この記事ははてなエンジニアAdvent Calendar 2024の7日目のエントリーです。昨日は id:miki_bene さんのEmacs のトレース情報を Mackerel(Vaxila) に送りたかった…… - ドキュメントを見た方が早いでした。タイトルから悔しさが伝わってきますね。
さて、この記事では、表題通りAWSのコストと使用状況レポート (CUR)2.0のデータをBigQueryへ転送して分析できるようにするためのポイントや、私が工夫していることをいくつか紹介します。
以下、当機能をCUR2.0と呼びます。
使用状況レポート (CUR) 2.0 とは
CURは Cost and Usage Report です。そのままですね。
CUR2.0は re:Invent 2023でリリースされたもので、AWS Billing and Cost Management の中の AWS Data Exportsの一部として整理されています。もともと存在していた旧CURはレガシーレポートとして残っています。
レガシーレポートについては、ドキュメントにおいて以下のように説明されており、
we recommend you use AWS Data Exports because these reporting methods will be unavailable at a later date.
いかにも使い続けるべきではなさそうです。つまり、これから改めてAWSの利用状況データを詳細に分析しようとする場合、および、現在レガシーレポート(CUR1.0)を利用している場合は、CUR2.0を利用するのがいいと思います。
なお、AWS Data Exportsでは直近でFinOpsのFOCUS1.0対応がGAしていましたが、今のところコンテナ基盤で実行されるものの配賦が可能なECS Task / EKS Podの費用分割をサポートしていません。
レガシーレポートからの切り替えでは、利便性の面で以下のような嬉しさがあります。
- レガシーレポートにあった大量の
product_*列がproduct: Struct<key_value: []Steuct<key:string, value: string>>>にまとまるようになった。列数が減るだけでなく、新機能が増えたりしても列の増減がある程度抑制されそう。 -
cost_category,resource_tagsが同様に独立した列でなくなり、追加削除でスキーマ変更を伴わなくなった。 -
line_item_usage_account_nameが格納されるようになった。
アカウント名がレコードに含まれるようになったのは非常にホットな更新です。
コンソールの AWS Cost Explorer との違い
以下のような重要な違いがあります。
- AWS Cost Explorerの画面ではグループ化ディメンションが1つしか指定できない。(Cost Explorer APIでも2つ)
- 探索的にドリルダウンする場合には問題がないことが多いのですが、まとまったレポートとして考えると「Cost Category / Account / Service / Environment」くらいのグループ化をしたい時があります
- Cost Explorerの画面ではAmortized Cost(純コスト) / Net Amortized Cost(償却純コスト)の数字が参照できる
- リザーブドノードやSavings Plansの前払いを期間償却した場合のレポートは Cost Explorerの画面からは参照できますが、CUR2.0 / レガシーレポートのデータにはその数字はありません
- Amortized あたりの概念は意外とわかりづらいのですが、Understanding your AWS Cost Datasets: A Cheat Sheetが詳細です。
後者は少し不便ではありますが、含まれるデータからクエリを工夫することで求めることができます。後述します。
まずはレポート出力の設定をしよう
AWS Data Exports は支払いアカウントで設定します。組織で請求をまとめている場合は、おおもとの支払いアカウントで設定することになります。
出力先としてS3のバケットを指定することになりますので、作成しておきましょう。
Organization の再編成などで支払いアカウントが切り替わったりすると、古い請求アカウントのCost Explorerでは過去の請求情報を参照することができなくなります。CURのレポートを出力する設定にしておけば、S3に出力されたレポートは永続します。
エクスポートタイプとして「標準データエクスポート」、データテーブルの形式は「CUR2.0」、ここではBigQueryに転送することを想定しているので、時間粒度として「日時」あたりを選んでおきます。
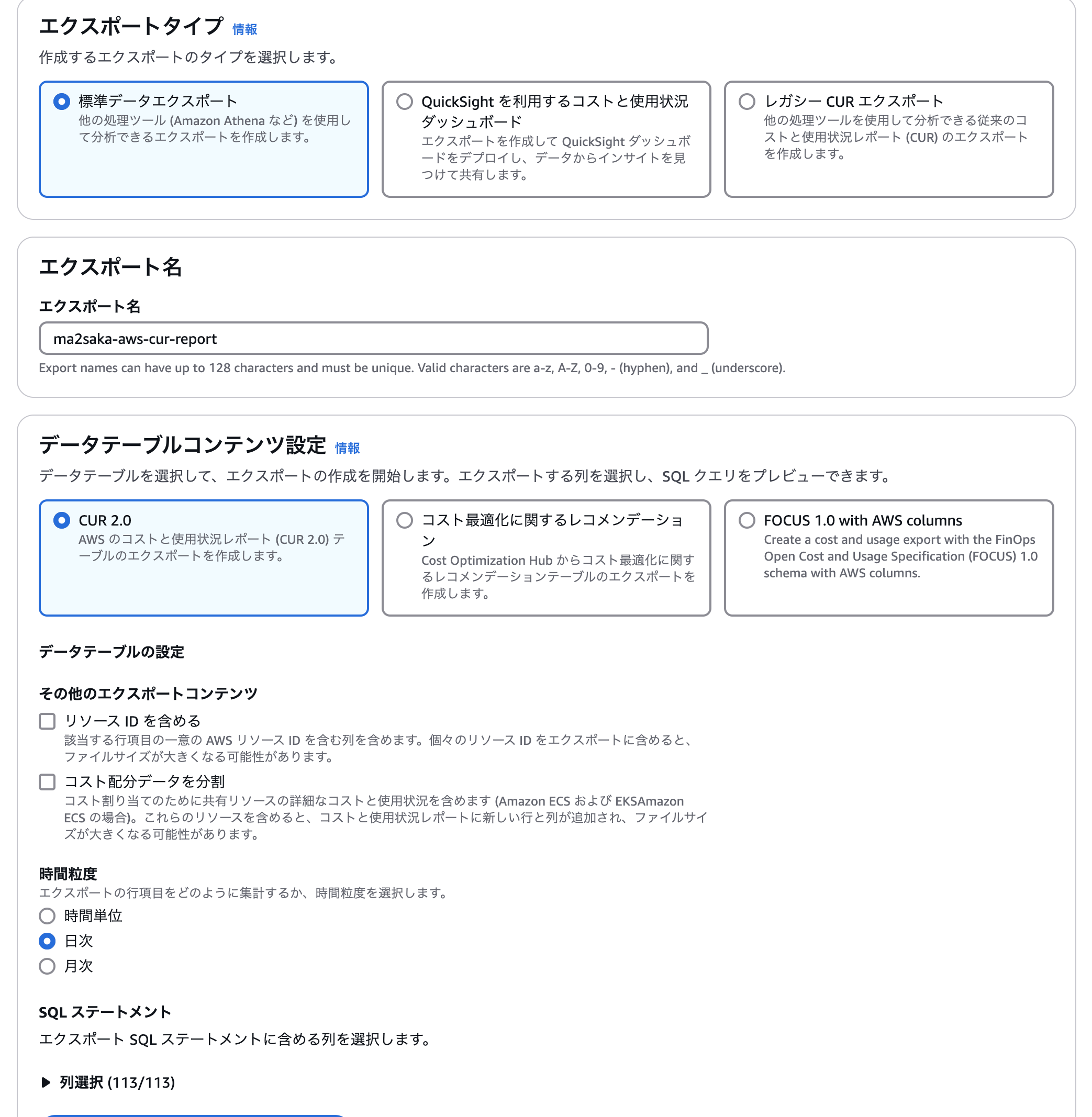
CUR2.0では出力する列を選ぶことができます。列は記事執筆時点では113列となっていました。
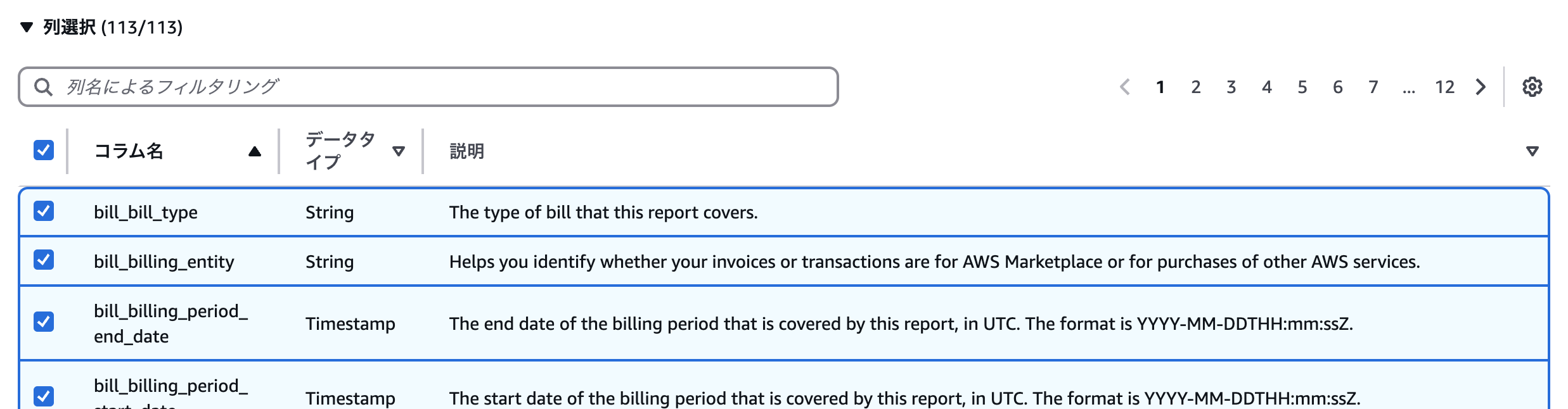
これは、利用者によって違うかもしれません。たとえば現時点のドキュメントによると125列あるという記載もあります。
最初は全て選んでおけばよいでしょう。
以下ドキュメントにはそれぞれのカラムについての説明はあるのですが、おそらく初めて触れる場合は適切なカラムを選択するのは不可能です。
データ形式はここでは Parquet ファイルを選択しておきます。スキーマ情報がファイルに含まれているとなにかと便利です。ファイルのバージョニングはどちらでもいいですが、ここでは上書きを選択しておきます。
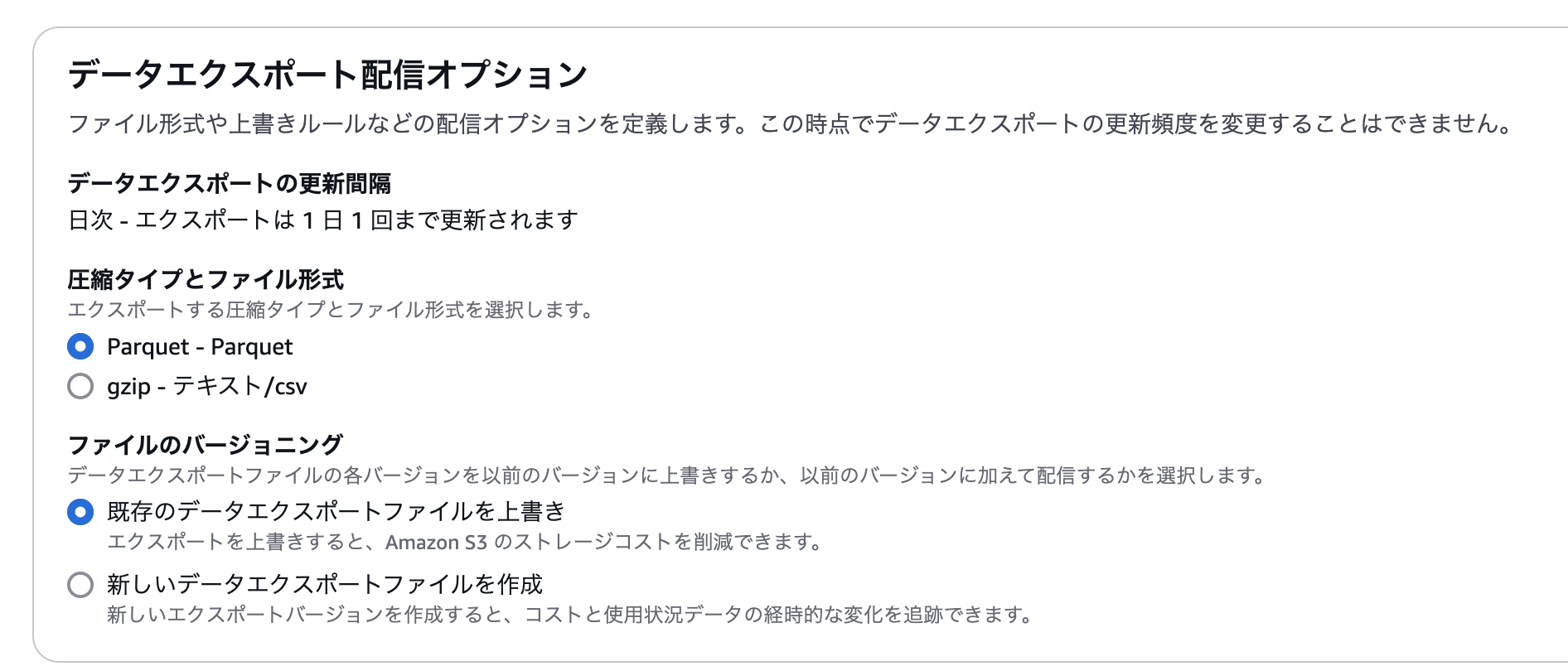
利用規模にもよりますが、そこそこのサイズのデータが頻繁に更新されることになります。S3からのアウトバウンド通信やストレージ容量増大が心配であれば、S3バケットとかには適宜リソースタグを付与しておくとよいでしょう。(私の利用状況では一日数回の同期で月数ドルでおさまっていました)
設定するとしばらくするとバケットにデータが溜まり始めます。
Google Cloud Storage への転送
Cloud Storage の Storage Transfer Service を利用するのがたいへん楽です。転送先のプロジェクトは作成しておきます。
S3側のオブジェクトの構成がそのまま転送されます。
データの内容としては金額や利用状況だけでなく、リソースコストタグやコストカテゴリの名称文字列も含まれる場合があります。
AWSの支払いアカウント所有のS3バケットに出力する際にはアクセス制御やデータ保管場所の問題は発生しづらいですが、AWSの外に転送する場面では組織のデータの取り扱いポリシー等を適宜参照してください。
Google Cloud StorageからBigQueryへの転送を試す(1ファイル)
さて、S3にデータが出力されたら、BigQuery に転送してみましょう。
BigQueryからは直接Cloud StorageにあるParquetファイルのロードが可能です。
ここでは、gs://${BUCKET_NAME}/cur/ に CUR2.0のデータを転送したものとします。。CUR2.0のレポートの名前を ${REPORT_NAME}/とします。また、転送先の BigQuery のテーブルは ${BQ_TABLE}とします。
% bq load --source_format parquet --location asia-northeast1 ${BQ_TABLE} gs://${BUCKET_NAME}/cur/${REPORT_NAME}/data/BILLING_PERIOD=2024-11/${REPORT_NAME}-00001.snappy.parquet
Parquet のメタデータからスキーマは自動取得されます。便利ですね。
スキーマを確認するには bq show --schema を利用します。
% bq show --schema --format=prettyjson ${BQ_TABLE}
[
{
"mode": "NULLABLE",
"name": "bill_bill_type",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "bill_billing_entity",
"type": "STRING"
},
...
クエリを打ってみる
例えば、EC2の利用データを1行取得してみましょう。
% bq query --format=prettyjson --nouse_legacy_sql \
"select \
line_item_usage_start_date, \
line_item_usage_end_date,\
line_item_usage_type,\
line_item_usage_amount,\
pricing_public_on_demand_cost,\
line_item_unblended_cost \
from ${BQ_TABLE} \
where \
line_item_line_item_type = \"Usage\" \
and line_item_product_code = \"AmazonEC2\" \
limit 1"
[
{
"line_item_unblended_cost": "0.0156341472",
"line_item_usage_amount": "0.356944",
"line_item_usage_end_date": "2024-11-28 01:00:00",
"line_item_usage_start_date": "2024-11-28 00:00:00",
"line_item_usage_type": "USW2-SpotUsage:m6g.xlarge",
"pricing_public_on_demand_cost": "0.054969376"
}
]
2024-11-28の0時から1時までの1時間の間で、USW2リージョンで(us-west-2ですね)、m6g.xlargeのSpotインスタンスの利用があったようです。公式によると通常価格は $0.154/hourです。この1時間の中で、課金のために計測された単位は line_item_usage_amount: 0.356944 です。だいたい20分くらいでしょうか。0.154 * 0.356944 = 0.05496937599999999 ですので、pricing_public_on_demand_cost列に入っているのはそのまま通常価格での金額ということだと思います。それに対して、実際に請求発生している line_item_unblended_cost は 0.0156341472です。だいたい7割引くらいですね。
このように詳細なデータが得られるのがCost Explorerにはない魅力です。
パーティショニングキーとレコードの主キー的なものの不在
CUR2.0のデータは日々更新されていきます。元データが更新されたら BigQuery のデータも更新したいと思うのは当然のことです。
ところで、Parquetファイルから展開されたスキーマを眺めていると、全てがNullableであることに気が付きます。
実際、ドキュメントを見てもどの列が必須列であり存在が保証されているかという説明はありません。サポートからの回答も「おそらく」という但し書きがつきます。そして、行ごとに一意となるようなキーはありません。
したがって、データを更新する際には少し工夫が必要です。
パーティションキーは会計期間(period)とするのがよさそう
CUR2.0のデータは以下のようなルールで出力されます。メタデータが格納された Manifest.json と、実際のデータファイル群です。見た感じデータファイルは100MBくらいの単位で分割されているようです。
- `${REPORT_NAME}/matadata/BILLING_PERIOD=2024-11/${REPORT_NAME}-Manifest.json`
- `${REPORT_NAME}/data/BILLING_PERIOD=2024-11/${REPORT_NAME}-00001.snappy.parquet`
ここで、パスから BILLING_PERIOD=2024-11 が確認できます。これを 2024-11-01 として日付に変換し、全ての行に必須の列として置くことで日付パーティションにすることができます。
利用状況レポートのデータのユースケースとして、保存されている全期間を対象に探索を行うことは稀で、集計や探索は期間を対象にすることがほとんどです。そういった点からも、Period列を追加してしまい、それをパーティションキーとして扱うのが妥当だと思います。
ただ、せっかくS3からGCS、GCSからBigQueryと転送を実際のデータファイルに手を触れずにやっているので、このためにファイルの内容に修正を加えるのは避けたい気持ちがあります。そこで、次のステップで少し工夫をしてみることにします。
行単位での更新ができないため、更新するときはPeriod単位で行う
BigQueryはDELETE操作がパーティション全てをカバーする際はDMLの処理コストがほとんどかかりません。
そこで、一時テーブルを作成してデータを全て読み込ませた後、マルチステートメントトランザクションで対象 Period のデータの置き換えを実行します。
一時テーブルは CREATE TEMP TABLE で作成するのでもいいですが、一時テーブルにそこそこの量のCUR2.0のデータをロードすることを考えると、expiration を指定した永続テーブルを利用すると便利かもしれません。
ここでは、一時テーブル名を BQ_TMP_TABLE変数で参照できるとします。以下のようなステートメントを実行することで、一時テーブルからアトミックにデータを移動することができます。
BEGIN TRANSACTION;
FOR target in (SELECT distinct period FROM @BQ_TMP_TABLE)
DO
-- 履歴テーブルから該当会計期間のデータを削除
DELETE FROM @BQ_TABLE where period = target.period;
-- 一時テーブルから該当会計期間のデータを追加
INSERT INTO @BQ_TABLE SELECT * FROM @BQ_TMP_TABLE where period = target.period;
-- 一時テーブルから該当会計期間のデータを削除(一時テーブルが再利用しない場合は不要)
-- DELETE FROM @BQ_TMP_TABLE where period = target.period;
END FOR;
COMMIT TRANSACTION;
※ BigQueryのパラメタライズドクエリではテーブル名指定をパラメータ化することはできないため、ここで示したコードは適宜ベタ書きにするなりORMに食わせる想定です
一時テーブルを作成する際、スキーマにperiod列を追加する
CUR2.0のデータには period 列はありません。そこで、一時テーブルを処理する Period ごとに作成することにして、以下のようにデフォルト値を持つ period 列をスキーマに追加します。
[
{
"defaultValueExpression": "\"2024-11-01\"",
"name": "period",
"type": "DATE"
},
....
これで、一時テーブルへデータをロードする際に自動的に固定の DATE("2024-11-01")が全ての行に追加されるようになります。
永続の履歴テーブルのスキーマはデフォルト値を持たず、単にREQUIREDにしておきます。
[
{
"mode": "REQUIRED",
"name": "period",
"type": "DATE"
},
....
これで、日付パーティションキーを持った状態で、CUR2.0のデータがBigQueryに転送できるようになりました。
処理対象の Period の特定 → デフォルト値入り period 列を持つ一時テーブルを作成 → データを全部取り込んで履歴テーブルに転送する、というステップを踏むので、このアプローチを取る場合は BigQuery Data Transfer Service とかを利用してフルマネージドでサクセスという夢は潰えます。残念です。
Net Amortized Cost への旅
さて、ここまででBigQueryにAWSの詳細な利用状況データが格納されました。
しかし、まだ課題が残っています。それが冒頭で触れたCost Explorerとの違いの一つであり、「Net Amortized Costの数字がない」問題です。ここはもう「工夫してクエリを書く」しかありません。そして、サポートに聞いても「このクエリで出せば正解だよ」という答えが出てくるものでもありません。
Amortized Cost をCURのデータから導くやり方については、ニフティさんのブログAWS Organizationの管理アカウントでSPs/RIを一括購入してカバレッジを上げるでかなり詳細に触れられています。ほぼ自分が書いたものと同じクエリになっていて面白かったです。
最近私が利用しているのは以下のようなクエリです。Cost Explorerの画面から参照する数字とぴったり一緒にならないのが悔しいところですが、差分は誤差であると扱える程度には一致すると思います。
SELECT
period,
SUM(
CASE
WHEN (line_item_line_item_type = 'SavingsPlanCoveredUsage') THEN savings_plan_net_savings_plan_effective_cost
WHEN (line_item_line_item_type = 'SavingsPlanRecurringFee') THEN ( savings_plan_total_commitment_to_date - savings_plan_used_commitment )
WHEN (line_item_line_item_type = 'DiscountedUsage') THEN reservation_net_effective_cost
WHEN (line_item_line_item_type = 'RIFee') THEN ( reservation_net_unused_amortized_upfront_fee_for_billing_period + reservation_net_unused_recurring_fee )
ELSE line_item_net_unblended_cost
END
) net_amortized_cost
FROM
@BQ_TABLE
WHERE
period >= "2024-07-01"
AND NOT (
line_item_line_item_type IN ('Tax',
'Refund',
'SavingsPlanUpfrontFee',
'SavingsPlanNegation')
OR line_item_product_code like '%AWSSupport%'
OR (line_item_line_item_type = 'Fee') AND (reservation_reservation_a_r_n <> ''))
GROUP BY
period
ORDER BY period;
そういえば、ニフティさんの記事とはline_item_line_item_type = "Fee" のレコードの扱いが異なります。
によると、
Fee – Any upfront annual fee that you paid for subscriptions. For example, the upfront fee that you paid for an All
らしいのですが、実は Route53-Domains のドメイン管理費用や、AWS Partner Networkの手数料などもここについてきます。そのため、RIの前払い費用のときのみ無視するというようにしています。
また、line_item_line_item_type = "RIFee" の場合には reservation_net_unused_amortized_upfront_fee_for_billing_periodも参照するようにしています。これは前払いしたRIの費用が未使用になったときに生じる費用が入力されています。
年に1回しか発生しない費用のパターンなどもあるので、ある時点でAWS Cost Explorerのデータときちんと一致していたとしても油断はできません。定期的に確認をしましょう。
税金とサポート費用を除いているのは、これらが実際に支払う金額に割合を乗じて決まる数字であるためで、その月のインフラの利用状況を直接反映する数字ではないからです。このあたり、普段からどういう数値をどういった目的で収集するのかというポリシーと相談しながら組み立てましょう。
ただ、クエリ結果を保証するのは難しい問題です。最終的に検算する方法は請求書とAWS Cost Explorerを頑張って見比べることになります。Cost Explorerのフィルタ条件と同じ結果を得られるようにするだけでも一苦労であることがわかります。
このあたりはBigQuery 関係ないので、AWS Well-Architected Labs > Cost Optimization > AWS CUR Query Libraryなどを参考にいろいろ書いてみるしかなさそうです。
コスト管理以外のデータの活用
冒頭で product 列にプロダクトの詳細なデータが格納されていると書きました。実はこの使用上レポートのデータはコスト管理以外にもいろいろ使い道があります。
たとえば、RDSを例にとりますと、
SELECT
product
FROM
@BQ_TABLE
WHERE
period >= "2024-07-01"
AND line_item_product_code = "AmazonRDS"
AND line_item_line_item_type = "Usage"
LIMIT 1
としたとき、以下のような(ネストされた)結果が得られます。
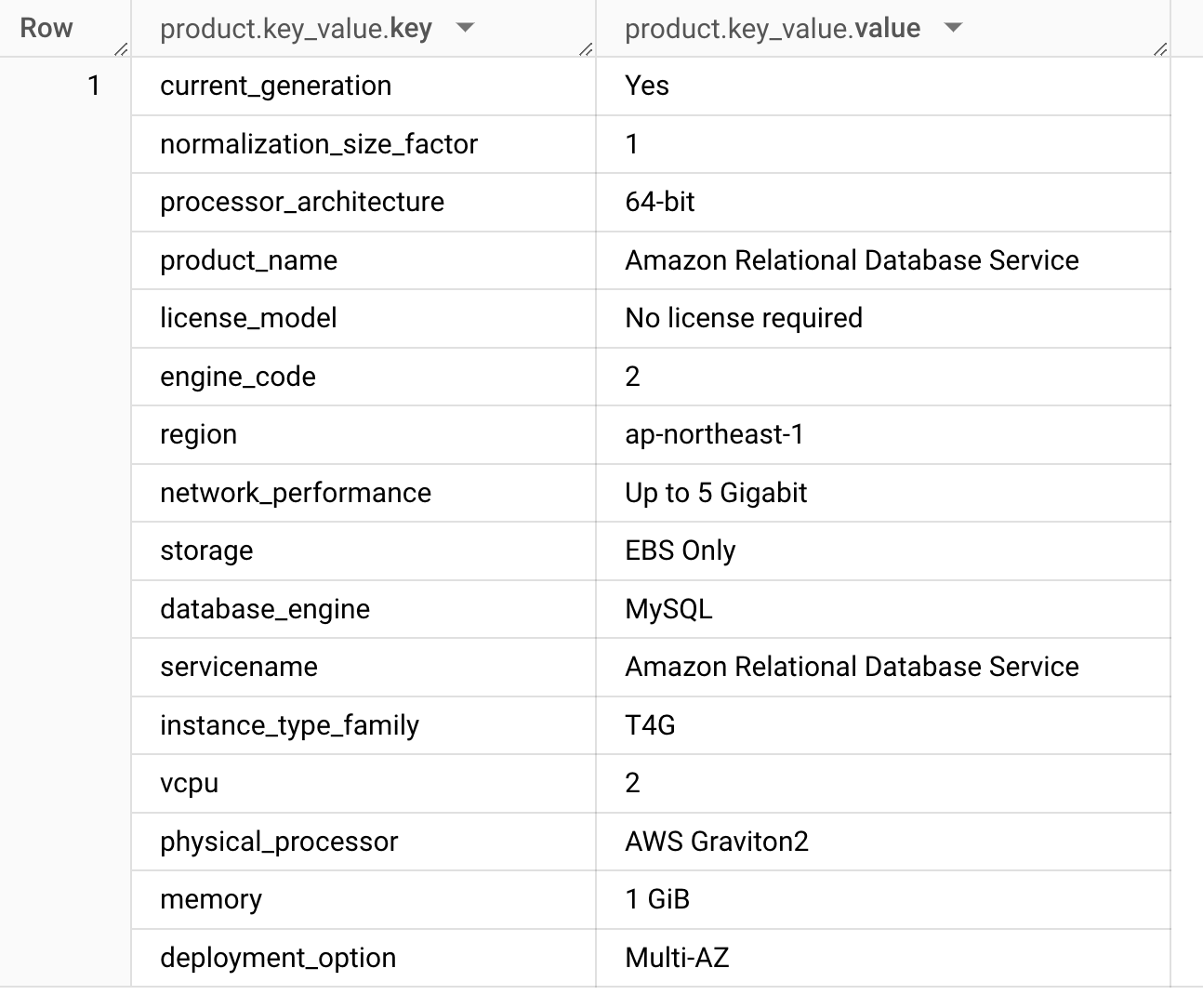
database_engine が MySQLになっています。ここは Aurora なら Aurora MySQL とかになるわけですね。
product 列は製品によって異なり、EC2だったらGPUのメモリとかCPUが提供する拡張命令セットの有無なども記録されています。全社的なインスタンスの世代管理であったり、特定のサービスの利用状況を把握するのには非常に使い勝手の良いビューになっています。
ただし、どんなデータが入っているかというのは網羅的に理解するためのドキュメントは残念ながらありません。
以下のように、それぞれのカラムに含まれる値の範囲を探索して理解を深めていくしかないのです。
SELECT
DISTINCT (SELECT value FROM UNNEST(product.key_value) WHERE key = "database_engine") engine
FROM
@BQ_TABLE
WHERE
period >= "2024-07-01"
AND line_item_product_code = "AmazonRDS"
AND line_item_line_item_type = "Usage"
GROUP BY engine
HAVING engine IS NOT null;
このクエリの結果は(私の環境では)以下のようになりました。
+-------------------+
| engine |
+-------------------+
| Aurora PostgreSQL |
| PostgreSQL |
| Any |
| MySQL |
| Aurora MySQL |
+-------------------+
まとめ
いかがでしたか?
AWS Data Exports から出力される CUR2.0 のデータをBigQueryに格納してみたくなったでしょうか? あるいは、Athena でいいかなと思ったでしょうか。
私の場合は Google Cloudの費用データなど他にもいろいろ FinOps 的に取り扱いたいデータが BigQuery に保管されているのと、利用チーム向けに提供するビューやアクセス制御の都合で BigQuery が都合よかったのですが、AWSに統一されている環境では Athena や Redshift をフロントエンドにするで全く問題なさそうです。重要なのはクエリです。これを読んだみなさんの編み出した最高のクエリをぜひ教えて欲しいと思っております。
6日までベガスで行われていた AWS re:Invent 2024 ではS3 Tablesなどが発表され、S3ベースのデータレイク形成の話題が非常にホットでした。ベストな構成はどんどん変わっていきますね。
それでは、良いクリスマスを。Happy Cost Management!