本記事の狙い
2020/2に、Oracle Cloud Infrastructure Data Science(OCI-Data Science)がリリースされました。
前回、OCI-Data ScienceからAWS S3上のファイルのデータにクエリしてみたので(Qiita記事:Oracle Cloud Infrastructure Data Scienceを使って、OCI Object StorageとAWS S3のファイルデータにアクセスしてみる)、本記事では、OCI-Data Scienceから、Pythonを使ってAWS Redshift上のデータにアクセスしてデータ取得する手順を、実施してみたいと思います。
参考文献
実施に参考になるリンク
- Oracle Cloud Infrastructure Data Science(OCI-Data Science)を使ってみよう
- OCI-Data Science 公式ドキュメント
- Oracle Accelerated Data Science SDK (ADS) 公式ドキュメント
- Qiita記事:Redshiftをはじめて触ってみた!
- Amazon Redshiftって何ができるの?AWSのデータウェアハウスサービスを解説
- Redshiftからデータ読み込んでpandasのデータフレームに入れる
- Qiita記事:リモートのpython3(psycopg2)からubuntu16.04@AWSのpostgresqlに接続
手順
以下のような手順で実施します。
1.OCI-Data Scienceの設定
2.Redshiftを起動し、テーブル作成、データを登録
2-1.Redshiftのクラスタ作成、起動
2-2.Redshiftにテーブル作成、S3にファイルから、テーブルにデータを登録
3.OCI-Data ScienceからRedshiftのテーブルにアクセスする
1.OCI-Data Scienceの設定
OCI-Data Scienceのノートブック環境を構築、初期設定をします。
上記参考文献の「Oracle Cloud Infrastructure Data Science(OCI-Data Science)を使ってみよう」を参考に下記を実施します。
・Oracle Cloudの基本的な設定の後に、ノートブック環境を構築します。
・getting-started.ipynbを使って、ノートブック環境(JupyerLab)の初期作業を行います。
2.Redshiftを起動し、テーブル作成、データを登録
2-1.Redshiftのクラスタ作成、起動
上記参考文献の「Qiita記事:Redshiftをはじめて触ってみた!」を参考にRedshiftクラスタを作成しました。
2-2.Redshiftにテーブル作成、S3にファイルから、テーブルにデータを登録
今回は、上記参考文献の「Amazon Redshiftって何ができるの?AWSのデータウェアハウスサービスを解説」の” Amazon Redshiftを使ってみる”を参考に、IAMロールの作成、Redshift上にテーブルを作成、S3上のcsvファイルからRedshift上のテーブルにデータを登録、の手順でデータを登録しました。
今回は下記のテーブルを作成し、サンプルデータを登録しています。
CREATE TABLE PURCHASE_ITEM (
CUST_ID integer,
AGE integer,
MARRIED VARCHAR(4000),
ADDRESS VARCHAR(4000),
CHILD VARCHAR(4000),
OCCUPATION VARCHAR(4000),
LASTCONTACT VARCHAR(4000),
LASTCALL integer,
CONTACT integer,
CONTACT_BEFORE_CAMPAIGN integer,
Purchased VARCHAR(4000)
);
3.OCI-Data ScienceからRedshiftのテーブルにアクセスする
では、実際に、OCI-Data ScienceからRedshiftのテーブルにアクセスしてみます。
今回は、上記参考文献の「Redshiftからデータ読み込んでpandasのデータフレームに入れる」のとおりに、sqlalchemy-redshiftを利用します。
まず、モジュールsqlalchemy-redshiftをインストールします。
pip install sqlalchemy-redshift
次に必要なライブラリをインストールします。
import redshift_sqlalchemy
from sqlalchemy import create_engine
Redshiftに接続します。
engine = create_engine('{dialect}+{driver}://{user}:{pwd}@{url}:{port}/{db}'.format(
dialect = 'redshift',
driver = 'psycopg2',
user='awsuser', #Redshiftのユーザー名
pwd ='XXXXXX', #パスワード
url='redshift-cluster-1.XXX.XXX.redshift.amazonaws.com', #Redshiftのクラスター画面のエンドポイント
port=5439, #Redshiftのポート番号
db='dev' #Redshiftのデータベース名
))
ここで下記のようなConnection timed outエラーが発生しました。
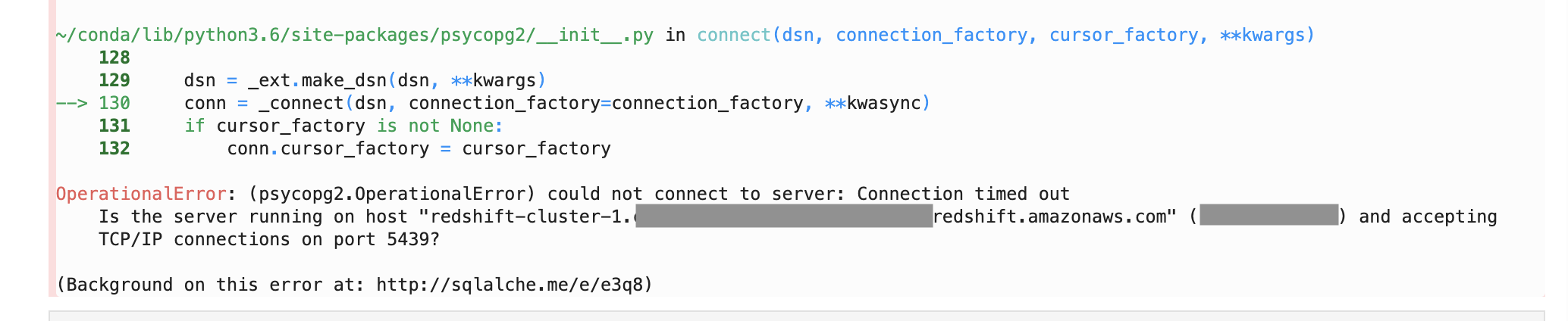
調べたところ、上記参考資料「リモートのpython3(psycopg2)からubuntu16.04@AWSのpostgresqlに接続」と同じようにみえるので、RedshiftのVNCセキュリティグループのインバウンドルールを下記のように設定します。
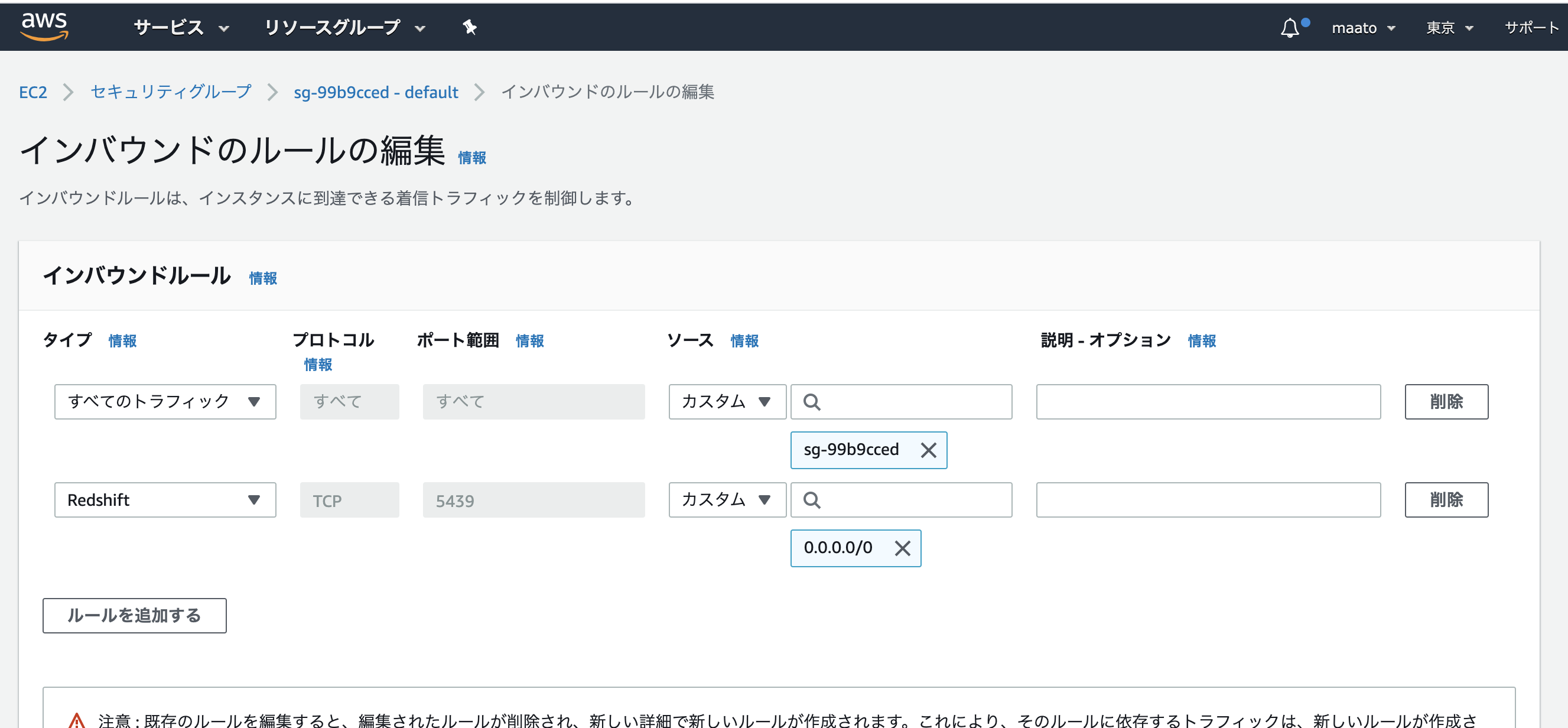
*今回は「0.0.0.0/0」を設定しましたが、実際の設定に関しては適切な値を設定してください。
*ここらへん、あまり自信ないので間違っていたらご指摘ください。。
セキュリティグループを設定後は、正常に接続できました。
Redshift上のデータを読み込み、データフレームに入れます。
import pandas as pd
redshift_data = pd.read_sql_query('SELECT * FROM PURCHASE_ITEM limit 100;', engine)
結果を確認してみます。
redshift_data.head()

確かに、無事取得できました。
終わりに
今回は、OCI-Data Scienceから、sqlalchemy-redshift を使って、AWS Redshift上のデータにアクセスしてみました。
これ以外にもう少しいい接続方法があるかもしれませんので、ぜひ試してみてください。(そして教えてください。。)
OCI-Data Scienceは、最大30日間300$分の無償クレジットが使えるOracle Free Trialの、対象サービスですので、ぜひ実際に使ってみることをおすすめします。