はじめに
Watson Discoveryには専用のクローラがあるのですが、現在のところ残念ながらWEBサイトをクロールする機能を持っていません。
そこで、別ソフトを使いいったんWebコンテンツをクロールした結果をローカルファイルに落とし、その結果をDiscovery付属のクローラでDiscoveryに取り込むということを実際に試してみました。
クローラは何を使ってもよかったのですが、ApacheのOSSであるManifoldCFが一番、イマ風かと思い、これを使ってみました。わかりやすい資料があまりなく、最初どう使っていいかわからず戸惑ったのですが、仕組みを理解できるとすごくよくできていることがわかり、今ではとても気に入っています。
その手順をこれから簡単に説明しようと思います。
前提OS
Mac OS High Sierraです。
この作業中に勝手に?バージョンアップされて、OSバージョンは作業終了時には10.13.2になっていました。
ソフトのダウンロード、解凍、起動
以下の手順で行いました。
Javaのバージョンが 9.0.1の場合、以下の手順で簡単に立ち上げることができました。
$ wget http://ftp.jaist.ac.jp/pub/apache/manifoldcf/apache-manifoldcf-2.9/apache-manifoldcf-2.9-bin.tar.gz
$ tar xzvf apache-manifoldcf-2.9-bin.tar.gz
$ cd apache-manifoldcf-2.9
$ cd example
$ java -jar start.jar
管理画面の起動、ログイン
上のコマンドでstart.jarが正常に立ち上がった場合
http://0.0.0.0:8345/mcf-crawler-ui/login.jsp
で、下記のログイン画面が表示されるはずなので、admin/adminのユーザーID/パスワードでログインします。
一点注意しないといけないのが、利用するブラウザです。いつものクセでSafariを使っていたのですが、これだと更新系のタスクが一切まともに動きません。(これで結構時間を無駄にしました。。)
Firefoxを使う必要があるみたいなので、この点に注意してください。
ログインすると、以下のような画面が表示されます。
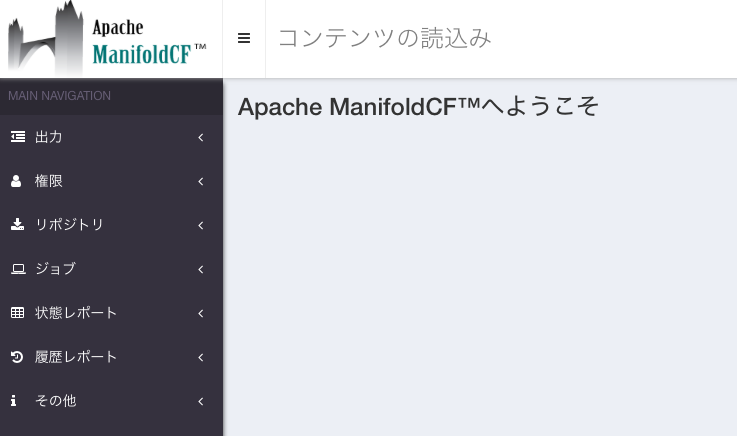
今回の目的を最短コースで実現するには、
- 出力の定義
- リポジトリの定義
- ジョブの定義
- ジョブの実行
という手順になります。
考え方として、
出力: 出力先の種別の定義
リポジトリ: 入力の種別の定義
ジョブ: 複製の個別タスク
ということになります。
上2つは、抽象的なクラス定義のようなものです。
ジョブが具体的なインスタンスにあたります。
今回のユースケースだと、
出力: ファイルシステム
リポジトリ: WEBサイト
ジョブ: 入力はWEB、出力はファイルシステム。xxxのサイトをクロールし、その結果を /xxx/yyy ファイルシステムに保存する
みたいな感じです。
以下でではそれぞれの設定例について説明しますが、上のことを念頭においておくと、個々の作業の理解が早いと思います。
出力コネクションの定義
出力コネクションとは、クロールした情報の出力先のことです。
Solr / Elasticsearchへの取込みが目的の場合、それぞれ用のConnectorがあるので、それを選べばいいのですが、Watson Discoveryではまだそのようなコネクタがないので、いったんローカルのファイルシステムに落とすことにします、
左側のメニューから「出力コネクション一覧」を選択し、「新しい出力コネクションを追加」をクリックし、次の画面では"fs_conn"などの名前を入力
「タイプ」のタブを選択し、ドロップダウンから"File system"を選択し、下の画面になるので「次へ」を選択。更に「保存」をクリック。
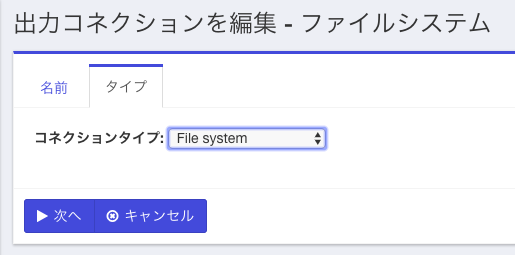
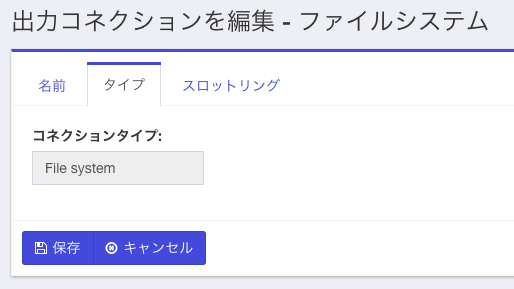
これで出力コネクションの定義ができたので、次にリポジトリの定義を行います。
リポジトリの定義
リポジトリとは、読込元のデータソースのことです。
今回はWebを選択しますが、ManifoldCFではこの他にも多くのリポジトリを対象とすることができます。
左側のメニューから「リポジトリコネクション一覧」を選択し、「新しいコネクションを追加」のボタンをクリックします。
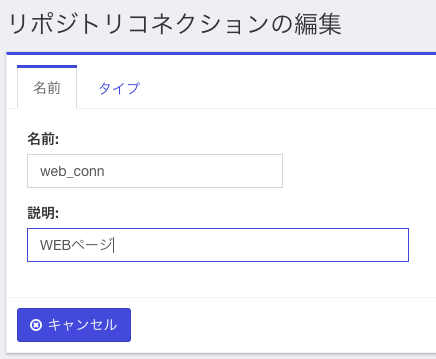
下のような画面がでてくるので、web_connなど適当な名前を指定し、「タイプ」タブをクリック。
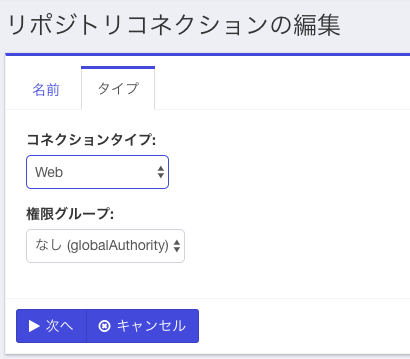
次の画面が出てきたら、コネクションタイプに"Web"を選択します。権限グループはデフォルトのままで「次へ」
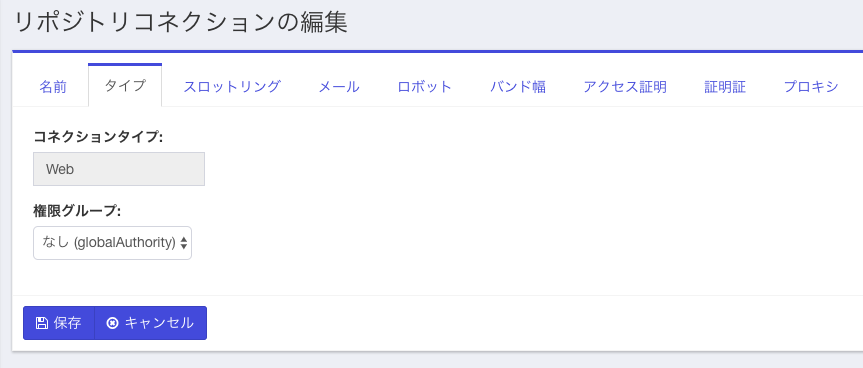
次の画面になったら「メール」のタブを選択し、emailアドレスを入力します。
クロール先にSSLがある場合は、「証明証(ママ)」タブをクリックしてください。
(日本語がちょっと変です。。)
図のようにURL正規表現を https://* として、「すべてを信用する」にチェックを付けてください。(一番緩い設定の場合)
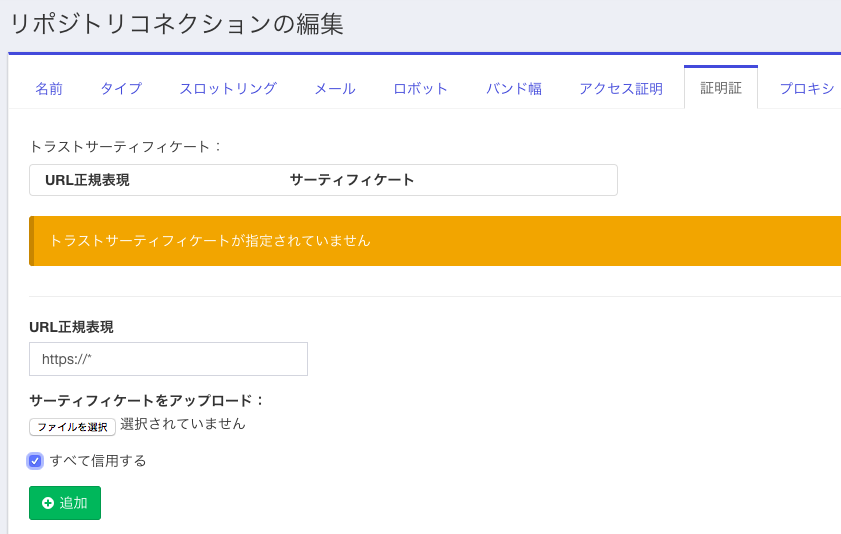
入力した後で「追加」ボタンを押すと、下の図のようになります。
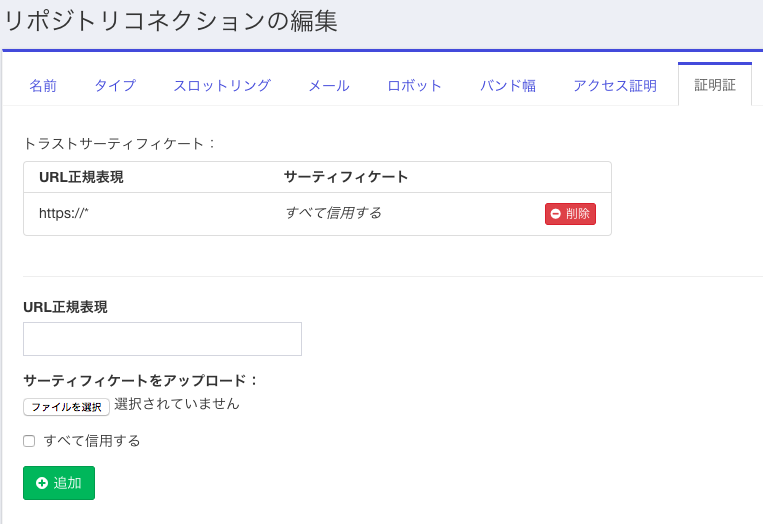
必要な情報を全部入力したら、「保存」ボタンをクリックして保存します。これでリポジトリの定義は終わりです。次にジョブの定義を行います。
ジョブの定義
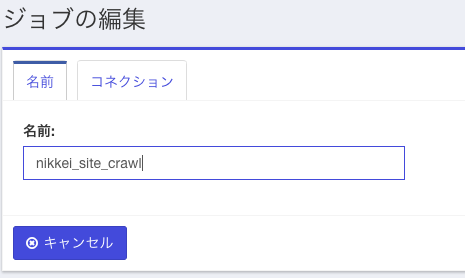
例によって、メニューから「ジョブ一覧」を選択し、「新しいジョブを追加」をクリックします。下の画面がでたら、"nikkei_site_crawl" などの適当な名前を入力し、「コネクション」タブをクリックします。
「コネクション」タブを押した直後は、下のような画面になっています。ここでまず入力(=リポジトリ)を指定します。右の接続名の欄に、先ほど定義したリポジトリの名前がドロップダウンにでてくるはずなので、それを指定します。その後で画面下方の「次へ」ボタンをクリックします。
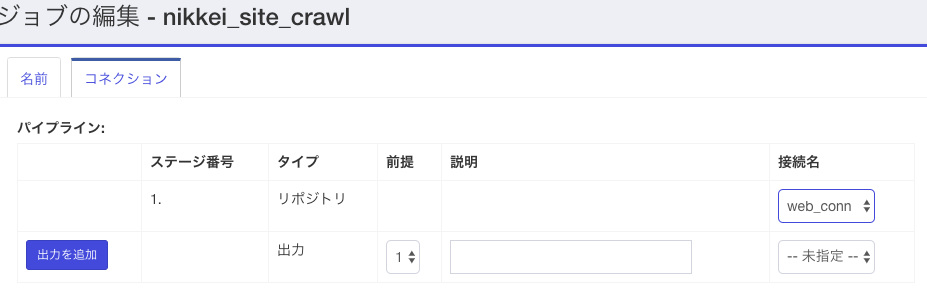
次は出力の指定です。2行目の接続名の欄には、一番最初に出力の定義で定義した名前がでてくるはずなので、それを選択し、「出力を追加」ボタンをクリックします。
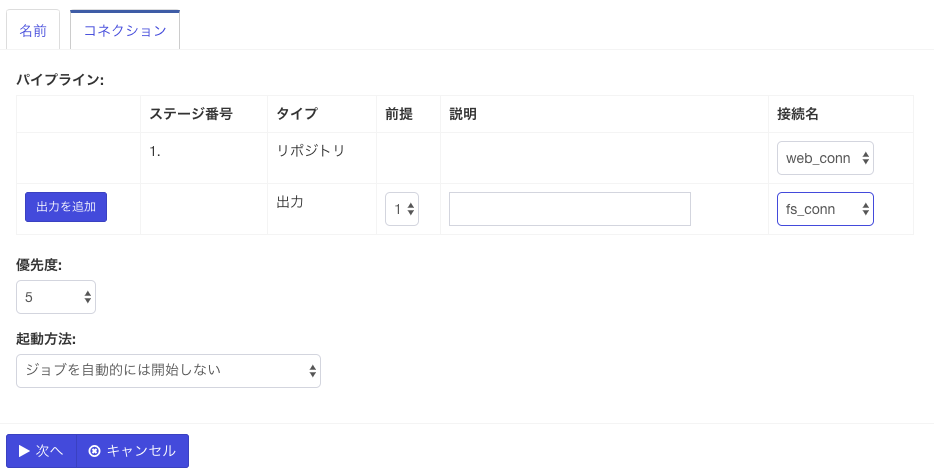
すると、下の図のようにリポジトリと出力の2行の内容が確定した状態で表示されます。

後は、他のタブをクリックして必要なパラメータを定義していきます。
最初に設定が必要なのが「シード」タブです。
下記が「シード」タブをクリックした直後の画面です。
ここではWEBクロールをかけるための起点となるWEBページのURLを指定します。
(通常はサイトのトップページ)
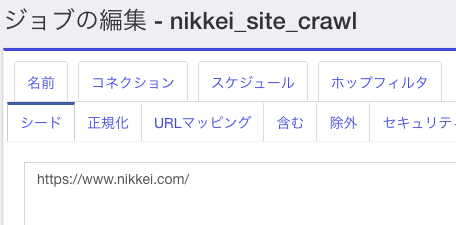
ちなみに、図ではhttpsの検証もかねて日経のサイト( https://www.nikkei.com/ )にしていますが、ここでは有料ページばかりで意味のある情報はほとんど取れませんでした。それよりはライブドアニュースのURL( http://news.livedoor.com/ )をお勧めします。。
WEBクロールの際に意識する必要のあるタブとして以下のようなものがあります。
- 含む WEBクロールではseedsで指定されたURLを出発点に、そのページに書かれているURL情報を抜いてきいて、新たにそのページをクロールし、ということを繰り返すわけですが、その際、どの範囲までをクロール対象とするのかの定義です。今回はseedsと同じ "https://www.nikkei.com/*." としました。

- 除外 Includesと逆に除外したいサイトがあればそれを指定します。今回は特に指定しませんでした。
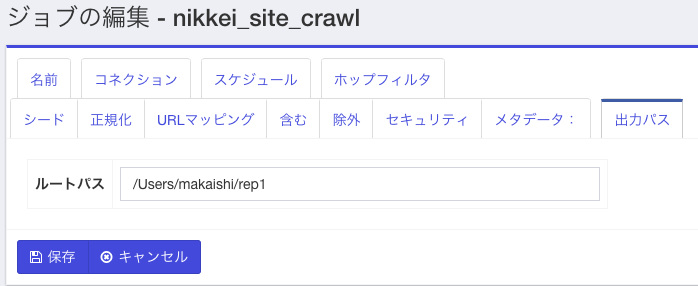
一番右の**「出力パス」**タブは、どのディレクトリにクロール結果を書き出すかを指定します。
今回のユースケースの場合、必須の設定項目です。ダウンロード用の適当なパスを指定します。最後に「保存」ボタンを押して設定を保存します。
以上で(今回のユースケースに限っていえば)必要は設定は完了です。あとは、今設定したジョブを実行するだけとなります。
ジョブの実行
最後に今定義したジョブを実行します。
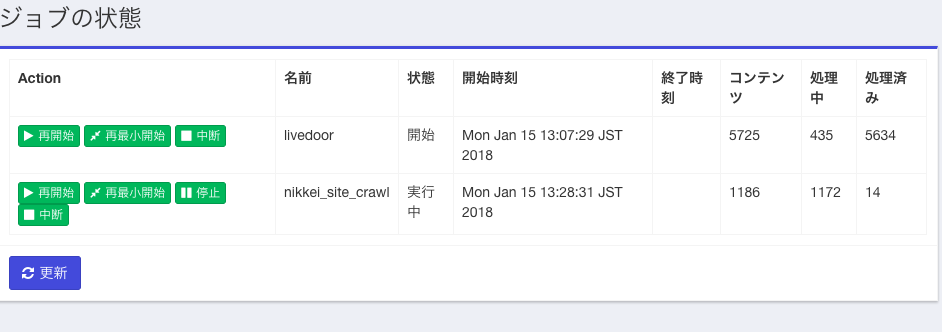
ジョブの実行は左のメニューのうち「ジョブ」「ジョブの状態と管理」を選択して行います。
下記のようなメニューが出るので。今定義したジョブに対して「開始」ボタンを押します。
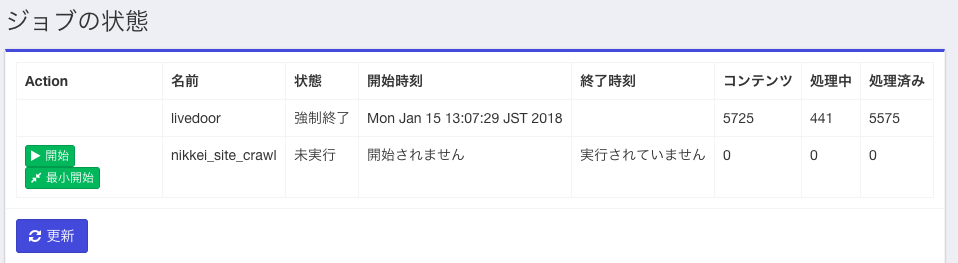
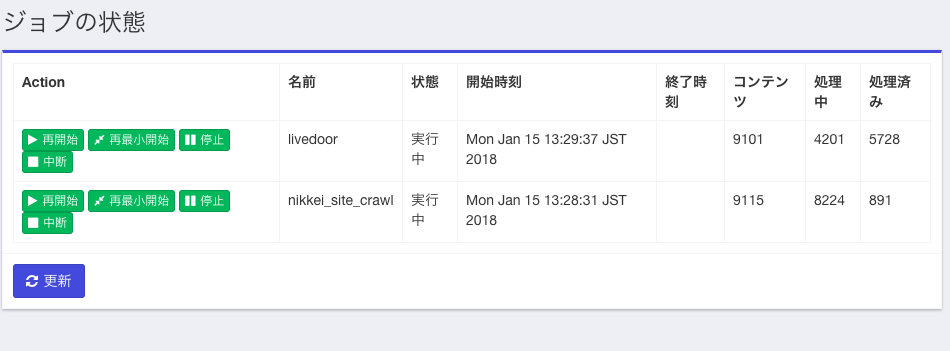
下記にジョブ実行中の途中経過の画面を示します。seedから出発して処理対象のコンテンツ数が増え、少し遅れて「処理済み」のコンテンツ件数も増えている様子がわかると思います。
おまけ
ここでダウンロードして得られたニュース記事をDiscovery付属のクローラを使ってDiscoveyに取り込むための手順については、別記事付属クローラツールを使ってファイルシステム上のコンテンツをWatson Discoveryに取り込むを参照してください。