1. はじめに
昨今、様々な企業・組織内で大規模言語モデル(LLM)の導入が進められています。
LLMを導入するにあたり、AI利用ガバナンスは必要不可欠です。
特に運用面では、
- 「どのアプリがどれだけトークンを消費しているのか?」
- 「特定のモデルでレイテンシが悪化していないか?」
- 「キャッシュ機能は実際にどれほどコスト削減に貢献しているのか?」
というのは気になるところです。
これらの問いに答えるためには、高度な オブザーバビリティ(可視性) が不可欠です。
本記事では、Kong AI Gatewayを使用してLLMの利用状況を可視化するための主要メトリクスとその活用方法について紹介します。
Kong AI Gatewayとは何か知りたい方は下記記事を参照ください。
2. Kong AI GatewayにおけるAIオブザーバビリティ
Kong AI Gatewayは、OpenAI、Azure AI、Anthropicなどの複数のLLMプロバイダの前段に位置する「AI Gateway」として機能し、LLMへのトラフィックを管理します。
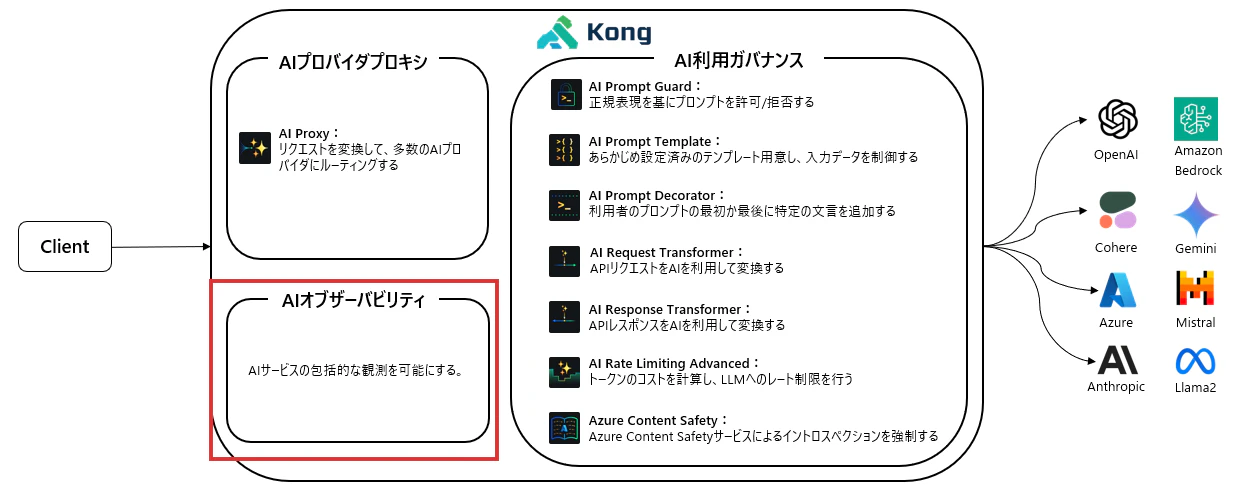
主な役割としては、LLMプロバイダへのプロキシ機能、AI利用のガバナンス、AIオブザーバビリティがあります。
このうちの、AIオブザーバビリティとしては、LLMプロバイダからのレスポンスをもとに、トークン数、コストなどをリアルタイムに集計できます。
集計されたデータは標準的なPrometheus形式に対応しているため、Prometheus + Grafana等で簡単に可視化可能です。
3. 監視可能なAIメトリクス
Kong AI Gatewayが収集するメトリクスは、大きく 「LLMトラフィック」 と 「Model Context Protocol(MCP)トラフィック」 の2つで構成されています。
詳細は公式ドキュメントを参照ください。
3.1. LLMトラフィックに関するメトリクス
3.1.1. メトリクス一覧
| カテゴリ | メトリクス名 | 説明 | 備考 |
|---|---|---|---|
| 利用量とコスト | AIリクエスト | LLMプロバイダに送信されたリクエスト数 | |
| AIトークン | LLMプロバイダによってカウントされるトークン数 | 入力(prompt)と出力(completion)を区別可能 | |
| AIコスト | LLMプロバイダから請求される推定コスト | AI Proxy(またはAI Proxy Advanced)プラグインで単価設定が必須 | |
| 性能 | AI LLMレイテンシ | LLMプロバイダが応答を返すのにかかる時間 | |
| キャッシュ | AIキャッシュフェッチ遅延 | AIセマンティックキャッシュ機能利用時に、キャッシュから応答を返すのにかかる時間 | v3.8以降 |
| AIキャッシュ埋め込み遅延 | AIセマンティックキャッシュ機能利用時に、キャッシュ中に埋め込み(Embedding)生成にかかる時間 | v3.8以降 |
AIセマンティックキャッシュ機能とは? ※Kong有償版限定
Kong AI GatewayのAIセマンティックキャッシュ機能とは、単純な文字列一致ではなく、ベクトルの近傍探索を用いることで、意味的に近い過去の質問に対してキャッシュから回答を返します。これにより、トークンコストの削減とレスポンスの高速化を実現します。
3.1.2. メトリクスに付与されるラベル
これらのメトリクスには豊富なラベルが付与されており、単なる総計だけではなく「誰が、どのモデルで、どう使ったか」というような分析も可能です。
| ラベル | 説明 | 備考 |
|---|---|---|
| LLMプロバイダ | LLMを提供するプロバイダ |
openai/anthropic/azure/aws等 |
| モデル | LLMのモデル |
gpt-4o/claude-3-5-sonnet等 |
| キャッシュ | キャッシュ状況 |
Hit/Miss/Bypass/Refresh
|
| データベース名 | AIセマンティックキャッシュ機能利用時に、キャッシュが格納されているデータベース名 |
redis等 |
| 埋め込みプロバイダ | AIセマンティックキャッシュ機能利用時に、埋め込み生成に使用されるプロバイダ | |
| 埋め込みモデル | AIセマンティックキャッシュプラグイン利用時に、埋め込み生成に使用されるモデル | |
| ワークスペース | メトリクスが発生したKongのワークスペース(組織や環境ごとの分類)名 | ワークスペースはKong有償版製品のみ利用可 |
| コンシューマ | リクエストを行ったユーザ/アプリ名 | v3.11以降 |
| トークンタイプ | 消費されたトークンの種類 |
prompt_tokens/completion_tokens/total_tokens
|
| リクエストモード | リクエストがどのように処理されたか |
oneshot(単一の応答が返された)/stream(応答はトークンのストリームとして配信された)/realtime(リクエストはリアルタイム セッションとして処理された)。※AIトークンメトリクスでは利用不可 |
3.2. MCPトラフィックに関するメトリクス
※Kong有償版限定
Kong AI Gatewayでは、AI MCP Proxy機能を持っています。
この機能では、Kong AI Gatewayはプロトコルブリッジとして機能し、MCPとHTTPを変換することで、MCP対応クライアントが既存のAPIを呼び出したり、Kongを介してアップストリームのMCPサーバとやり取りしたりできるようにします。
このようにKong AI GatewayがMCPクライアントからのリクエストを仲介する際に、メトリクスを集計することで、ツールの呼び出し回数や実行時間を計測できます。
3.2.1. メトリクス一覧
| カテゴリ | メトリクス名 | 説明 | 備考 |
|---|---|---|---|
| 利用量 | MCPレスポンスボディサイズ | MCPサーバのレスポンスボディサイズ | v3.12以降 |
| 性能 | MCPレイテンシ | MCP サーバ呼び出しにかかった時間 | v3.12以降 |
| エラー | MCPエラー合計 | エラータイプ別にラベル付けされた、MCPサーバエラーの総数 | v3.12以降 |
3.2.2. メトリクスに付与されるラベル
MCP特有のラベルにより、「どのサービス/ルートで、どうMCPツールを使ったか」を分析できます。
| ラベル | 説明 | 備考 |
|---|---|---|
| サービス | メトリクスが発生したサービス名 | |
| ルート | メトリクスが発生したルート名 | |
| MCPメソッド | MCPにおけるメソッド名 | 例:tools/call/tools/listなど |
| MCPツール名 | 呼び出された具体的な機能(ツール)名 | |
| ワークスペース | メトリクスが発生したKongのワークスペース名 | ワークスペースはKong有償版製品のみ利用可 |
| エラータイプ | MCPサーバのエラータイプ | MCPエラー合計メトリクスのみ利用可能 |
4. ユースケースの例
3. 監視可能なAIメトリクスで説明したメトリクスやラベルを組み合わせることで、以下のような高度な分析が可能になります。
① コストの最適化
AIトークン と AIコスト を コンシューマ ラベルで集計することで、「どの部門・どのアプリが予算を消費しているか」が分かります。これにより、社内でのコスト割合や、異常な大量消費の早期発見が可能になります。
② パフォーマンスのボトルネック特定
システム全体の応答が遅い際、それがLLMプロバイダによるものか(AI LLMレイテンシ)、キャッシュ検索時のベクトル変換によるものか(AIキャッシュ埋め込み遅延)を切り分けて適切な対処ができます。
③ キャッシュ利用効果の評価
全リクエストのうちキャッシュの利用割合を可視化することで、セマンティックキャッシュの設定が適切か、あるいはキャッシュが有効に機能しているかを定量的に判断できます。
④ MCPクライアントのツール利用の監視
MCPクライアントがMCP経由で外部ツールを呼び出す際、その成功率や性能の監視、異常に高い頻度で呼ばれているツールが無いかの監視ができます。
5. さいごに
Kong AI Gatewayが提供するメトリクスを活用することで、運用における様々な面を可視化できるようになります。
特に、最新のv3.11からはLLMトラフィックにおけるコンシューマラベルがサポートされ、リクエストを行ったユーザ/アプリごとの分析が可能になったため、社内共通AIプラットフォームとしての利便性がかなり向上したように思えます。
最近はKong AI Gateway関連のアップデートがアツいので、積極的にキャッチアップしていきたいところです!