今まで大量のクエリをチューニングしてきた中で、selectivity(選択度)の理解がとても大事だなと感じているので、今回はselectivityについて書きます。
※以降の話は、「いろいろと例外はあるけど、基本的にはこうなることが多い」という経験に基づいてお話しますので、様々な場面において例外があり、すべてのクエリのパフォーマンスをカバーできるわけではありません。ただ、「基本的にはこうなる」ということを理解することで、今までと違う視点でSQLの読み書きをできるようになるきっかけを提供できたらなという想いで書きます。
※筆者はSQL Serverを使いますので、実行プランはSQL Serverのものが出てきますが、selectivity自体はベンダに依存せずに使える知識です。
クエリのパフォーマンス要件
全てのクエリを限界まで速くする必要はありません。
■ 限界まで高速に
・WEBサービス上のユーザー操作によって実行されるクエリ
※ここでもユーザーのアクセス回数によってどの程度シビアに考えるべきかは変わってくる
(例:サイトTOPと特定のページとでは、実行回数が大きく変わるためサイトTOPのほうがシビア)
■ ほどほどの待ち時間は許容でき、タイムアウトせずに結果が返ってくればOK
・単発のデータ抽出
■ 要件次第では数時間実行でもOK
・バッチ処理
・APIによるデータ連携
僕はクエリチューニングを依頼された際に「どんな場面で、どういった頻度で実行されるのか」を最初に聞くことにしていますが、これはなんとなくの速度要件をはじめに把握しておきたいためです。
高速なクエリとは
高速なクエリ = 低IO = [selectivityの良い検索述語 + 適切なインデックス]
→片方だけだとパフォーマンスは出ない
selectivity:選択率 / 選択性 と訳される。行をどれだけ絞り込めるかの指標
selectivityが良い:少ないレコードに絞り込みできること。selectivityの良さはクエリパフォーマンスに直結する
※本来はselectivityが高い/低いと表現するが、少ないレコードに絞り込めることを「高い」と表現する説と「低い」と表現する説がありわかり辛いため、単に「良い」と表現する
検索述語:WHERE句の各条件のこと
適切なインデックス:張ることでIOを劇的に削減できるインデックスのこと
selectivityを調べてみよう
以下の会員情報テーブルをサンプルとして使用します。このテーブルに1000万レコード入っているものとします。
CREATE TABLE [Member](
[MemberID] [int] NOT NULL,
[GenderID] [int] NULL,
[Zipcode] [varchar](8) NULL,
[TodoufukenID] [int] NULL,
CONSTRAINT [PK_Member] PRIMARY KEY CLUSTERED
(
[MemberID] ASC
))
■ クエリA
select
*
from Member
where MemberID = 1
→実行したところ、1レコードとれた
■ クエリB
select
*
from Member
where GenderID = 2 --1:Male 2:Female NULL:Unknown
→実行したところ、500万レコードとれた
ここで、selectivityの概念を使って2つのクエリを評価すると、以下のようになります。
クエリA:「MemberID = 1という検索述語は、Memberのレコードを1000万から1レコードまで、劇的に絞り込むことができるため、selectivityがとても良い」
クエリB:「GenderID = 2という検索述語は、Memberのレコードを1000万から500万レコードまでしか絞り込めず、selectivityは悪い」
ポイント:主キーやユニークキーは、selectivityが最も良い。
参考:「selectivityが良い」とは、レコード全体の5%程度まで絞り込めるかどうかと言われている
https://www.amazon.co.jp/dp/4774173010/ (302ページより)
■ クエリC
select *
from Member
where GenderID = 2
and Zipcode = '123-4567'
→実行したところ、100レコードとれた
クエリC:「GenderID = 2 and Zipcode = '123-4567'という検索述語は、Memberテーブルのレコードを1000万レコードから100レコードまで、劇的に絞り込むことができるため、selectivityが良い」
ポイント:複数の検索述語もひとまとめで考えてOK
■ クエリD
select *
from Member as A
join MemberAdditional as B on A.MemberID = B.MemberID
where A.GenderID = 2
and A.Zipcode = '123-4567'
and B.RegistDate between '2018/01/01' and '2018/12/31'
→30レコード
ここで、Memberテーブルと1:1の関係を持つテーブルMemberAdditional(1000万レコード)を追加します。2テーブルのJOINを含むクエリを実行したところ、30レコードとれました。
クエリD:「A.GenderID = 2 and A.Zipcode = '9010222' and B.RegistDate between '2018/01/01' and '2018/12/31'という検索述語は、レコードを1000万レコードから30レコードまで、劇的に絞り込むことができるため、selectivityが良い」
***→NG。***複数テーブルの検索述語が存在する場合、selectivityはテーブル単位で評価する(理由は後述)

クエリDのselectivityの評価結果

ポイント:複数テーブルのJOINを含むクエリでは、selectivityが良い検索述語が1つ以上存在すれば、クエリ全体としてパフォーマンス面のポテンシャルが高いとの判断が可能 (理由は後述)
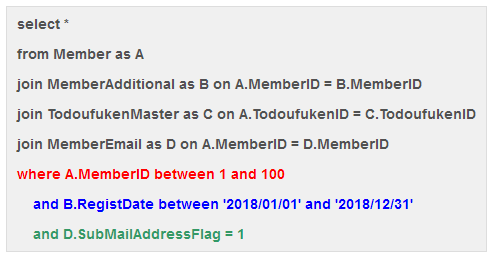
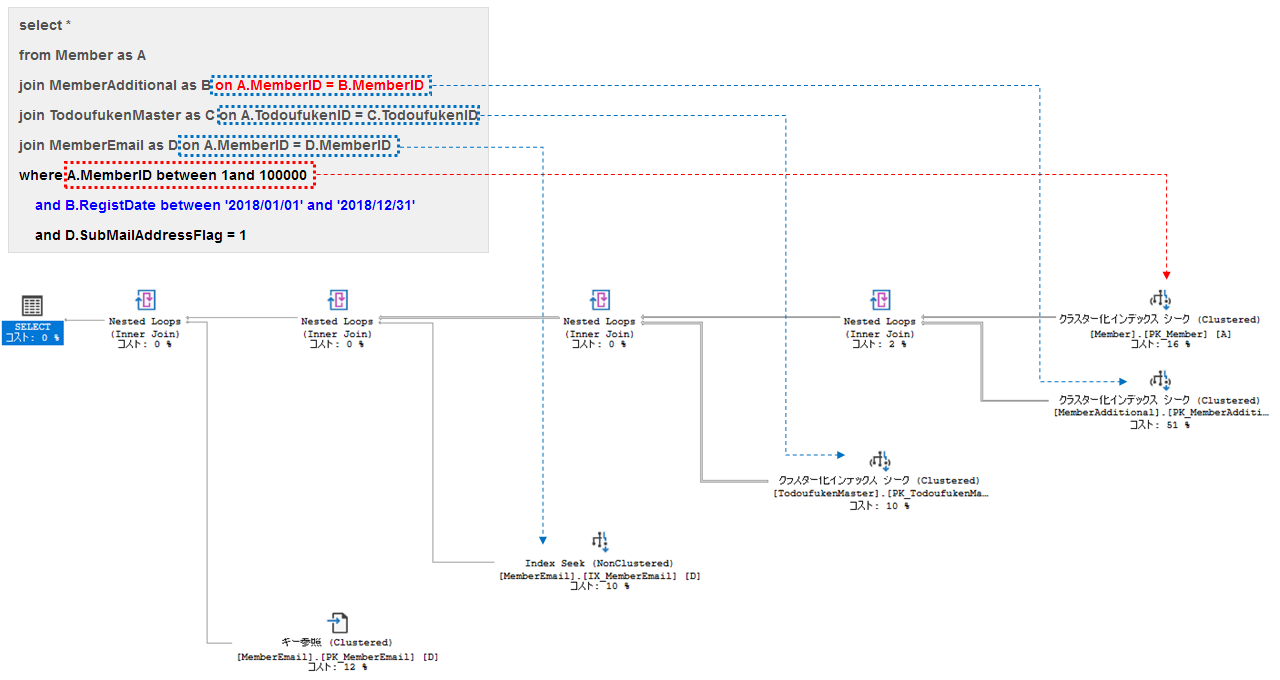
■ クエリE (より複雑なクエリ)

クエリEのselectivityの評価結果

→パフォーマンス面のポテンシャルが高いクエリだが、実際に実行すると遅い(=適切なインデックスが無い)
※MemberEMail / TodoufukenMasterという2テーブルを追加します。それぞれ会員のメールアドレスを持った2000万レコードのテーブルと、都道府県情報を持った47レコードのマスタテーブルとします。
ポイント:selectivityが良いだけでは不十分(=ポテンシャルが高いだけ)で、適切なインデックスが作成されることではじめて高速になる
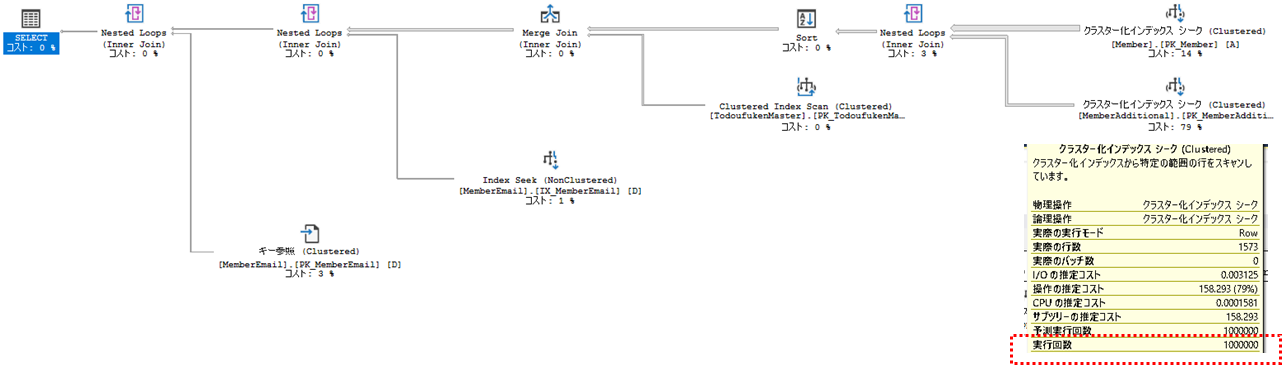
クエリCと同等のselectivityのクエリと速度比較
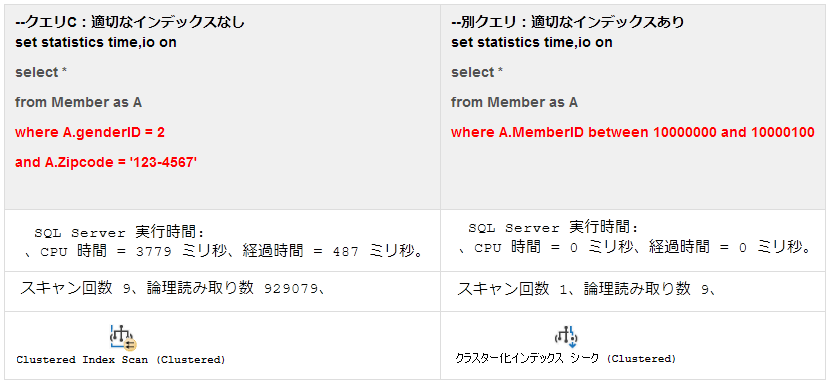
結果行数はほぼ同一のクエリだが、実行時間およびCPU負荷にかなりの差がある。適切なインデックスの有無によるもの。
クエリCに適切なインデックスを作成することで、上記の高速なクエリと同等のパフォーマンスを得ることが可能
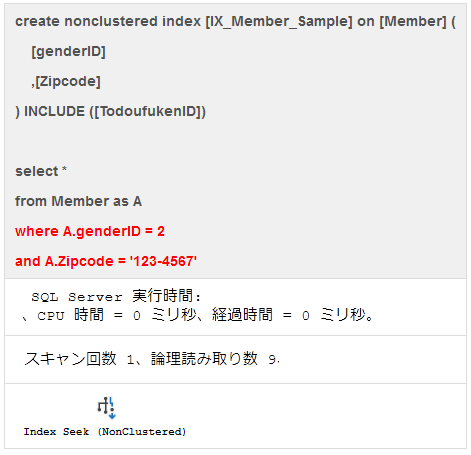
ポイント:selectivityの良い検索述語の組み合わせでインデックスを作ることで、「適切なインデックス」を作成できる。
→状況に応じて付加列を追加してカバリングインデックスを作成しても良い。
selectivityと実行プランの関係性
「複数テーブルのJOINを含むクエリでは、selectivityが良い検索述語が1つ以上存在すれば、クエリ全体としてパフォーマンス面のポテンシャルが高いとの判断が可能」
→何故か?クエリの実行過程をみていくと説明できる
■ クエリF
このクエリは超高速。実行プランは以下のようになる。
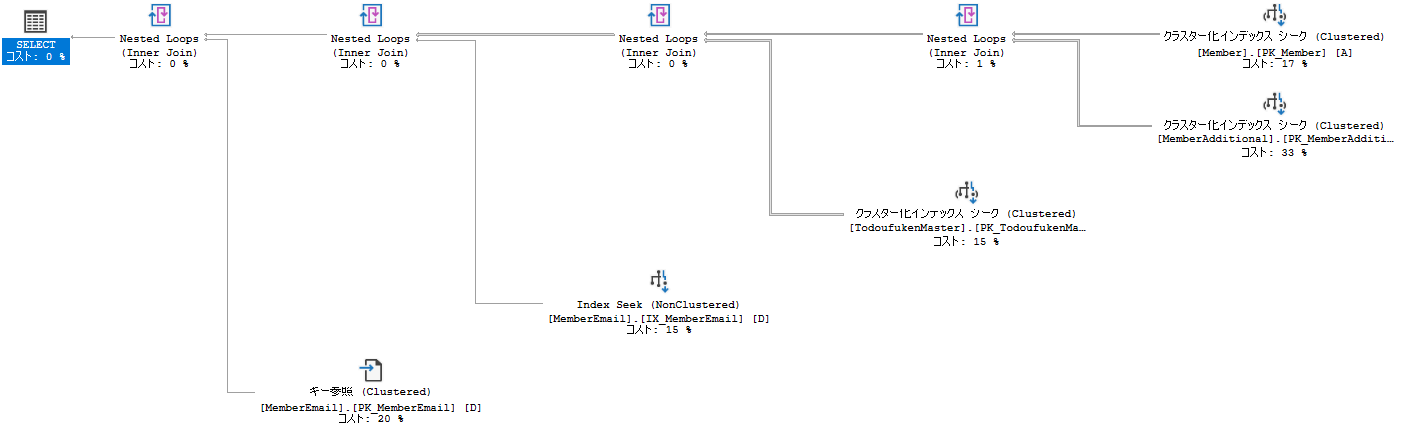
右端の一部にフォーカスする。
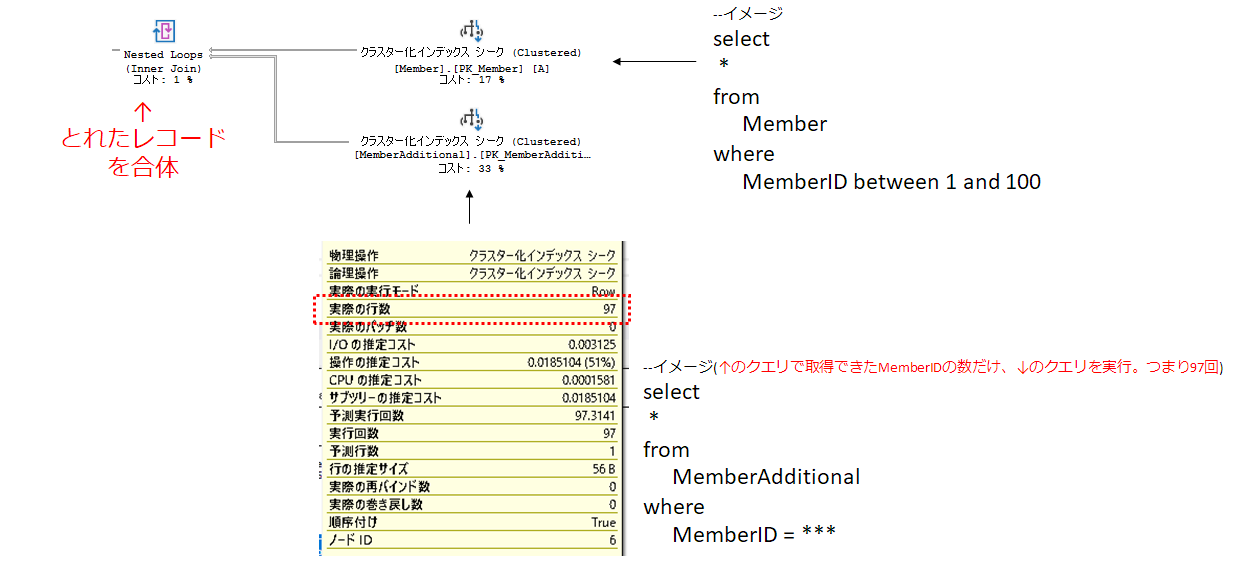
↑ こんな感じで、2つのテーブルにおいて、それぞれ単体でデータを絞り込んでから合体させている
※正確には各インデックスorヒープといったデータ格納領域ごと
ポイント①:Memberのシーク述語は、元クエリのwhere句と同一
ポイント②:MemberAdditionalのシーク述語は、元クエリのwhere句「B.RegistDate between '2018/01/01' and '2018/12/31'」ではなく、元クエリの結合条件「A.MemberID = B.MemberID」となっている
他のテーブルについても、すべて結合条件がシーク述語になっている(ここではキー参照については言及しません)
シーク述語:SQL Serverがインデックスをseekするときに使用する絞り込み条件。
ここまでの内容をまとめると、クエリと実行プランの対応としては以下のイメージ。
selectivityが最も良い検索述語のみがシーク述語となり、それ以外は結合条件がシーク述語になっている
■ クエリG
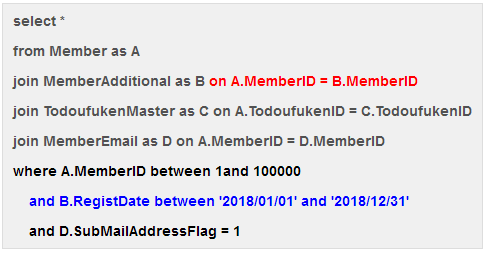
このクエリはかなり遅い。実行プランは以下のようになる。
A.MemberID between *** という検索述語で10万レコードくらいまでしか絞り込めないため、MemberEmail / MemberAdditionalのSeek回数がそれぞれ約10万回とかなり多い。
Memberのレコードをそこまで絞り込めなかった(パフォーマンス的な)悪影響がMemberEmail / MemberAdditionalへ伝搬していく様子が分かる。
まとめ
・JOINを含むSELECT文は、実際は各テーブル(orインデックス/ヒープ)ごとにデータを絞り込み、合体するという処理を繰り返す
・複数テーブルに対する検索述語が存在する場合でも、基本的には最もselectivityが良い検索述語のみがシーク述語(=実行時のデータ走査用述語)となり、それ以外は結合条件がシーク述語となる
・最もselectivityが良い検索述語による絞り込みレコード数は、その後の各結合処理の実行回数(≒レコード数)へと影響が伝搬していく
→selectivityが良いとパフォーマンス的に好影響が、selectivityが悪いとパフォーマンス的に悪影響が伝搬していく
「複数テーブルのJOINを含むクエリでは、selectivityが良い検索述語が1つ以上存在すれば、クエリ全体としてパフォーマンス面のポテンシャルが高いとの判断が可能」
→何故か?
Answer:「クエリ実行時、selectivityが良い検索述語によりぐっとレコード数が絞り込まれ、その後の結合時にパフォーマンス的な好影響が伝搬していくため」
まとめ
・高速なクエリ = selectivityの良い検索述語 + 適切なインデックス
・クエリの新規作成、改修時には、「selectivityの良い選択述語があるか」と「適切なインデックスが存在するか」を確認する