目次
はじめに
こんにちは、matoです。この記事はマナビDXクエストのアドベントカレンダー20日目の記事です。
今年のマナビDXクエストは、コミュニティマスター(以後、CM)二年目として参加させていただき、微力ではありますが受講生のみなさまの学習をサポートさせていただきました。3ヶ月というかけがえのない濃密で貴重な時間を過ごせたこと、こうやってみなさんと繋がっていられることをありがたく思います。この場を借りて改めてお礼いたします。
プログラム期間中は、私自身CMという立場ではあるものの学ぶ姿勢は1ミリも変わっておりませんでした。むしろ、学び続けなれば支える者として持続性を保つことができないと思っておりましたので常に必死でした。(既にすごい人もいっぱいいるし)
そのため、資格取得にもチャレンジしAI分野の最高峰と言われるE資格を取得することもできました。
👇体験記も書いていますのでよかったらこちらの記事も読んでくださいね。
おかげで自信を持って受講生のみなさんに学びを提供することができたと振り返っています。学びながらサポートするという一度で二度おいしい体験をさせていただきありがとうございました。
本記事は"RAGを実装したら結構楽しかったので一緒にやりません?"っていう内容です。
前置き
アウトプットこそ"最大の学び"だ
自身の知識やスキルを高めていくためには純粋な勉強、いわゆるインプットが大事ですが、それを確実なものとして定着させるためにはアウトプットがとても大事です。資格勉強においても動画やテキストでインプットしたら問題を解く、ノートに書くといった能動的なアプローチによって記憶として固定化されやすくなります。
インプットとアウトプットの差分、つまり自分の未熟さに気づくことができ、どこを重点的に学べばいいかも明確になります。
これってニューラルネットワークの学習プロセスと全く同じですよね。AI勉強してると何気ない人間の行動が機械学習の端々に見えてくるなぁと。
最近、LLMって言葉をよく聞きませんか?Large Language Model(大規模言語モデル)のことで、わかりやすい事例でいうとchatGPTやGemini、Claudeのような対話側生成AIに使われている言語モデルのことですね。
あれ、すごく便利ですよね。使ってない日は無いくらい毎日話しかけています。自分の勤めている会社でもようやく一部生成AIが解禁になったのですが、実作業でフル活用するにはまだ社内整備が追いついていなくヤキモキしている日々です。セキュリティが…とかで、JTCでよくあるアレです。
そこを待っていてもしょうがないですし、これがローカルでできたらな…って思ってるんですよね。
そう、ローカルでね。
…ん?…ローカル…?
そうか!
ローカルだ!!
そうだ、ローカルLLMを実装しよう
やろうと思ったらすぐ体が動くタイプなのは僕のいいところです。ただPCとかあまり詳しくないので調べてみると、どうもMacBook Airだとユニファイドメモリ(メモリ領域をCPUとGPUで共有してくれるのでWindowsのように別途GPUを用意しなくていい)のおかげで簡単に動くみたいなんです。実は今年のAmazonプライムセールでMacBook Air M4買ってたので早速実装してみました。
進め方としては
Geminiに聞きまくる
これ一点のみ。ネットでの検索は一切していません。
Gemini 3.0 Proにアップデートしてから僕も乗り換えたクチなのですが理解力が全然違います。細かい文脈の理解度が高いですよね。ベンチマークスコアも圧倒的ですが体感的にも全然違う印象。
本当はGPTも使いたいのですが、我が家のAI課金は1つまでという縛りがあるので併用ができません。コード生成はClaudeがいいよと聞きますが、そもそも課金できないですし週末エンジニアなのでGemini一本でなんとかしています。(というかそれしかないですもん)
やってみてどうだったのかというと、フツーに実装できてしまいました。
ええ、何の問題もなく、やりたかったことが1〜2日で構築できたって感じです。
本記事ではその実装方法をまとめていますので参考になればと。
実現したかったこととか
なんとなくRAGを組んでみたいなーとは思うものの大した知識はありません。とりあえず実装前段階での環境、目標、モヤモヤしていることはこんな感じでした。
-
環境
- ハード:MacBook Air M4 256GB SSD/16GBメモリ
- 生成AI:Gemini 3.0 Pro(コード生成支援)
-
やりたいこと
- RAGで文書検索アプリを作りたいなあ
- 検索したときに参照元とか出すようにしたいなあ
- (ローカルなら業務でも使えるな)
-
よくわからないこと
- LLMって何入れればいいの?
- RAGってどうやって組むの?
- 精度上げるにはどうしたいいの?
- パラメータとか知らんよ?
- 使い物になるんかな?
いろいろわからないことだらけでしたが、とりあえずGeminiに聞けばできるっしょ!と気楽にやってみました。
実際の画面はこんな感じ👇
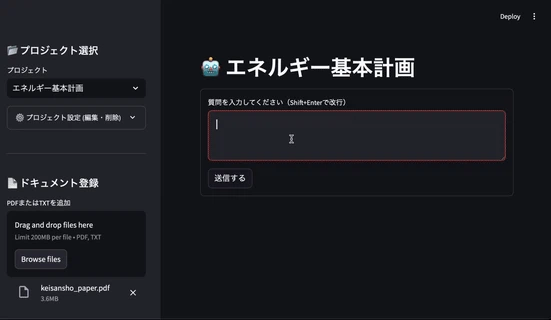
- 経産省の資料などを入れています
- 2倍速にしているので実際はちょっと遅いです(が使えるレベル)
- Gifのため画質悪くてすいません
こんな感じでそこそこ使えるものができました。
前置きはこんなところにしておいて実装内容を以下にまとめていますのでご参照ください。なるべくAIとかPCに詳しくない方でも進められるよう丁寧に書いています(本当はGeiminiに書かせている)のでたぶん最後までイケるかなと思っております。
MacBook前提となっていますのでWindowsの方はごめんなさい。
それではどうぞ👐
RAGの実装
📘 MacBook Air M4で作る!社内文書検索AI構築ガイド
このガイドでは、社外にデータを漏らさず、自分のPCの中だけで動く「文書検索AI」を作ります。 「黒い画面(ターミナル)」での操作は最小限にし、最終的にはスマホアプリのようにアイコンをダブルクリックするだけで使える状態を目指します。
🛠️ 第1章:道具を揃える(環境構築)
まずは料理でいう「調理器具」を揃えるフェーズです。ここが一番の難所ですが、手順通りやれば大丈夫です。
ステップ1:黒い画面(ターミナル)を開く
Macを操作するための司令塔です。
- キーボードの
Command (⌘)+Spaceを押して検索バーを出します。 - 「ターミナル」と入力して
Enterキーを押します。 - 白い文字が打てる黒い(または白い)画面が出てきます。
ステップ2:Python 3.11 を入れる
なぜ? 最新の Python 3.14 などは、AI用ライブラリがまだ対応しておらずエラーの原因になります。最も安定している 3.11 を指定して入れます。
ターミナルに以下をコピー&ペーストして Enter を押します。
brew install python@3.11
つまづきポイント: 「brew: command not found」と出たら、Homebrewというツールが入っていません。その場合は公式サイトのコードを貼り付けて先に入れてください。
ステップ3:AIの脳みそ(Ollama)を入れる
Pythonは「プログラム」ですが、実際に考える「脳みそ」は別のソフトを使います。
-
Ollama公式サイト にアクセスし、「Download for Mac」をクリックしてインストールします。
-
インストール後、ターミナルで以下を実行して、AIモデル(Llama 3.1)をダウンロードします。
ollama pull llama3.1※数GBあるので少し時間がかかります。「Success」と出ればOKです。
📂 第2章:作業場所を作る
PCの中に、このAI専用の「部屋(フォルダ)」を作ります。
ステップ1:フォルダ作成と移動
ターミナルで以下を一行ずつ実行します。
# 1. "rag_project" というフォルダを作る
mkdir rag_project
# 2. そのフォルダの中に入る
cd rag_project
ステップ2:仮想環境(Virtual Environment)を作る
なぜ? PC全体にライブラリを入れると、他のソフトと喧嘩して壊れることがあります。「このフォルダの中だけで使うPython環境」を作ることで、安全に開発できます。
# 必ず 3.11 を指定して "rag_project_env" という環境を作る
python3.11 -m venv rag_project_env
# その環境を有効にする(スイッチオン!)
source rag_project_env/bin/activate
確認: ターミナルの行の先頭に
(rag_project_env)と表示されれば成功です。
ステップ3:必要な部品(ライブラリ)を一気に入れる
AIを動かすための部品をインストールします。
pip install streamlit chromadb langchain-ollama langchain-text-splitters sentence-transformers pymupdf pillow
-
streamlit: チャット画面を作る部品 -
chromadb: PDFの内容を記憶するデータベース -
pymupdf: PDFから文字や画像を読み取る部品
💻 第3章:AIアプリ本体を作る (app.py)
ここがメインディッシュです。これまでの改善(日本語対応、削除機能、画像プレビューなど)を全て盛り込んだコードです。
ステップ1:ファイルを作る
好きなテキストエディタ(VS Code推奨ですが、なければMac標準の「テキストエディット」でも可)を開きます。
⚠️ テキストエディットを使う場合の超重要注意点: 「フォーマット」メニューから 「標準テキストにする」 を必ず選んでください。これをしないと、プログラムとして動かないファイル(.rtf)になってしまいます。
ステップ2:コードを貼り付ける
以下のコードをすべてコピーして、貼り付けてください。
機能別にモジュール化した方がいいですが、簡略化のためまとめて書いています。
Pythonコード(ここクリックで展開)
import os
import shutil
import streamlit as st
from sentence_transformers import SentenceTransformer
import chromadb
from langchain_ollama import ChatOllama
from langchain_text_splitters import RecursiveCharacterTextSplitter
import fitz # PyMuPDF
from PIL import Image
import hashlib
# --- 設定 ---
BASE_DOC_DIR = "documents"
EMBED_MODEL_NAME = "intfloat/multilingual-e5-base" # 日本語に強いモデル
EMBED_MODEL_LOCAL = "embeddings/multilingual-e5-base"
CHUNK_SIZE = 500
CHUNK_OVERLAP = 100
TOP_K = 10
OLLAMA_MODEL_NAME = "llama3.1"
st.set_page_config(page_title="社内専用RAGチャット", layout="wide")
# --- リソース読み込み ---
@st.cache_resource
def load_embedder():
if os.path.isdir(EMBED_MODEL_LOCAL):
return SentenceTransformer(EMBED_MODEL_LOCAL)
else:
model = SentenceTransformer(EMBED_MODEL_NAME)
model.save(EMBED_MODEL_LOCAL)
return model
@st.cache_resource
def get_llm():
return ChatOllama(
model=OLLAMA_MODEL_NAME,
temperature=0.3,
num_ctx=8192,
repeat_penalty=1.2, # 同じ言葉の繰り返し防止
num_predict=1000,
stop=["### 質問:", "### 参照情報:", "User:", "Assistant:"] # 暴走防止
)
def get_splitter():
return RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "、", " ", ""],
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
length_function=len,
is_separator_regex=False,
)
# --- ロジック関数 ---
def get_safe_collection_name(project_name):
"""日本語のプロジェクト名を、データベース用に安全な英数字に変換する"""
hash_object = hashlib.md5(project_name.encode())
return "proj_" + hash_object.hexdigest()
def save_uploaded_file(uploaded_file, project_path):
try:
file_path = os.path.join(project_path, uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
return file_path
except Exception as e:
st.error(f"ファイル保存エラー: {e}")
return None
def process_file_and_add_to_db(file_path, collection, embedder):
splitter = get_splitter()
filename = os.path.basename(file_path)
# 上書き対策:古いデータを消してから登録
try:
collection.delete(where={"source": filename})
except Exception:
pass
try:
if filename.lower().endswith(".pdf"):
doc = fitz.open(file_path)
text_all = []
for page_num, page in enumerate(doc):
page_text = page.get_text().replace("\n", " ")
if not page_text.strip(): continue
chunks = splitter.split_text(page_text)
if not chunks: continue
docs_for_embed = [f"passage: {c}" for c in chunks]
embeddings = embedder.encode(docs_for_embed, batch_size=32, convert_to_numpy=True)
ids = [f"{filename}_p{page_num+1}_{i}" for i in range(len(chunks))]
metadatas = [{"source": filename, "page": page_num + 1} for _ in chunks]
collection.add(documents=chunks, embeddings=embeddings.tolist(), ids=ids, metadatas=metadatas)
text_all.append(page_text)
return True if text_all else False
elif filename.lower().endswith(".txt"):
with open(file_path, "r", encoding="utf-8") as f:
text = f.read().replace("\n", " ")
chunks = splitter.split_text(text)
if chunks:
docs_for_embed = [f"passage: {c}" for c in chunks]
embeddings = embedder.encode(docs_for_embed, batch_size=32, convert_to_numpy=True)
ids = [f"{filename}_{i}" for i in range(len(chunks))]
metadatas = [{"source": filename, "page": 1} for _ in chunks]
collection.add(documents=chunks, embeddings=embeddings.tolist(), ids=ids, metadatas=metadatas)
return True
return False
except Exception as e:
st.error(f"処理エラー ({filename}): {e}")
return False
def delete_files(files_to_delete, project_path, collection):
deleted_count = 0
for filename in files_to_delete:
try:
collection.delete(where={"source": filename})
except Exception as e:
st.warning(f"DB削除エラー ({filename}): {e}")
file_path = os.path.join(project_path, filename)
if os.path.exists(file_path):
os.remove(file_path)
deleted_count += 1
return deleted_count
def rename_project(old_name, new_name):
old_path = os.path.join(BASE_DOC_DIR, old_name)
new_path = os.path.join(BASE_DOC_DIR, new_name)
if os.path.exists(new_path):
return False, "そのプロジェクト名は既に存在します"
try:
os.rename(old_path, new_path)
client = chromadb.PersistentClient(path="./chroma_db")
try:
old_safe_name = get_safe_collection_name(old_name)
new_safe_name = get_safe_collection_name(new_name)
collection = client.get_collection(name=old_safe_name)
collection.modify(name=new_safe_name)
except ValueError:
pass
return True, "変更しました"
except Exception as e:
return False, f"エラーが発生しました: {e}"
def delete_project(project_name):
client = chromadb.PersistentClient(path="./chroma_db")
safe_name = get_safe_collection_name(project_name)
try:
client.delete_collection(name=safe_name)
except ValueError:
pass
dir_path = os.path.join(BASE_DOC_DIR, project_name)
if os.path.exists(dir_path):
shutil.rmtree(dir_path)
return True
def get_pdf_page_image(file_path, page_number):
try:
doc = fitz.open(file_path)
page = doc.load_page(page_number - 1)
pix = page.get_pixmap(matrix=fitz.Matrix(2, 2))
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
return img
except Exception:
return None
# --- UI構築 ---
def main():
if not os.path.exists(BASE_DOC_DIR):
os.makedirs(BASE_DOC_DIR)
with st.sidebar:
st.header("📂 プロジェクト選択")
projects = [f for f in os.listdir(BASE_DOC_DIR) if os.path.isdir(os.path.join(BASE_DOC_DIR, f))]
project_options = ["(新規作成...)"] + projects
selected_option = st.selectbox("プロジェクト", project_options, index=1 if projects else 0)
if "current_project" not in st.session_state:
st.session_state.current_project = selected_option
if st.session_state.current_project != selected_option:
st.session_state.messages = []
st.session_state.current_project = selected_option
st.rerun()
if selected_option == "(新規作成...)":
new_project_name = st.text_input("新しいプロジェクト名")
if st.button("作成"):
if new_project_name:
os.makedirs(os.path.join(BASE_DOC_DIR, new_project_name), exist_ok=True)
st.rerun()
st.stop()
selected_project = selected_option
project_path = os.path.join(BASE_DOC_DIR, selected_project)
with st.expander("⚙️ プロジェクト設定 (編集・削除)"):
st.caption("名前の変更")
new_name_input = st.text_input("新しい名前", value=selected_project)
if st.button("変更を保存"):
if new_name_input and new_name_input != selected_project:
success, msg = rename_project(selected_project, new_name_input)
if success:
st.success(msg)
st.session_state.current_project = new_name_input
st.rerun()
else:
st.error(msg)
st.markdown("---")
st.caption("プロジェクトの削除")
delete_confirm = st.checkbox("本当に削除しますか?", key="del_confirm")
if delete_confirm:
if st.button("削除を実行する", type="primary"):
delete_project(selected_project)
st.success(f"プロジェクト '{selected_project}' を削除しました")
st.session_state.current_project = None
st.rerun()
st.markdown("---")
st.header("📄 ドキュメント登録")
uploaded_files = st.file_uploader("PDFまたはTXTを追加", type=['pdf', 'txt'], accept_multiple_files=True)
if uploaded_files:
if st.button("アップロードして学習開始"):
embedder = load_embedder()
client = chromadb.PersistentClient(path="./chroma_db")
safe_name = get_safe_collection_name(selected_project)
collection = client.get_or_create_collection(name=safe_name)
progress_bar = st.progress(0)
for i, uploaded_file in enumerate(uploaded_files):
file_path = save_uploaded_file(uploaded_file, project_path)
if file_path:
success = process_file_and_add_to_db(file_path, collection, embedder)
if success:
st.toast(f"✅ {uploaded_file.name} を登録しました")
else:
st.error(f"❌ {uploaded_file.name} の処理に失敗")
progress_bar.progress((i + 1) / len(uploaded_files))
st.success("学習完了!")
st.rerun()
st.markdown("---")
current_files = os.listdir(project_path)
with st.expander(f"🗑️ ファイル管理・削除 ({len(current_files)}件)", expanded=False):
if len(current_files) > 0:
files_to_delete = st.multiselect("ファイル一覧", current_files)
if files_to_delete:
if st.button("選択したファイルを削除する", type="primary"):
client = chromadb.PersistentClient(path="./chroma_db")
safe_name = get_safe_collection_name(selected_project)
collection = client.get_or_create_collection(name=safe_name)
deleted_count = delete_files(files_to_delete, project_path, collection)
if deleted_count > 0:
st.success(f"{deleted_count}件削除しました")
st.rerun()
st.title(f"🤖 {selected_project}")
chat_container = st.container()
with chat_container:
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
with st.form(key="chat_form", clear_on_submit=True):
prompt_input = st.text_area("質問を入力してください(Shift+Enterで改行)", height=100)
submit_button = st.form_submit_button("送信する")
if submit_button and prompt_input:
prompt = prompt_input
st.session_state.messages.append({"role": "user", "content": prompt})
with chat_container:
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
with st.status("🚀 AIが考え中です...", expanded=True) as status:
st.write("🔄 準備中...")
embedder = load_embedder()
llm = get_llm()
st.write("🔍 検索中...")
client = chromadb.PersistentClient(path="./chroma_db")
safe_name = get_safe_collection_name(selected_project)
collection = client.get_or_create_collection(name=safe_name)
query_embedding = embedder.encode([f"query: {prompt}"])[0].tolist()
actual_k = min(TOP_K, collection.count())
docs, metas = [], []
if actual_k > 0:
results = collection.query(query_embeddings=[query_embedding], n_results=actual_k)
docs = results.get('documents', [[]])[0]
metas = results.get('metadatas', [[]])[0]
if not docs:
st.warning("⚠️ 関連する情報が見つかりませんでした。")
status.update(label="検索失敗", state="error", expanded=True)
st.stop()
else:
st.write(f"✅ ヒット: {len(docs)} 件")
st.write("📖 読解中...")
context_list = []
ref_pages = []
seen_pages = set()
for doc, meta in zip(docs, metas):
source = meta.get('source', '不明')
page = meta.get('page', 0)
ref = f"{source} (p.{page})"
context_list.append(f"[Source: {ref}] {doc}")
unique_key = f"{source}_{page}"
if unique_key not in seen_pages and source.endswith(".pdf"):
seen_pages.add(unique_key)
ref_pages.append({"file": source, "page": page})
context = "\n\n".join(context_list)
rag_prompt = (
"あなたは社内専用のAIアシスタントです。以下の「参照情報」に基づいて質問に答えてください。\n"
"回答には必ず根拠となる **[Source: ファイル名 (p.番号)]** を明記してください。\n"
"もし情報がない場合は正直に「情報にありません」と答えてください。\n\n"
f"### 参照情報:\n{context}\n\n"
f"### 質問:\n{prompt}\n\n"
"### 回答:"
)
status.update(label="完了", state="complete", expanded=False)
response_container = st.empty()
full_response = ""
for chunk in llm.stream(rag_prompt):
full_response += chunk.content
response_container.markdown(full_response + "▌")
response_container.markdown(full_response)
if "情報にありません" in full_response or "情報が見つかりません" in full_response:
ref_pages = []
if ref_pages:
with st.expander("📷 参照ページプレビュー", expanded=True):
cols = st.columns(min(len(ref_pages), 3))
for i, ref in enumerate(ref_pages[:6]):
file_path = os.path.join(project_path, ref['file'])
img = get_pdf_page_image(file_path, ref['page'])
if img:
with cols[i % 3]:
st.image(img, caption=f"{ref['file']} (p.{ref['page']})", use_column_width=True)
st.session_state.messages.append({"role": "assistant", "content": full_response})
if __name__ == "__main__":
main()
ステップ3:保存する
ファイルを rag_project フォルダの中に app.py という名前で保存してください。
🤖 第4章:アイコン作成(全自動化)
黒い画面を使わず、アイコンをダブルクリックするだけで起動・停止できるようにします。Macの「Automator」アプリを使います。
1. 起動アプリ(🚀 社内RAG.app)を作る
- Macの Automator を起動し、「新規書類」→「アプリケーション」を選びます。
- 左側の検索バーに「シェル」と入れ、「シェルスクリプトを実行」を右側にドラッグします。
- 以下のコードをコピペします。 ※注意:
cd /Users/user/rag_projectのuserの部分は、あなたのMacのユーザー名に書き換えてください。(ターミナルでwhoamiと打つとわかります)
# パスを通す(ツールを使えるようにする)
export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
# プロジェクトフォルダへ移動(あなたの環境に合わせて書き換えてください!)
cd /Users/user/rag_project
# Ollama(脳みそ)が寝ていたら叩き起こす
if ! pgrep -x "ollama" > /dev/null; then
ollama serve &
sleep 5
fi
# 仮想環境を使ってアプリ起動
source rag_project_env/bin/activate
streamlit run app.py
- 「🚀 社内RAG」 という名前でデスクトップに保存します。
2. 停止アプリ(🛑 RAG停止.app)を作る
同じくAutomatorで新規作成し、以下のコードをコピペします。
# 1. プロセスを強制終了
pkill -f "streamlit run app.py" || true
# 2. 音を鳴らす(バックグラウンドで)
afplay /System/Library/Sounds/Hero.aiff &
# 3. 「2秒後に勝手に消える」メッセージを出す
osascript -e 'display dialog "システムを停止しました 🛑" with title "社内RAGアプリ" buttons {"OK"} default button "OK" giving up after 2'
- 「🛑 RAG停止」 という名前でデスクトップに保存します。
✅ 最終確認:使い方マニュアル
これで準備完了です!以下のように運用してください。
-
起動: 「🚀 社内RAG」 をダブルクリック。
- 黒い画面は出ず、ブラウザが自動で開きます。
-
学習:
- サイドバーの「プロジェクト選択」で名前を決めます(日本語OK)。
- PDFをドラッグ&ドロップし、「アップロードして学習開始」を押します。
-
検索:
- 質問を入力して送信します。
- 回答の下に「参照ページプレビュー」が出るので、元データを確認できます。
-
終了: 「🛑 RAG停止」 をダブルクリック。
- 画面中央に「停止しました」と通知が出れば完了です。
これで、完全ローカル&高機能なRAGシステムの完成です!お疲れ様でした!
カスタム方法
やり方は簡単です。app.pyを生成AIに丸ごと渡して
- このコードを基にもっと精度を上げる方法を教えて
- ○○の機能を追加するコードを書いて
- 各パラメータの役割を教えて
と打ち込むだけです。
それだけで丁寧な回答が得られるはずです。慣れてきたらどんどんやりたいことが出てくると思うので、なんでも生成AIに聞いてみてください。自分だけのオリジナルチャットAIが出来上がっていくでしょう。
最後に
ここまでお付き合いいただきありがとうございました。うまくいきましたら幸いです。
まだまだカスタム要素はいくらでも残っていますが、これくらいだったら使えるかなというレベル感に仕上がっているかと。
私もRAGに関しては素人ですが、今回チャレンジしてみて世界中で活用されているLLMのことが少しわかったようなった気がしています。パラメータの意味や実際にそれがどう検索精度に影響するのか、手を動かしてみることでググッと解像度が高まった感じです。
やっぱり自ら作ることで得られる経験値というのは絶大です。
「何となく生成AIを使っているけどもっとLLMのことを知りたい」「自社でローカルLLMを使ったセキュアな検索アプリを構築したい」という方に今回のガイドが少しでも役に立てればと思います。
他にもLM Studioを使ったやり方などもありますが生成AIをうまく活用してチャレンジしていきましょう!今回はWindowsユーザーの方はごめんなさい。基本的なやり方は大きく変わらないと思いますが、少しだけ環境設定が変わってきます。
生成AIは使い方次第で自身のポテンシャルを最大限に引き上げてくれる良きパートナーになってくれます。
出力された結果を鵜呑みにするのではなく
- なぜそうなるのか?
- このコードはどういう意味か?
を常に意識しAIから学ぶ姿勢を持つことでどんどん成長していける、そんな素晴らしい世界に今僕らは生きているのだと思うとワクワクが止まりません。
AIとの共生の中で作ることを楽しみながら一緒にスキルアップっていきましょう!