スクレイピングした文章を形態素解析したい!
nodeではjava用に書かれたkuromojiを移植したkuromoji.jsを使用するのが簡単っぽい。(自分調べ)
しかしWeb上の文字は日々変化し、思ったように解析できない場合も多い。
そこでWeb上の資源を解析して作られている新語・固有表現に強いmecab-ipadic-NEologdという辞書も導入する。
(+ベースはipadic辞書)
- MeCab: Yet Another Part-of-Speech and Morphological Analyzer
- kuromoji - japanese morphological analyzer
- mecab-ipadic-neologd/README.ja.md at master · neologd/mecab-ipadic-neologd
- 日本語形態素解析エンジンKuromojiについて調べた - motacaplaのめう <-概念が分かりやすい👏
環境
- Windows 10, git-bash, MINGW64(素直にlinux使ったほうが簡単です)
- busybox(UNIXコマンド群、後で導入)
- node v12.18.3
- npm v6.14.7
- kuromoji.js v0.1.2
kuromoji.js の導入
kuromoji.jsにはデフォルトで辞書が入っているため、使うだけなら非常に簡単。
サンプルのdicPathを、node_module内の辞書を参照するように変更する。
$ npm install kuromoji
var kuromoji = require("kuromoji");
kuromoji.builder({ dicPath: "node_modules/kuromoji/dict" }).build(function (err, tokenizer) {
// tokenizer is ready
var path = tokenizer.tokenize("すもももももももものうち");
console.log(path);
});
実行すると形態素解析した結果が出力されるはず。
kuromoji-js-dictionary の導入
kuromoji.jsに新しい辞書を追加するには、その辞書をkuromoji用に変換する必要がある。
これを支援してくれるスクリプトがあったので使用させてもらう。
$ git clone https://github.com/sable-virt/kuromoji-js-dictionary.git
$ cd kuromoji-js-dictionaly
$ npm install
windows環境では一部動かないので手作業で修正...
{
"scripts": {
+ "euc": "find ./neologd-seed -name '*.csv' -exec sh -c 'nkf -e --overwrite {}' ';'",
+ "tar": "find ./neologd-seed -name '*.csv' -exec sh -c 'tar -cvzf ./dict/neologd/$(basename {}).tar.gz {}' ';'",
- "tar": "find ./neologd-seed -name '*.csv' -exec sh -c 'tar -cvzf ./dict/neologd/$(basename '{}').tar.gz {}' \\;",
}
}
eucはgitのログを見る限り必要無くなったようだが、npm run convertから消し忘れている様子...。
必要ないか断定できないのでログからリバートした。
また-execコマンドはwindowsでは;で終わらせる必要があるらしいので修正。
ビルドするために他にxzとnkfが必要なので、無い場合は適当に用意しておく。
linux環境ならbrewなどで適当に取ってこれるがwindowsだとこれまた厄介。
xzはbusyboxを使用し、nkfはvictorから適当なものを用意した。
それぞれ--helpコマンドが通れば追加完了。
その他足りないコマンドは各自で。
辞書のコンバート
ここからはレドメ通りなのだが一応記録しておく。
./neologd-seedのディレクトリに使用したい辞書(****.csv.xz)を置いておく。
初めから以下のの辞書が置いてあるので、とりあえずそれを使用する。
- ../dict/mecab-ipadic-2.7.0-20070801.tar.gz (ベースの辞書)
- mecab-user-dict-seed.20180322.csv.xz
- neologd-adjective-verb-dict-seed.20160324.csv.xz
- neologd-common-noun-ortho-variant-dict-seed.20170228.csv.xz
- neologd-noun-sahen-conn-ortho-variant-dict-seed.20160323.csv.xz
# ./dict/neologd に変換した辞書を出力
$ npm run convert
# ./dist に kuromoji.js 用の辞書を出力
$ ./bin/run
All done!!って言われたら完成!
./dictディレクトリを自分のプロジェクトに持ってきて、dicPathを変更すれば完成。
TypeError: Cannot read property 'lookup' of nullは辞書が見つからないエラー。
おま環か分からないが、package.jsonからの相対パスで記載すればOKだった。
新しい辞書の追加(mecab-ipadic-NEologd)
上記では予め用意された辞書を使用したが、NEologdはビルドすることで最新の辞書を作成することができる。(週2更新?)
ただそれはまた大変なので、リポジトリに定期的に保存?されているビルドされた辞書を使用する。
上記URLの ./seed からビルドされた辞書を取得できる。
試しにmecab-user-dict-seed.****.csv.xzという辞書を追加する場合...
この辞書をダウンロードして、./neologd-seedに放り込む。
前回のビルドの残骸(***.csv)が残っている場合、消しておいてもよい。
その後、上記の「辞書のコンバート」の章と同じことをやれば完成だ。
他の辞書もこれと同様の手法で導入できる(はず)。
NEologdの効能
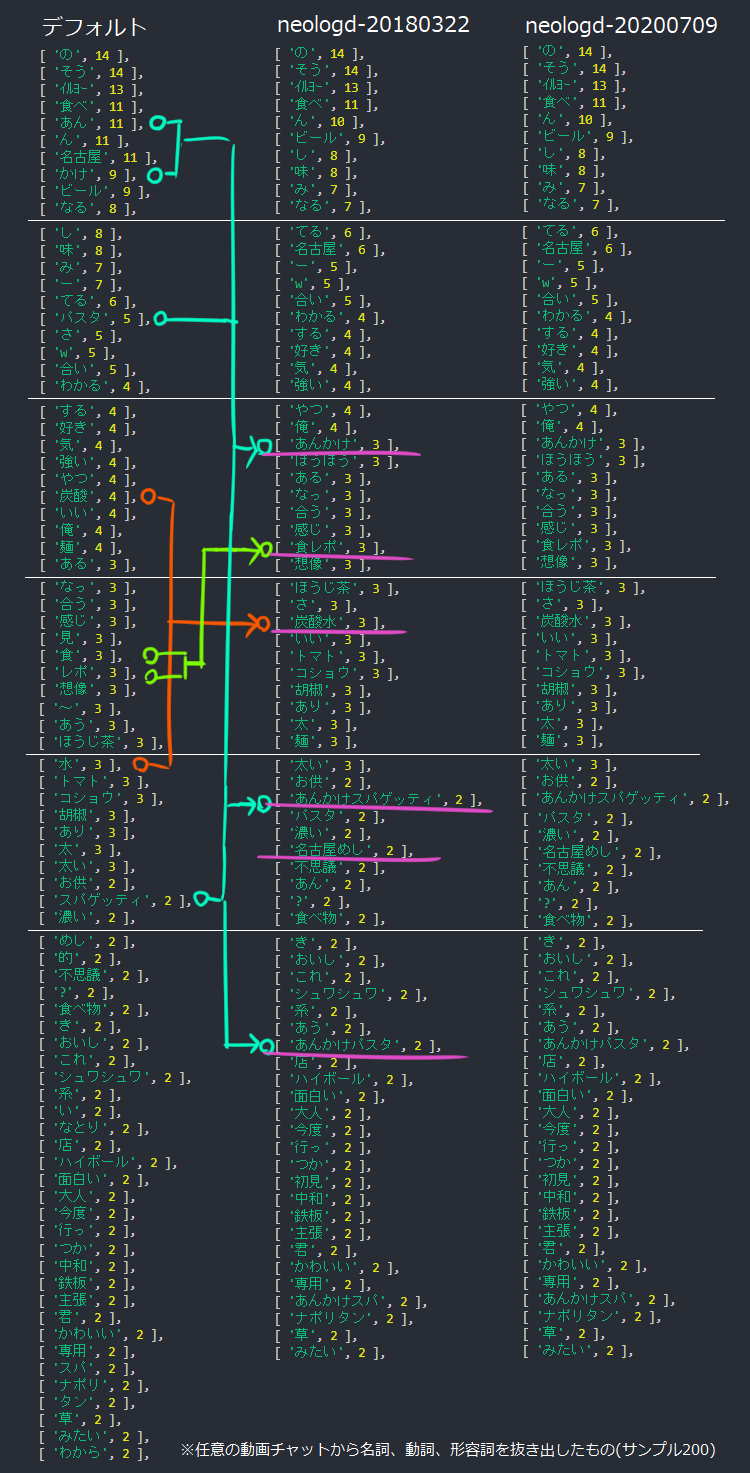
NEologdを今試しているサンプルに適用してみた。
これはある動画のチャット欄から単語として有用な名詞、動詞、形容詞を抽出し、出現数をカウントしたものである。
(ちなみにあんかけパスタを食べているシーンのチャット200件を対象としている)
未適用の状態と比較すると「名古屋めし」や「あんかけパスタ」といういかにもな単語が、ちゃんと1ワードになっていることが確認できた。
2018年版と2020年版は特異な単語が無かったせいか大きな変化は無かった。
よって、Webの情報を処理する際には、NEologdを使用したほうが効果的であろう。
結論
kuromojiとNEologdを使ってどんどん形態素解析してこ!
あとがき:
nodeでゴリゴリ書けるのは非常に助かる。
やろうと思えばブラウザでも実行できるのは強い。
Sudachiってのも試してみたいね。
ぶっっっちゃけスクリプトをnodeで書き直せばこんなに引っかからないよねぇ。
けど、元ソースを読み解くのも面倒なので、環境側を合わせる方針にした。
...WSLを使うのも手か?(まだ触ってないから未知の世界)