はじめに
こんにちは。逆転オセロニアのYouTubeチャンネル「まこちゃんねる」の中の人です。
本稿では、公式wikiから駒の顔画像を自動収集することを目標にします。
今回はPythonのスクレイピングフレームワーク、Scrapyを利用してみます。
モチベーション
- オセロニアを題材にしていく上で、画像収集する場面が多いため
- Pythonでスクレイピングを実装したことが無かったので、その練習のため
スクレイピング(Scraping)とは?
ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。
ウェブスクレイピング - Wikipedia より
今回であれば、公式wikiから駒の顔画像及び付随する情報(名称・レア度等)を自動で抽出することになります。

環境
- macOS
- JupyterLab
- Python3.6
- Scrapy
実装の流れ
まずはScrapyをインストールし、scrapyコマンドでプロジェクトを作成します。その後、スクレイピングしたデータを格納する為のItemクラスの実装、HTMLをパースする為のparse関数の実装、取得したデータを操作する為のPipelineを実装していきます。
-
Scrapyプロジェクトの作成
- Scrapyをインストールする
- プロジェクトを作成する
-
Spiderの実装
- Itemを実装する
- Parse処理を実装する
- Pipelineを実装する
-
スクレイピングの実行
- 実際にデータを取得する
Scrapyプロジェクトの作成
Scrapyをインストールし、scrapyコマンドでスクレイピングをするために必要なフレームワークを作成していきます。
Scrapyをインストールする
Scrapyをpipでインストールします。
$ pip install scrapy
プロジェクトを作成する
scrapy startproject <プロジェクト名> で雛形を作成します。今回はプロジェクト名をscraping_character_dataとしています。
$ scrapy startproject scraping_character_data
以下のディレクトリ構造で雛形が作成されます。
$ tree scraping_character_data/
scraping_character_data
├── scraping_character_data
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
Spiderの実装
スクレイピングの中核となる部分です。コマンドでspiderを作成し、雛形として作成されたitems.py、pipelines.py、spider.pyの中身を実装していきます。
Itemを実装する
生成されたitems.pyを編集し、HTMLでパースしたデータを保持するフィールドを定義します。今回であれば、キャラクターの図鑑No、顔画像URL、名前、属性、レア度を定義しておきます。

import scrapy
class CharacterDataItem(scrapy.Item):
no = scrapy.Field()
face_img_url = scrapy.Field()
name = scrapy.Field()
attribute = scrapy.Field()
rarity = scrapy.Field()
Parse処理を実装する
まずはparse処理を作成するために、scrapyコマンドでspiderを作成します。scrapy genspider <spiderクラス名> <スクレイピング対象のドメイン名>で作成することができます。今回はクラス名をcharacter_data、ドメイン名をオセロニア攻略.gamematome.jpとして作成します。
$ scrapy genspider character_data オセロニア攻略.gamematome.jp
spidersディレクトリ直下にcharacter_data.pyが作成されます。
$ tree scraping_character_data/scraping_character_data/spiders
scraping_character_data/scraping_character_data/spiders
├── __init__.py
└── character_data.py
作成されたcharacter_data.pyを編集していきます。nameは実際にスクレイピングを実行するときに指定する値になります。allowed_domainsには実行対象のドメイン名を指定しておきます。今回であればオセロニア攻略.gamematome.jpが作成時に自動で格納されています。start_urlsにはスクレイピング開始のURLを指定しておきます。ここで注意なのですが、日本語のドメイン名はPunycodeへ変換してから扱うようにしたほうが良さそうです。日本語ドメイン名のまま動かしていたらスクレイピングが全然実行されず、ここでめちゃくちゃハマりました...。
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from scraping_character_data.items import CharacterDataItem
class CharacterDataSpider(CrawlSpider):
name = 'character_data'
# Punycodeへ変換しておく
domain = 'オセロニア攻略.gamematome.jp'.encode('idna').decode("utf-8")
allowed_domains = [domain]
start_urls = [f'https://{domain}/game/964/wiki/キャラクター情報']
次にスクレイピング時の巡回ルールを指定します。CrawlSpider、Rule、LinkExtractorをインポートします。LinkExtractorにはどのリンクを巡回するかのルールを指定し、callbackにはルールを満たした時に呼ばれる関数を指定します。今回であれば、start_urlsに指定したURLに含まれるtable要素のidがcontent_block_9に含まれるURLを巡回してスクレイピングを行うことになります。他にもcssのタグや正規表現等といった指定の仕方もすることができます。
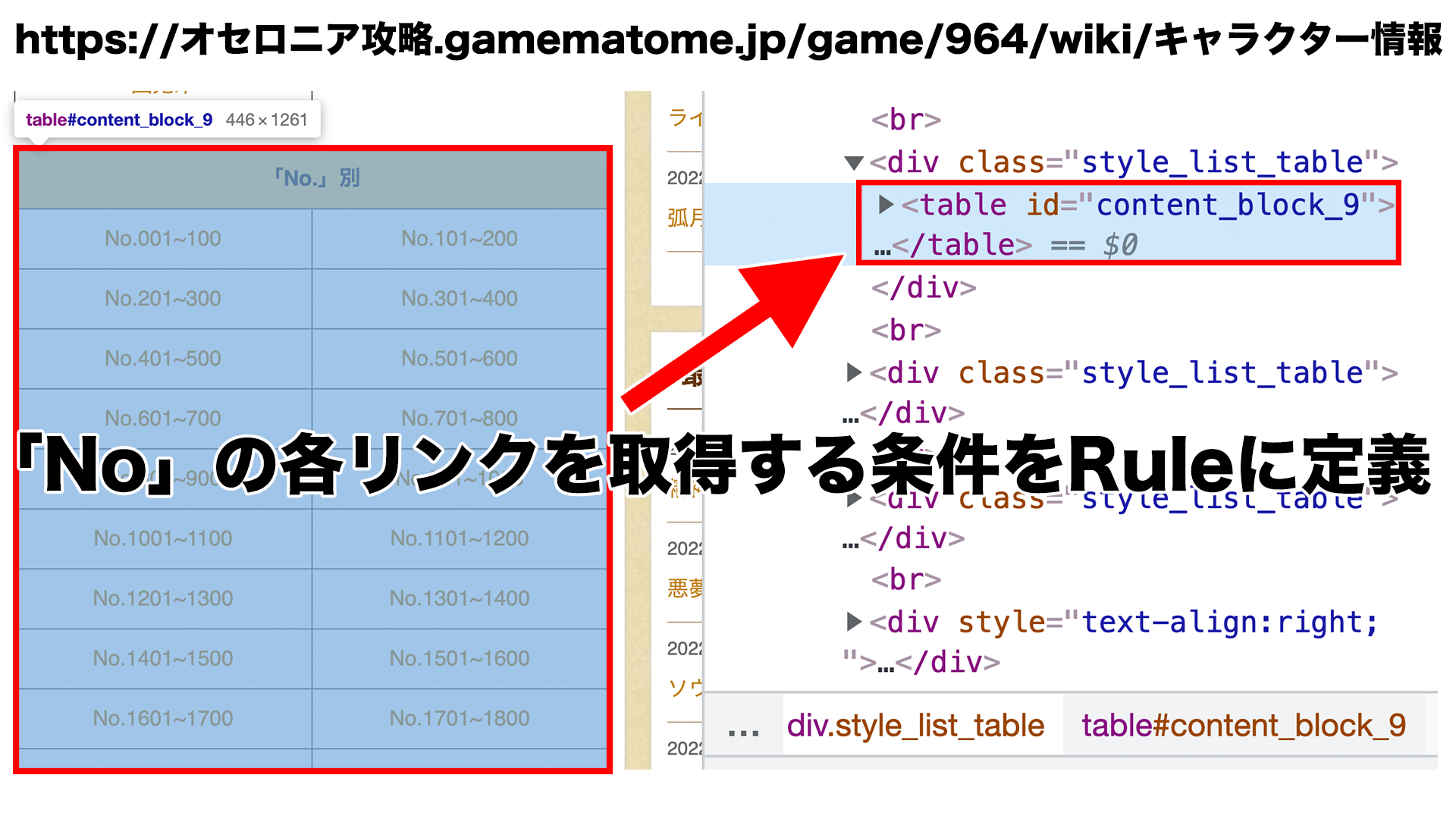
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class CharacterDataSpider(CrawlSpider):
...
rules = (
Rule(
LinkExtractor(restrict_xpaths='//table[@id="content_block_9"]'),
callback='parse_character_data'
),
)
抽出する部分の処理を実装していきます。データ格納先のCharacterDataItemをインポートしておきます。**Ruleで定義したcallback関数(parse_character_data)が呼ばれるので、ここに処理を書いていきます。**responseにはhtml情報が入ってくるので、ChromeのDevToolsで要素を探索しつつコードに起こします。今回であれば、table要素のidがcontent_block_2を探索すれば必要な情報が抜き出せそうです。最後にCharacterDataItemに抽出したデータを詰めてPipelineに処理を渡します。

from scraping_character_data.items import CharacterDataItem
...
def parse_character_data(self, response):
table = response.xpath("//table[@id='content_block_2']")[0]
trs = table.xpath("//tr")[1:]
for tr in trs:
no = tr.xpath(".//td[1]/text()").get()
face_img_url = tr.xpath(".//td[2]/a/img/@src").get()
name = tr.xpath(".//td[3]/a/text()").get()
attribute = tr.xpath(".//td[4]/text()").get()
rarity = tr.xpath(".//td[5]/text()").get()
yield CharacterDataItem(
no=no,
face_img_url=face_img_url,
name=name,
attribute=attribute,
rarity=rarity
)
Pipelineを実装する
pipelines.pyを編集していきます。抽出したデータがPipelineに流れてくるので、ここでデータの保存処理を行います。process_itemの引数itemからデータを取得することができます。今回は取得したデータからファイル名を作り、キャラクターの顔画像を保存することにします。ファイル名は{5桁の図鑑No}_{属性}_{レア度}_{名前}.pngとします。一応scrapyの場合、画像専用のImagesPipelineがあるのですが、内部で勝手にjpeg変換されてしまっているようで、透過画像として保存できなかったので断念しました。ここら辺詳しい方、是非コメントで教えてください。
import scrapy
import requests
import pathlib
class ScrapingCharacterDataPipeline():
def process_item(self, item, spider):
filename = '_'.join([item["no"].zfill(5), item["attribute"], item["rarity"], f'{item["name"]}.png'])
file = pathlib.Path('data', 'face_img', filename)
r = requests.get(item['face_img_url'])
if r.status_code == 200:
with file.open(mode="wb") as f:
f.write(r.content)
スクレイピングの実行
scrapyコマンドで実行します。scrapy crawl <定義したname>で実行できます。
$ scrapy crawl character_data
データを取得する
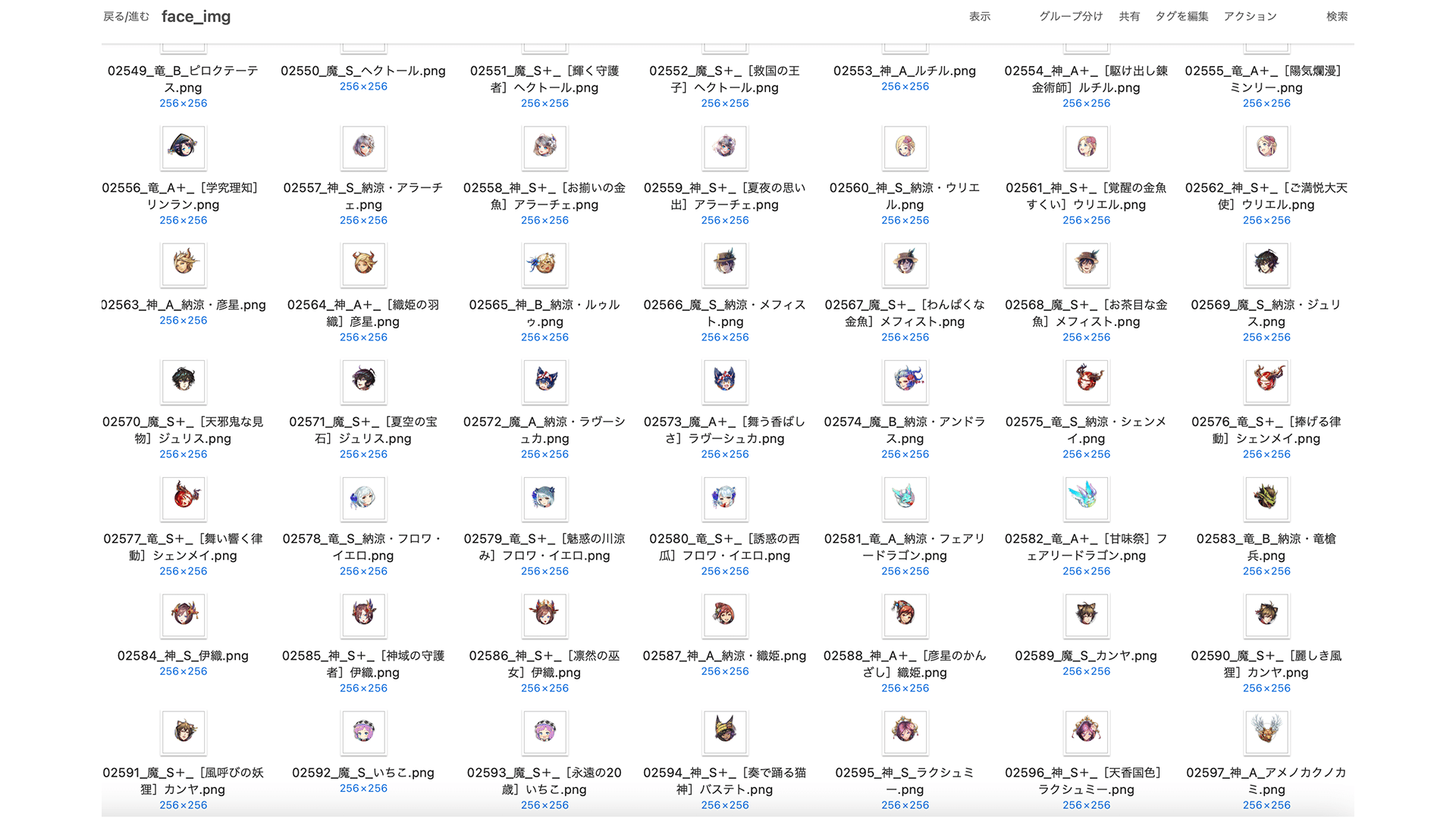
実際にデータを取得してみるとこんな感じ。やったね!これでオセロニアを題材に色々と画像処理を試せるぞい!
おわりに
今回は全キャラクターを対象としましたが、追加された駒だけを対象とするような改修をしたいなと思いました。毎回全件取得していたら、サイトにめちゃくちゃ負担をかけることになりますからね...。
...って、キャラクター情報ページメンテされてないじゃん!No5300までしか乗ってないじゃん!記事記載時ではNo5401〜まであるのに...頼むよkJ〜
参考