1. どんな内容か
H x W pixel の1チャンネル画像が3枚セットで与えられる。
2枚がセットで特徴ベクトルを与え、1枚はセグメント化されていて目的変数となる。
題意は、2チャンネルのデータからセグメント化されたもう1チャンネルを再現することである。
最初のアイデアとして、pixel単位で2チャンネルの画素値からもう1チャンネルを予測できれば良さそうである。
無論題意的には、convolution matrixを何か考えて、周辺数pixel距離までを読み込んで予測させるとかだろう。
また、目的変数については、画素値が規定値以上かでクラス分けされ、規定値以下については回帰で画素値の予測が期待されている。
とりあえず最初の試みとして、このクラス分類について試みてみた。
なお、 python の実行環境は venv を使って分離しておいて、その中で pip を使って必要なライブラリをインストールした。
python3 -m venv ./P
source P/bin/activate
pip install --upgrade pip
pip install --upgrade scikit-image
2. データの取り込みと確認
2.1 データの読み込み・確認
1チャンネル画像を2個読み込んで、スタックして2チャンネル画像とする。
1次元化して画素値[p1, p2]に対してクラス(0 or 1)を対照すればよいはずである。
画像の読み込みはscikit-imageを使った。
今回は別になんでもよかったはず。
画像を読み込むと、H x Wのnumpy配列になる。
こんなかんじ
>>> from skimage import io
>>> img = io.imread('train_images/train_hh_00.jpg')
>>> print(img.shape, img.dtype)
(8098, 11816) uint8
>>> print(img.max(), img.min(), img.mean(), img.std())
255 0 4.339263004581821 4.489037358487263
>>> print(img)
[[1 1 1 ... 6 7 5]
[2 2 2 ... 6 8 8]
[2 2 2 ... 7 8 9]
...
[2 2 1 ... 6 7 8]
[2 3 3 ... 8 9 8]
[2 3 3 ... 8 9 8]]
この後
io.imshow(img)
io.show()
とやれば画像として確認できるし
img *= 20
とかやっておけば画素値を拡大しておける。
2.2 HH, HV 画像の画素値分布の確認
これで分類をやろうと思うのだから、ちゃんと視認しておく。
読み込んだ HH, HV, annotation 画像のnumpy配列の配列を作っておいて matplotlib で3次元にscatter plotする。
やってみるとこれが地獄のように遅い。
全部はとても plot できないので、以下のようにして1次元化して一部だけplotしてみる。
import matplotlib.pyplot as plt
def reshape_them(img):
rimg = list(map(lambda i: i.reshape([1, -1]), img))
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(rimg[0][0][75500000:75510000], rimg[1][0][75500000:75510000], rimg[2][0][75500000:75510000], marker='o')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
plt.show()
以下の結果を得た。


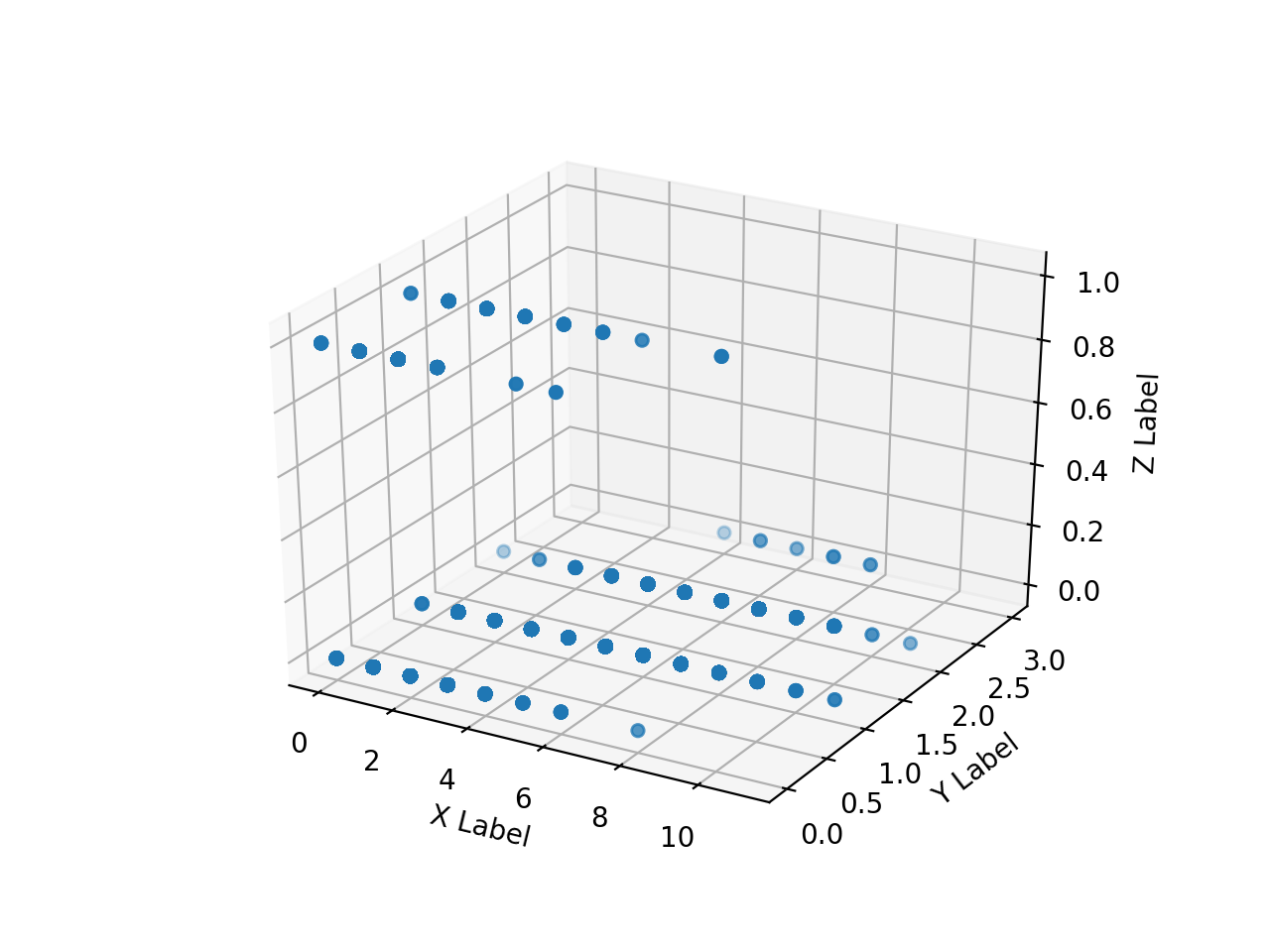

それぞれ ax.scatter() の配列範囲が [0:10000], [500000:510000], [5500000:5510000], [755000000:75510000], である。
annotation 画像の都合で、教師データの画素値(Z)がなんらかの値をとる領域がかなり後ろに偏っていること、
同じ HH, HV 値から 2class に別れていることなどがわかる。
なので、 HH, HV だけ 2class 分類するのは無謀なのだが、とりあえずこれで何が得られるか確かめてみる。
2.3 3channel画像を作成
HH, HV 1channel 画像をstackして3channel画像を作成する。
前述のnumpy arrayをスタックすればいい、と思ったが、多チャンネル画像は 2D array がチャンネル数分積層しているのではなく、
チャンネル数の長さの 1D array が XY に並んでいるものだった。
作り方は、まず 2D array を3枚並べた array を作っておいて(imgx)、transpose()で「軸」をいじってチャンネル方向を最内にする(imgy)。
imgx = np.array([imgs[0], imgs[1], imgs[1]*0])
imgy = imgx.transpose(1,2,0)
imgz = imgy * 16
io.imshow(imgz)
io.show()
3channel 必要なので、 *0 して全部0のプレーンも作って含めてある。
また画素値が小さすぎるので *16 して見分けがつくように補正している(imgz)。
せっかくなので、もと画像と並べて表示しようとしてみる。
im21 = cv2.hconcat([gray2rgb(imgs[0]*16), gray2rgb(imgs[1]*16)])
im22 = cv2.hconcat([gray2rgb(imgs[2]*16), imgz])
im2 = cv2.vconcat([im21, im22])
io.imshow(im2)
io.show()
結合の際にチャンネル数を合わせるために gray2rgb() を使っている。
3. クラス分類 --SVM
3.1 SVM
話を戻す。1枚の H x W 1channel 画像を読み込んだところで、それを 1 x H*W に reshape する。
これを2画像 vstack して transpose すれば、 pixel ごとに2画像の画素値が並び、同様に 1 x H*W に reshape した annotation 画像とセットにすれば SVM で識別器が作れそうである。
import sklearn.svm
import joblib
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import time
def reshape_and_calc(img):
rimg = list(map(lambda i: i.reshape([1, -1]), img))
print(rimg[0].shape, rimg[0].dtype, rimg[0].ndim)
train = np.vstack((rimg[0], rimg[1])).transpose()
label = rimg[2][0]
print(train.shape, label.shape)
train = train / 16.0 # [0..255] を [0..1) にしてから 16倍相当
label = np.where(label>10, 1, 0)
print(train)
print(label)
恐ろしいことに、学習で食わせるデータは N x 2 の行列なのに、 scikit-learn の svm が食うラベル(目的変数)は 1 x N のベクトルなのである(なのでtrainの計算にtranspose()がついている)。
なんで縦横食い違ってんねん。
この後、以下のようにまるっと SVM のクラス分類機オブジェクトに食わせて、最後はそれ自体を joblib で serialize してしまえばおしまいではある。
svm = sklearn.svm.SVC(kernel='rbf', random_state=0, gamma=0.10, C=10.0)
svm.fit(train, label)
joblib.dump(svm, 'svmmodel.sav')
ただし、この svm.fit() は猛烈に時間を食う上に途中経過を全く出さないので、本当に計算しているのかどこかでスタックして
いつまで待っても無駄なのかの見分けが全くつかない。
なので、やっていいのか怪しいが、データをちょっとづつ切り出して順次学習させるということをやってみる。
以下のコードは動作した。
train_X, test_X, train_y, test_y = train_test_split(train, label, train_size=0.8, random_state=1999)
#print(train_X, test_X, train_y, test_y)
print('data splitted', train_X.shape, test_X.shape, train_y.shape, test_y.shape)
M = len(train_X)
L=65536
offset=0
start_time = time.time()
while offset < M:
print('fitting', offset, '/', M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
svm.fit(train_X[offset:L2], train_y[offset:L2])
offset += L
print('done')
y_pred = svm.predict(test_X)
print('Misclassified samples: %d' % (test_y != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(test_y, y_pred))
こういうログが残っている。
fitting 76349440 / 76548774 706.0181198120117 sec
fitting 76414976 / 76548774 706.6317739486694 sec
fitting 76480512 / 76548774 707.2629809379578 sec
fitting 76546048 / 76548774 707.8376820087433 sec
done
Misclassified samples: 54996
Accuracy: 1.00
707秒で 76,548,774点を扱っていた。
これを、 verification はそもそも別のファイル群で行う、学習には全データを突っ込みたいので train_test_split したくない、となると突如ハマった。
3.2 SVM classification - 正負のバランス
train_test_split() は一セットの訓練データ、ラベルから、訓練用のセットと学習結果の評価用のverificationのセットを切り出してくれる。ついでに、ランダムにシャッフルも入れてくれるっぽい。
しかしここで、一部を評価用に回してしまうのはもったいない、評価は別のファイルでやるから1ファイル全部を訓練データに使いたいとしてtrain_test_split()を使わないようにしたとする。
train_X, test_X, train_y, test_y = train_test_split(train, label, train_size=0.8, random_state=1999)
の部分を単にtrain, labelをtrain_X, train_yに突っ込んでみると、速攻ラベルデータに正例しか含まれていないとして拒否られる。
ValueError: The number of classes has to be greater than one; got 1 class
考えてみれば、この教師データの元は一枚の画像で pixel 値で、クラスの異なる部分は画像の下部にある小さな領域だけだった。
上から pixel 値をつまんで行けば相当進まなければ1クラスしか含まれない。
改善方法は、クラス=0、=1双方同じ数だけ画素を抽出し、結合して念の為ランダムシャッフルして、上から順に65536づつ処理する。
両クラスから同数抽出するために、多い方のクラスはランダムシャッフルが必要で結合してまたシャッフルしている。
やってみるとこれが猛烈に遅かった。何かというとすぐにnumpyだから速いというが、こういうことやれば当然のように遅い。
あるファイルでは、 pixel 数が 95,685,968、うち正例が 4,811,822 だったので正負合わせて 9,623,644点を抽出する。
1点あたり HH, VV 2個の値があり、 [0, 1) で規格化したところで 64bit 浮動小数点値になっているだろうから 96M点×2×8byte で
1.54G から 153.6M を抽出して入力データを作っていた。
def reshape_them(imgs):
rimg = list(map(lambda i: i.reshape([1, -1]), imgs))
train = np.vstack((rimg[0], rimg[1])).transpose()
teach = rimg[2][0]
print(train.shape, teach.shape)
train = train / 256.0
teach = np.where(teach>10, 1, 0)
return [train, teach]
def balance(data):
train_x = data[0]
train_y = data[1]
mask = train_y == 1
train_x_pos = train_x[mask]
train_x_neg = train_x[np.logical_not(mask)]
sample = min(len(train_x_pos), len(train_x_neg))
train_y_balance = [1 for i in range(sample)] + [0 for i in range(sample)]
print('shrink length to', len(train_y_balance))
if len(train_x_pos) < len(train_x_neg):
np.random.shuffle(train_x_neg)
else:
np.random.shuffle(train_x_pos)
train_x_balance = np.concatenate([train_x_pos[:sample], train_x_neg[:sample]])
print("shuffled and concatenated", train_x_balance.shape)
Y = np.hstack([train_x_balance, np.array(train_y_balance).reshape([len(train_y_balance),1])])
#print(Y.shape)
np.random.shuffle(Y)
print(Y[:,0:2], Y[:,2].transpose())
return([Y[:,0:2], Y[:,2].transpose()])
def run(train_X, train_Y, model):
print(train_X.shape, train_Y.shape)
M = len(train_X)
L=65536
offset=0
start_time = time.time()
while offset < M:
print('fitting', offset, '/', offset / M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
#print(train_X[offset:L2], train_Y[offset:L2])
model.fit(train_X[offset:L2], train_Y[offset:L2])
offset += L
print('done')
(X, Y) = reshape_them(imgs)
(X, Y) = balance([X, Y])
svm = sklearn.svm.SVC(kernel='rbf', random_state=0, gamma=0.10, C=10.0)
run(X, Y, svm)
3.3 SVM - 学習後
学習自体は AWS で行った。
学習が終了すると
joblib.dump(svm, modelfile)
として SVM オブジェクトを serialization 保村している。これをローカル PC に持ってきて
手元のファイルに対して
with open(modelfile, mode="rb") as f:
svm = joblib.load(f)
M = len(X)
L=65536
offset=0
start_time = time.time()
y_pred = []
while offset < M:
print('prediciting', offset, '/', offset / M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
_Y = svm.predict(X[offset:L2])
y_pred.append(_Y)
#print('Misclassified samples: %d' % (Y[offset:L2] != _Y).sum())
#print('Accuracy: %.2f' % accuracy_score(Y[offset:L2], _Y))
offset += L
predicted = np.concatenate(y_pred).reshape(imgs[2].shape)
io.imshow(predicted)
io.show()
im2 = cv2.hconcat([predicted*10.0, imgs[2]*1.0])
io.imshow(im2)
io.show()
として予測値を出して結合して画像に戻してやれば、画像として見た目でどの程度それっぽいか判断できそうである。
で、やってみると、以下のようになって AWS 環境の linux の python と、ローカルの MacOS の python でモジュール名が微妙に食い違っていて読み込めない。
File "/usr/local/Cellar/python/3.7.5/Frameworks/Python.framework/Versions/3.7/lib/python3.7/pickle.py", line 1426, in find_class
__import__(module, level=0)
ModuleNotFoundError: No module named 'sklearn.svm._classes'
確かに serialization file の先頭部分を見ると、AWSで作ると
00000000 80 03 63 73 6b 6c 65 61 72 6e 2e 73 76 6d 2e 5f |..csklearn.svm._|
00000010 63 6c 61 73 73 65 73 0a 53 56 43 0a 71 00 29 81 |classes.SVC.q.).|
00000020 71 01 7d 71 02 28 58 17 00 00 00 64 65 63 69 73 |q.}q.(X....decis|
00000030 69 6f 6e 5f 66 75 6e 63 74 69 6f 6e 5f 73 68 61 |ion_function_sha|
00000040 70 65 71 03 58 03 00 00 00 6f 76 72 71 04 58 0a |peq.X....ovrq.X.|
とアンスコが入っているが、 mac で吐かせてみると
00000000 80 03 63 73 6b 6c 65 61 72 6e 2e 73 76 6d 2e 63 |..csklearn.svm.c|
00000010 6c 61 73 73 65 73 0a 53 56 43 0a 71 00 29 81 71 |lasses.SVC.q.).q|
00000020 01 7d 71 02 28 58 17 00 00 00 64 65 63 69 73 69 |.}q.(X....decisi|
00000030 6f 6e 5f 66 75 6e 63 74 69 6f 6e 5f 73 68 61 70 |on_function_shap|
00000040 65 71 03 58 03 00 00 00 6f 76 72 71 04 58 06 00 |eq.X....ovrq.X..|
のようにアンスコがいないのである。
うーん、そんな所にブレが。
しょうがないので AWS で predict までやってみたが、これが学習と違って one path の計算しかしないくせに死ぬほど遅い。
上記のように正負同数にするための抽出がないので計算点数が多いのだが、それにしても遅い。
ex73: prediciting 65929216 / 0.9993775530341474 9615.45419716835 sec
ex75: prediciting 70975488 / 0.9991167432331827 10432.654431581497 sec
の様に1ファイル2.8時間コースであった。

左 predicted、右 label