はじめに
赤石です。
2021年5月21日に実施されたイベント IBM Cloud Festa Online2021 でWatson Studio上のサービスであるSPSS Modeler Flowを使って、タイタニック・データセットを対象に決定木のモデルを作る話をしました。
当記事は、そこで見せた内容を、自分の環境で再現するための手順となります。
SPSS Modeler Flowの特徴
最初に冒頭でご紹介したプレゼンのメッセージの抜粋をお伝えします。
決定木はPythonのOSSライブラリであるscikit-learnでも作ることができます。しかし、その場合と比較して、ここでご紹介するSPSS Modeler Flowは次の特徴があります。
- 完全にプログラミングレスにモデルを作れる
- 欠損値に対して特別な処理を行わず決定木モデルを作れる(精度は問わなければという前提は入ります)
- カテゴリ変数のダミー化の処理も不要
- データ項目名が日本語のままでツリーの判断ロジック表示ができる(scikit-learnでは視覚化ツールが日本語対応していないのでこれができない)
全体を通じて、プログラミングが苦手なユーザーに取ってとても便利な分析ツールであるということができます。
前提条件
Watson Studio
IBM Cloudでライト・アカウントのユーザー登録がされていて、かつWatson Studioのプロジェクトまでが作成済みであること。
手順については、下記のリンクを参照してください。
無料でなんでも試せる! Watson Studioセットアップガイド
CSVファイル
デモで利用するタイタニック・データセットのCSVは、次のリンク先から事前にダウンロードしてください。
タイタニック・データセット
実習手順
それでは、早速実習を始めてみます。まず、下のようなプロジェクト管理の初期画面が表示されていることを確認してください。

CSVファイルアップロード
赤枠で示した「Newデータ資産」のリンクをクリックし、画面の指示に従ってCSVファイルをアップロードします。正しくできると下の画面のようになるはずです。

これで最初のステップの「CSVファイルアップロード」は完了です。
新規フローの作成
次の上の画面で、右上の「プロジェクトに追加」をクリックします。
下の画面になったら、「 Modelerフロー」を選択します。

次の画面になったら、「名前」の欄に「決定木分析(タイタニック)」などと入力し、画面右下の「作成」ボタンをクリックします。

しばらく待って、次の画面がでてくれば、新規フローの作成に成功しています。

ノードの配置と結線
SPSS Modeler Flowは、有名なNode-REDと同じく、ビジュアルプログラミング環境です。「ノード」と呼ばれる部品を左側の「パレット」から中央の「キャンパス」にドラックアンドドロップして配置し、ノード間を結線することで、プログラムを組み立てていきます。
最初に今回のデモで使うノードをすべて配置することにします。
以下の部品を配置してみて下さい。
「インポート」「データ資産」
「出力」「データ検査」
「フィールド操作」「タイプ」
「フィールド操作」「パーティション」
「モデル作成」「C5.0」
それぞれの部品の配置は、その後の結線のことを考えて下の図のようにして下さい。

更にノード間の結線を行います。慣れないと一番最初が難しいかもしれませんが、マウスポインタを結線したいノードの右側に移動すると、下のような矢印アイコンが表示されます。

そこで、結線先に向かってドラックアンドドロップすると、うまく結線ができます。下のような接続ができれば結線作業は完了です。

結線が終わったら、個別のノードの属性を設定していきます。
データ資産ノードの設定
最初に設定するのは左上のデータ資産ノードです。このノードをダブルクリックして下さい。

すると、上の様な画面が出てくるので
①「Data Asset」をクリック
②2段階目の選択肢として「titanic_j.csv」が出てくるので、このファイルを選択
③最後に画面右下のOKを選択
とします。

上の画面になったら「保存」をクリックして下さい。
下の図のようにノード名称が「titanic_j.csv」に変わっていたら、設定に成功しています。
設定ができたら、プレビュー機能を使って、データの中身を確認してみます。
ノードでマウス右ボタンクリックで下のコンテキストメニューを表示し、「プレビュー」を選択します。
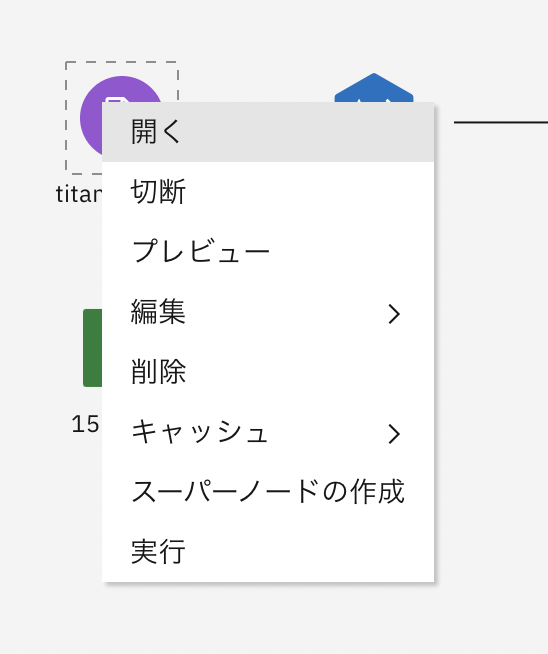
下のようなパネルが出てきたら、プレビューに成功しています。
ポップアップパネル右上の閉じるアイコンで、ポップアップを閉じて下さい。
検査ノードでの確認
次に検査ノードを使ってデータの状態を確認してみましょう。
最初に検査ノードの真上にマウスポインタを移動して、右ボタンでコンテキストメニューを表示します。今度は、一番下の「実行」を選択して下さい。
下のような画面になったら、「Data Audit」の右側の目のアイコンをクリックして下さい。

下のようなデータの散布図などの情報が表示されます。

画面をもっと下にスクロールすると、次の画面のように項目ごとの欠損値の状態などもわかるようになっています。

上の表から「年齢」には177個の欠損値が、「乗船港コード」には、2個の欠損値があることが読み取れます。Python & scikit-learnで決定木を作る場合、前処理としての「欠損値対応」が必要なケースですが、SPSS Modeler Flowの場合、このまま特別な対応をとらなくても決定木のモデル構築が可能です。
確認が終わったら、画面左上の「フローに戻る」のリンクをクリックします。
タイプノードの設定
次に、モデルを作る上で最も重要なタイプノードの設定をします。まず、タイプノードをダブルクリックして下さい。
下の画面が出てきたら、まず画面中程の「値の読み込み」をクリックして下さい。
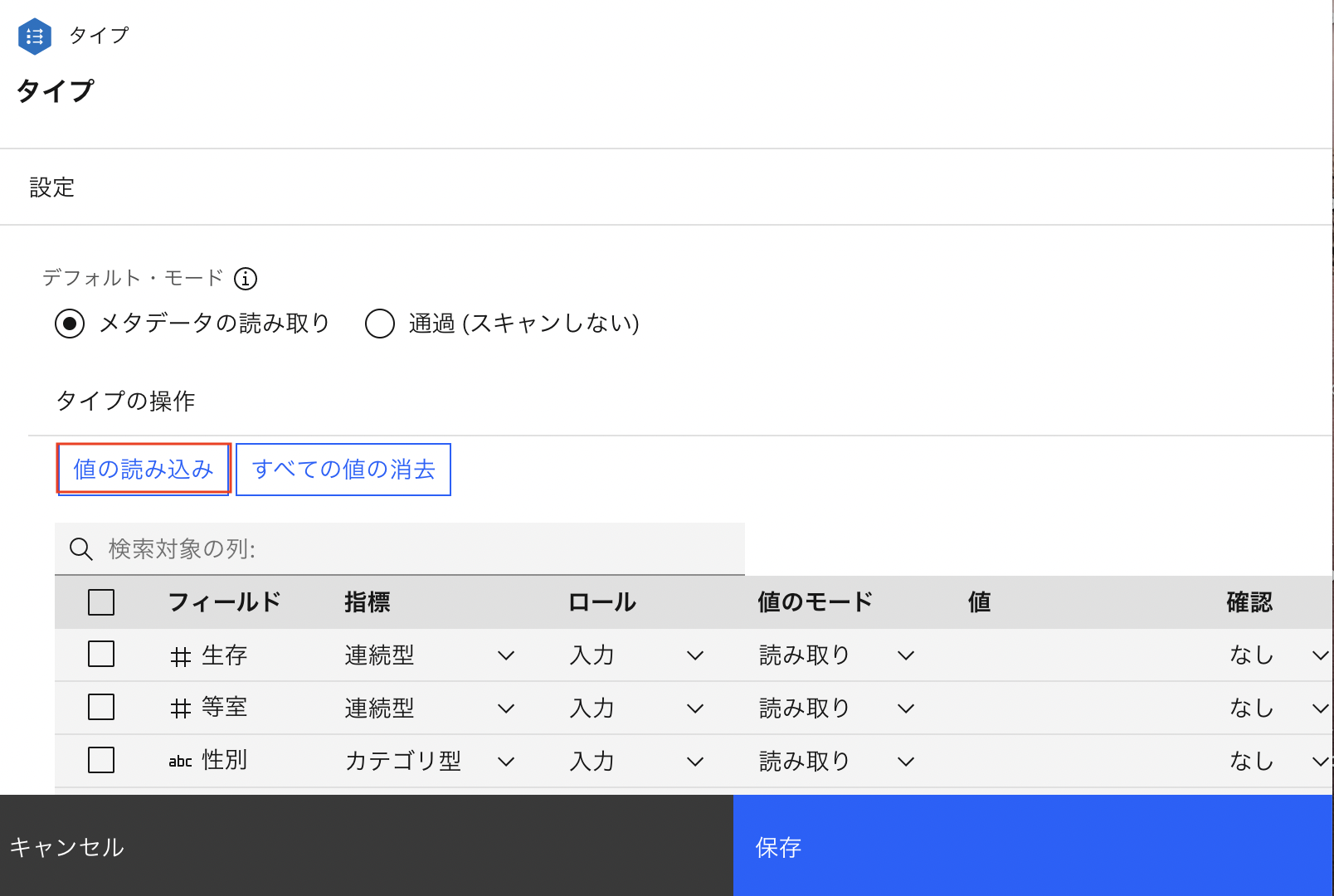
これにより、CSVのデータを全部読み取り、結果に応じて各項目の自動設定をします。
次に下の画面で「生存」「等室」「乗船港コード」のロールを「なし」に変更して下さい。今回利用するデータセットでは、上と同じことを意味する別の項目が存在するため、情報のダブりをなくす目的でこの設定をします。 参考までに、Pythonで同じ処理をする場合は、データフレームのdrop関数を使う形になります。

設定後は、下の画面のようになるはずです。
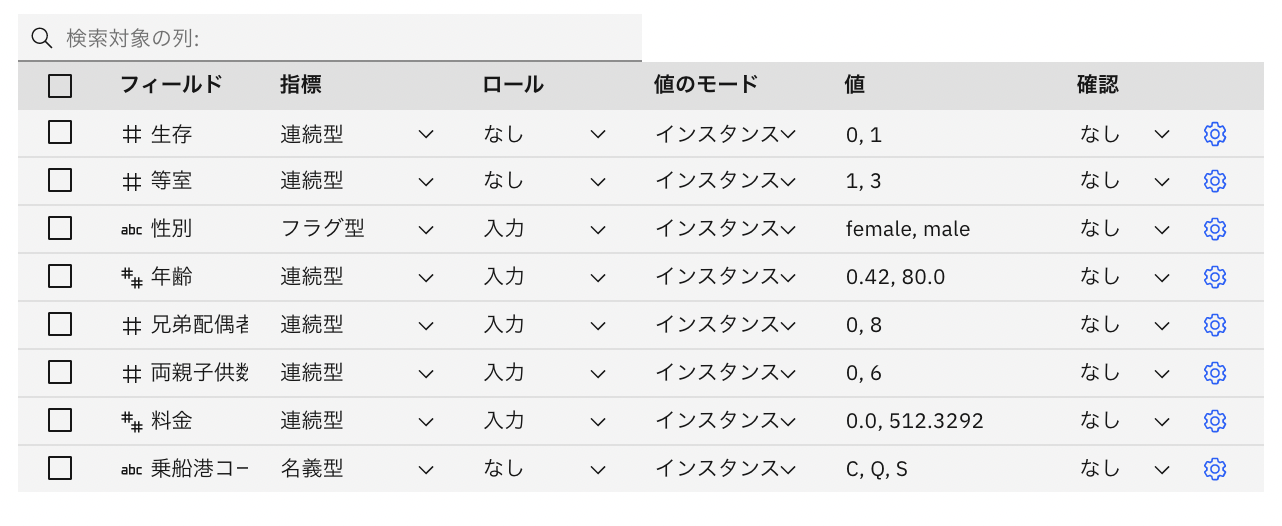
次にこのリストをスクロールダウンして、一番下の項目まで表示させます。
そして、下から2つめの「生存可否」の項目のロールを「入力」から「ターゲット」に変更して下さい。この項目が目的変数であることを教えるための設定です。

この他、「指標」の値を手で修正することが必要な場合もあるのですが、今回はその必要はありませんでした。
Python & scikit-learnで決定木モデルを作る場合、指標値が「フラグ型」「名義型」となっている項目に対してはモデル構築前に前処理が必要です。しかし、SPSS Modeler Flowでは**「指標」の設定さえ適切にできていれば、後の処理はユーザーは意識しなくてOK**です。これもSPSS Modeler Flowの特徴の一つになります。
設定が正しくできたら、下の画面右下の「保存」ボタンをクリックします。

パーティションノードの設定
次にパーティションノードの設定をします。パーティションノードをダブルクリックすると、下の画面が表示されます。

ここで、
トレーニング:パーティション: 70
テスト・データ区分:30
シード: 123
を設定し、画面右下の「保存」ボタンをクリックします。
モデルの構築
これで、モデル構築のためのすべての準備はできました。
下の画面で「実行」をクリックすると、学習が始まります。

下の図のように新しくオレンジ色のノードができていれば、学習に成功しています。

結果の確認
このノードにマウスポインタをあわせて、コンテキストメニューを表示させて下さい。
メニューから「モデルの表示」を選択します。

上の画面が表示されるので、下から3つめの「ツリー図」をメニューから選択します。

上の様な図が出てくるので、「分類のラベルの表示」にチェックをつけた上で、ツリー図を拡大してみて下さい。
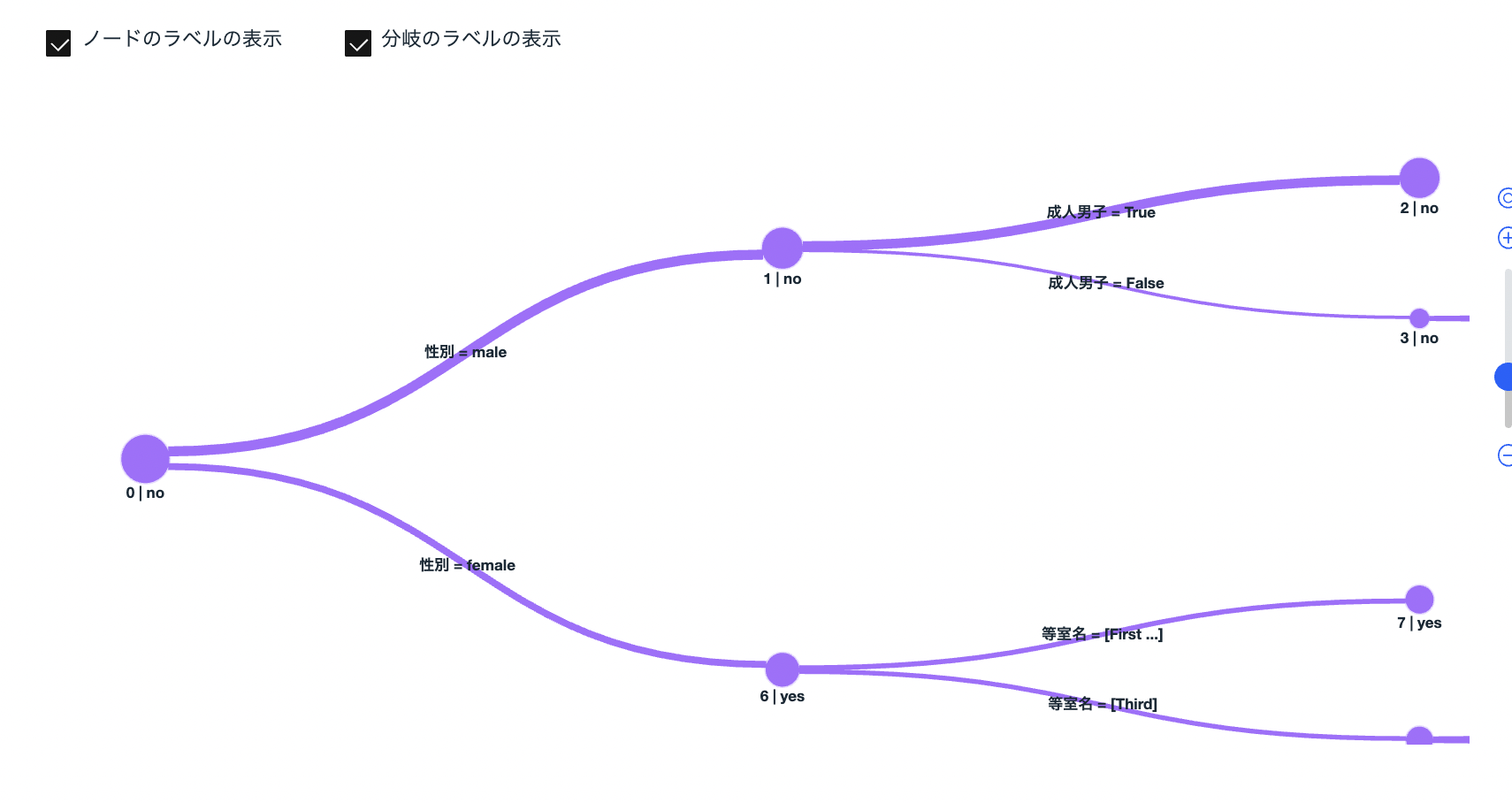
上の図が、最終的な結果です。**生き残れたかどうかの一番重要な要素は「性別」で次の要素は「等室」(一等室の方が生き残る確率が高かった)や「成人男子」(男でも子供は優先して救出された)**など、当時の生々しい様子が、ツリーによる分析結果から読み取れます。
精度の分析
最後に今作ったモデルの精度分析をしてみましょう。
パレットから「出力」「精度分析」のノードをドラッグアンドドロップし、学習済みモデルと結線します。下の図の赤枠で囲まれた部分が、新たに追加されたところです。

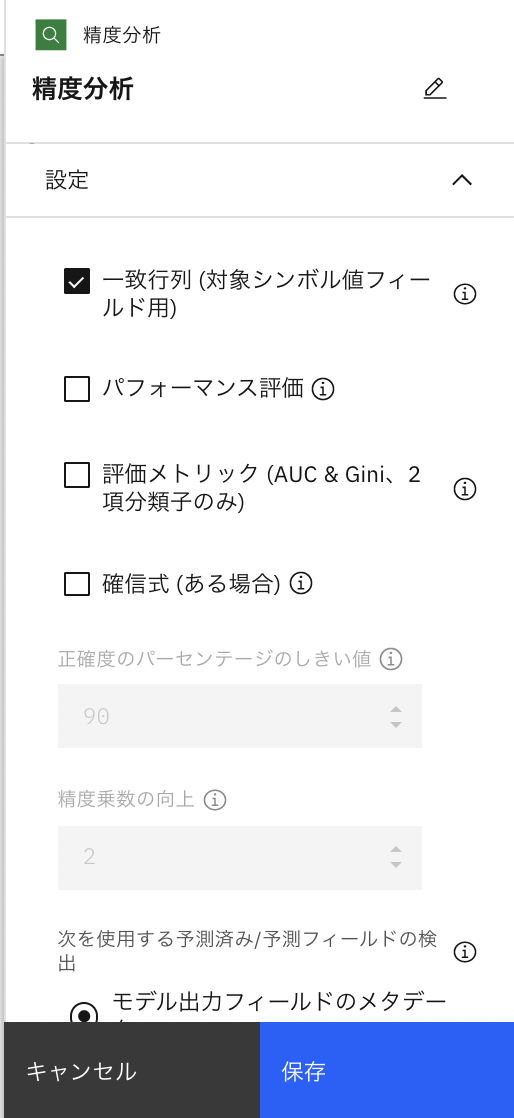
次の「精度分析ノード」をダブルクリックします。下の画面が出て来るので、「一致行列」にチェックを入れて、右下の保存ボタンをクリックします。
「精度分析ノード」のコンテキストメニューを表示させ、実行ボタンをクリックします。
実行後の様子が、次の画面になります。

赤枠で囲んだ部分が、検証データに対する混同行列です。
まとめ
以上、とても簡単な操作で決定木のモデルが作れる、しかも判断ロジックの確認もお手軽にできることを確認しました。
タイタニックデータセットでは欠損値があり、今回は欠損値を持った状態のままでモデルを作ったことになります。
あるいは、scikit-learnでモデルを作る際に必須の手順であるカテゴリ変数のダミー変数化は、タイプノードで「名義型」が正しく設定されていれば、自動的に内部で対応してくれています。
こうした点もscikit-learnではできない便利な点です。
全体を通じて、プログラミングが苦手なユーザーに取ってとても便利な分析ツールであるということができます。
おまけ(作成済みフローの読み込み)
今回ご紹介した手順は、Pythonに比べるとはるかに簡単なものですが、もっと簡単に決定木の結果だけ確認したい方のために、構築済みのフローもGithubにアップしておきました。
以下にこのフローをダウンロードして、より簡単にモデル構築をする手順を説明します。
「プロジェクトに追加」「Modeler フロー」の選択までは同じで、下の画面から

①「ファイルから」タブを選択
②画面左下のガイドに従い、フローファイルをアップロード
③画面右下の「作成」ボタンをクリック
読みが完了したら、画面上部の「実行」ボタンをクリックすると、モデルが構築され、モデルの表示も可能になります。
IBM Cloud Festa で使った発表資料はこちら