本記事の狙い
2020/2に、Oracle Cloud Infrastructure Data Science(OCI-Data Science)がリリースされました。
前回、OCI-Data ScienceからOracle Autonomous Database(ADW)上のデータにクエリしてみたので(Qiita記事:Oracle Cloud Infrastructure Data Scienceを使ってOracle Autonomous Database(ADW)のデータにアクセスしてみる)、本記事では、実際にOCI-Data Scienceを使って、Oracle Cloud Infrastructure Object Storage(OCI-Object Storage)と、AWS S3上のファイルからデータを取得する手順を、実際に実施してみたいと思います。
参考文献
実施に参考になるリンク
- Oracle Cloud Infrastructure Data Science(OCI-Data Science)を使ってみよう
- OCI-Data Science 公式ドキュメント
- Oracle Accelerated Data Science SDK (ADS) 公式ドキュメント(Loading Data)
- Qiita記事:AWSアクセスキー作成
手順
以下のような手順で実施します。
1.OCI-Data Scienceの設定
2.OCI-Object Storage上にファイルをおき、OCI-Data Scienceからアクセスする
3.OCI-Data Science上にファイルををおき、OCI-Data Scienceからアクセスする
4.AWS S3上にファイルをおき、OCI-Data Scienceからアクセスする
1.OCI-Data Scienceの設定
上記参考文献の「Oracle Cloud Infrastructure Data Science(OCI-Data Science)を使ってみよう」を参考にOCI-Data Scienceのノートブック環境を構築、設定をします。
手順とおりに実施すれば、それほど難しくないのでは、と思います。
- Oracle Cloudの基本的な設定の後に、ノートブック環境を構築します。
- getting-started.ipynbを使って、ノートブック環境(JupyerLab)の初期作業を行います。
2.OCI-Object Storage上にファイルをおき、OCI-Data Scienceからアクセスする
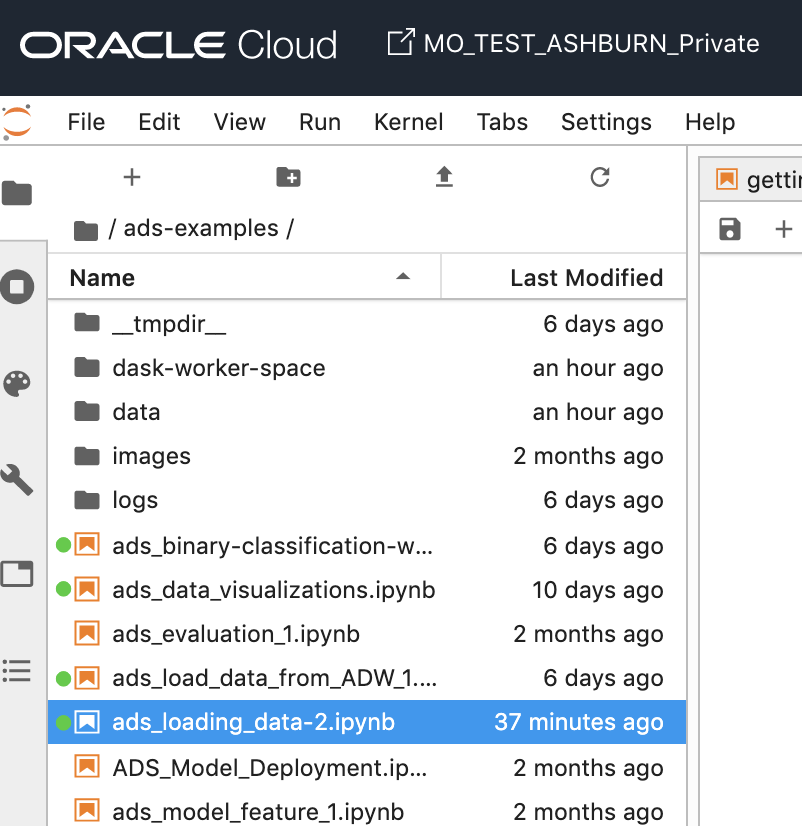
OCI-Data Scienceの中には、/home/datascience/ads-examples 配下のディレクトリに、多くのサンプルノートブックファイルが存在します。
これらサンプルファイルで、基本的な使い方は大体網羅されていますが、今回はその中の一つ、ads_loading_data-2.ipynb というサンプルファイルを使います。
このサンプルノートブックの順序に従ってやれば、大体できるようになっています。
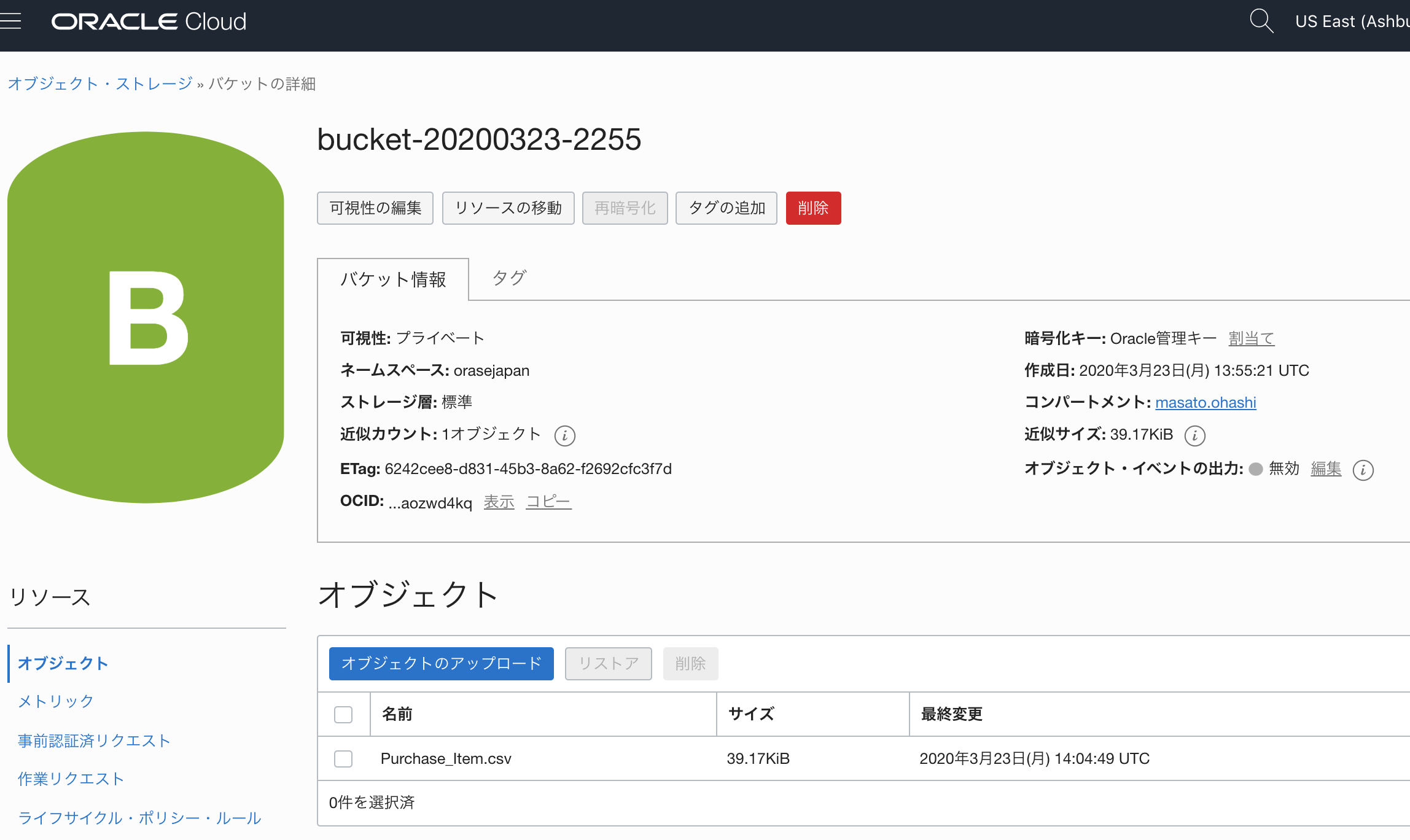
a.OCI-Object Storageにファイルをおく
- 左のナビゲートから、オブジェクト・ストレージを選択します。
- **「バゲットの作成」**ボタンから、バゲットを作成します。(例:bucket-20200323-2255)
- バゲットができたら、**「オブジェクトのアップロード」**ボタンから、ファイルをアップロードします。(例:Purchase_Item.csv)
b.OCI-Data Scienceからファイルにアクセスする
OCI-Data Scienceのノートブック環境から、ads_loading_data-2.ipynb を開きます。
必要なライブラリを読み込みます。
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import logging
logging.basicConfig(format='%(levelname)s:%(message)s', level=logging.ERROR)
from ads.dataset.factory import DatasetFactory
from ads.dataset.dataset_browser import DatasetBrowser
OCI-Object Storageへの接続にあたっては、OCI configuration fileの設定が必要ですが、こちらは、getting-started.ipynbを使って、先に設定しておく必要があります。参考文献の「Oracle Cloud Infrastructure Data Science(OCI-Data Science)を使ってみよう」を参考にOCI-Data Scienceのノートブック環境を構築、設定しておいてください。
実際にOCI-Object Storage上のデータにアクセスしてみます。
OCI-Object Storage上のファイルにアクセスするには、ADSに含まれるDatasetFactory.openを使って、oci://<bucket-name>/<file-name>のように指定します。
以下のように記載します。
ds_oci = DatasetFactory.open("oci://bucket-20200323-2255/Purchase_Item.csv",
storage_options={"config":"~/.oci/config", "profile":"DEFAULT"}, delimiter=",")
以上です。
OCI configuration fileを利用し、CSVファイルをカンマ区切りで読み込んでいます。
正常に取得できたか、確認してみます。
ds_oci.head()
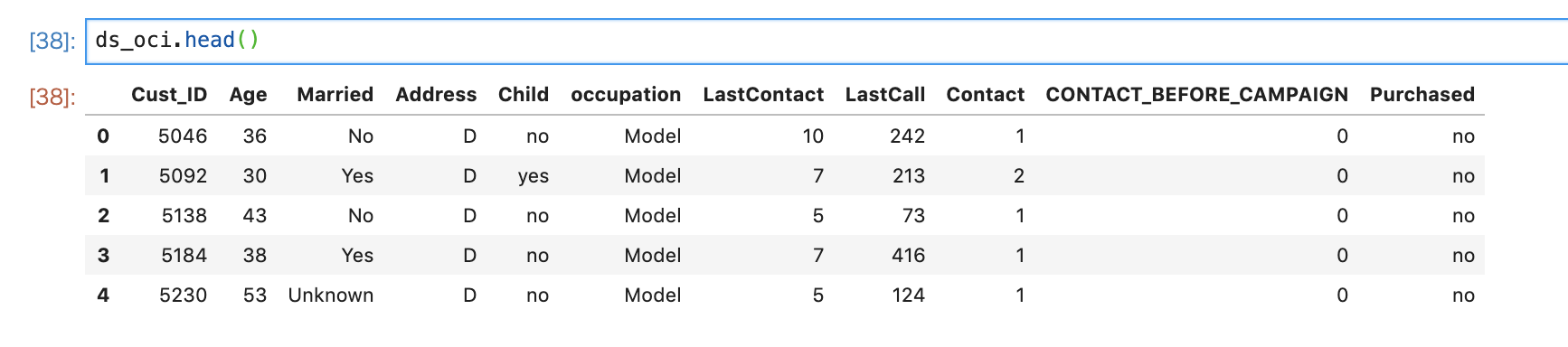
きちんとOCI-Object Storage上のファイルからデータが取得されています。
簡単ですね。
3.OCI-Data Science上にファイルをおき、OCI-Data Scienceからアクセスする
ads_loading_data-2.ipynb の中には、Local File Storageという、OCI-Data Scienceのノートブック環境上にファイルをおいてアクセスする方法も紹介されているのでやってみます。
a.OCI-Data Science上にファイルをおく
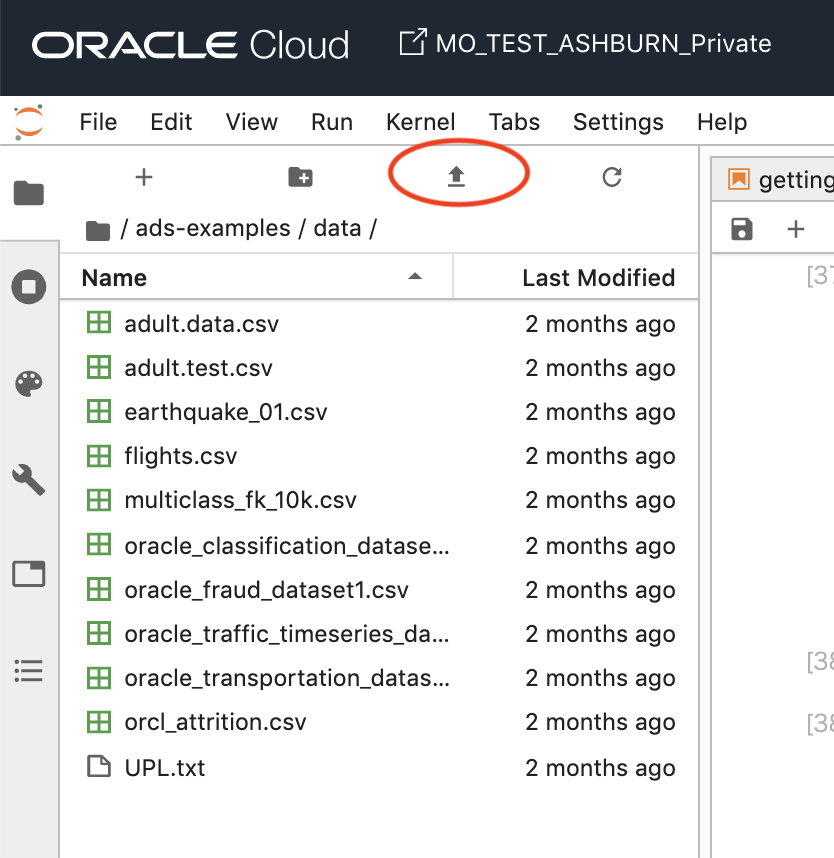
/home/datascience/ads-examples/dataディレクトリ配下には、デフォルトでサンプルデータが置いてあります。
同じようにデータをこのディレクトリ(もしくは適当なディレクトリ)に置きます。ファイルのアップロードには、JupyterLabのアップロードボタンを利用すると便利です。
b.OCI-Data Scienceからファイルにアクセスする
今回はads_loading_data-2.ipynbにあるとおり、/home/datascience/ads-examples/dataディレクトリ配下に、デフォルトで存在するサンプルデータを利用します。
この場合も、ADSに含まれるDatasetFactory.openを使って、以下のように記載します。
ds_ocids = DatasetFactory.open("/home/datascience/ads-examples/data/multiclass_fk_10k.csv")
確認してみます。
ds_ocids.head()
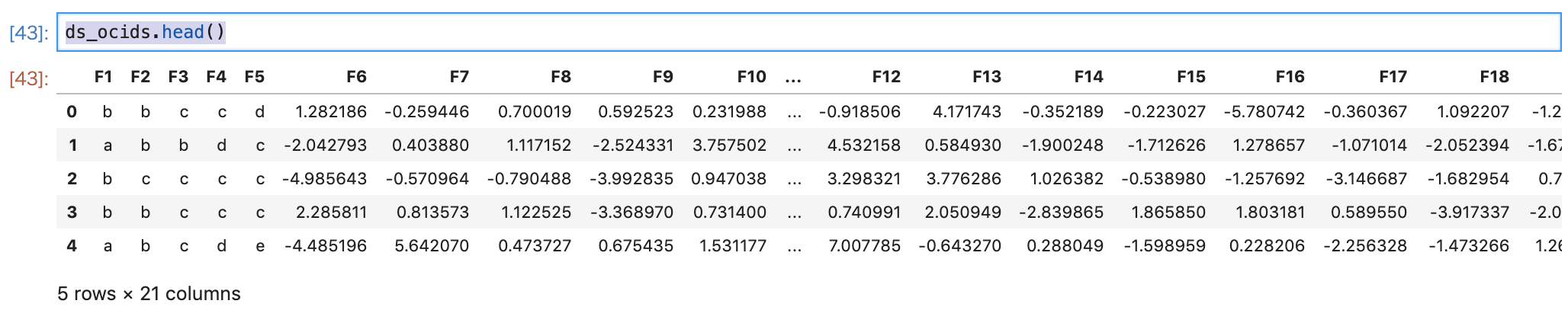
うむ。
難しくないですね。
c.OCI-Data Science上に新規ファイルを作成し、データをロードする
今度は逆に、Notebook上のデータを使って、OCI-Data Science上のノートブック環境に新規ファイルを作成し、上記で使用したds_ocidsのデータをロードしてみます。
この場合は、ADSDatasetに含まれる、to_csv()メソットを利用します。
import os
# Generate CSV of our data
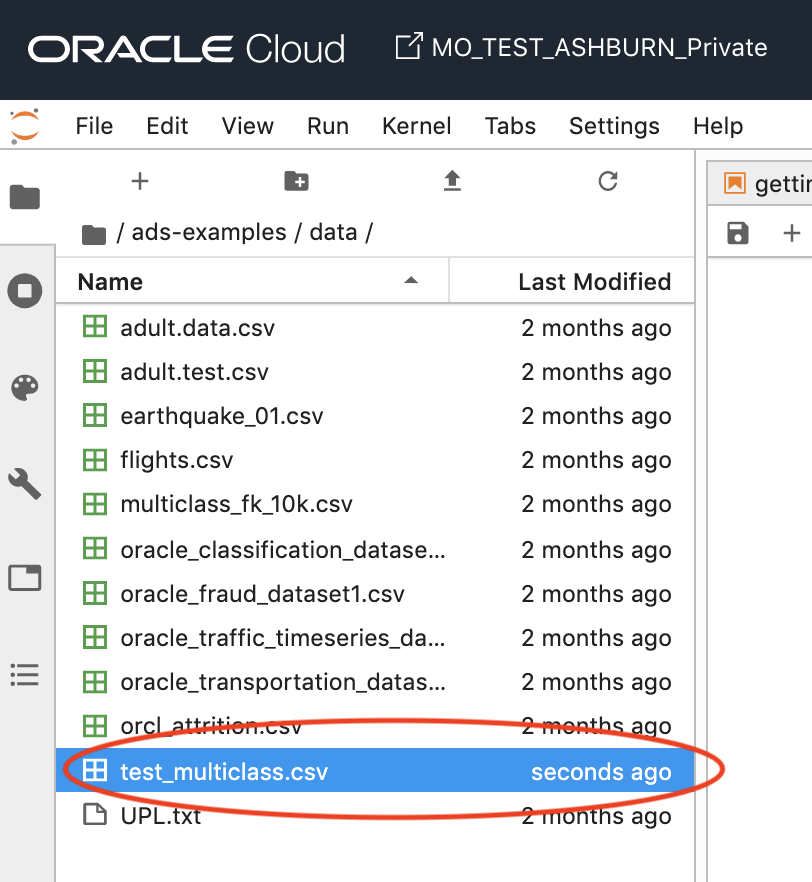
[ds_link] = ds_ocids.to_csv("./data/test_multiclass.csv")
確認します。
確かに新規ファイルが作成され、データがファイルにロードされていますね。
4.AWS S3上にファイルをおき、OCI-Data Scienceからアクセスする
次に、AWS S3上のデータに、OCI-Data Scienceからアクセスしてみます。
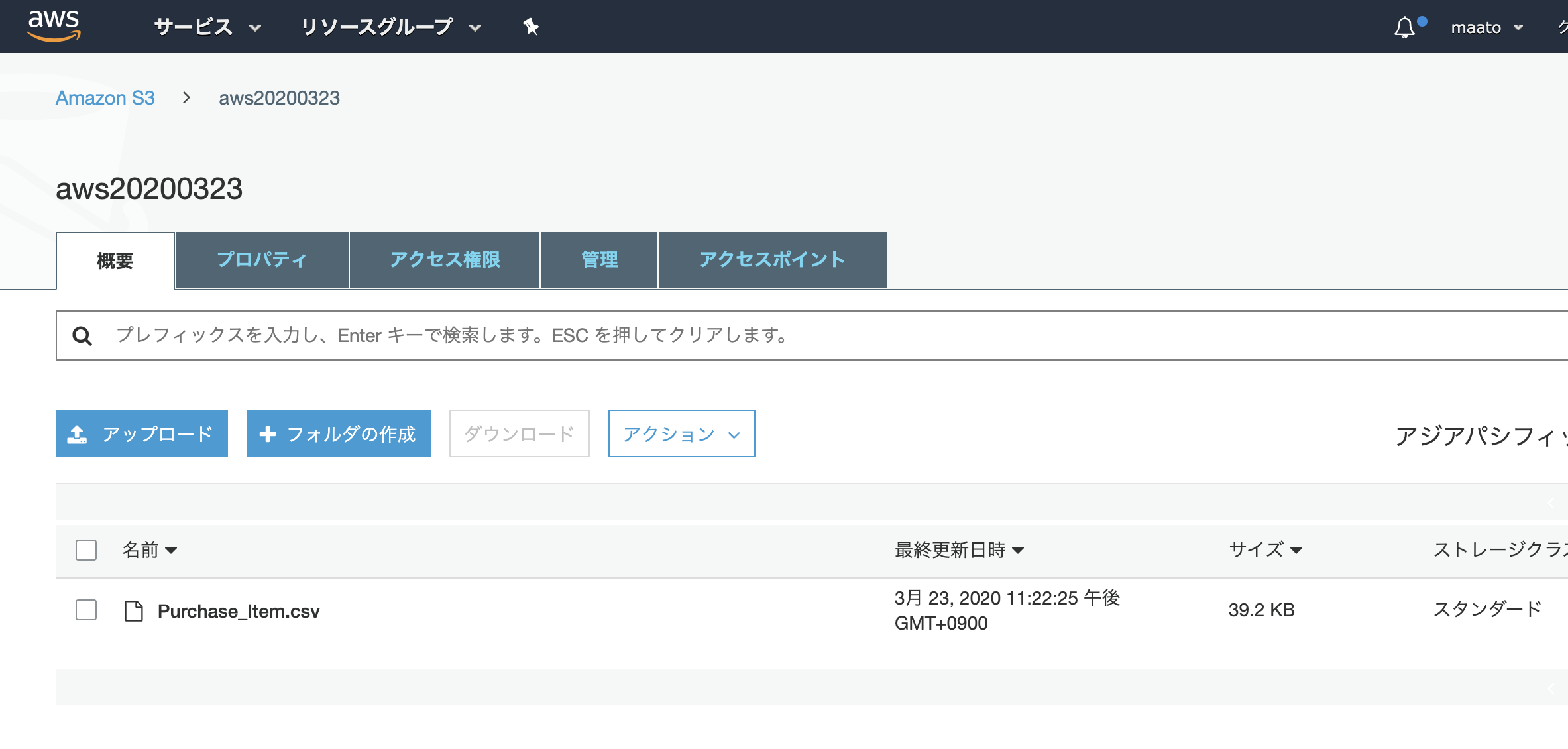
a.AWS S3にファイルをおく
- S3上にバゲットを作成し、ファイルをアップします。
OCI-Data Scienceからアクセスするには、アクセスキーID、シークレットアクセスキーが必要となります。
**参考文献「AWSアクセスキー作成」**を参考にしながら、以下を実施します。
- グループ作成
- ユーザー作成
- アクセスキーID、シークレットアクセスキーIDの確認
また、バケットへのエンドポイントURLを確認しておきます。S3上のファイル詳細のオブジェクトURLに記載あります。(もっといい確認方法があるかもしれません、、、)
例:https://<バケット名>.s3-ap-northeast-1.amazonaws.com
b.OCI-Data Scienceからファイルにアクセスする
AWS S3上のファイルにアクセスする場合も、OCI-Object Storageと同様に、ADSに含まれるDatasetFactory.openを使って、oci://<bucket-name>/<file-name>のように指定します。
以下のように記載します。
aws_key = '<上記で確認したアクセスキーID>'
aws_secret = '<上記で確認したシークレットアクセスキーID>'
ds_s3 = DatasetFactory.open("s3://<バケット名>/<ファイル名>", storage_options = {
'key': aws_key,
'secret': aws_secret,
'client_kwargs': {
"endpoint_url": "<エンドポイントURL>"
}
})
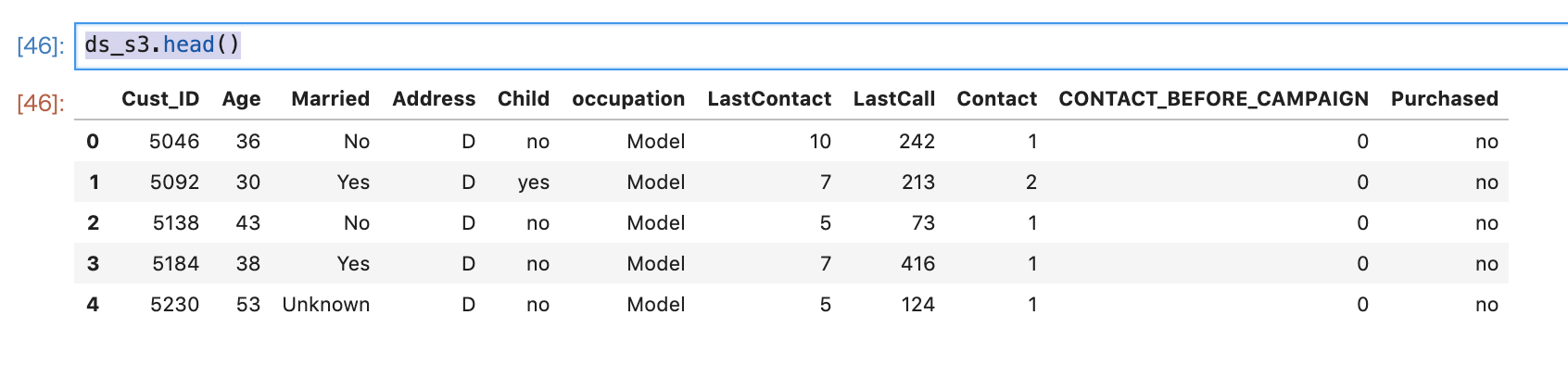
確認してみます。
ds_s3.head()
確かに、無事取得できました。
これでAWS S3上のデータを使って、OCI-Data Science上でデータ分析を実施したり、OCI-Object StorageとAWS S3上のデータを結合してOCI-Data Scienceで利用したり、分析の幅が広がりますね。
終わりに
今回は、OCI-Data Scienceにサンプルとして含まれる、ads_loading_data-2.ipynb をベースに、OCI-Data Scienceから、OCI-Object Storageと、AWS S3上のファイルにアクセスし、データを取得してみました。
またこの方法以外にもADSを使って、様々なデータソースからデータを取得する方法が、サンプルノートブックや、ADSのドキュメントの「Loading Data」に記載しているので参考にしてみてください。
OCI-Data Scienceは、最大30日間300$分の無償クレジットが使えるOracle Free Trialの、対象サービスですので、ぜひ実際に使ってみることをおすすめします。