概要
- AWS Lambda では、マネージドに提供されている AWS レイヤーがあり、自分でビルドすることなく簡単に利用できる
- AWS SDK for pandas のマネージドな Lambda Leyer には、 pandas / numpy といったデータ処理系のモジュールや aiohttp / requests といった HTTP リクエスト用モジュールなど、様々なモジュールがバンドルされている (一覧は後述)
- AWS Lambda でこれらのモジュールを使用する方法として、多くの記事では Lambda Layer を自作する方法や第三者の公開するレイヤーを利用する方法が記載されているが、上述の Lambda Layer でより簡単かつ安全に実現できる
AWS SDK for pandas とは
AWS SDK for pandas (旧名称: AWS Data Wrangler)は、AWS が開発・公開しているオープンソースの Python ライブラリです。 AWS のデータやデータ分析サービスと pandas の DataFrame とのやり取りを容易にする目的で設計されており、例えば「S3 のデータを直接 pandas の DataFrame として読み書きする」などの操作を最小限のコードで実現できます。
本記事では SDK の詳細には触れません。公式ドキュメント や、下記動画のちょっぴり Deep Dive (資料) が参考になりますので、そちらをご参照ください。
同 SDK を Python 環境にインストールすれば、当該 SDK のモジュールを使うことはもちろん、このモジュールが依存する各種ライブラリも同様に直接利用できます。
そして、この SDK は、AWS Lambda レイヤーのうち、AWS がマネージドに提供する AWS レイヤーとしてもラインナップされています (公式ドキュメントはこちら)。そのため、自分でレイヤーをパッケージングすることなく Lambda 関数に追加できます。
やってみる
Lambda 関数の作成と、Layer 追加前の挙動確認
東京リージョンで、Lambda 関数を作成してみます。
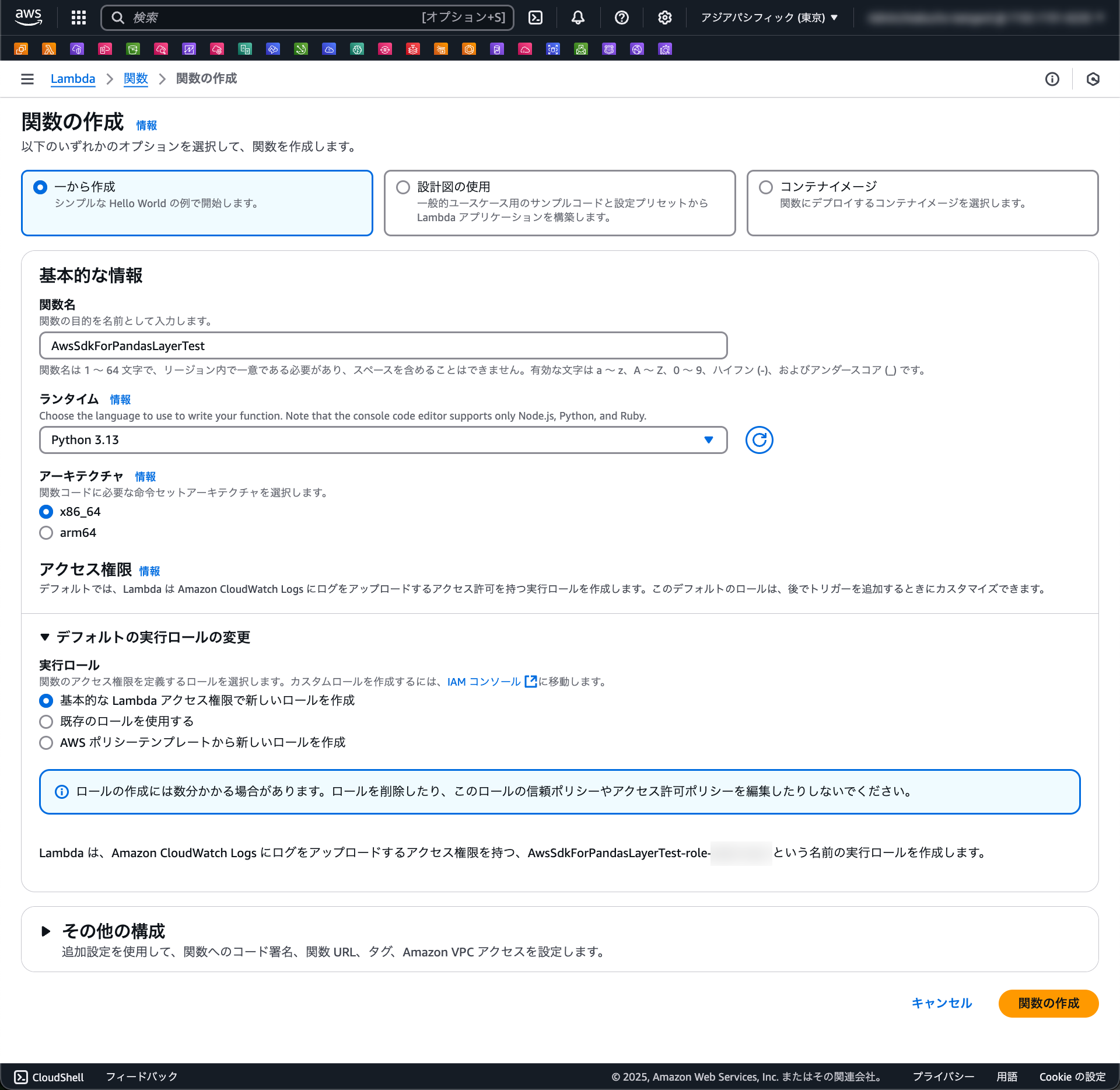
まず、何もレイヤーを追加しない状態で pandas を import して、失敗することを確認してみましょう。最初に作成されるコードに、pandas の import とバージョン表示の 2 行を追加してみます。
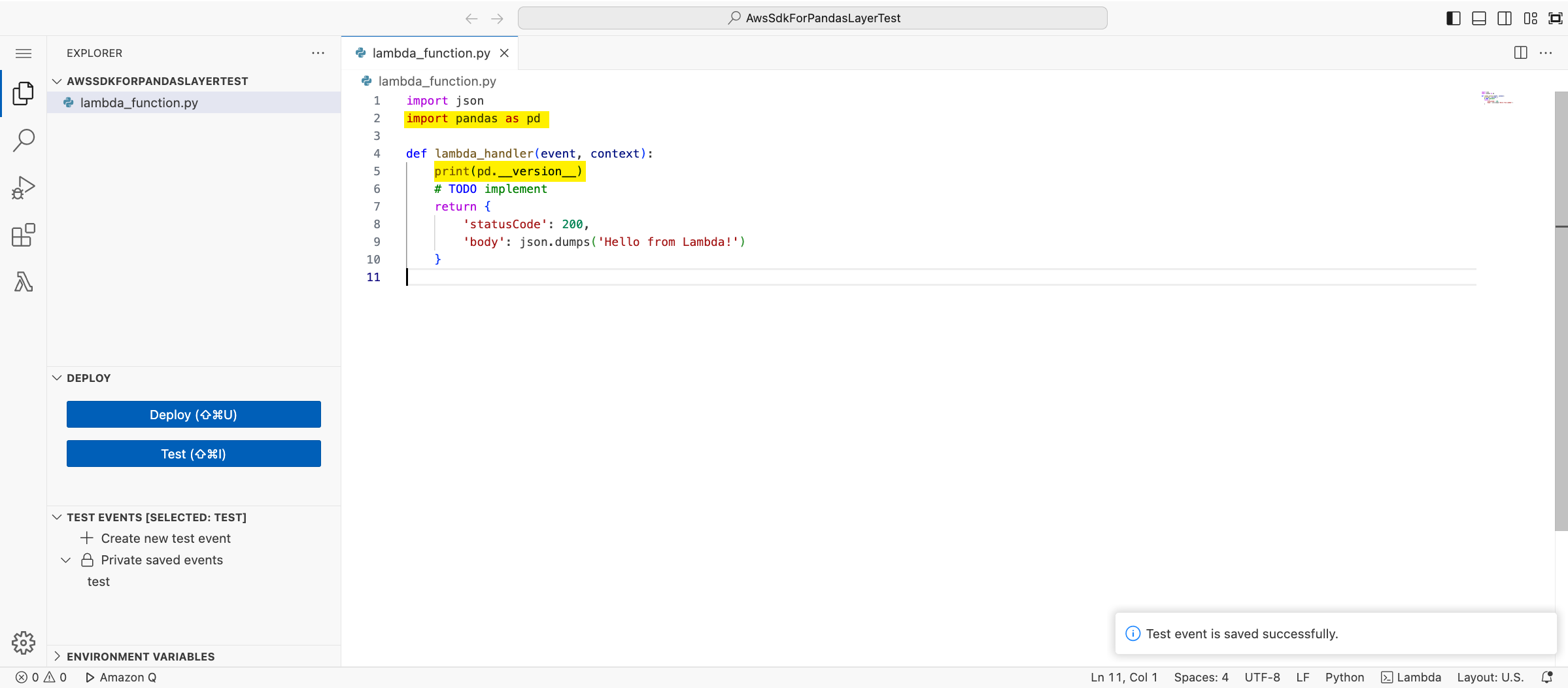
この状態で Lambda 関数の「テスト」タブからテスト実行してみると、pandas が見つからずにエラーになることが確認できます。
AWS SDK for pandas の Lambda Layer 追加
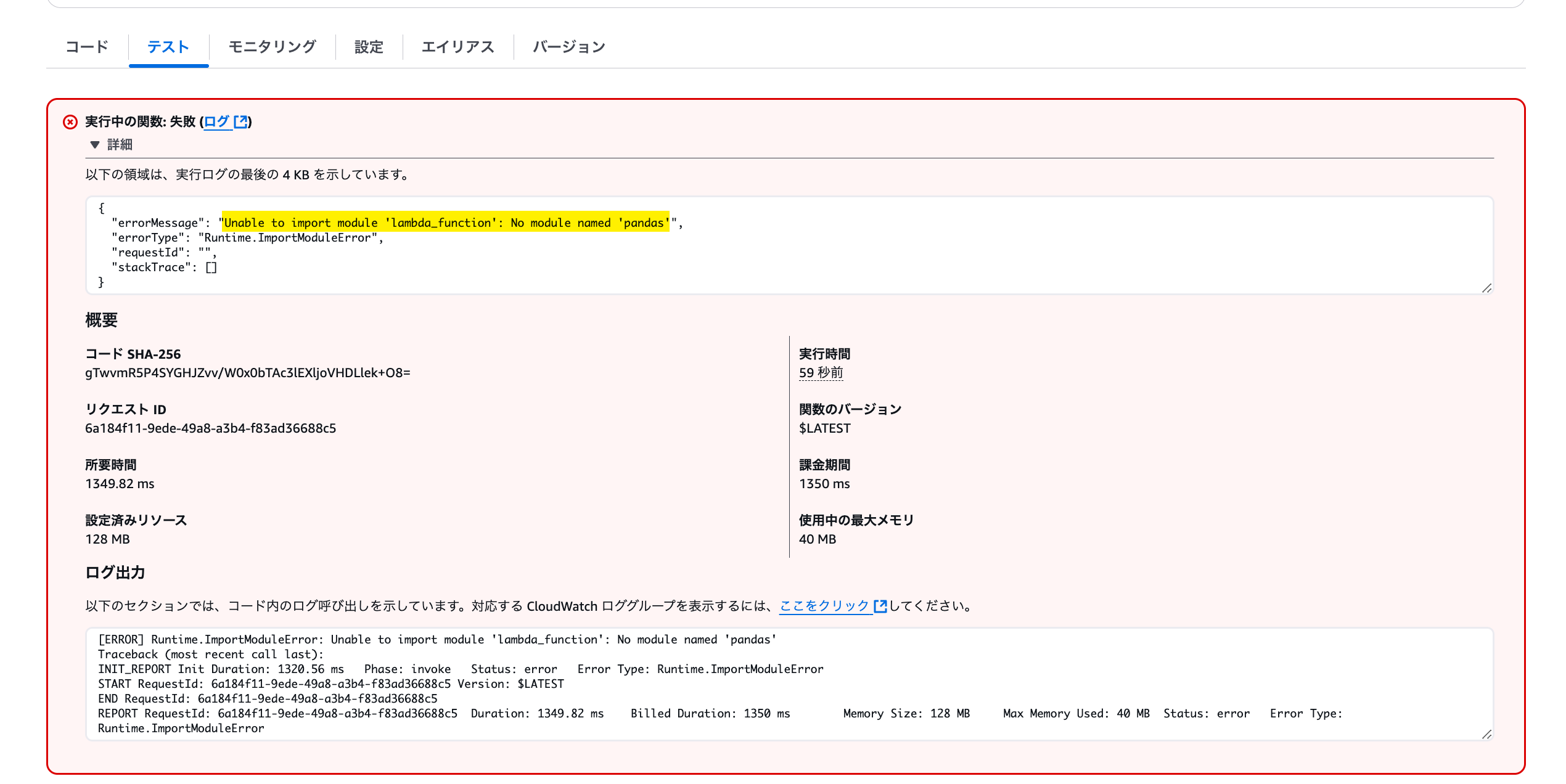
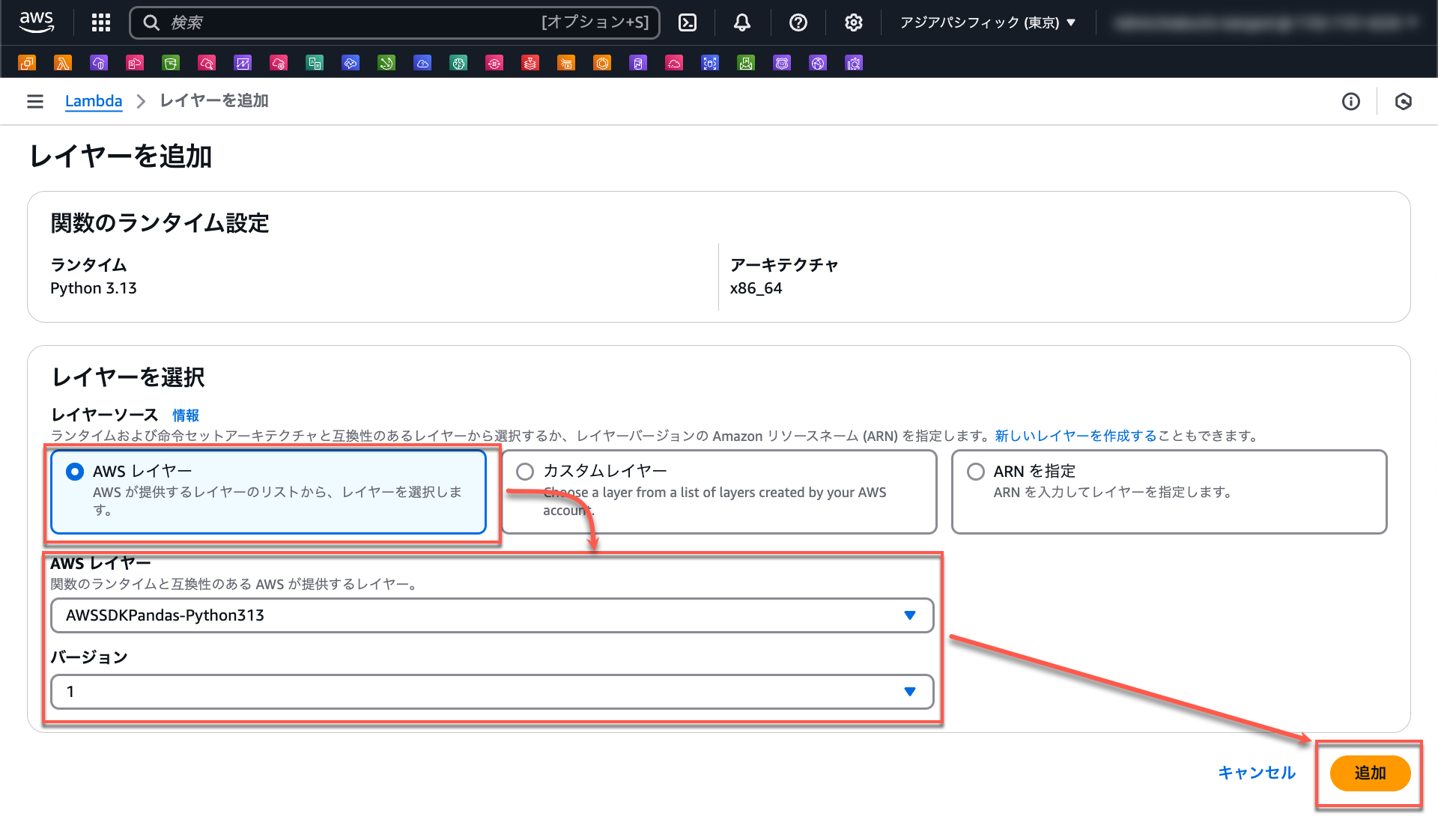
では、AWS SDK for pandas の Lambda Layer を追加してみます。Lambda の「コード」タブに戻り、最下部のレイヤーのセクションで「レイヤーの追加」をクリックします。
追加するレイヤーとして「AWS レイヤー」> 「AWSSDKPandas-Python313」を選択し、バージョンも選択します。「追加」をクリックすると追加完了します。
再び Lambda 関数の「テスト」タブからテスト実行してみると、pandas の import に成功し、pandas が利用可能であることがわかります。
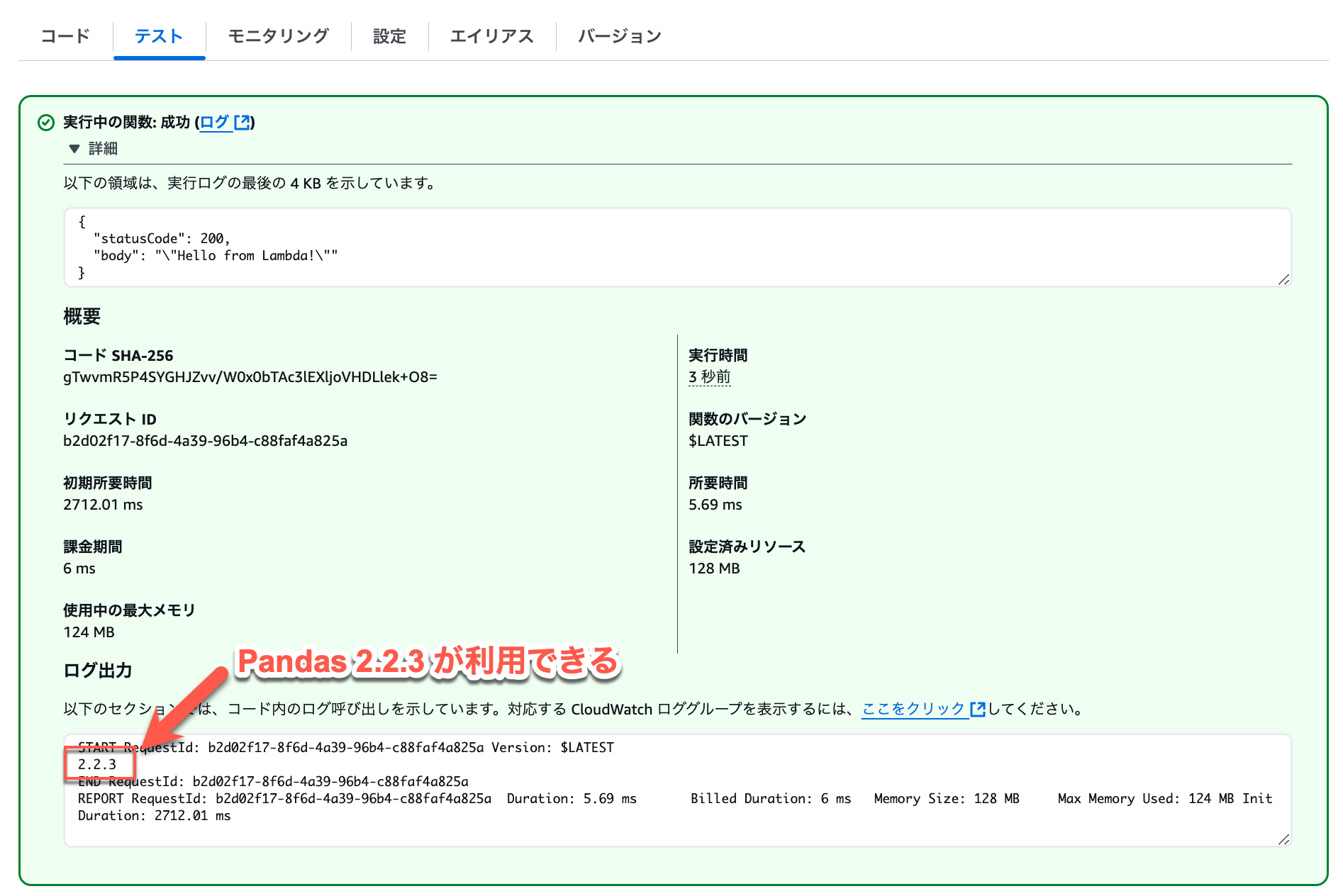
レイヤーを自作するよりもずっと簡単ですし、AWS レイヤーとして提供されているため安心s利用できますね!
参考:含まれているモジュール一覧
2025/02/24 時点で、Python 3.13 版の AWS SDK for Pandas 3.11.0 に含まれるモジュールの一覧は以下の通りです。単にデータ処理系のモジュールだけでなく、 aiohttp や requests といった HTTP リクエスト系モジュールや、スクレイピングモジュールの beautifulsoup4 なども含まれているため、データ処理以外のユースケースでも活用できるかなと思います。
| module_name | version |
|---|---|
| Events | 0.5 |
| PyMySQL | 1.1.1 |
| aenum | 3.1.15 |
| aiohappyeyeballs | 2.4.4 |
| aiohttp | 3.11.11 |
| aiosignal | 1.3.2 |
| asn1crypto | 1.5.1 |
| async-timeout | 4.0.3 |
| attrs | 24.3.0 |
| autocommand | 2.2.2 |
| awswrangler | 3.11.0 |
| backports.tarfile | 1.2.0 |
| beautifulsoup4 | 4.12.3 |
| certifi | 2024.12.14 |
| charset-normalizer | 3.4.1 |
| et_xmlfile | 2.0.0 |
| frozenlist | 1.5.0 |
| gremlinpython | 3.7.3 |
| idna | 3.10 |
| importlib_metadata | 8.0.0 |
| inflect | 7.3.1 |
| isodate | 0.7.2 |
| jaraco.collections | 5.1.0 |
| jaraco.context | 5.3.0 |
| jaraco.functools | 4.0.1 |
| jaraco.text | 3.12.1 |
| jmespath | 1.0.1 |
| jsonpath-ng | 1.7.0 |
| lxml | 5.3.0 |
| more-itertools | 10.3.0 |
| multidict | 6.1.0 |
| nest-asyncio | 1.6.0 |
| numpy | 2.2.1 |
| openpyxl | 3.1.5 |
| opensearch-py | 2.8.0 |
| packaging | 24.2 |
| packaging | 24.2 |
| pandas | 2.2.3 |
| pg8000 | 1.31.2 |
| platformdirs | 4.2.2 |
| ply | 3.11 |
| propcache | 0.2.1 |
| pyarrow | 18.1.0 |
| python-dateutil | 2.9.0.post0 |
| pytz | 2024.2 |
| redshift-connector | 2.1.5 |
| requests | 2.32.3 |
| requests-aws4auth | 1.3.1 |
| scramp | 1.4.5 |
| setuptools | 75.8.0 |
| six | 1.17.0 |
| soupsieve | 2.6 |
| tomli | 2.0.1 |
| typeguard | 4.3.0 |
| typing_extensions | 4.12.2 |
| typing_extensions | 4.12.2 |
| tzdata | 2024.2 |
| wheel | 0.43.0 |
| yarl | 1.18.3 |
| zipp | 3.19.2 |
一覧取得には以下記事のスクリプトを利用させていただきました。
おわりに
私自身、Pandas を Lambda で利用するにはレイヤーを自作しなければならないと思っていました。お客様向けの検証を行うにあたり、もっと楽な方法がないかな?と思って調べたところ、こんなに簡単になっていることに気付きました。知識アップデートって大事ですね。