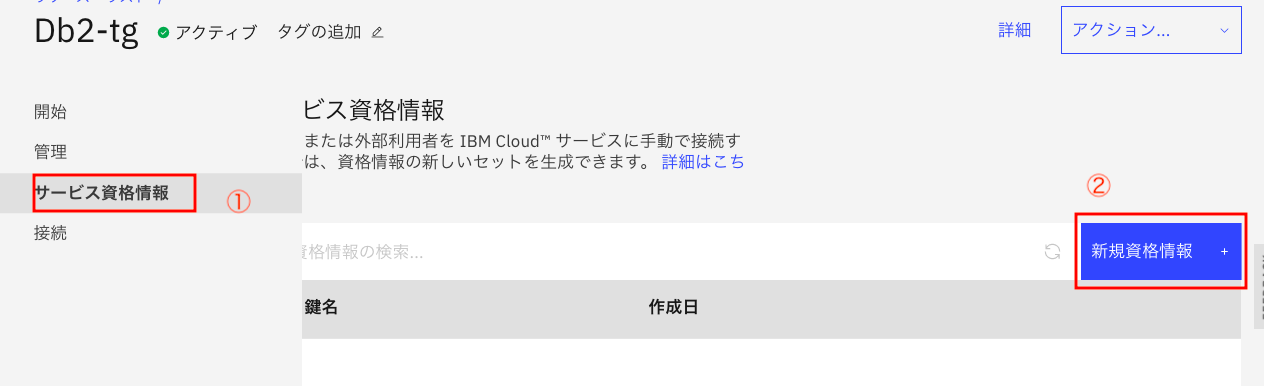
下のパネルが出てきたら、デフォルトの状態で、「追加」
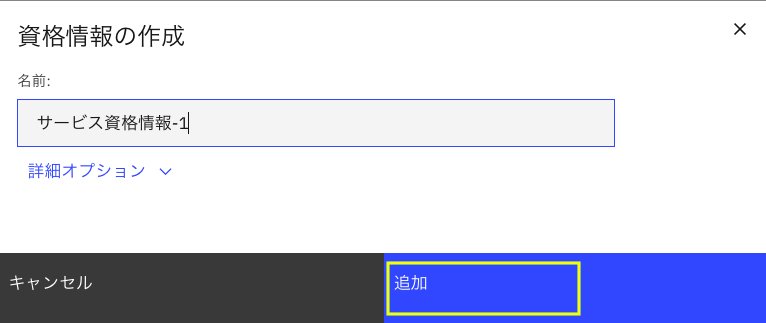
下のようになるので、画面右下の小さいアイコンをクリックします。
ちょっとわかりにくいのですが、これは資格情報をクリップボードにコピーする機能です。
コピーした資格情報は、テキストエディタなどにはりつけて保存しておきます。
サンプルテーブルの作成
次にサンプルテーブルを作成します。DB2の管理コンソールでは、CSVデータからテーブルを生成する機能があるので、その機能を使うことにします。
サンプルで使うデータはなんでもいいのですが、他の記事で使っているAutoAI用の学習データにしましょう。
下記のURLからダウンロードできるので、ブラウザでアクセスして、ファイルとして保存しておいて下さい。
下のDB2の画面で、今度は
① 管理のメニューをクリック
② Open Consleをクリック
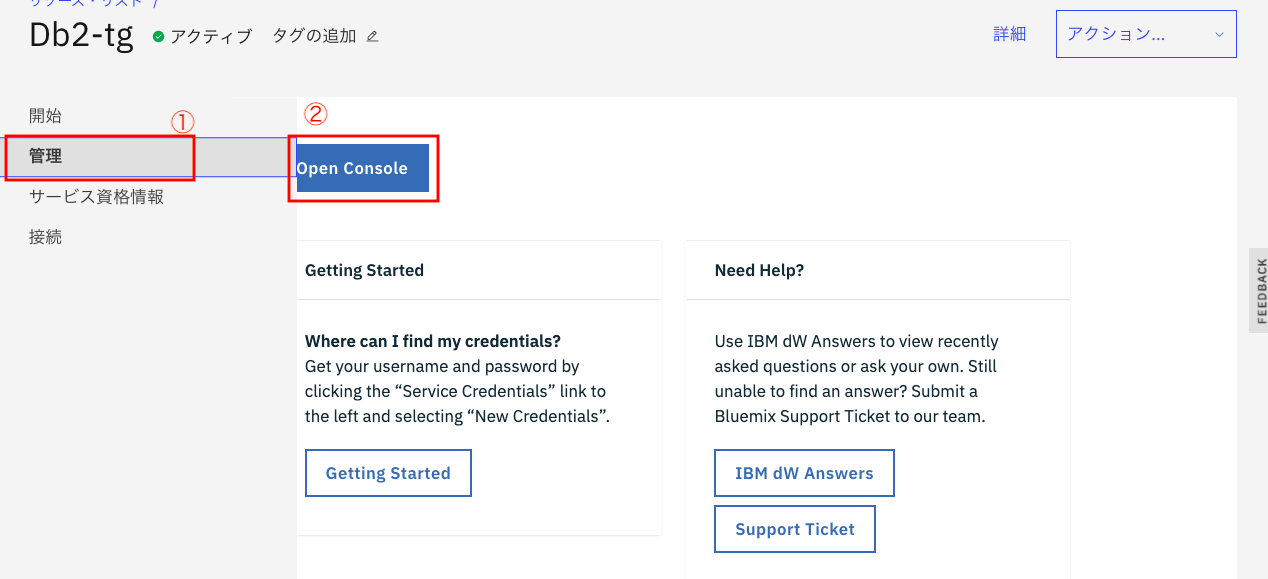
下のような画面になるので、画面右上の「三」のアイコンをクリックします。
出てきたメニューから「Load」「Load Data」を順に選択します。
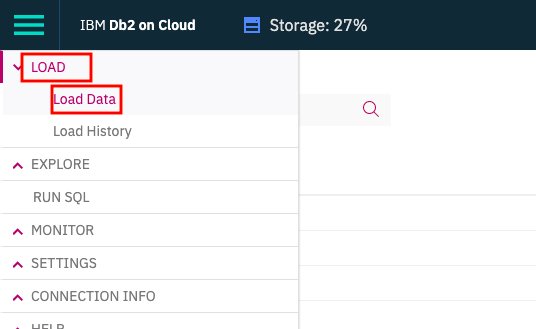
下の画面で
① 事前準備したcsvファイルをドラッグアンドドロップ
② ファイル名が「Selected file」に入ったのを確認し
③ Nextをクリック
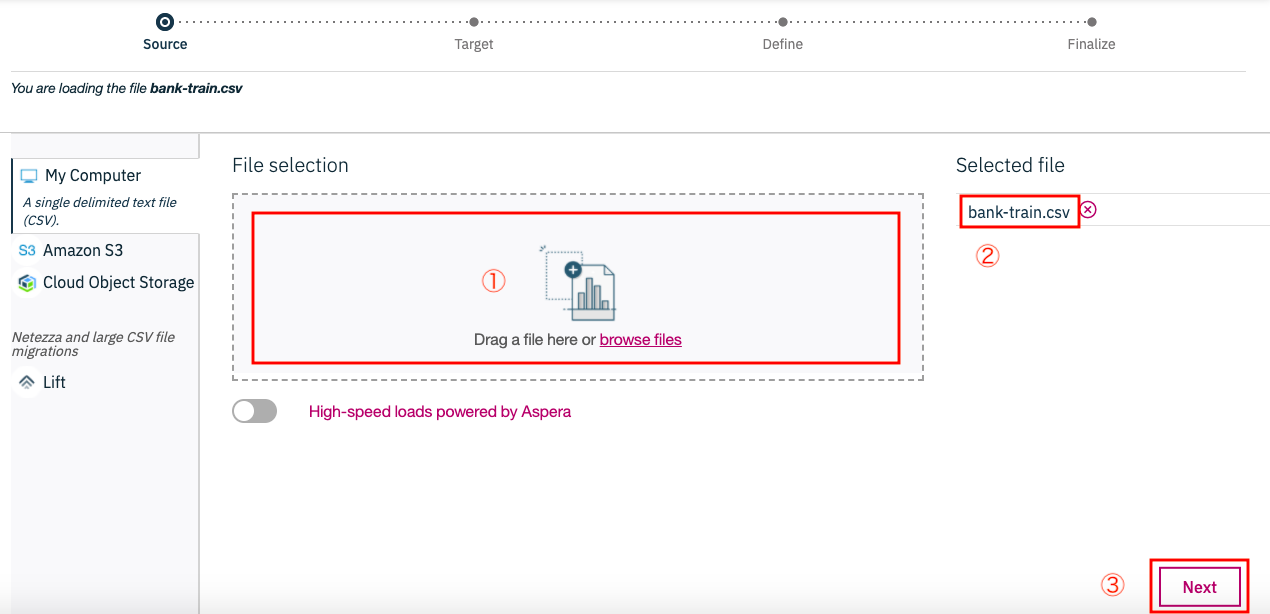
① スキーマ名選択の画面では、先ほど取得した資格情報内のusernameと同じものがあるはずなので、それを選択します。
② テーブル名に関してはNew Tableをクリック
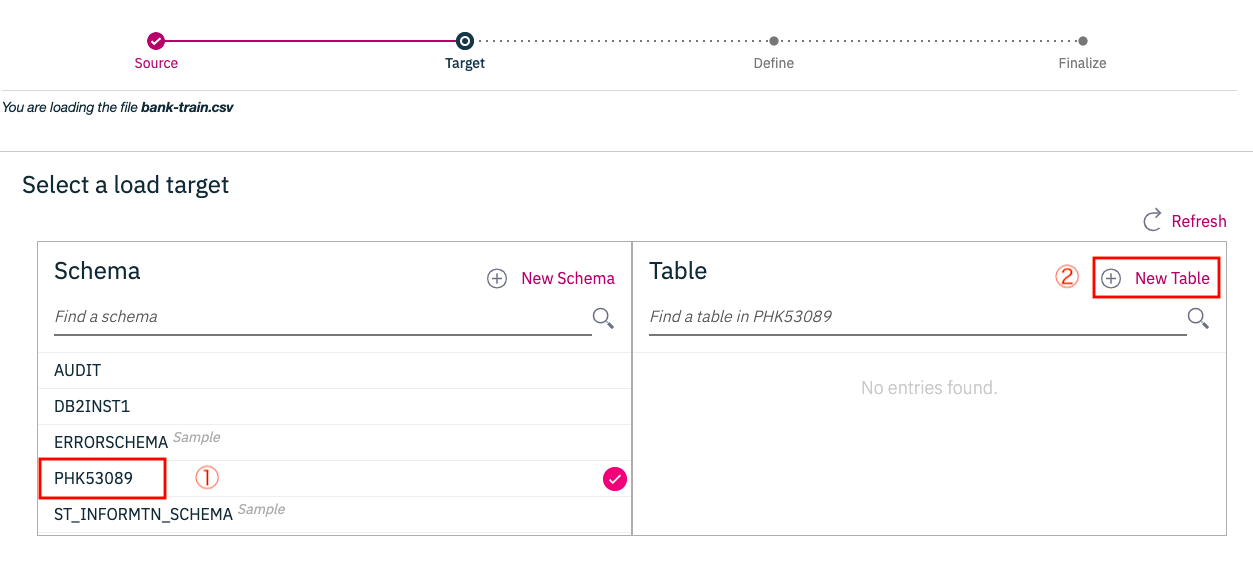
下のような画面に変わるので、
① テーブル名称をBANK_TRAINとし
② Createボタンをクリックします。
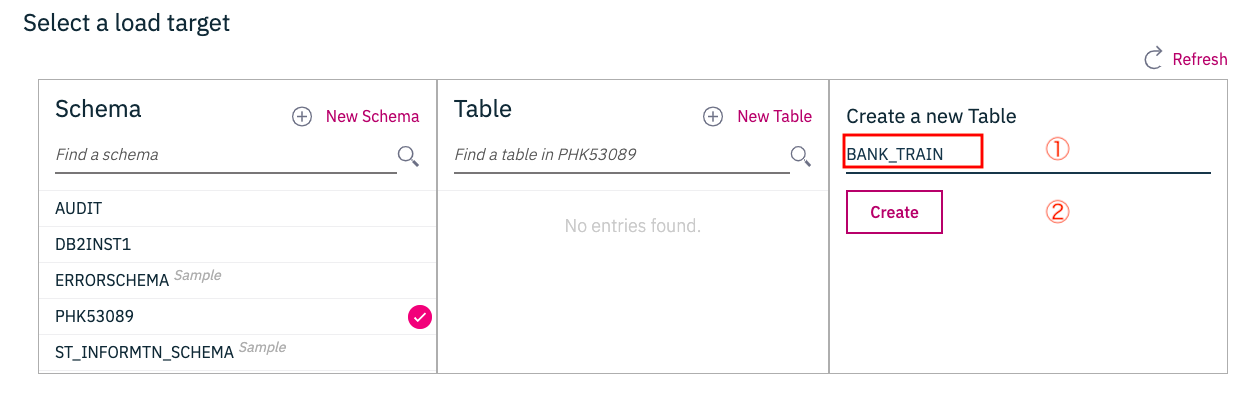
下の画面で、もう一度「Next」
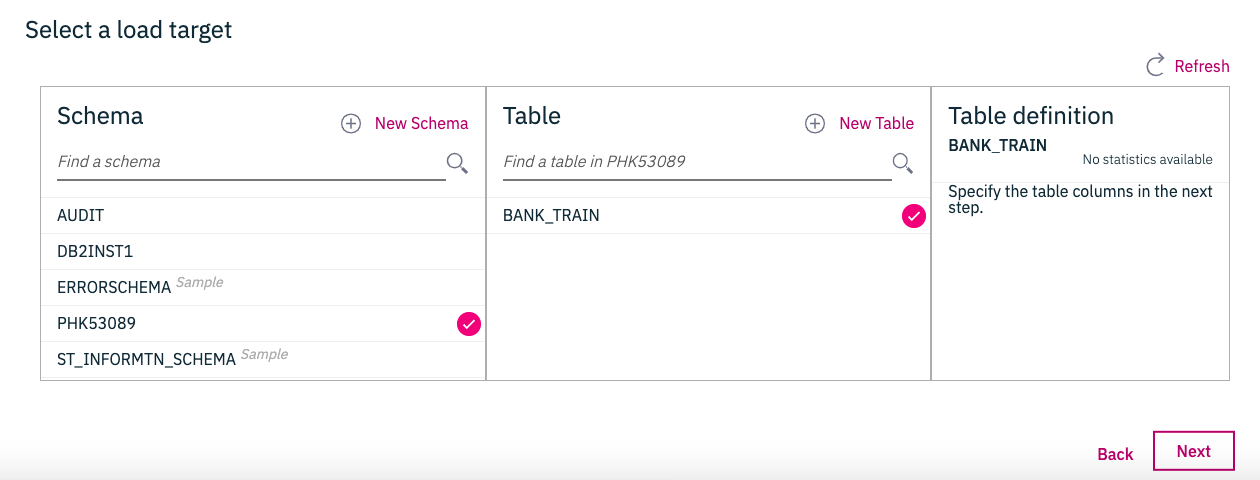
今度はこんな画面になります。ここでもう一回Next
最後にこんな確認画面が出るので、「Begin Load」をクリックします。
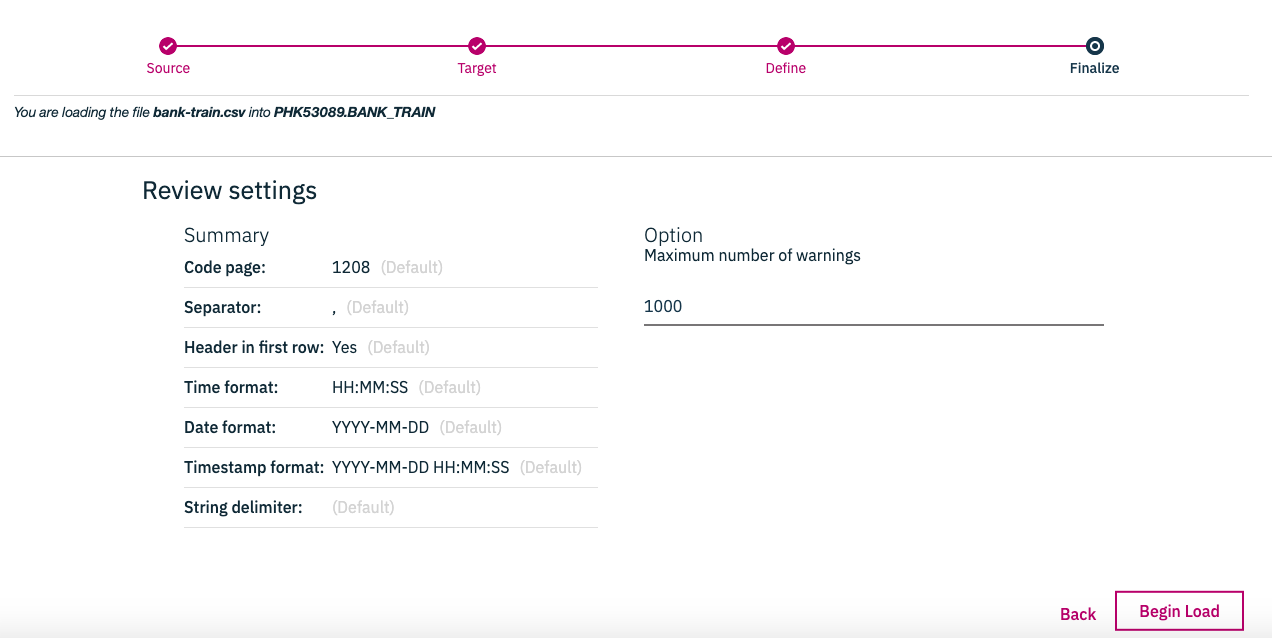
これで、データロードがはじまるはずです。下の画面がでてくれば完成です。
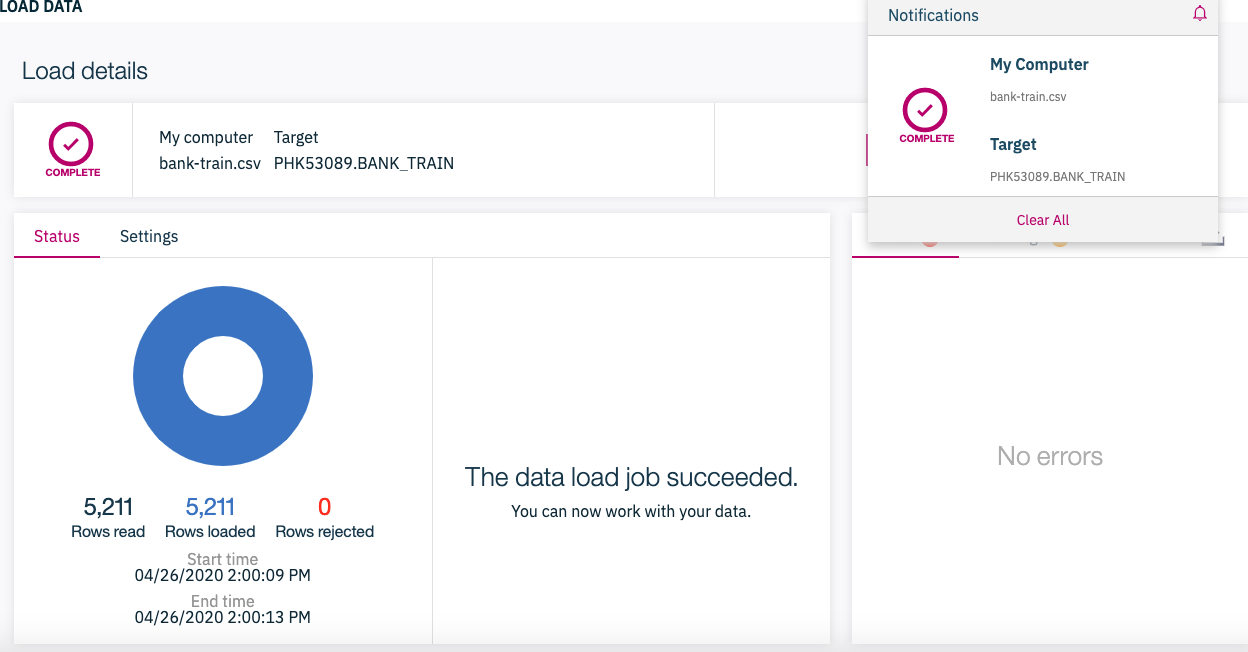
余談ですが、私が基盤系をやっていた20年前だったら、自分でデータ型とか長さとか調べてDDLを手で作っていました。データベースの世界も随分楽になったものです。
手順
かなり長い手順になりましたが、以上でデータベース側の準備が完了しました。
いよいよ本題のWatson Studio(正確にはKnowledge Catalog)側の作業に入ります。
接続情報の登録
Watson Studioのプロジェクト管理の画面から
① 「プロジェクトに追加」
② 「Conenction」
を選択します。
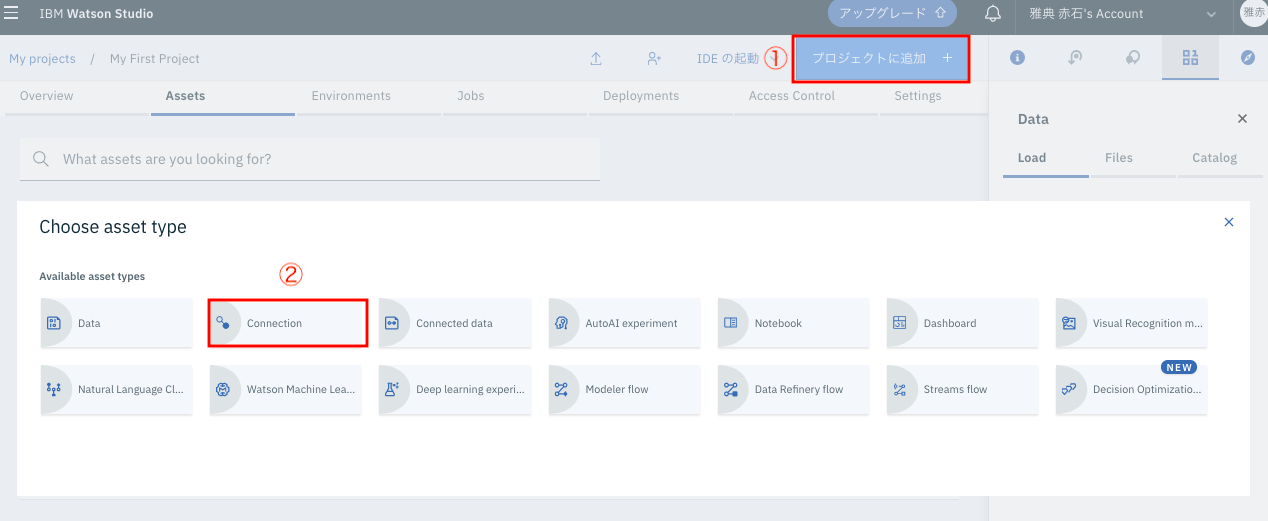
ここで出てきた一覧が、Knowledge Catalogで対応しているデータベースです。随分たくさんのデータベースに対応していることがわかります(グレーアウトで選択できないものは「有償プランのみ対応」を意味しています)。
この中で、Db2を選択します。
すると、下の図のような接続情報設定画面が表示されます。
左上の名称は「db2 connection」など適当な名前を入力します。残りは、先ほどテキストエディタに保存した資格情報から必要な項目をコピーして下さい。
Databaseの欄は共通でBLUDBです。ポートが50000でSSLはなしです。残りの対応付けは想像つくと思います。
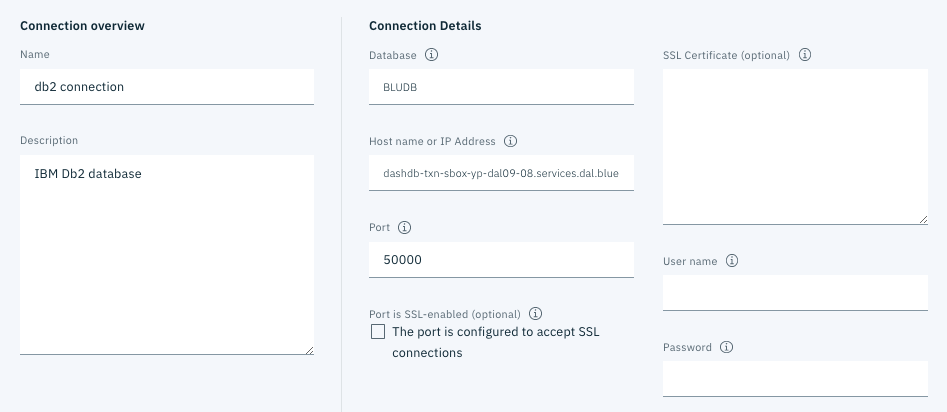
usernameとpasswordまで入力すると、今まで選べなかった画面右下のCreateボタンが選べるようになるので、それをクリックします。この段階で、接続テストをしているので、パスワードが違っている場合は、ここで登録エラーになります。下の図のように正常終了した場合は、接続に成功したことを意味しています。
テーブルの登録
引き続き、テーブルの登録をしてみましょう。
「プロジェクトに追加」から今度は「conencted data」を選択します。
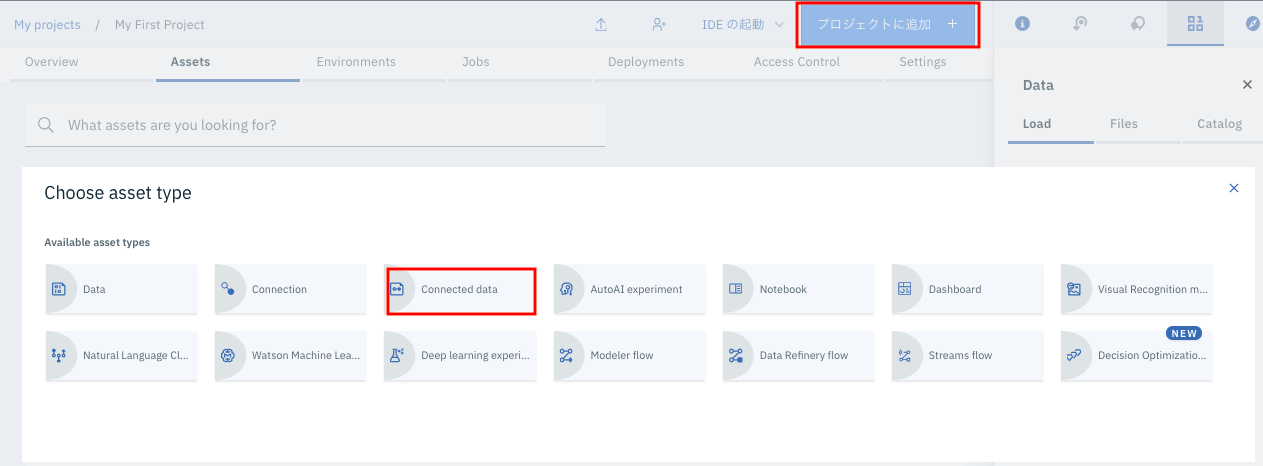
下のように「Select connection source」という画面が出てきます。
順に以下の操作をして下さい。
① Connections 先ほど作ったibm db2を選びます。
② Schemas テーブルを作る際に指定した、db2接続ユーザーと同じものを選びます
③ Tables BANK_TRAIN (事前準備で用意したテーブル)
④ ③までを選択すると、画面右下のSelectボタンが有効になるので、クリックします。
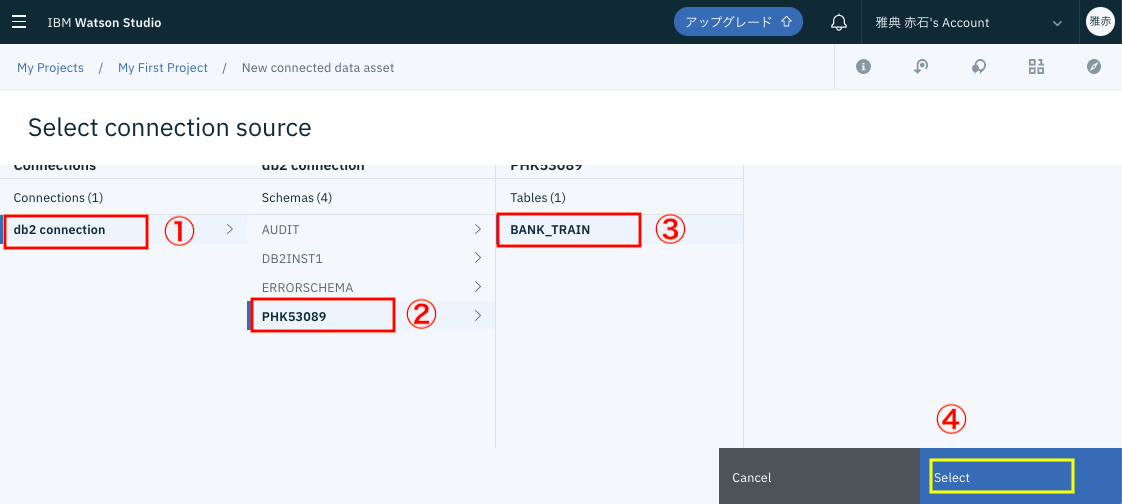
すると、下のような画面に遷移します。
① Sourceの設定が適切であることを確認します。
② Nameの欄に DB2_BANK_TRAINと名称を入力します。
③ Createボタンをクリックします。
すると、Data Assetsが次のように変わり、DB2のテーブルが登録されたことがわかります。
引き続き、登録済みのテーブルの利用例をいくつか紹介します。
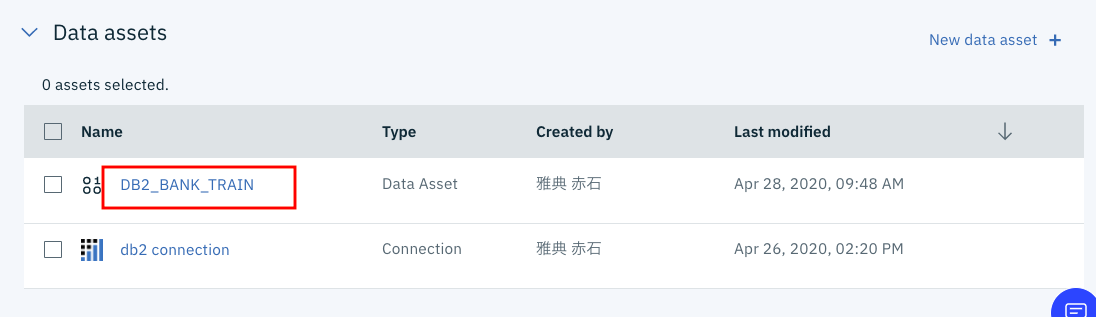
Refineryからのアクセス
最初はRefineryというDB簡易ツールからのアクセスです。
上の図の赤枠で囲まれたテーブルのリンクをクリックすると、即座にRefineryが起動されます。
下の図が、Refineryの初期画面です。先ほど登録されたテーブルの内容がプレビュー機能で表示されていることがわかります。
Refinaryの機能を紹介すると、長くなるので、図の赤枠のプロジェクト名の欄をクリックして、いったん画面を抜けることにします。
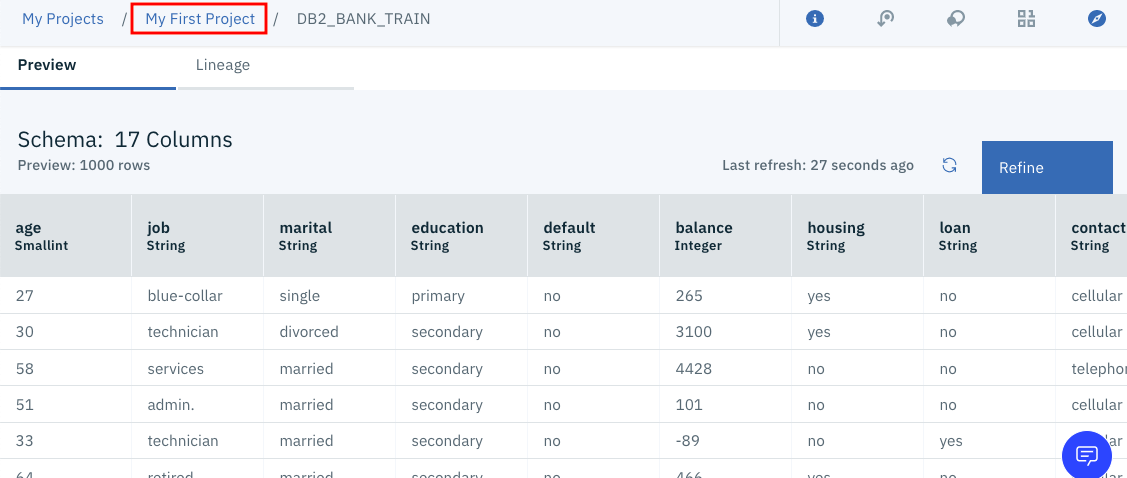
Modeler Flowからのアクセス
「プロジェクトに追加」から「Modeler Flow」を選択します。

Nameの欄に「DB access sample」と入力し、Create
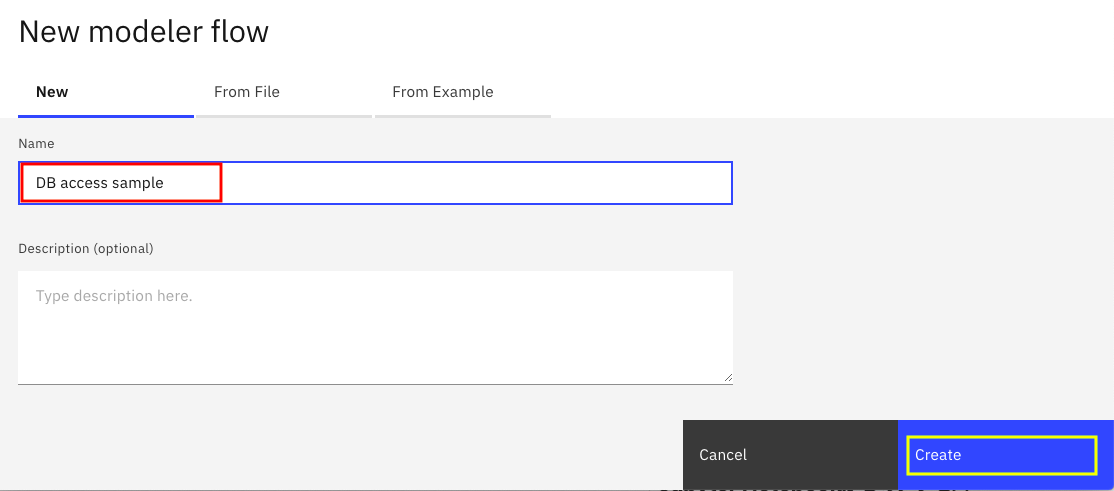
画面中央に編集用のキャンパスが表示されます。画面左のパレットから、「Import」「Data Asset」を選択肢、キャンパスに向けてドラッグアンドドロップします。
下の図のように、中央のキャンパスに、Data Assetのアイコンが配置されます。設定のため、このアイコンをダブルクリックします。
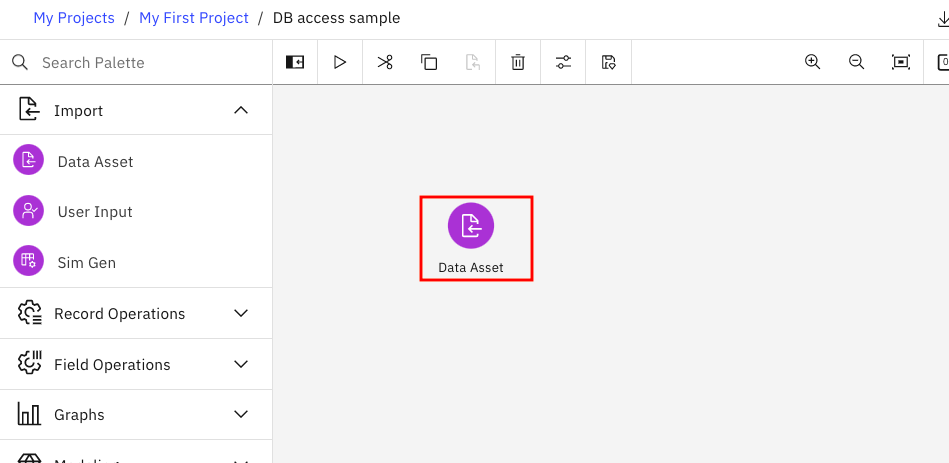
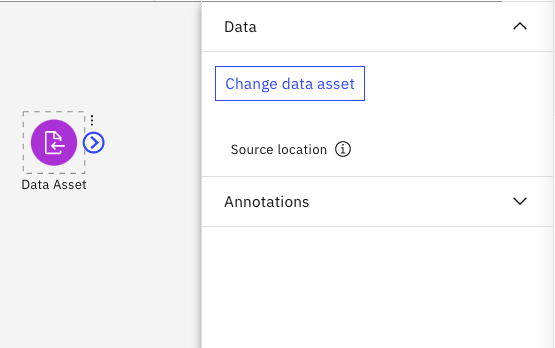
下のような設定画面になるので、「Change data asset」のボタンをクリックします。
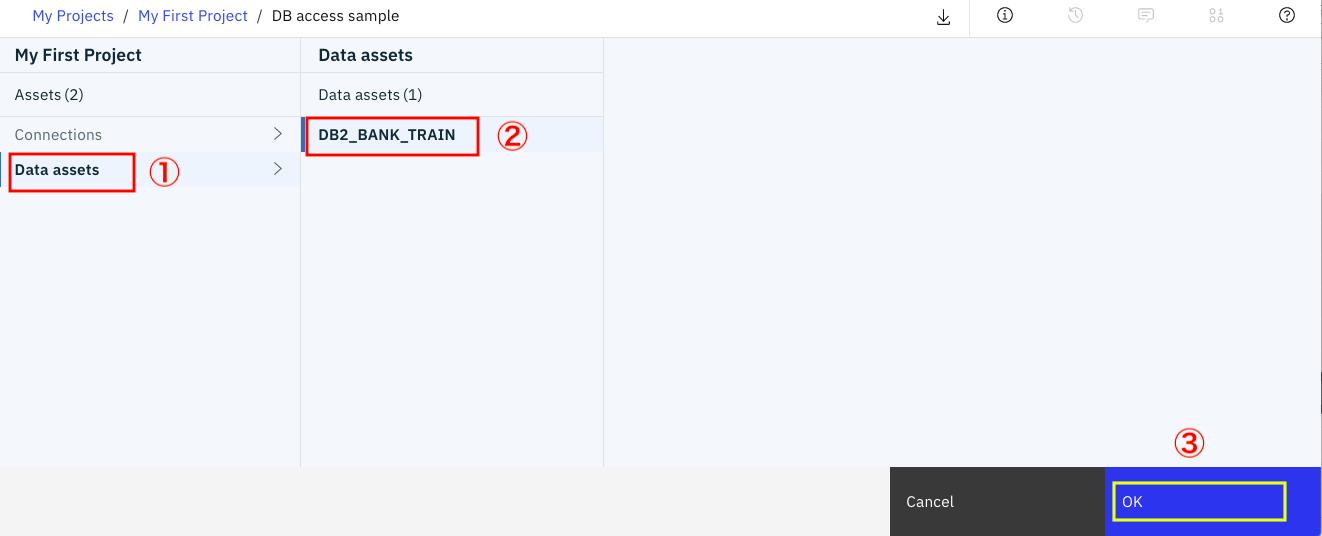
下の画面で、①「Data assets」②「DB2_Bank_TRAIN」を順に選択し、最後に画面右下の③「OK」ボタンをクリックします。
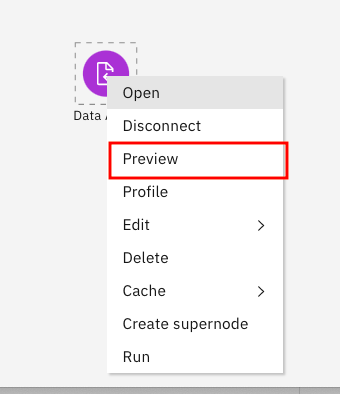
これで、Modeler Flow上のアイコンと、Data Assetの対応付けが完了しました。試しにプレビュー機能でそのことを確認してみます。キャンパス上のアイコンで、マウス右ボタンクリックし、コンテキストメニューを表示します。
メニューから「Preview」を選択して下さい。
下のような結果が表示され、準備したDBデータがModeler Flowからアクセスできていることがわかります。
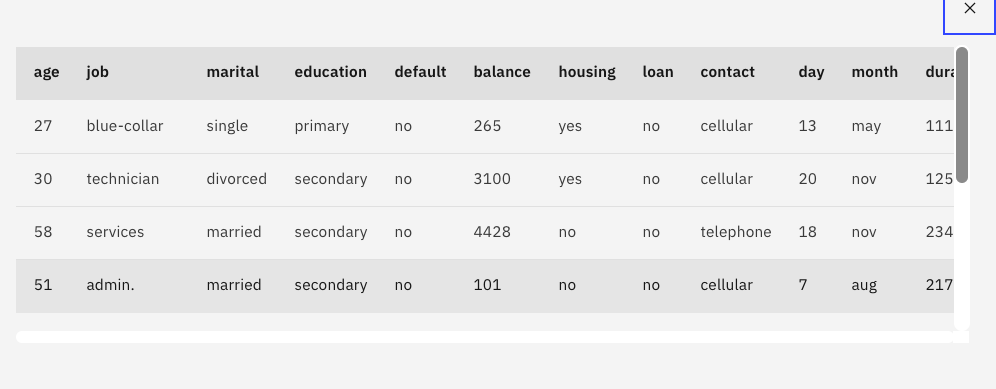
閉じるボタンをクリックして、最後に下の画面のプロジェクト名の領域をクリックしてプロジェクト管理の画面に戻ります。
Jupyter Notebookからのアクセス
今度は、Data Assetに登録したテーブルをJupyter Notebookから利用してみます。
まず、「プロジェクトに追加」から、「Notebook」を選択します。

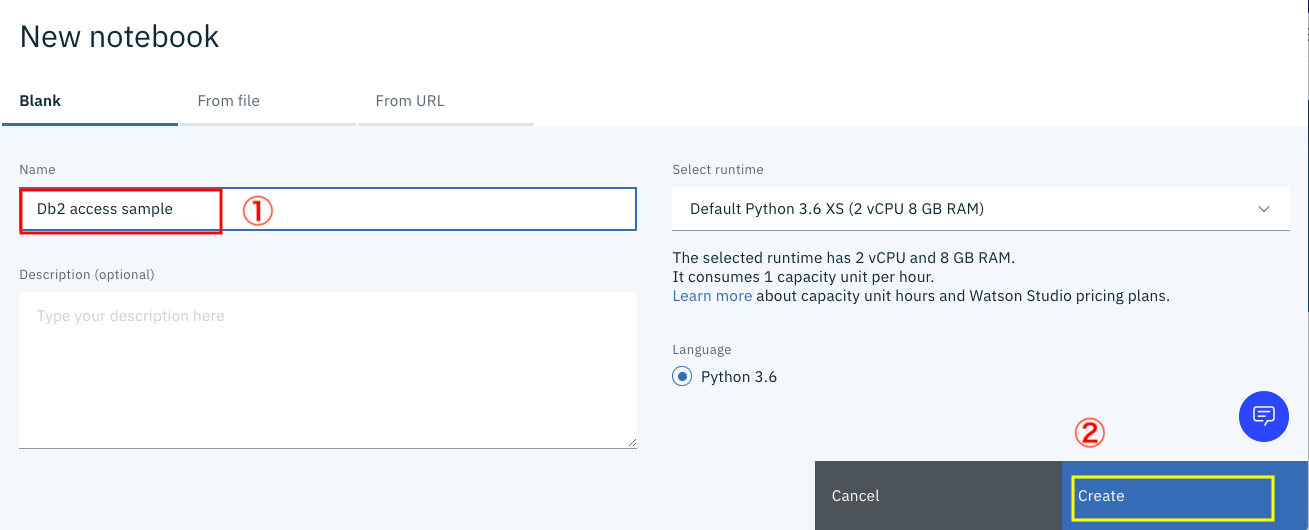
下の画面で
①Nameの欄に「Db2 access sample」と入力し
② 画面右下の「Create」ボタンをクリックします。
下の画面が出てきたら、右上の「閉じる」アイコンで、画面を消します。
画面上部の右から2つめ、「Find and add data」アイコンをクリックします。
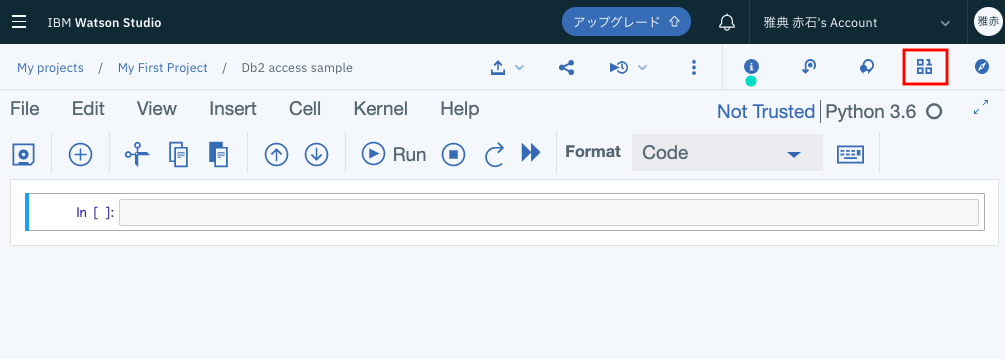
先ほど、「Connected data」として登録したDB2_BANK_TRAINが出てくるはずです。ここのドロップダウンリストをクリックします。
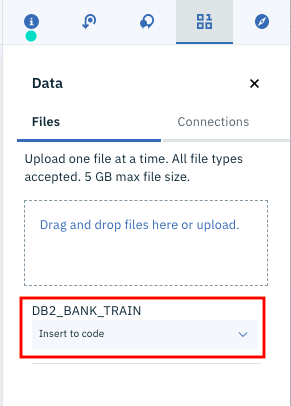
リストの中から「pandas DataFrame」を選択します。
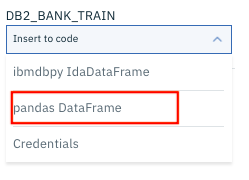
Db2のデータにアクセスするためのコードが自動生成されて、Notebookが下の図のようになるはすです。
ここでShift+Enterで、このセルを実行してみます。
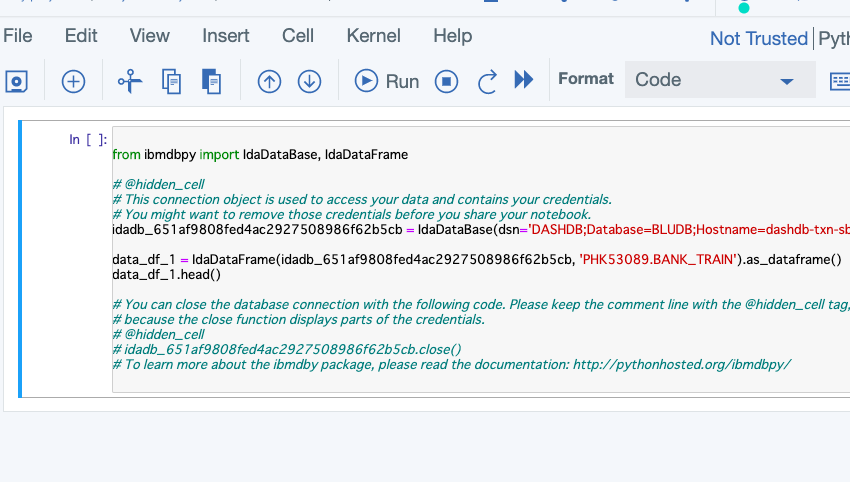
すると、Db2のデータがPythonのDataFrameに読み込まれていることがわかります。
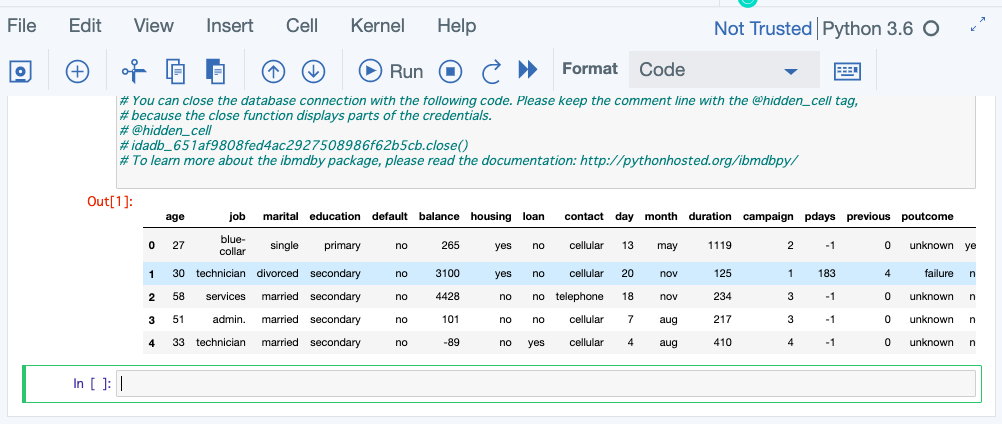
このように、一度、Connectionや、Connected dataを登録しておくと、ユーザーは接続情報など気にすることなく、データベースのデータを利用することができます。これがWatson Studioと連携したKonwledge Catalogの機能の一部ということになります(Konwledge Catalog自体は他にも機能がいくつもあります)。