はじめに
こんにちは。逆転オセロニアのYouTubeチャンネル「まこちゃんねる」の中の人です。
本稿では、以前にも挑戦したデッキ画像から駒名称を抜き出すことを目標にします。
今回は特徴点マッチングを使った方法を利用してみます。
モチベーション
前回は**テンプレートマッチングを使った方法を利用することで、テンプレート画像から駒名称を取得しました。が、この方法はテンプレート画像を用意する手間があるのが問題点**でした。
そこで、今回はテンプレート画像を作らなくても良い手法で、かつ汎用性の高く、画像から駒名称を抜きだしたいと思ったのが始まりです。

特徴点マッチングとは?
2つの画像間で特徴点を検出し、似た特徴点をマッチングする手法です。テンプレートマッチングは回転や拡縮に弱かったのですが、特徴点マッチングは回転や拡縮にも強いのが特徴です。
特徴点を検出するアルゴリズムは、SIFTやSURF、AKAZEが有名らしいです。
マッチングの手法は、**総当たり法(Brute-Force)か近似最近傍探索法(FLANN)**を利用します。
処理の流れ
-
特徴点の検出
- 画像の特徴点(キーポイント)を検出する
-
特徴量の記述
- 各キーポイントの周辺の勾配情報から特徴量を記述する
-
特徴点のマッチング
- 画像間の特徴量を比較して特徴点を対応付ける
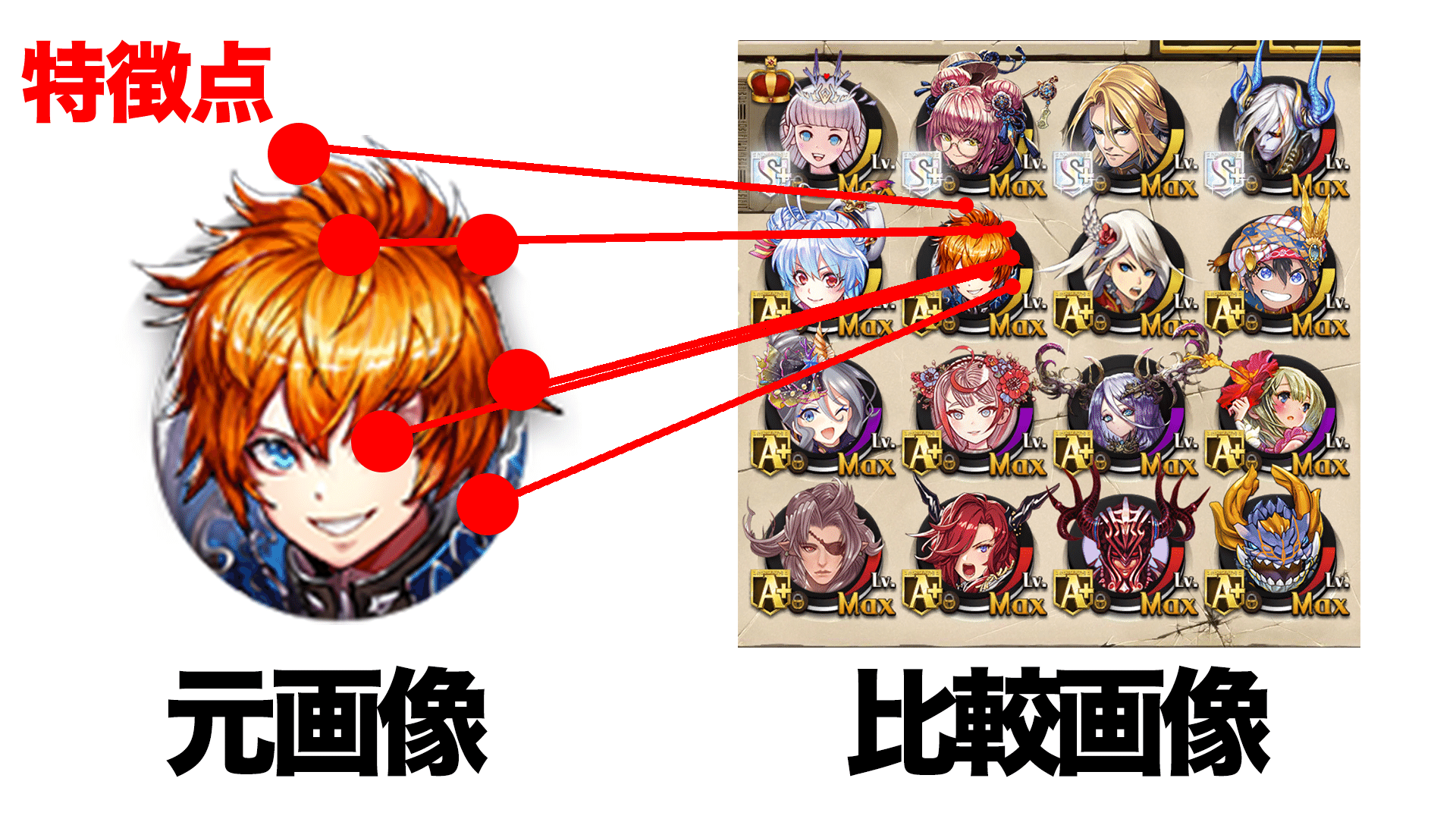
環境
- macOS
- JupyterLab
- Python3.6
- OpenCV
実装の流れ
今回はアルゴリズムにSIFTを使い、FLANNでのマッチングで実装していきます。
- 画像間の対応点の取得
- 特徴点検出と特徴量記述を実装する
- FLANNベースのマッチング処理を実装する
- マッチング結果から対応点を取得する
- 特徴点マッチングの判定
- 画像間の対応点を描画する
- 複数画像の判定に対応する
- 駒名称を出力する
画像間の対応点の取得
まず、SIFTで各画像の特徴点と記述子(特徴点の特徴量)を求めます。その後、FLANNと呼ばれる近似最近傍探索アルゴリズムを用いて、**元画像の各特徴点と特徴が近い比較画像の記述子を求めます。**求めた記述子同士の距離から特徴量として良いものを対応点として取得します。
特徴点検出と特徴量記述を実装する
**SIFT_create()**で検出器を初期化し、**detectAndCompute()**で検出と記述を行います。
kp1、kp2には特徴点の各座標、des1、des2には各特徴点に対応する特徴量が格納されています。
import cv2
import numpy as np
import glob
import matplotlib.pyplot as plt
%matplotlib inline
# 元画像(顔画像)を読み込み、グレースケール変換する(-1はBGRA)
img1 = cv2.imread("face/04524_神_A+_[高みへ挑む者]イリオット.png", -1)
img1_gray = cv2.cvtColor(img1, cv2.COLOR_BGRA2GRAY)
# 比較画像(デッキ画像)を読み込み、グレースケール変換する
img2 = cv2.imread("deck.png")
img2_gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 検出器(SIFT)の初期化をする
sift = cv2.SIFT_create()
# キーポイントの決定と特徴量を記述する
kp1, des1 = sift.detectAndCompute(img1_gray, None)
kp2, des2 = sift.detectAndCompute(img2_gray, None)
FLANNベースのマッチング処理を実装する
今回は記述子のマッチングアルゴリズムに**FLANN(Fast Library for Approximate Nearest Neighbor)**を利用します。indexとsearchパラメータを指定して初期化します。checksの値を大きくすれば精度が上がりますが、速度は遅くなります。flann.knnMatch(des1, des2, k=2)は、第引数des1(元画像の記述子)の各特徴点に対して、第二引数のdes2(比較画像の記述子)を比較していき、近似解2つをマッチング結果として取得します。つまり、元画像の各特徴点と対応するであろう比較画像の特徴点2つを取得しています。
FLANN_INDEX_KDTREE = 0
# INDEXパラメータを指定する
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
# 木構造を再起的に辿る回数を指定する
search_params = dict(checks = 50)
# FLANNの初期化をする
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 上位2つのマッチング結果を取得する
matches = flann.knnMatch(des1, des2, k=2)
マッチング結果から対応点を取得する
des1の各特徴点に近似している2つの距離から特徴量として良いものを対応点としてgoodに格納していきます。0.7の値が小さほど対応点の検出は厳密になり、大きいほど誤検出してしまうので、調整する必要があります。

# 上位2つの距離を相対的に見て、特徴量として良いものを対応点とする
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
特徴点マッチングの判定
マッチした特徴点の個数を閾値とし、閾値に満たない場合は元画像は比較画像に含まれないと判定することにします。今回であれば、特徴点が10個より多くマッチングすれば画像が含まれていると判定します。
画像間の対応点を描画する
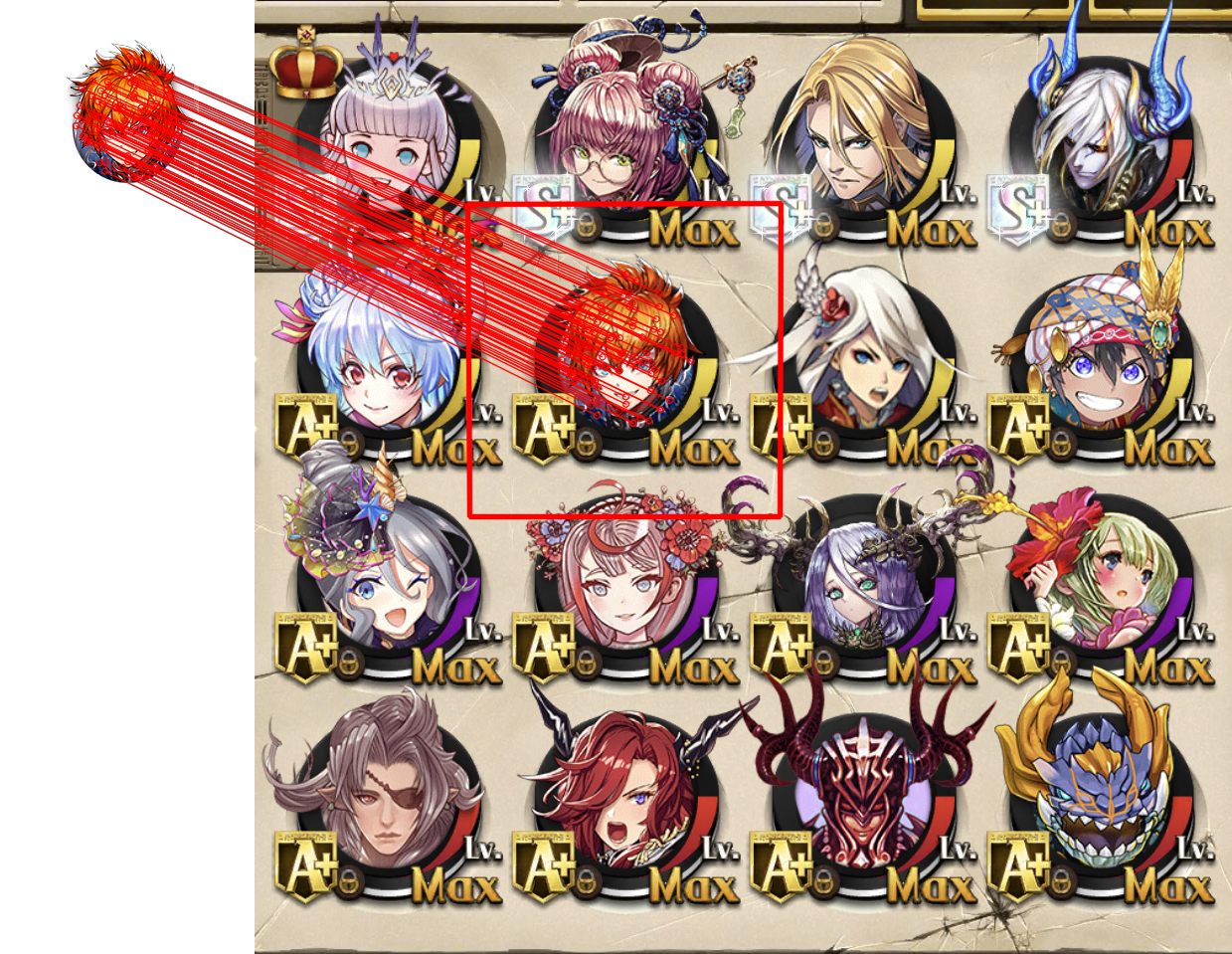
閾値を超えた特徴点が10個を超えている時、画像間の特徴点同士を赤線で結び、元画像が比較画像のどの部分に含まれているのかを赤の矩形で描画する。
# 特徴点個数の閾値
MIN_MATCH_COUNT = 10
if len(good) > MIN_MATCH_COUNT:
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1,1,2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
matchesMask = mask.ravel().tolist()
h,w = img1_gray.shape
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts, M)
img2 = cv2.polylines(img2, [np.int32(dst)], True, (0,0,255), 3, cv2.LINE_AA)
draw_params = dict(matchColor = (0,0,255,255),
singlePointColor = None,
matchesMask = matchesMask,
flags = 2)
img_output = cv2.drawMatches(img1, kp1, img2, kp2, good, None, **draw_params)
cv2.imwrite("output.png", img_output)
複数画像の判定に対応する
元画像を複数枚に増やして順番に判定していく処理を実装します。目標は、比較画像(デッキ画像)に含まれる全駒分の5000クラス以上になるのですが、流石に時間がかかりすぎるので工夫しないとダメそうです。(単純ループで1回試してみましたが、2時間以上かかりました・・・)。
今回は単純にループすることで順次画像を判定してみたいと思います。元画像には以下の5クラスを使いました。被りますが、ループ版の完成コードを載せておきます。
04524_神_A+_[高みへ挑む者]イリオット
02018_魔_S+_[百億の牙]ベルゼブブ
00179_竜_A+_[地帝竜]ランドタイラント
00586_神_S+_[叡智の書]ヒアソフィア
00847_竜_A+_[地城竜]ランドタイラント

import cv2
import numpy as np
import glob
import matplotlib.pyplot as plt
%matplotlib inline
# 比較画像(デッキ画像)を読み込み、グレースケール変換する
img2 = cv2.imread("deck.png")
img2_gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 検出器(SIFT)の初期化をする
sift = cv2.SIFT_create()
# デッキ画像のキーポイントの決定と特徴量を記述する
kp2, des2 = sift.detectAndCompute(img2_gray, None)
# FLANNの初期化をする
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
files = glob.glob("face/*.png")
for idx, file in enumerate(files):
img1 = cv2.imread(file, -1)
img1_gray = cv2.cvtColor(img1, cv2.COLOR_BGRA2GRAY)
# キーポイントの決定と特徴量を記述する
kp1, des1 = sift.detectAndCompute(img1_gray, None)
# 上位2つのマッチング結果を取得する
matches = flann.knnMatch(des1, des2, k=2)
# 上位2つの距離を相対的に見て、特徴量として良いものを対応点とする
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
print(len(good))
# 特徴点個数の閾値
MIN_MATCH_COUNT = 10
if len(good) > MIN_MATCH_COUNT:
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1,1,2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
matchesMask = mask.ravel().tolist()
h,w = img1_gray.shape
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts, M)
img2_tmp = img2.copy()
img2_tmp = cv2.polylines(img2_tmp, [np.int32(dst)], True, (0,0,255), 3, cv2.LINE_AA)
draw_params = dict(matchColor = (0,0,255,255),
singlePointColor = None,
matchesMask = matchesMask,
flags = 2)
img_output = cv2.drawMatches(img1, kp1, img2_tmp, kp2, good, None, **draw_params)
cv2.imwrite(f"{str(idx)}.png", img_output)

駒名称を出力する
最後はテンプレート画像の時と同じように、駒名称を出力して目的を達成する。
# 駒名称リスト
piece_name_list = []
files = glob.glob("face/*.png")
for idx, file in enumerate(files):
img1 = cv2.imread(file, -1)
img1_gray = cv2.cvtColor(img1, cv2.COLOR_BGRA2GRAY)
...
piece_name_list.append(file.split("_")[3].rstrip(".png"))
# 駒名称を出力する
print("\n".join(piece_name_list))
[高みへ挑む者]イリオット
[地帝竜]ランドタイラント
おわりに
これで後は、前回スクレイピングした全駒の顔画像と突合していけば、自前でデータを作らなくても全自動でデッキの中の駒名を取得する事が可能になりました!
また、前回のテンプレートマッチングの実装では、私の端末やオセロニアのデッキ仕様が変わったら全てが終わってしまう実装でしたが、今回は特徴量から求めているので、汎用的に利用していくことも可能です。ただし、全ての駒をチェックしていくとなると数時間かかるため、普段よく使われる駒だけをチェックするか、最低でも検索対象をA+とS+に絞らないとダメだなと思いました。次回はここら辺を改善していきたいと思います。DNN系の技術を用いたら精度高く早くなるのかな?
参考