はじめに
FORTNITEもシーズン6に入り、弓などの新しい武器が追加されたり、クラフトの要素が追加されたりと雰囲気がガラッと変わりましたね。どんな対戦ゲームでもそうですが、環境がガラッと変わった時は、どういった戦術が効果的か、強い武器はなんなのか、といった情報は誰でも気になるところかと思います。
例えば今回のFORTNITEシーズン6でいえば、実は弓がめちゃくちゃ強くて、みんな弓を使って相手を倒している、なんてことになると、弓対策をしたほうが勝率が上がるかもしれません。
普段からFORTNITEをプレイしており、かつデータサイエンティスト的なことをしている身としてはFORTNITE$\times$データ分析で何か示唆を出してみたいものです。いろんな分析方法は考えられそうですが、今回はFORTNITEのプレイ動画内に表示されている「キルログ」をPythonを使って自動集計してみようと思います。
※以下の画像は実際に私のプレイ動画のキャプチャを使用しております。
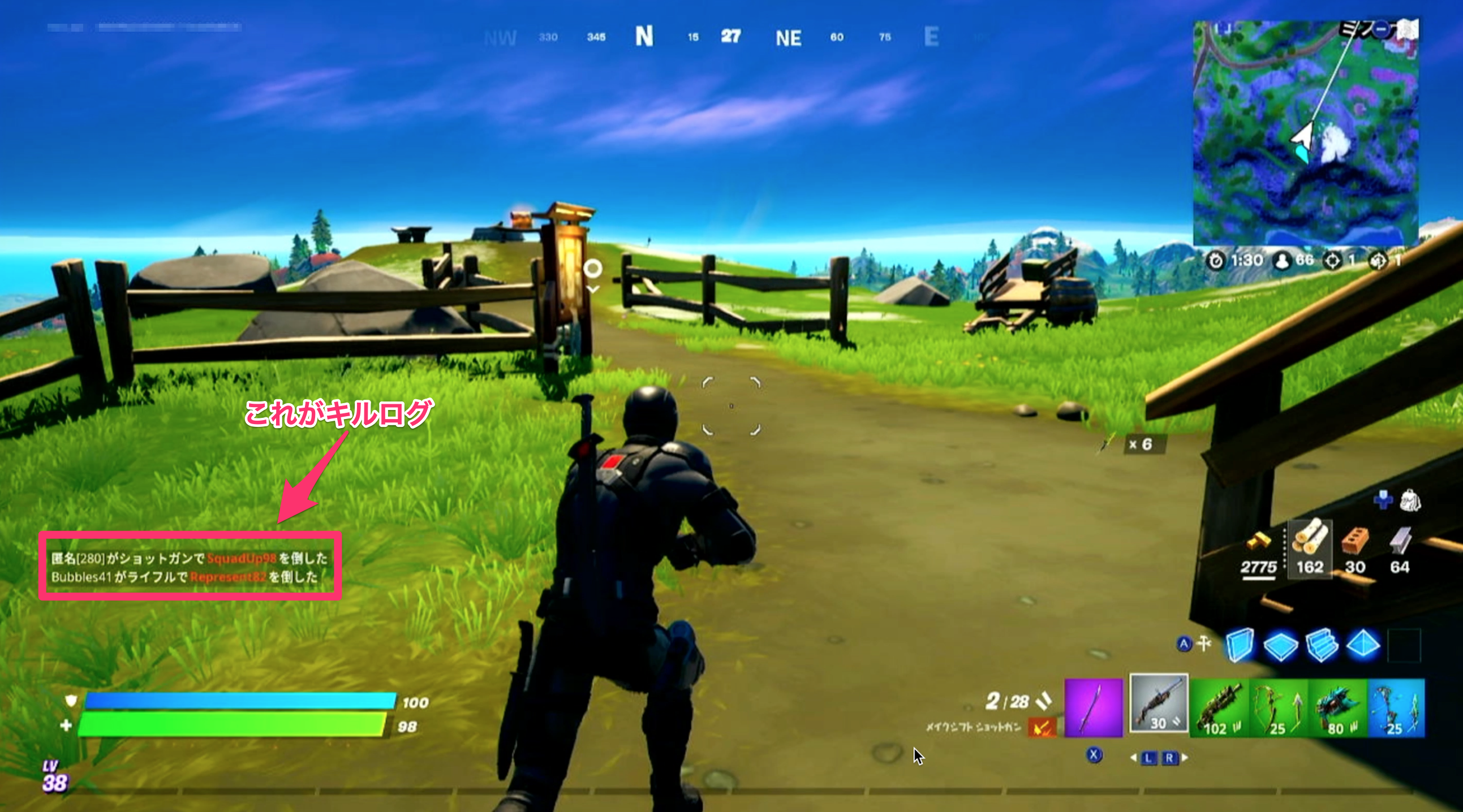
キルログはプレイ画面左下に表示されるテキスト情報で、基本的なフォーマットは「誰がどんな武器で誰を倒した」といった感じになります。(中には最初のバスから飛び降りる際のバスドライバーにお礼をした、とか〇〇が観戦を始めた、とかキル情報以外にもいろんな情報が流れます。)
今回の目的は、このキルログからどんな武器が敵を倒した時の決め手になっているかを集計することとします。もちろんショットガンが一番多いのは想像できるのですが、意外と弓で倒している回数が多いとなると、弓はより警戒したほうがいいってことになるかもしれません。
前提条件と準備
通常のバトロワ(アリーナではない)でソロのモードでプレイした動画で実際に私がプレイしてビクロイが取れたものを使用します。
自分のプレイ環境がPCやPS4とかではなくswitchを使っているので、FORTNITEのプレイ動画をそのままでは録画できません。なので以下のキャプチャーボードを使いました。
自分が購入した時は割引キャンペーン的なことをしてて安価で購入できたのですが、実際使ってみると思った以上に画質が粗々でした...
テキスト情報を抽出する、という観点ではおすすめできないですね。もっと高価なものを購入しておけばよかったと思っています。
技術面の話
ここからは実際にどうやってFORTNITEのプレイ動画からキルログを集計するかの、技術的なお話をしていこうと思います。
※動画データの扱いに不慣れですので、セオリーでない処理をしている可能性があります。変なことしてたらアドバイスいただけると嬉しいです!
まず今回の処理を以下の図のように大きく3ステップで考えることにします。

キルログのテキストデータが抽出されれば、あとは特定のキーワード(武器の名前など)を集計するなりしたら、今回の目的は達成できそうです。とりあえずはこんな感じでシンプルに考えました。
キルログの仕様について
ここでキルログの仕様について簡単に触れておきます。公式とかで仕様を確認したわけではなので、正確ではないかもしれませんが、私が目視で確認した限り以下の仕様になっているかと思います。
- 1つのキルログは最大5秒間画面に表示される
- 1度に表示されるキルログの件数は最大5件まで
- キルログの更新が頻繁の時は5秒待たずに次のキルログに更新される(最初のバスドライバーにお礼をするログを確認する限り)
- 多分改行はない?
実際の対戦中はそこまでキルログが頻繁に更新されることはまぁないと思うので、処理②の画像として保存する動画フレームの間隔は、5秒間に1フレームでよさそうです。キルログの漏れもなければ重複もなくなるはず。
なので、以降の動画を編集する処理にてfps(frames per second)を指定できるのですが、5秒1フレームで良いので、fps=0.2を指定しています。
要素技術
今回は全ての処理をPython上で行いたいと思います。(動画編集ソフトなどは使用しない)
3つのステップを実現するPythonライブラリと参考にした記事は以下の通りです。
① 動画のトリミング
moviepyというライブラリで実現できます。以下の記事で使い方を勉強させていただきました。
「それ、pythonでできるよ」-動画のトリミング-
② 動画の各フレームを画像で保存
OpenCVを使いました。以下の記事がとてもわかりやすかったです。
Python, OpenCVで動画ファイルからフレームを切り出して保存
③ OCR
Tesseractとpyocrを使いました。以下の記事とそのコメントが参考になります。
ColaboratoryでTesseract-OCRを動かしてみる
2021.11.22追記
OCRについて、現在は上記の記事のように日本語学習済みデータをGitから持ってくる必要はなくなっているようで、上記の記事通りではcolab上でpyocrを動かせませんでした。代わりにtesseract-ocr-jpnをaptでインストールするだけで日本語が適用できるようになっているようです。以下の記事を参考にしました!
それでは3ステップを一つ一つ実装していきたいと思います。
実装環境はGoogle Colabを使っており、動画ファイルの格納先はGoogle Driveを使っているので、以下のようにcolabにGoogle Driveをマウントしておきます。
# colabにGoogle Driveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# 動画ファイルの保存先
drive_dir = "/content/drive/MyDrive/Colab Notebooks/FORTNITE/"
①. 動画のトリミング
まずはmoviepyをpipでインストールします。
!pip install moviepy
動画のトリミングはVideoFileClipのcrop関数で実現できます。参考記事ではx2,y2の引数を切り取る長さと表現されていますが、正しくは以下の図のように切り取り終わりのx座標、y座標を指定します。
(なので、x1 $<$ x2, y1 $<$ y2である必要があります。そうでないと正しくファイルを取得できないようです。)

from moviepy.editor import *
# キルログの座標はだいたいこの辺でした
x1= 105 # x座標(x1)
y1 = 1150 #y座標(y1)
x2 = 1000 # x座標(x2)
y2 = 1400 # y座標(y2)
# 入力動画ファイル名
input_name = drive_dir + "fortnite_jpn.mov"
# 保存ファイル名
output_name = drive_dir + "fortnite_kill_log_fps0.2.mp4"
# キルログの部分だけになるようにトリミング実施
video = VideoFileClip(input_name).crop(x1=x1,y1=y1,x2=x2,y2=y2)
# 5秒間で1フレームになるようにfps=0.2で動画を保存する
video.write_videofile(output_name,fps=0.2)
上の処理で切り取られる動画は以下のような感じになります。
プレイ動画の最初10秒だけを切り取って、キルログ部分だけをトリミングしたものを5秒1フレームで保存したものです。
まぁだいたいキルログだけになってるかな。

②. 動画の各フレームを画像で保存
cv2.VideoCaptureにフレームを画像化したい動画ファイルを渡します。read関数で1フレームずつ順番に画像を取得でき、それをcv2.imwriteで1枚ずつ保存しています。
import cv2
import os
# キルログだけにトリミングした動画データ
input_name = drive_dir + "fortnite_kill_log_fps0.2.mp4"
cap = cv2.VideoCapture(input_name)
cap_num = 0
while True:
ret, frame = cap.read()
if ret:
cv2.imwrite(drive_dir + "capture/fortnite_capture_"+str(cap_num)+".jpg", frame)
else:
break
cap_num +=1
③. OCR
以下のようにTesseractとpyocrをcolab上にインストールします。
上でも書きましたが、現在は日本語に適用させるためにGitからjpn.traineddataを持ってくる必要はなく、tesseract-ocr-jpnをaptでインストールすることでcolab上でも動かせました。
!apt install tesseract-ocr
!apt install libtesseract-dev
!apt install tesseract-ocr-jpn
!pip install pyocr
以下で日本語が利用可能かを確認しつつ、処理②で取得した画像の何枚かをOCRにかけてみます。
from PIL import Image
from glob import glob
import sys
import pyocr
import pyocr.builders
import numpy as np
import matplotlib.pyplot as plt
tool = pyocr.get_available_tools()[0]
# OCR対応言語を表示
langs = tool.get_available_languages()
print(langs)
# ['eng', 'jpn', 'osd']
# 画像ファイル名を指定すれば抽出されたテキストを返す関数を用意
def ocr(image_file_path):
return tool.image_to_string(
Image.open(image_file_path),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
# OCRを試してみる画像ファイルを指定
test_name = drive_dir + "capture/fortnite_capture_2.jpg"
# 画像ファイルを表示用に読み込んでおく
img = cv2.imread(test_name)
# 画像を表示させてみる
plt.title("original image")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
# OCR結果
print(ocr(test_name))

抽出されたテキスト
ー w は オ e グ ダ ② a る リ P て
'囃が丿jス ド ラ イ バ ー に お 礼 を し た ま い り
墟バスドヲイバー化ぉ札誉 ⑧ /
- が バ ス ド ラ イ バ ー に お 礼 を し た | W
カ ン と と 0 ュ コ 綱 誠 言 國 談 言 闇 闇
の R①②①①①⑪① と れ と と か は ュ ユ コ 0 い ① 防
ノ に ー ン シ 誠 し い \ ぁ ゃ 報 ク ド 、

抽出されたテキスト
ー ペ 蛹
匯 名 [②⑧0」 が シ ョ ッ ト ガ ン で Tacoliands③③ を 倒 し た
ド と タ リ ン ト に し マ レ ス ③ は 再 コ `\ 談 談
FireCheeks⑤⑥ が シ ョ ッ ト ガ ン で Ramipage⑦① を 側 し た
HoorayBeets が シ ョ ッ ト ガ ン で PsyonicOx を 倒 し た
LuckyNumber④②⑦⑨ が SMG で solocamperl を 倒 し た h

抽出されたテキスト
' 沼鉄 談 侵 グ ー 継 ⑧ ② ス 、 縄
G喇鴨がシヨ キ ル ム WWTIYTYTL ① [ 詞 詞 談
沼 ⑦ ビ E ベ ュ ノ レ ④ コ ン P ム 閻 談 00 コ ①.① 0 副 闇 論
が ご _
誌 ー ン ー ペ ョ
背景を変に認識してしまい、抽出されたテキストはぐちゃぐちゃな結果になりました。正直これではキルログの集計は不可能です。画質がそもそもあまりよくないのもありますが、画像データに対してなんの前処理も加えていなければ、まぁこうなるよねって感じの結果です。
この手の処理でよくやる前処理としては、画像をグレースケールにしたり、画像の2値化(白と黒の2色だけにする)が挙げられるかと思われるので、以下の記事を参考にOpenCVで画像の2値化を前処理として加えてみます。
【Python】OpenCVとpyocrで画像から文字を認識してみる
# オリジナル
plt.title("original image")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
# オリジナル画像のOCR結果
print(ocr(drive_dir + "capture/"+ test_name))
# グレースケール
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.title("gray scale image")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
# 画像を保存
cv2.imwrite(drive_dir + "capture_gray_scale/" + test_name, img)
# グレースケール画像のOCR結果
print(ocr(drive_dir + "capture_gray_scale/" + test_name))
# 2値化
th = 150
img = cv2.threshold(img ,th, 255 ,cv2.THRESH_BINARY)[1]
plt.title("binarization image")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
# 画像を保存
cv2.imwrite(drive_dir + "capture_binarization/" + test_name, img)
# 2値化処理画像のOCR結果
print(ocr(drive_dir + "capture_binarization/" + test_name))

正直まだまだ変な認識をたくさんしてはいますが、前処理なしの状態と比べればかなり認識率が上がっていることがわかります。カタカナなんかは特にましになっています。武器名は基本カタカナなのでまぁ一旦はこれでいいでしょう。
全ての画像データに対して、2値化処理を加えて別途保存しておきます。
# 全画像データに対して2値化処理を加えて保存する
th = 150
cap_file_list = glob(drive_dir+"capture/*")
for image_name in cap_file_list:
# 画像データ読み込み
img = cv2.imread(image_name)
# グレースケールに変換
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2値化
img = cv2.threshold(img ,th, 255 ,cv2.THRESH_BINARY)[1]
# 画像を保存する
cv2.imwrite(drive_dir + "capture_binarization/" + image_name.split("/")[-1], img)
2値化された全画像データに対してOCRをかけます。OCRの結果を配列に格納しておきます。
from tqdm import tqdm
# 全画像データをOCRにかける
cap_file_list = glob(drive_dir+"capture_binarization/*")
all_kill_log = []
for image_name in tqdm(cap_file_list):
kill_log = ocr(image_name).split("\n")
all_kill_log += kill_log
キルログの集計
あとはキルログから各武器名の出現回数を算出するだけです。正直FORTNITEの全ての死因におけるキルログの表記のされ方を知らないので、今回はとりあえず「ライフル、ショットガン、サブマシンガン、ピストル、弓、収集ツール」の6つのキルパターンを集計することにしました。
あとは愚直に特定のキーワードを含むキルログを集計しました。OCRでありがちな表記揺れを考慮しながらカウントしています。
kill_pattern = {
"ライフル":0, # ライフルで倒した回数
"ショットガン":0, # ショットガンで倒した回数
"SMG":0, # サブマシンガンで倒した回数
"ピストル": 0, # ピストルで倒した回数
"弓": 0, # 弓で倒した回数
"つるはし":0 # 収集ツールで倒した回数
}
for log in all_kill_log:
# 文字間にスペースが入りがちなので、スペースを除去
log = log.replace(" ", "")
# ライフル
if "ライフル" in log or "ライブル" in log or "ライプル" in log:
kill_pattern["ライフル"] += 1
# ショットガン
elif "ショット" in log or "シヨツト" in log:
kill_pattern["ショットガン"] += 1
# サブマシンガン
elif "SM" in log or "MG" in log:
kill_pattern["SMG"] += 1
# ピストル
elif "ピストル" in log or "ビストル" in log "ヒストル" in log:
kill_pattern["ピストル"] += 1
# 弓
# 弓だけはなぜか具体的な武器名が表示されるようです。
# 弓の武器名は全て〜〜ボウなので、ボウを探します。
elif "ボウ" in log or "ポウ" in log or "ボク" in log or "ポク" in log:
kill_pattern["弓"] += 1
# 収集ツールで倒すと「殴って倒した」と表記されます。
# つるはし
elif "殴" in log:
kill_pattern["つるはし"] += 1
結果は次のようになりました!
|武器名|回数|
|:|:|
|ショットガン|33|
|ライフル|19|
|サブマシンガン|2|
|弓|2|
|ピストル|1|
|収集ツール|1|
合計数が58なので、検知漏れが大量にありそうですが、相対的な差としては大体こんなもんですかね。ショットガンやライフルが多いのは当たり前ですが、弓でもしっかり倒している人がいるようです。
おわりに
動画の画質がよければ、ある程度正確に集計できそうかなーなんて思いました。キルログの集計をPythonでぱぱっと行うなら、こんな感じかなーと体験することができて楽しかったです。
今回はOCRの精度がいまいちだったこともあり、この集計結果から何か示唆が出るか、というと怪しいですが、これをたくさんのプレイ動画で集計し続けたらなにか面白いことがわかる?かも。
FORTNITEを題材としたデータ分析をもっといろいろやってみたい。
おわり