「SORACOM アドベントカレンダー 2021」アンカー担当の松下(ニックネーム: Max)です。
Qiitaのルールでは12/25が終わるタイミングまでに25日分埋まっていればよい、言い方を変えれば「アンカーは必ず12/25に書け」というものなんですね。
ありがたくも 2019年、 2020年に続き、3年連続でアンカーを賜りました! そろそろ、誰かがアンカーやってもいいんですよ
今年は「振り返り」の回
2019年はSORACOMのユーザーコミュニティー「SORACOM UG」の5年間を振り返り、2020年はAI カメラ「S+ Camera Basic」を使った技術的な内容だったので、次は順番的に振り返りかなーというお気持ちになりました。
登壇タイトルって、トレンドを表している...?
先日社内での活動レビューをしていた際に気が付いたのが登壇回数だったんです。2017年3月からソラコムでエバとして活動し始めて約5年、登壇回数は2021年12月時点で488回だったんです。あと12で500回...おしい!
まあ、これからもバンバン登壇するので500、1000といく所存です。
回数はさておき、別に思ったのが「登壇タイトルってトレンドなどを反映しているよね...?」ということです。来場者の期待や、学んだ方が良い事を盛り込むわけですから当然と言えば当然です。とはいえ、IT業界の5年といえば、もはや一昔前。
そこで、タイトルをまとめたら何か見えてくるんじゃないか?というのが今回のアンカーブログです。結構見切り発車でやってる感があるので、一体何が得られるのか未知数ですが、お付き合いください!!
※ちなみにデータサイエンティストの経験や才能は一切ないので、迷いっぷりもご笑覧ください!
まずはデータを集めるところから
何は無くとも、まずはデータからです。回数とかはデータ化してあるのですが、タイトルまではやって無かったんです。ということでpptxを開いてはタイトルをスプレッドシートにコピるという苦行作業を延々と行います。
RPAが使えればよかったんでしょうが、どのページ、どのテキストがタイトルなのかを特定する方法がわからなかったので自動化できませんでした。
結局、5年488回のうち、3年223回分で力尽きてしまいました...ごめんなさい。
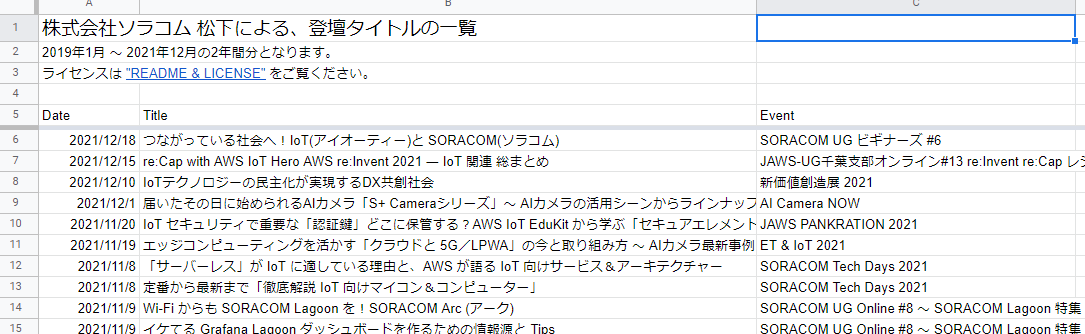
データは株式会社ソラコム 松下による、登壇タイトルの一覧で公開しています(ライセンスはCC BY-NC-ND 4.0)。
中身はこんな感じです。
次は単語抽出だ ~ Amazon Comprehend を試す
分析するには単語抽出(形態素解析)からですかね。
昔はMeCabやChaSenとIPAの辞書を使って単語抽出していましたが、現代はどうなんでしょう?知ってるサービスとしてはAmazon Comprehendがあるので、まず試してみました。コンソールからサクッとできるのはありがたいですねー。
入力文字: IoT セキュリティで重要な「認証鍵」どこに保管する?AWS IoT EduKit から学ぶ「セキュアエレメント」の役割と機能
出力結果:
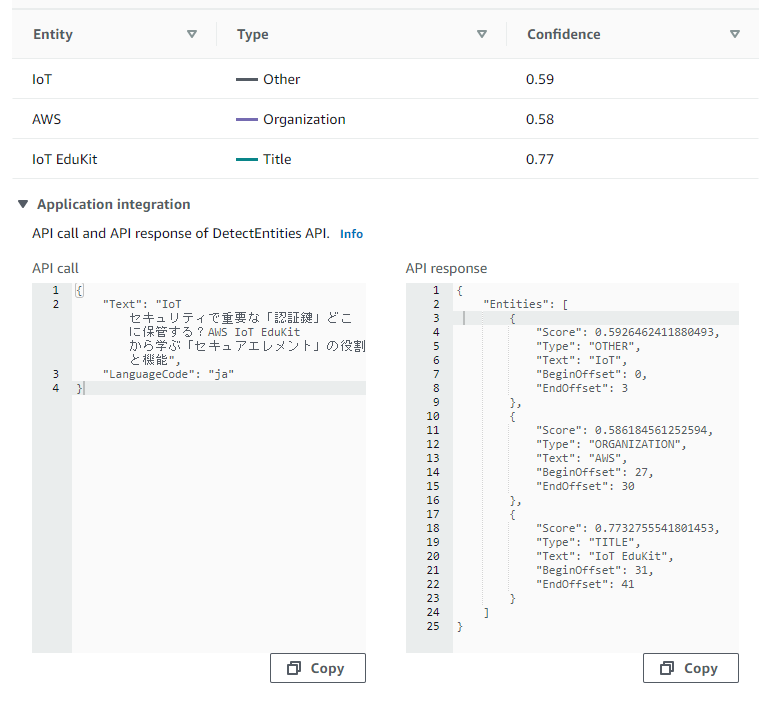
うーん、もう少し単語をピックアップしてもらいたかった気持ちです。
どうやら「エンティティ検出」と言うらしい
Amazon Comprehendのドキュメントを読むと、単語抽出の事を「エンティティの検出」と表現されており、ならば "エンティティ検出" 機能を持つサービスを探せば良さそうと見えてきました。ググります。
"Azure エンティティ検出" や "Google Cloud エンティティ検出" とすると、それぞれ Azure Cognitive Service for Language や Natural Language AI にたどり着きました。
Google Cloud Natural Language AI を試す
Natural Language AI はページ上にPlaygroundがありました。やってみましょう。
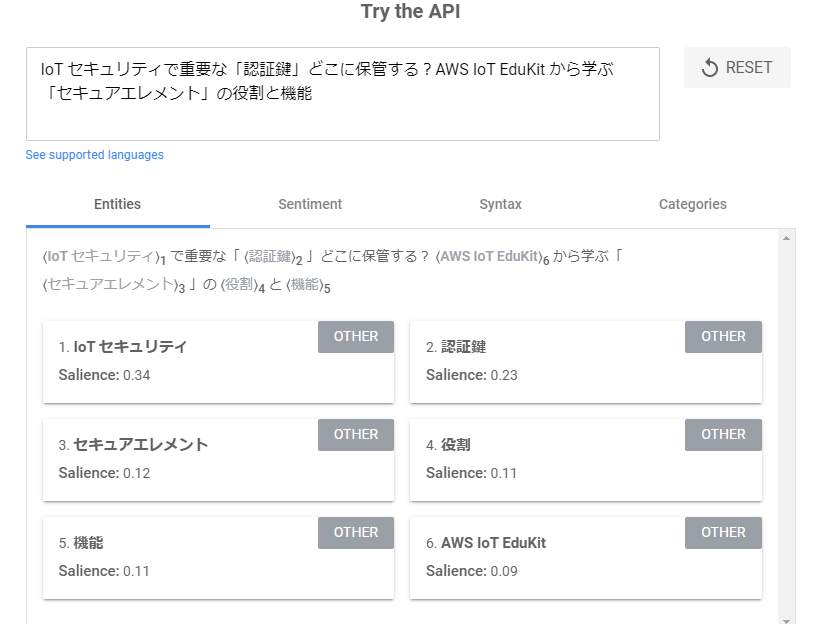
おお、それっぽいぞ!やっぱWeb上でサクッと試せるのはありがたい。
Azure Cognitive Service for Language を試す
Azure Cognitive Service for Language は Azure Cognitive Service 内の「言語」から開始できます。なんと Free がある!それじゃあ、試してみましょう。
インスタンスを作った後、「Language Studio」を立ち上げれば、Webブラウザ上から操作できるようになります。

これもそれっぽい!
Natural Language AI で行くことにした
分析自体はピボットテーブルでやろうかなと思っていたので、エンティティ検出さえできればOKなのが要件として見えました。精度はもちろんですが、手間はできる限り減らしたいので、チュートリアルがあって、pipでサクッと環境が作れそうな Natural Language AIにしました。
Natural Language AI によるエンティティ検出
チュートリアルでは、Cloud Shell 内で完結しているのですが、私の場合はSpreadsheet上のタイトルを読み込ませる必要があります。
そこで gcloud コマンドを使うところまではCloud Shell上で行い Natural Language AI の API を呼び出すときの認証情報 key.json の生成ができた後は、それをPCに持ってきてローカルで Natural Language AI が動かせるようにしました。
ローカル PC での手順は以下の通りです。
python3 -m venv extract_entities
cd extract_entities
source bin/activate
pip3 install google-cloud-language
export GOOGLE_APPLICATION_CREDENTIALS=./key.json
key.json は Cloud Shell 上で cat key.json して、ターミナルからコピって作成してください。環境変数 GOOGLE_APPLICATION_CREDENTIALS には key.json の保存先を書きます。同一ディレクトリなら ./key.json 、ホームディレクトリなら ~/key.json ですね。
これで環境が整いました。あとはチュートリアルに掲載されている analyze_text_entities() 関数をベースに、エンティティ検出のコードを書きます。
今回はコマンドラインの第1引数に指定した文字列(タイトルを想定)からエンティティを検出し、ピボットテーブルに流し込みやすい「タイトル 単語」の組を出力するようにしました。
"""Extract Entities using Google Cloud Natural Language AI
Required: `key.json` and `export GOOGLE_APPLICATION_CREDENTIALS=/FOO/BAR/key.json`
Using and Result:
python3 extract_entities.py "あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。"
"あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。" "イーハトーヴォ"
"あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。" "すき"
"あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。" "モリーオ市"
"あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。" "波"
"あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。" "草"
"あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。" "底"
"あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。" "森"
"""
from google.cloud import language
def analyze_text_entities(text):
client = language.LanguageServiceClient()
document = language.Document(content=text, type_=language.Document.Type.PLAIN_TEXT, language="ja")
return client.analyze_entities(document=document)
import io
import csv
def tsv_from_(rows):
f = io.StringIO()
writer = csv.writer(f, delimiter='\t', quoting=csv.QUOTE_NONNUMERIC)
writer.writerows(rows)
r = f.getvalue()
f.close()
return r
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('text', help='input text')
args = parser.parse_args()
response = analyze_text_entities(args.text)
rows = []
for entity in response.entities:
row = [args.text, entity.name]
rows.append(row)
print(tsv_from_(rows))
データの準備から extract_entities.py の実行まで
Spreadsheet からタイトルだけコピってきて titles.txt で保存します。
cat titles.txt | head -3
つながっている社会へ!IoT(アイオーティー)と SORACOM(ソラコム)
re:Cap with AWS IoT Hero AWS re:Invent 2021 ― IoT 関連 総まとめ
IoTテクノロジーの民主化が実現するDX共創社会
実際に実行してみます。怖いので最初は3タイトル分だけ。ちなみに、連続でAPIコールすると止められちゃいそうな気もしたので、とりあえず sleep 1 をいれてあります。
IFS=$'\n' ; for TITLE in `cat titles.txt | head -3` ; do python3 extract_entities.py "${TITLE}" ; sleep 1 ; done | tee result.tsv
"つながっている社会へ!IoT(アイオーティー)と SORACOM(ソラコム)" "社会"
"つながっている社会へ!IoT(アイオーティー)と SORACOM(ソラコム)" "ソラコム"
"つながっている社会へ!IoT(アイオーティー)と SORACOM(ソラコム)" "SORACOM"
"つながっている社会へ!IoT(アイオーティー)と SORACOM(ソラコム)" "IoT"
"つながっている社会へ!IoT(アイオーティー)と SORACOM(ソラコム)" "アイオーティー"
"re:Cap with AWS IoT Hero AWS re:Invent 2021 ― IoT 関連 総まとめ" "IoT"
"re:Cap with AWS IoT Hero AWS re:Invent 2021 ― IoT 関連 総まとめ" "Cap with AWS IoT Hero AWS re"
"re:Cap with AWS IoT Hero AWS re:Invent 2021 ― IoT 関連 総まとめ" "関連"
"re:Cap with AWS IoT Hero AWS re:Invent 2021 ― IoT 関連 総まとめ" "2021"
"IoTテクノロジーの民主化が実現するDX共創社会" "IoTテクノロジー"
"IoTテクノロジーの民主化が実現するDX共創社会" "DX共創社会"
"IoTテクノロジーの民主化が実現するDX共創社会" "民主化"
おお、いい感じではないでしょうか。なんか微妙に空白行が入るのは微妙ですが、あとでsedで削除できるから気にしない。
では head -3 を取って、全部行ってみましょう! ついでに空白行も削除削除。
IFS=$'\n' ; for TITLE in `cat titles.txt` ; do python3 extract_entities.py "${TITLE}" ; sleep 1 ; done | tee result.tsv
# 結果は割愛
sed -i '/^$/d' result.tsv
無事出力されました。これをSpreadsheetに貼り付けたものがこちらです。
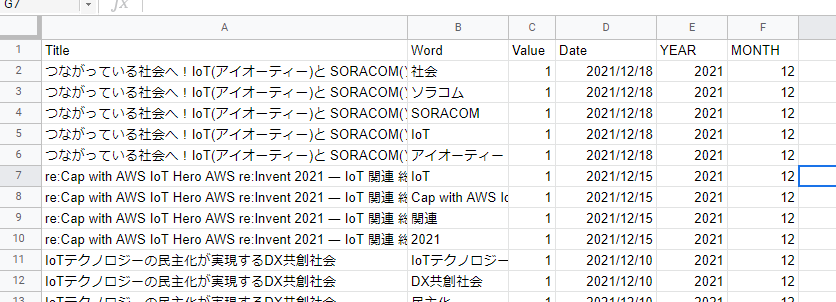
Valueは集計用として固定値1を設定、DATEはTitleを基にVLOOKUPで引っ張ってきています。YEARとMONTHはDATEからの算出です。
分析開始
さあ役者データは揃いました。楽しい分析タイムのスタートです!
やっぱり1位は「IoT」とはいえ「事例」も人気
3年間のトップは「IoT」そして「SORACOM」が来ていますね。当たり前っちゃ当たり前ですが、3位の「事例」も納得です。10位にも「活用事例」が入ってますし、やはりみんな大好き "事例" ということでしょう。
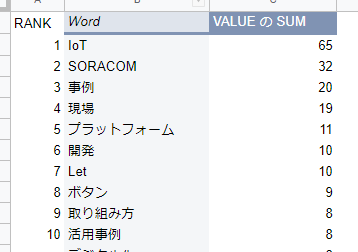
あと「現場」や「開発」と同レベルで「ボタン」も多かったんですねー。やはり「取り組み方」といった入口の紹介が多かったようです。
他はシートを見てください。
2021年は「AI カメラ」そして「SORACOM Lagoon」
2021年を基に集計してみると、また違った面が見られます。総合でランクインしていたキーワードに割って入っているのが「AI カメラ」や「SORACOM Lagoon」そして「機能」です。
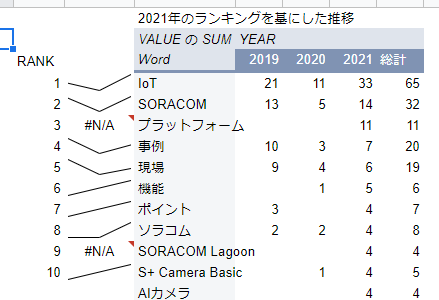
AIは、IoTで集めたデータの分析にも、そしてカメラデバイス上での分析と、具体的な活用が見えてきたのが増加の背景と言えるでしょう。
逆に2019年を基にしたトレンドを見てみると特に「ボタン」が減ってますね。簡単だし、説明しなくても大丈夫になってきたのかな?
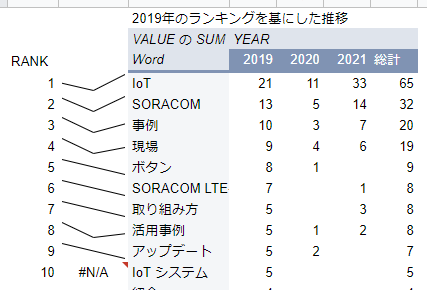
IoT のこれまで、そして、これから
タイトル一覧で気づいた方もいらっしゃると思いますが、ほとんど同じタイトルが無いんです。実はスライド構成も同じものがほとんどありません。スライドのページ自体は流用しますが、順番や同じページでも話す内容は異なっています。
これは、聞く方の興味ポイントや周辺環境は常に変わっているわけで、それに合わせた学びを持ち帰っていただきたいという想いからです。そのおかげでタイトル作りは毎度苦労しており、〆切調整に奔走してくれているメンバーには大感謝なのです!
そして、タイトルを作り込んだからこそ、なんとなくですがトレンドが見えたのも、分析していて楽しかったです。
IoTという単語を頻繁に目にするようになって、はや6年近く。事例や取り組み方は人気ではあるものの、AIやカメラといった「次の一手」が見え始めています。
あと、今回はうまくエンティティ検出されてなかったのですが「遠隔操作」もしくは「遠隔監視」という、具体的な方法もトレンドが上がってきており、IoTはフワッとした話から、地に足着いた現実のものになってきていると言えるでしょう。
2022年、そして今後のIoTは「つなげる or つなげない」という議論から「つながるのはあたりまえ、それでどうする?」と、活用を見出していくフェーズになったなーという、、、これだけ時間かけたのに、Natural Language AIの使い方を紹介して、普通の感想を書いただけのポエムブログになってしまいましたが、皆さんにとってのIoT活用の次の学習ポイントの単語帳として、今回の分析結果が役に立てばと思っております!
あーなんとか、かき揚がってよかった!それじゃあ、メリークリスマス&良いお年を!
来年のアンカーは誰に任せた!
― Max
EoT