はじめに
Deep Learningのモデルを軽量化する手法に、知識の蒸留(Knowledge Distillation) という考え方があります。
知識の蒸留の考え方については、以下の記事が非常に参考になります。蒸留って何?という方は、まずはこちらを見てほしいです。
本記事では上記のような知識の蒸留の考え方で本当に精度を保ちつつ、モデルの軽量化が行えるのか、実際に実装しながら確かめてみました。
実験する内容としては、
- 扱うタスクはlivedoorニュースコーパスのニュース記事のタイトル文をカテゴリーに分類するタスク
- 教師モデルは東北大BERTモデルをファインチューニングしたもの
- 生徒モデルはTransformerブロックが2層だけの小さいBERT(詳細は後述)
とします。
まずは教師モデルを用意する
東北大BERTモデルにクラス分類を行うためのLinear層を1層追加したモデルを教師モデルとします。まずは教師モデルを学習するところまでをざっと紹介します。
前回の記事で紹介したhuggingfaceのTrainerクラスをガッツリ使った実装になってます。Trainerクラスの使い方よくわからん、って方はこちらの記事もぜひご覧ください。Trainerクラスを使い始めてから実装のスピードが飛躍的に上がりました。ものすごく便利だと思います。
上のTrainerクラス紹介記事と似たような実装をしているのでデータの準備、Dataset, DataCollatorの定義、モデルの定義に関する実装例は閉じておきます。
詳細をご確認頂く場合はこちらをクリックしてください。
データの準備
import pandas as pd
from sklearn.model_selection import train_test_split
# 事前にlivedoorニュースコーパスをカテゴリー、本文、タイトルに分けておいたデータフレームを用意しておきます。
df = pd.read_pickle('./livedoor_data.pickle')
# カテゴリーのID列を付与しておく
categories = df['category'].unique().tolist()
category2id = {cat: categories.index(cat) for cat in categories}
df['category_id'] = df['category'].map(lambda x: category2id[x])
train_df, eval_df = train_test_split(df, train_size=0.8)
print('train size', train_df.shape)
print('eval size', eval_df.shape)
# train size (5900, 4)
# eval size (1476, 4)
# 後ほど使う用に学習・検証データをcsvファイルで保存しておきます。
train_df.to_csv('train.csv', index=False)
eval_df.to_csv('eval.csv', index=False)
Dataset、DataCollatorを定義する
from tqdm import tqdm
import torch
from torch.utils.data import Dataset
from transformers import AutoTokenizer
class LivedoorDataset(Dataset):
"""
livedoorニュースのタイトルとカテゴリーIDを辞書形式で格納します。
Datasetの時点ではタイトルはテキストのまま格納しています。
"""
def __init__(self, df):
self.features = [
{
'title': row.title,
'labels': row.category_id
} for row in tqdm(df.itertuples(), total=df.shape[0])
]
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx]
class LivedoorCollator():
"""
ミニバッチを取り出すときに呼び出されます。
このときにTokenizerでテキストをidのテンソルに変換しています。
huggingfaceのTrainerクラスのデフォルトの仕様に合わせて、目的変数のキーをlabelsとしています。
"""
def __init__(self, tokenizer, max_length=512):
self.tokenizer = tokenizer
self.max_length = max_length
def __call__(self, examples):
examples = {
'title': list(map(lambda x: x['title'], examples)),
'labels': list(map(lambda x: x['labels'], examples))
}
encodings = tokenizer(examples['title'],
padding=True,
truncation=True,
max_length=self.max_length,
return_tensors='pt')
encodings['labels'] = torch.tensor(examples['labels'])
return encodings
モデルを定義
import torch.nn as nn
from transformers.modeling_outputs import ModelOutput
class LivedoorNet(nn.Module):
"""
huggingfaceのTrainerクラスの仕様に合わせて、
- モデル内で損失を計算できるようにする
- 戻り値をModelOutputにしている
- 予測値をlogitsというキーに格納している
"""
def __init__(self, pretrained_model, num_categories, loss_function=None):
super().__init__()
self.bert = pretrained_model
self.hidden_size = self.bert.config.hidden_size
self.linear = nn.Linear(self.hidden_size, num_categories)
self.loss_function = loss_function
def compute_loss(self, state, labels):
"""
CrossEntropyLossを想定していますが、
後にloss関数を変更して、このクラスを使用したりしたいので、
loss関数に合わせた入力が行えるようにlossを計算するところをあえて関数化しています。
"""
return self.loss_function(state, labels)
def forward(self,
input_ids,
attention_mask=None,
position_ids=None,
token_type_ids=None,
output_attentions=False,
output_hidden_states=False,
labels=None):
outputs = self.bert(input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
token_type_ids=token_type_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states)
state = outputs.last_hidden_state[:, 0, :]
state = self.linear(state)
loss = None
if labels is not None and self.loss_function is not None:
loss = self.compute_loss(state, labels)
attentions = None
if output_attentions:
attentions = outputs.attentions
hidden_states = None
if output_hidden_states:
hidden_states = outputs.hidden_states
return ModelOutput(
logits=state,
loss=loss,
last_hidden_state=outputs.last_hidden_state,
attentions=attentions,
hidden_states=hidden_states
)
メトリクスを計算する関数を用意
from transformers import EvalPrediction
from sklearn.metrics import precision_score, recall_score, f1_score
def custom_compute_metrics(res: EvalPrediction):
# res.predictions, res.label_idsはnumpyのarray
pred = res.predictions.argmax(axis=1)
target = res.label_ids
precision = precision_score(target, pred, average='macro')
recall = recall_score(target, pred, average='macro')
f1 = f1_score(target, pred, average='macro')
return {
'precision': precision,
'recall': recall,
'f1': f1
}
教師モデルの学習
上であれこれ定義したものを順番に宣言して、全部Trainerクラスに突っ込んで学習させます。
from transformers import Trainer, TrainingArguments
from transformers import EarlyStoppingCallback
# 学習・検証データのDatasetを作成
train_dataset = LivedoorDataset(train_df)
eval_dataset = LivedoorDataset(eval_df)
# 東北大BERTのTokenizerを宣言
tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# collatorクラスを宣言
livedoor_collator = LivedoorCollator(tokenizer)
# 事前学習済の東北大BERTモデルを用意
pretrained_model = AutoModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# 教師モデルを用意
loss_fct = nn.CrossEntropyLoss()
teacher_net = LivedoorNet(pretrained_model, len(categories), loss_fct)
# Trainerクラスにわたす引数色々を宣言
training_args = TrainingArguments(
output_dir='./output/teacher',
evaluation_strategy='epoch',
logging_strategy='epoch',
label_names=['labels'],
save_strategy='epoch',
lr_scheduler_type='constant',
metric_for_best_model='f1',
save_total_limit=1,
load_best_model_at_end=True,
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
num_train_epochs=30,
remove_unused_columns=False
)
trainer = Trainer(
model=teacher_net,
tokenizer=tokenizer,
data_collator=livedoor_collator,
compute_metrics=custom_compute_metrics,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
)
# 学習開始
trainer.train(ignore_keys_for_eval=['last_hidden_state', 'hidden_states', 'attentions'])
# 学習が終わったらファインチューニング済のモデルを学習のログ情報を保存
trainer.save_state()
trainer.save_model()
私の環境では上記の学習方法で教師モデルの精度(ベストスコア)はEpoch4でF1スコア0.89ほどになりました。
比較用に蒸留なしで小さいBERTを1から学習してみる
知識の蒸留がどれだけ効いているかを確認するために、まずは生徒モデルとして想定している小さいBERTを蒸留の考え方なしに1から学習させてみます。
BERTのアーキテクチャーをしたモデルはBertConfigで柔軟に対応できますね。今回用意する生徒モデルは
- Transformerブロックが2層(教師は12層)
- Multi−head Attentionのhead数は4つ(教師は12個)
- 内部の次元数は512(教師は768)
- FeedForward Networkの中間層の次元数は512(教師は3072)
としました。
from transformers import BertConfig, BertModel
student_config = BertConfig(
vocab_size=tokenizer.vocab_size,
hidden_size=512,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=512,
)
# 上記のアーキテクチャーをしたBERTモデルを宣言
# パラメータはinitialの状態
small_bert = BertModel(student_config)
small_net = LivedoorNet(small_bert, num_categories=len(categories), loss_function=loss_fct)
学習は教師モデルと同様にTrainerクラスでさくっと行います。
training_args = TrainingArguments(
output_dir='./output/student_no_distillation',
evaluation_strategy='epoch',
logging_strategy='epoch',
label_names=['labels'],
save_strategy='epoch',
lr_scheduler_type='constant',
metric_for_best_model='f1',
save_total_limit=1,
load_best_model_at_end=True,
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
num_train_epochs=30,
remove_unused_columns=False
)
trainer = Trainer(
model=small_net,
tokenizer=tokenizer,
data_collator=livedoor_collator,
compute_metrics=custom_compute_metrics,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
)
# 学習開始
trainer.train(ignore_keys_for_eval=['last_hidden_state', 'hidden_states', 'attentions'])
# 学習済モデルと学習ログを保存
trainer.save_model()
trainer.save_state()
私の環境では上記の学習でEpoch11でF1スコアが0.77ほどになりました。教師モデル(F1:0.89)とは大幅に劣る結果となりました。
ただこの小さいモデルのサイズ(保存されたpytorch_model.binのサイズ)は77MBなのに対し、教師モデルのサイズは423MBなので、モデルはしっかりと軽量化されています。
知識蒸留の考え方で生徒モデルを学習させる
参考記事を見るに、知識蒸留といっても色々な手法があるようですが、ここでは教師モデルのsoftなラベルにおける予測結果を生徒モデルに教える方針を取ります。(知識蒸留としては最もスタンダードな蒸留方法かな?)
まずは先程学習した教師モデルを用意
pretrained_model = AutoModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
teacher_model = LivedoorNet(pretrained_model, len(categories), loss_function=None)
teacher_model.load_state_dict(torch.load('./output/teacher/pytorch_model.bin'))
温度付きSoftmaxを使って教師モデルの予測結果をならした確率分布を生徒のラベルにする
知識蒸留の考え方の大事なところの1つは、教師の持つ知識(教師モデルの各ラベルの予測確率)をどれだけ生徒に継承できるかです。
それを調整する重要な要素は参考記事にもあるように温度付きSoftmaxの温度パラメータですかね。今回の実験では温度パラメータを何パターンか試してみて、どれくらい教師モデルの予測結果を熱して蒸留するのが良いのか確認してみようと思います。
蒸留用のDatasetを用意
まずはDatasetの準備なのですが、上の実装で使っていたDatasetクラスは正解ラベルがカテゴリーIDでした。
しかし、蒸留をする際は教師モデルの予測結果を温度付きSoftmaxに通したものを正解ラベルとしたいので、Datasetクラスの段階では学習データのタイトル文を教師モデルに通したlogit(Softmax通す前の状態)で一旦保持するようにしました。
class DistillLivedoorDataset(Dataset):
def __init__(self, df, tokenizer, teacher_model, device):
self.features = []
for row in tqdm(df.itertuples(), total=df.shape[0]):
title = row.title
input_ids = tokenizer(title,
truncation=True,
max_length=512,
return_tensors='pt')['input_ids']
input_ids = input_ids.to(device)
teacher_model.eval()
teacher_model.to(device)
with torch.no_grad():
teacher_logits = teacher_model(input_ids).logits[0]
self.features.append({
'title': title,
'labels': teacher_logits.cpu()
})
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_distill_dataset = DistillLivedoorDataset(train_df, tokenizer, teacher_model, device)
eval_distill_dataset = DistillLivedoorDataset(eval_df, tokenizer, teacher_model, device)
Datasetの中身を確認するとこんな状態になってます。
print(train_distill_dataset[0])
# {'title': '【Sports Watch】斎藤佑樹が“イチロー化しつつある”',
# 'labels': tensor([-1.7939, -1.6529, -0.2352, -2.0816, 0.2937, -0.9128, 9.8194, -1.4500,
# -0.5878])}
温度パラメータを調整できるDataCollatorを用意する
DataCollatorでミニバッチデータを取り出すときに、上のDatasetのlabelsの中身を温度付きSoftmaxに通して分布をならすようにしました。このならされた確率分布が生徒モデルの正解ラベルになります。
class DistillLivedoorCollator():
def __init__(self, tokenizer, max_length=512, temperature=1):
self.tokenizer = tokenizer
self.max_length = max_length
self.temperature = temperature
self.softmax = nn.Softmax()
def __call__(self, examples):
examples = {
'title': list(map(lambda x: x['title'], examples)),
'labels': list(map(lambda x: self.softmax(x['labels'] / self.temperature), examples))
}
encodings = tokenizer(examples['title'],
padding=True,
truncation=True,
max_length=self.max_length,
return_tensors='pt')
encodings['labels'] = torch.stack(examples['labels'])
return encodings
distill_collator = DistillLivedoorCollator(tokenizer, temperature=5)
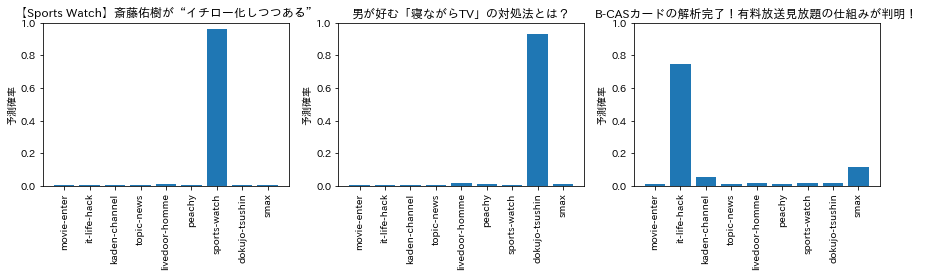
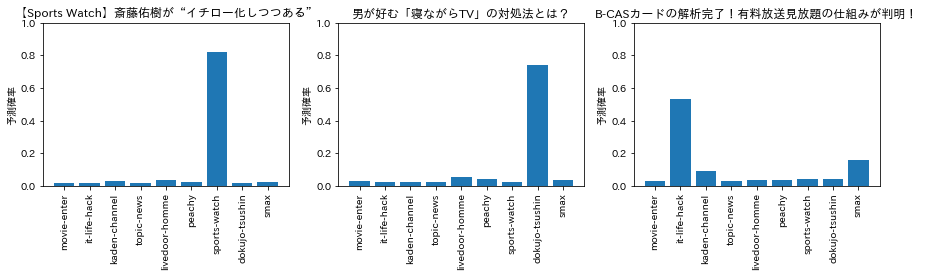
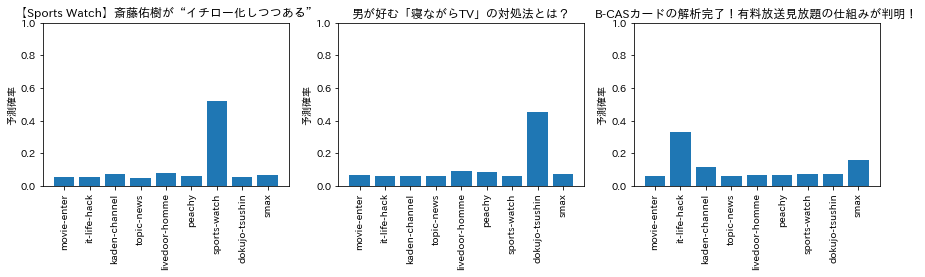
ちなみに今回の教師モデルの予測結果を温度付きSoftmaxに通すとどんな分布になるのかを温度パラメータを調整しながらいくつかプロットしてみると下図のような感じになりました。
-
temperature = 1

-
temperature = 2
-
temperature = 3
-
temperature = 5
-
temperature = 10
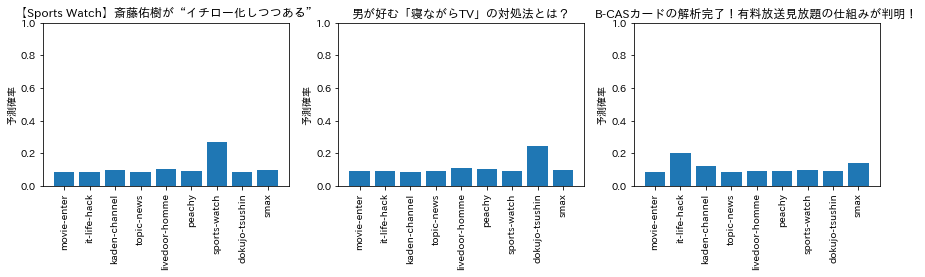
temperature = 1,2,3くらいはほとんどハードラベルって感じですが、temperature = 10くらいまでいくとだいぶ分布がならされた様子が伺えます。こんなんで本当に学習うまくいくのか?とやや懐疑的ですが、今回の実験では上記の各温度でそれぞれ生徒モデルを作成してみようと思います。
生徒モデルを用意する
今回の実験では教師モデルの予測確率と生徒モデルの予測確率の損失の計算としてKLDivLossを採用しました。
教師モデルで使ったクラスをそのまま使いたいですが、lossの計算がCrossEntropyLossを想定した書き方になっていたので、クラスの内部で用意しておいたcompute_lossをKLDivLoss用に書き換える形で、LivedoorNetクラスを継承して宣言することにします。
import torch.nn.functional as F
class DistillLivedoorNet(LivedoorNet):
def compute_loss(self, state, labels):
return self.loss_function(F.softmax(state).log(), labels)
loss_fct = nn.KLDivLoss()
# 先程実験した蒸留なしの小さいBERTモデルを宣言するときに使ったconfigと同じものを使っています。
small_bert = BertModel(student_config)
student_distill_net = DistillLivedoorNet(small_bert,
num_categories=len(categories),
loss_function=loss_fct)
metricsの関数も書き換えておく
このままだとバッチ内の正解ラベルが教師モデルの予測確率の分布(ソフトなラベルの状態)になっているので、検証データのメトリクスを計算するときは検証データの正解のハードラベルを渡すようにしています。
(こんな書き方絶対良くないなぁと思いながら、他に良い実装方法がパッと思いつかなかったので、とりあえずこれで...)
def distill_custom_compute_metrics(res: EvalPrediction) -> Dict:
pred = res.predictions.argmax(axis=1)
target = eval_df['category_id'].tolist()
precision = precision_score(target, pred, average='macro')
recall = recall_score(target, pred, average='macro')
f1 = f1_score(target, pred, average='macro')
return {
'precision': precision,
'recall': recall,
'f1': f1
}
生徒モデルを学習
あとはTrainerクラスにつっこんで終わりですね。
training_args = TrainingArguments(
output_dir='./output/student_distillation_t5',
evaluation_strategy='epoch',
logging_strategy='epoch',
label_names=['labels'],
save_strategy='epoch',
lr_scheduler_type='constant',
metric_for_best_model='f1',
save_total_limit=1,
load_best_model_at_end=True,
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
num_train_epochs=30,
remove_unused_columns=False
)
trainer = Trainer(
model=student_distill_net,
tokenizer=tokenizer,
data_collator=distill_collator,
compute_metrics=distill_custom_compute_metric
args=training_args,
train_dataset=train_distill_dataset,
eval_dataset=eval_distill_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
)
# 学習開始
trainer.train(ignore_keys_for_eval=['last_hidden_state', 'hidden_states', 'attentions'])
# 学習済モデルと学習ログを保存
trainer.save_model()
trainer.save_state()
精度比較
教師モデル、蒸留なしの生徒のみモデル、蒸留あり(T=1,2,3,5,10)の生徒モデルの検証データのF1スコアのEpoch毎の推移を比較するとこんな感じになりました。
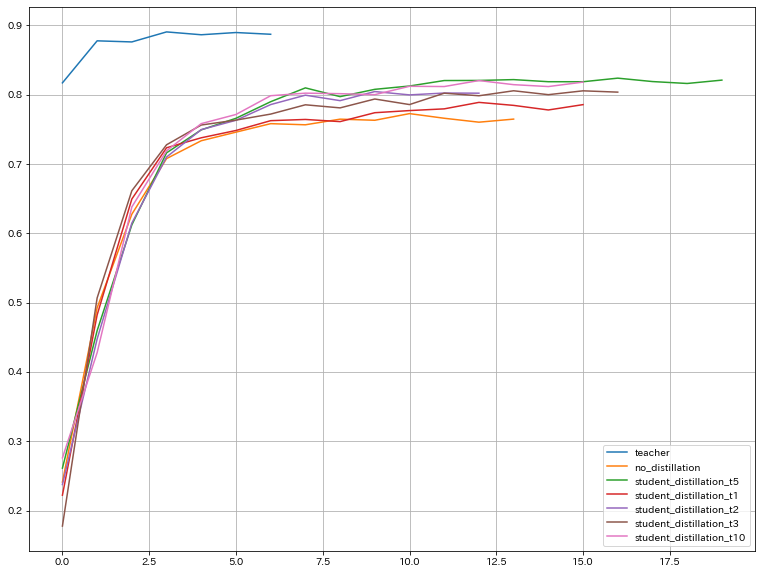
それぞれのモデルのベストスコアなどをまとめると以下のような結果に。
| モデル | モデルサイズ p(ytorch_model.binのサイズ) |
推論速度 (mean_eval_runtime) |
ベストスコア (F1) |
|---|---|---|---|
| 教師モデル | 423MB | 0.843s | 0.890 |
| 生徒モデル(蒸留なし) | 77MB | 0.485s | 0.773 |
| 生徒モデル(蒸留あり、T=1) | 77MB | 0.547s | 0.789 |
| 生徒モデル(蒸留あり、T=2) | 77MB | 0.552s | 0.805 |
| 生徒モデル(蒸留あり、T=3) | 77MB | 0.558s | 0.806 |
| 生徒モデル(蒸留あり、T=5) | 77MB | 0.543s | 0.824 |
| 生徒モデル(蒸留あり、T=10) | 77MB | 0.558 | 0.821 |
ベストスコアが 教師モデル>蒸留あり>蒸留なし となるのは良いとして、蒸留ありのときの温度パラメータはT=5,10あたりが良さげな結果になりました。教師の予測確率の分布は割とならしたほうが良いんだなぁという勘所を知ることができました。逆に小さい温度で蒸留(ほとんどハードラベル)しても、蒸留なしよりかは精度が良くなることも確認できました。
おまけ
生徒同士で教え合うDeep Mutual Learningを試してみる
最後に参考記事でも紹介されている生徒同士で教え合う学習方法も実装して検証してみました。
学習アーキテクチャーは下図の通りです。
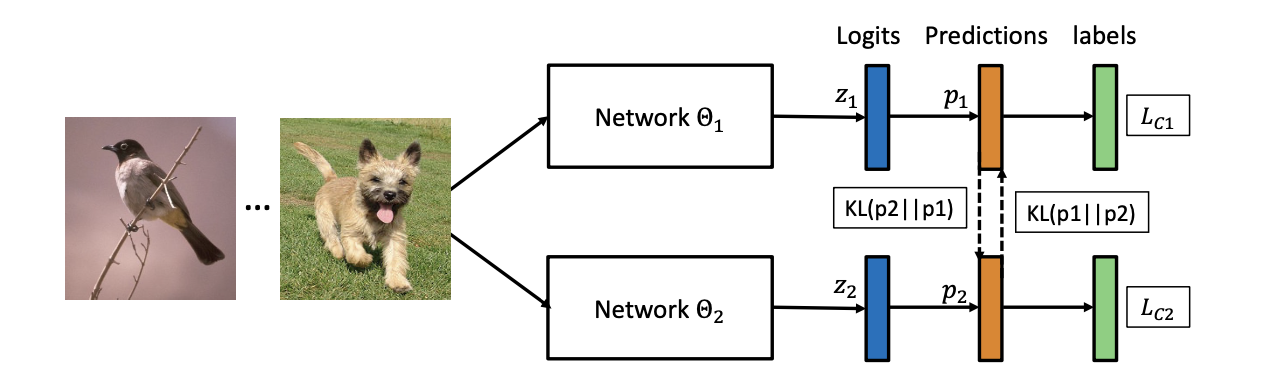
教師モデルを使わず、複数の生徒モデルを同時に学習させます。
そのときにお互いの答えが似た回答になるように教え合いながら学習させる方式です。
以下のようにこのDeep Mutual Learningを実装してみました。Trainerクラスを使って複数のモデルを別々のLossで同時に学習させる方法がわからなかった(そもそもそんなことできる?)ので、Trainerクラスは使わずに実装しています。
モデルを用意するところ
student1_config = BertConfig(
vocab_size=tokenizer.vocab_size,
hidden_size=512,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=512,
)
# 生徒2のinitializer_rangeを少しいじっています。
# 生徒1と全く同じ(デフォルトは0.02)よりも少し変更したほうが良い結果となったので。
student2_config = BertConfig(
vocab_size=tokenizer.vocab_size,
hidden_size=512,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=512,
initializer_range=0.05
)
# Loss関数は2つ使います。
cross_entropy_loss = nn.CrossEntropyLoss()
kldiv_loss = nn.KLDivLoss() # 生徒同士の予測確率を近づける学習に使います
student1 = LivedoorNet(BertModel(student1_config), len(categories), loss_function=cross_entropy_loss)
student2 = LivedoorNet(BertModel(student2_config), len(categories), loss_function=cross_entropy_loss)
student1.cuda()
student2.cuda()
optimizer1 = optim.Adam(student1.parameters(), lr=5e-5)
optimizer2 = optim.Adam(student2.parameters(), lr=5e-5)
train_loader = DataLoader(train_dataset, collate_fn=livedoor_collator, batch_size=128, shuffle=True)
eval_loader = DataLoader(eval_dataset, collate_fn=livedoor_collator, batch_size=128, shuffle=False)
学習するところ
Lossの計算を少しアレンジしています。論文の4,5式の$D_{KL}$の重み付けをするパラメータ$\lambda$を導入しています。
$$
L_{\Theta_1} = L_C + \lambda \cdot D_{KL}(\boldsymbol p_2 || \boldsymbol p_1)
$$
というのも重み付けなし、$L_C$を重み付け、$D_{KL}$を重み付けのパターンを色々確かめていると、$D_{KL}$を重み付けしたときは一番精度が良い結果となったから、って理由です。こういうマルチタスク学習みたいなことをするときの各Lossの重み付けは解くタスクによっても全然違う気がするので、都度調整が必要かなー。
Trainerクラスを使っていないので、学習コードが非常に汚いですが、ご容赦ください...
EPOCH_NUM = 30
best_metrics = 0.0
early_stopping_patience = 3
stop_count = 0
co_loss_weight = 5
student1_train_epoch_loss = {
'ce_loss': [],
'kl_loss': [],
'total_loss': []
}
student2_train_epoch_loss = {
'ce_loss': [],
'kl_loss': [],
'total_loss': []
}
student1_eval_metrics = {
'precision': [],
'recall': [],
'f1': []
}
student2_eval_metrics = {
'precision': [],
'recall': [],
'f1': []
}
for epoch in range(EPOCH_NUM):
student1_train_step_loss = {
'ce_loss': [],
'kl_loss': [],
'total_loss': []
}
student2_train_step_loss = {
'ce_loss': [],
'kl_loss': [],
'total_loss': []
}
student1.train()
student2.train()
for batch in tqdm(train_loader):
# インプットのテンソルをGPUに移動
batch = {k:v.cuda() for k,v in batch.items()}
optimizer1.zero_grad()
optimizer2.zero_grad()
student1_outputs = student1(**batch)
student2_outputs = student2(**batch)
student1_prob = F.softmax(student1_outputs.logits, dim=1)
student2_prob = F.softmax(student2_outputs.logits, dim=1)
# お互いの予測確率の分布が近くなるようにlossを計算
student1_kldiv_loss = kldiv_loss(student1_prob.log(), student2_prob)
student2_kldiv_loss = kldiv_loss(student2_prob.log(), student1_prob)
student1_loss = student1_outputs.loss + student1_kldiv_loss*co_loss_weight
student2_loss = student2_outputs.loss + student2_kldiv_loss*co_loss_weight
student1_loss.backward(retain_graph=True)
student2_loss.backward()
optimizer1.step()
optimizer2.step()
student1_train_step_loss['ce_loss'].append(student1_outputs.loss.item())
student1_train_step_loss['kl_loss'].append(student1_kldiv_loss.item())
student1_train_step_loss['total_loss'].append(student1_loss.item())
student2_train_step_loss['ce_loss'].append(student2_outputs.loss.item())
student2_train_step_loss['kl_loss'].append(student2_kldiv_loss.item())
student2_train_step_loss['total_loss'].append(student2_loss.item())
for k,v in student1_train_step_loss.items():
student1_train_epoch_loss[k].append(sum(v)/len(v))
for k,v in student2_train_step_loss.items():
student2_train_epoch_loss[k].append(sum(v)/len(v))
print('EPOCH', epoch)
print('student1: ce_loss', student1_train_epoch_loss['ce_loss'][epoch],
'kl_loss', student1_train_epoch_loss['kl_loss'][epoch],
'total_loss', student1_train_epoch_loss['total_loss'][epoch])
print('student2: ce_loss', student2_train_epoch_loss['ce_loss'][epoch],
'kl_loss', student2_train_epoch_loss['kl_loss'][epoch],
'total_loss', student2_train_epoch_loss['total_loss'][epoch])
student1.eval()
student2.eval()
student1_preds = []
student2_preds = []
for batch in tqdm(eval_loader):
batch = {k:v.cuda() for k,v in batch.items()}
with torch.no_grad():
student1_outputs = student1(**batch)
student2_outputs = student2(**batch)
student1_preds += student1_outputs.logits.argmax(dim=1).cpu().tolist()
student2_preds += student2_outputs.logits.argmax(dim=1).cpu().tolist()
student1_eval_metrics['precision'].append(precision_score(eval_df['category_id'], student1_preds, average='macro'))
student1_eval_metrics['recall'].append(recall_score(eval_df['category_id'], student1_preds, average='macro'))
student1_eval_metrics['f1'].append(f1_score(eval_df['category_id'], student1_preds, average='macro'))
student2_eval_metrics['precision'].append(precision_score(eval_df['category_id'], student2_preds, average='macro'))
student2_eval_metrics['recall'].append(recall_score(eval_df['category_id'], student2_preds, average='macro'))
student2_eval_metrics['f1'].append(f1_score(eval_df['category_id'], student2_preds, average='macro'))
print('student1 eval_precision', student1_eval_metrics['precision'][epoch],
'eval_recall', student1_eval_metrics['recall'][epoch],
'eval_f1', student1_eval_metrics['f1'][epoch])
print('student2 eval_precision', student2_eval_metrics['precision'][epoch],
'eval_recall', student2_eval_metrics['recall'][epoch],
'eval_f1', student2_eval_metrics['f1'][epoch])
# early stopping
sum_f1 = student1_eval_metrics['f1'][epoch] + student2_eval_metrics['f1'][epoch]
if best_metrics < sum_f1:
best_metrics = sum_f1
else:
stop_count += 1
if stop_count == early_stopping_patience:
break
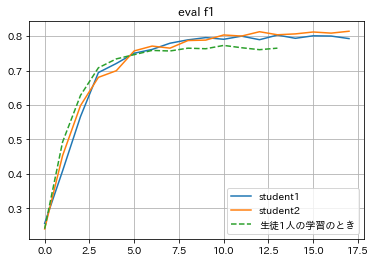
Early Stoppingの指標として、生徒1,2の予測精度の合計値を採用してみた結果、学習結果は以下のようになりました。
(ベストスコアは生徒1: 0.800、生徒2: 0.812でした。)
参考として生徒1人で学習したとき(先程検証した蒸留なしの小さいBERTモデルにおける精度)も合わせて表示してみると、生徒1人で学習するよりかは生徒同士が教え合いながら学習したほうがどちらの生徒も良い結果となることがわかりました。
生徒1と生徒2の違いはパラメータの初期値が違う程度の違いでしたが、片方の生徒はRoBERTaにする、とかしたらもう少し良い結果になるのでは?と思ったりしてます。
おわりに
なんとなく知識蒸留の実装方法やどれくらい精度が出るのかの感覚を養うことができました。
実際にDeep Learningのモデルをビジネスに適用するとき、BERT-baseのサイズだとでかすぎて運用できん、ってことも多々あることでしょうし、精度をある程度落としてでもモデルの軽量化が優先されるなら、積極的に知識蒸留の考え方を使っていきたいですねぇ。
おわり