プログラムコードをNLPのモデルで扱うための備忘録です。
プログラムコードの機能についての情報を持った分散表現を作り、そこからコード要約とキャプショニングを行えるモデル(code2seq)について説明してみます。
内容的にはcode2vec( https://arxiv.org/abs/1803.09473 )の発展的な内容になっていて、似ている部分が多いです。下記で記事化しています。
https://qiita.com/m3yrin/items/b7b11ec2c7d045d07efb
Twitter : @m3yrin
論文情報
- 論文 : code2seq: Generating Sequences from Structured Representations of Code
- 著者 :
- URI ALON, Technion
- SHAKED BRODY, Technion
- OMER LEVY, Facebook AI Research
- ERAN YAHAV, Technion
- 著者実装 : https://github.com/tech-srl/code2seq
- 公式ページ : https://code2seq.org/
- arxiv : https://arxiv.org/abs/1808.01400
- Accepted to ICLR'2019
TL;DR
- プログラムコードの機能的な情報を埋め込む手法code2seqを提案
- コードを抽象構文木(AST)で表現し構文情報をBiLSTMで埋め込む
- コード要約(Java)とコードキャプショニング(C#)で効果を確認
できること
word2vecなどによる単語の分散表現は、自然言語処理タスクにとって重要な役割を果たしました。
同様に、"プログラムコード"の機能的な情報を持つベクトルを作ることができれば、プログラムコードについても自然言語処理モデルのようなアプリケーションを作ることができるはずです。
この論文では、コードの機能名を予測するタスク(コード要約)とコードの機能についての文章を生成するタスク(コードキャプショニング)を行なっています。
また、この論文の先行研究code2vec(Alon et al., 2019)では下記のアプリケーションの可能性を挙げています。
- 機能の類似性を元にしたコード検索
- プログラムがI/Oを実行するかどうかを予測
- プログラムの必要な依存関係を予測
- プログラムがマルウェアの疑いがあるかどうかの予測
今回扱うタスク
すでに述べていますが、今回は下記の二つのタスクを行います。
コード要約
メソッド名をメソッド本文から推測します。
今回はJavaのデータセットを使っているのでJavaを例にします。
例えば下記のようなコードがテキストとして与えられた時、
void f() {
boolean done = false;
while (!done) {
if (remaining() <= 0) {
done = true;
}
}
}
checkDone ようなラベルを推測させます。
コードキャプショニング
プログラムコードから英文でプログラムコードに対する説明文を生成します。
コードキャプショニングではC#のデータセットを使っているのでC#を例にします。
下記のようなコードが与えられた時、
TreeView myTreeView = new TreeView();
myTreeView.Nodes.Clear();
foreach (string parentText in xml.parent)
{
TreeNode parent = new TreeNode();
parent.Text = parentText;
myTreeView.Nodes.Add(treeNodeDivisions);
foreach (string childText in xml.child)
{
TreeNode child = new TreeNode();
child.Text = childText;
parent.Nodes.Add(child);
}
}
に対して、下記のような説明文を生成させます。
add a child node to a treeview in c #
自然言語なので、aとかがちゃんとついています。
抽象構文木(AST)によるプログラムコードの表現
code2seqではプログラムコードを抽象構文木(Abstract Syntax Tree; AST)で表した上で抽象ベクトルを作ります。
ASTとは、有り体に言えば、言語に寄る表現を無くしたうえで木構造でプログラムを表したものです。Wikipediaの記事では下記のようになります。
抽象構文木(英: abstract syntax tree、AST)とは、通常の構文木(具象構文木あるいは解析木とも言う)から、言語の意味に関係ない情報を取り除き、意味に関係ある情報のみを取り出した(抽象した)木構造のデータ構造である。
理論的には、有限なラベル付き有向木であり、分岐点[1]に演算子、葉[2]にそのオペランドを対応させたものである。つまり、葉は変数や定数に対応する。
例えば、下記(再出)のようなコードでは
void f() {
boolean done = false;
while (!done) {
if (remaining() <= 0) {
done = true;
}
}
}
ASTは下記のようになります。(線の太さは一旦無視してください...)
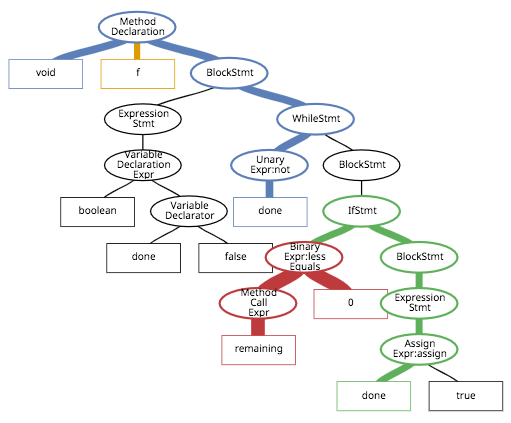
ASTは非終端ノード(分岐点、丸いところ)に演算の種類(代入、加算、whileなど)、終端ノード(葉、四角いところ)には演算の引数(オペランド)を持ち、全体で一つのrootノードを持ちます(ここではMethod Declarationです)。
ASTは各言語で生成するライブラリが提供されており、それを使います。
木構造(AST)を使うことのメリットとして、プログラムの実装の揺れに対して頑健であることを論文では挙げています。
例えば下記の2つのコードは、for文とdo-while文が異なるだけで、基本的には同じ処理を行なっています。

この二つのコードを、ニューラル翻訳モデルのように、ただ単純に単語(トークン)の系列として分析したとしても、機能の類似性をモデルが把握することは難しくなります。
一方でASTで分解して並べてみると下記にようになり、モデルとしては図中の赤色のパスの類似性を発見できます。
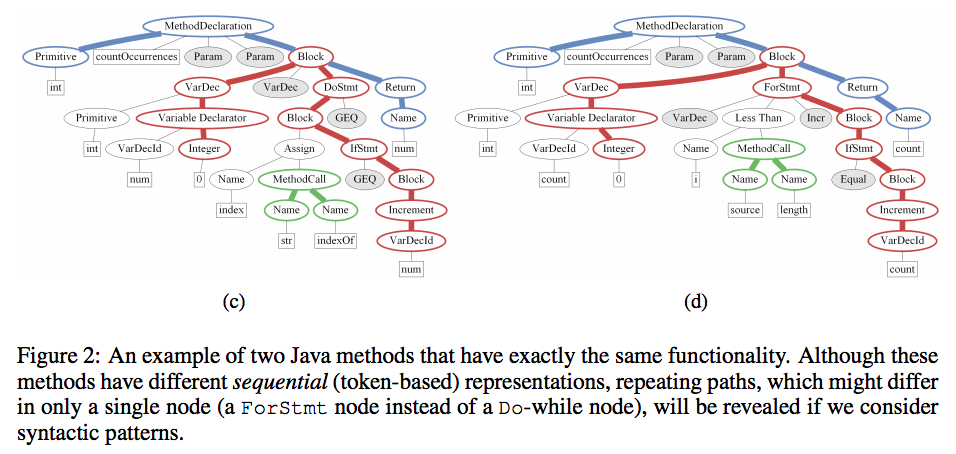
定性的には、構造についての情報をうまく使うことができれば、その機能についての情報を得ることも容易になります。
モデル構造
全体像
モデルの全体図は下記の通りです。
code2seqのモデルは基本的にはBi-directional LSTMを使ったencoder-decoderモデルに注意機構を使ったものです。これはニューラル機械翻訳モデル(Neural Machine Translation; NMT)の基本的なモデルですので、説明は割愛します。(オライリーの本、MLPシリーズの本などでも取り扱われています。)
code2seqでは、エンコーダ部分でコードの構文情報を獲得するための下記の3つのベクトルを作成し、後段のエンコーダに対する初期状態$h_0$を計算します。
- ASTのパス系列を埋め込んだベクトル(Path Representation)
- パス系列の最初と最後のラベルを埋め込んだベクトル(Token Representation)
Path Representation
プログラムコードをASTで表し、ASTで表したプログラムは終端ノード(四角いやつ)を二つと、その間の非終端ノード(丸いやつ)の列で分解できます。これを"ASTパス"と呼びます。
例えば上図の赤色のパスでは、
x_i = v_{1}^{i}v_{2}^{i}...v_{l_i}^{i} = \\
\\
terminals, Method Call Expr, Binary Expr:less Equals, terminals
と書けます。(便宜上、終端ノードのシンボルを$terminals$としています。)
ASTパスの種類は364種類と有限です。
ASTパスの系列情報のベクトルを作るために、各ノードを埋め込み行列で埋め込んだ上でBiLSTMに与え、BiLSTMの最後の出力を連結したものを、ASPパスに対する埋め込みベクトル(Path Representation)とします。
蛇足なのかもしれませんが、ちゃんと書くと、
E_{v_{i}}^{nodes} = path\_vocab^\top \cdot v_{i}, \\
where \ path\_vocab \in \mathbb{R}^{364\times d_{nodes}}
(論文には明記されていませんが)となります。
埋め込んだ$E_{v_{i}}^{nodes}$をBiLSTMに系列として入力し、最終ステップの出力ベクトルの2つのベクトル(BiLSTMなので2つのLSTMを持っています)を連結します。
h_1,...,h_l = LSTM(E_{v_{1}}^{nodes},...,E_{v_{l}}^{nodes})
\\
encode\_path(v_{1}...v_{l}) = \left[ h_l^{\rightarrow} ; h_1^{\leftarrow} \right]
$h_l^{\rightarrow}$, $h_1^{\leftarrow}$は添え字を間違えそうですね...
Token Representation
ASTパスの最初と最後のノードは終端ノードであり、対応する値を持ちます。("0"とか"ArrayList"とか)
この値をそのまま埋め込み行列で埋め込むことも可能ですが、終端ノードの値はプログラムによって任意の値にできるので、種類が膨大になり学習しにくく(希薄化の原因に)なります。
論文では終端ノードの値をサブトークンに分割し、種類を減らす工夫をしています。
例えば、"ArrayList"は"Array"と"List"二つのサブトークンに分割します。
サブトークンに分割した後に、埋め込み行列を使ってベクトルに変換し、総和をとって終端ノードの値に対するベクトル(Token Representation)とします。
\begin{equation*}
encode\_token(w) = \sum_{s \in split(w)} E_s^{subtokens}
\end{equation*}
ASTパスは始まりと終わりの2つの終端ノードがあるので、一つのASTパスからToken Representationは2つ作れます。
Combined Representation
最後に、以上の3つのベクトルを連結して全結合層で変換したものを、一つのASTパスに対する抽象ベクトル$z_i$とします。
z_i = tanh \left( W_{in} \left[ encode\_path(v_{1}...v_{l}) ; encode\_token(value(v_{1})) ; encode\_token(value(v_{l})) \right] \right)
$value$ は終端ノードを終端ノードの持つ値に変換する関数、$W_{in}$ は $(2d_{path} + 2d_{token}) \times d_{hidden}$ の行列です。
これで一つのASTパスに対する抽象ベクトルが作れました。一つのプログラムから作れるASTパスの分だけ、抽象ベクトルが作成できます。
Decoder Start State
さて、encoder-decoderモデルのdecoderに対する初期状態を作ります。
論文では、k個のASTパスに対するベクトルに対して、その平均をdecoderの初期値としています。
h_0 = \frac{1}{k}\sum_{i=1}^{k}z_i
ASTパスの順序を今回は考えていない(そもそも順序がないはずな)ので、平均するだけです。
Attention
論文では注意機構を使ってASTパスのベクトルを参照しています。
学習
Setup
学習ではクロスエントロピー損失を使用しています。
各埋め込みベクトルの長さは一律で$d_{tokens} = d_{nodes} = d_{hidden} = d_{target} = 128$としています。
イテレーションごとのASTパスのサンプリング
一つのプログラムコードからたくさんのASTパスが生成されることになりますが、これを全て使って$h_0$を作ると処理が重くなります。
そこで、学習時には生成できるASTパスのバッグから、イテレーション毎にk個のパスを均一にサンプルして使用します。ユニフォームにサンプルすることで、サンプルによるバイアスを排除する意味も含んでいます。
kは100以下ではスコアが悪化し、300以上ではスコアの改善に寄与しなかったと報告しています。評価ではGPUメモリなどの制約も考慮してk=200を選んだそうです。
評価
コード要約
モデルでは単語をサブトークンに分解して使用しているので、メソッド名をサブトークンの列として推測することを前提とします。例えば、setMaxConnectionsPerServerはset max connections per serverと分解されます。
また評価はprecision, recall, and F1 scoreで行い、単語の大文字小文字については無視しています。
Data
モデルを3つのデータセットで学習を行なっています。
学習には複数のプロジェクトのコードが含まれるようにし、予測は異なるプロジェクトに対して行うようにしています。
-
Java-small
11の比較的大きいプロジェクト。9のプロジェクトを学習用、1プロジェクトを評価用、1プロジェクトをテスト用に使用して、汎化をみている。700K exampleのデータ量。 -
Java-med
Githubのスター付与トップ1000のプロジェクトからなるデータセット。4M exampleのデータ量。 -
Java-large
Githubのスター付与トップ9500のプロジェクトからなるデータセット。 16M exampleのデータ量。
Baselines(コード要約)
ベースラインとして下記のモデルをそれぞれのデータセットで再学習させて比較しています。
- Convolutional attention network to predict method names(Allamanis et al.,2016)
- Syntactic paths with Conditional Random Fields (CRFs) (Alon et al., 2018);
- Code2vec (Alon et al., 2019);
- TreeLSTM (Tai et al., 2015) encoder with an LSTM decoder and attention on the input sub-trees.
加えて下記のNMTのモデルとも(公平な比較のためサブトークン化などの調整も加えた上で)比較しています。
- 2-layer bidirectional encoder-decoder LSTMs (split tokens and full tokens) with global attention (Luong et al., 2015)
- Transformer (Vaswani et al., 2017)
結果(コード要約)
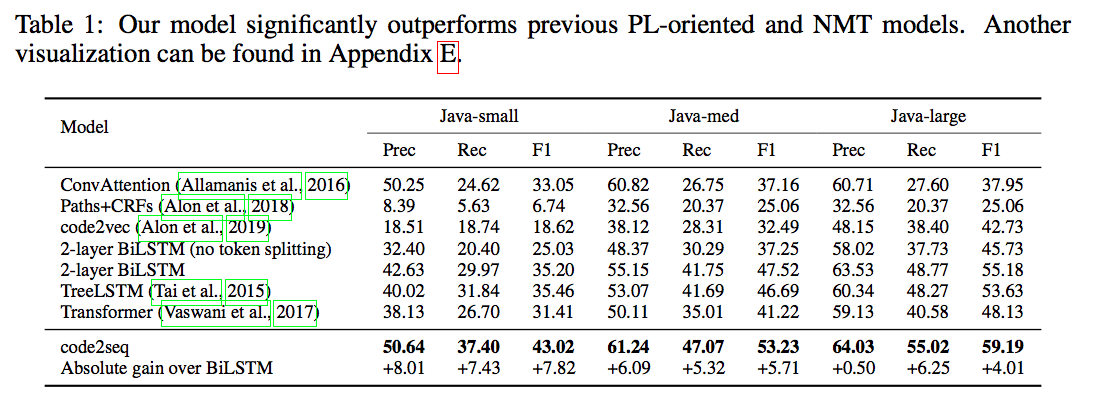
下記のTable 1はコード要約タスクの結果です。
基本的にはパス情報を埋め込むことでこれまでのBaselineを越えることができています。TreeLSTMもパス情報を扱うモデルですが、Code2seqの手法のほうが、長い距離の構文間の関係を捉えることができていると、著者らは考えているようです。
FernandesらによるGraph Neural Networkを使った手法に対しても、Java-largeデータセットにおいてはCode2Seqの方が良い性能だったとことです。
入力長に対する応答
入力するコードの長さがパフォーマンスにどのように影響を与えるかの結果をFig.4に示しています。
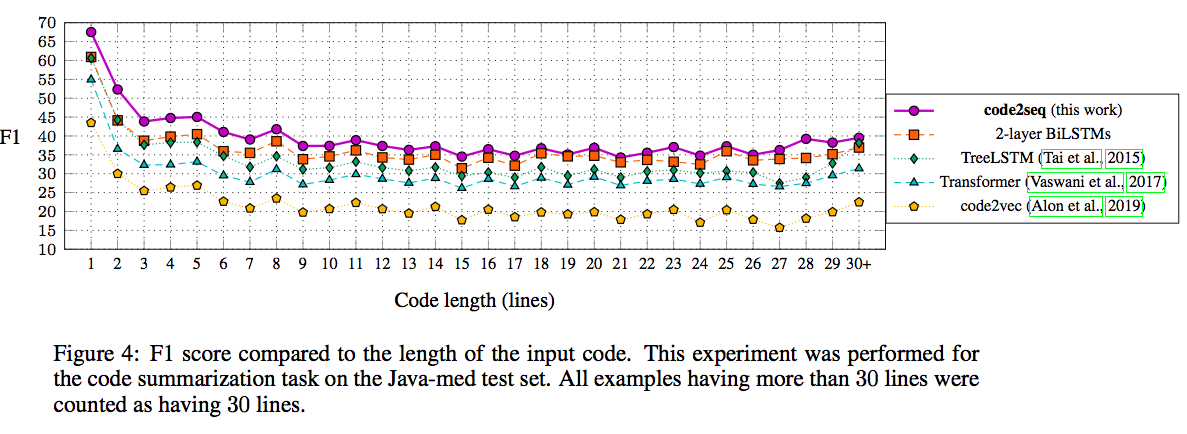
基本的には入力のコードが大きくなると、単調にスコアが下がっています。
(心の目でみると28+くらいからスコアが上がっているように見えるのは気のせいですかね...)
コードキャプショニング
コードキャプショニングにはCodeNN (Iyer et al., 2016)のデータセットを使用し評価しています。
CodeNNのデータセットはC#のコードであり、StackOverflowの66,015の問題と回答のペアからなっていて、Iyer et alの評価スクリプトと同じく、評価にはスムージングを施したBLUEスコアを使用しています。
Baselines(コードキャプショニング)
コードキャプショニングでは下記モデルと比較を行っています。
- CodeNN
- TreeLSTMs with attention
- 2-layer bidirectional LSTMs with attention
- Transformer
結果(コードキャプショニング)
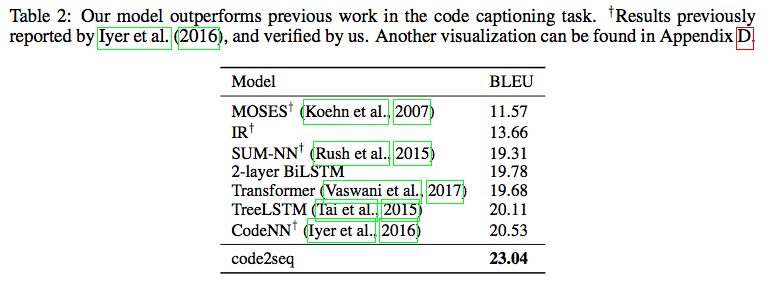
最も結果の良いCodeNN(Iyer et al., 2016)より2.51ほどスコアが改善しています。
ABLATION STUDY
Java-med データセットを使い、ABLATIONテストを行なっていますが、内容が込み入ってくるので割愛します。。。
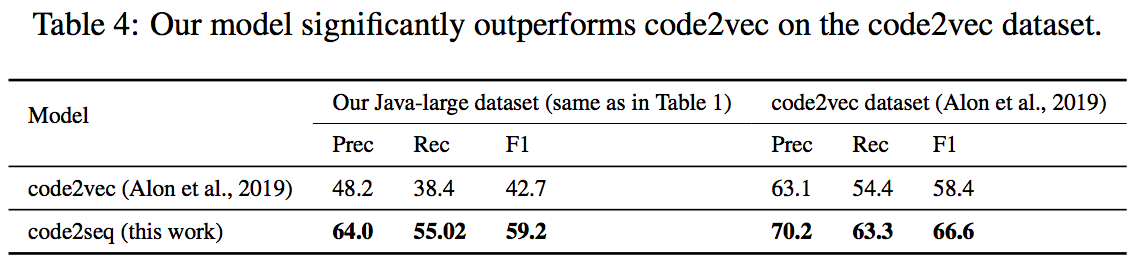
(補足) code2vecとの比較
code2vec(Alon et al., 2019)についての記事も書いているので、code2vecとの比較も載せたいと思います。
結論としては、表4に示すように、code2seqの方が良い性能を出すそうです。
(そりゃそうでしょうね、という感じ...)
code2vecの論文で報告されたスコアよりも低いスコアがこの論文では示されていますが、これは評価に使用したデータセットが異なるためとしています。
code2vecで使用したデータセットには、同じプロジェクトのデータがtrain / validation / testのそれぞれに混入し、メソッド名がそれぞれのデータにリークしている可能性を著者らは指摘しています。
実装
著者実装がデータセットと共に公開されています。
https://github.com/tech-srl/code2seq
code2vecに似ていて、実装はTensorflowで行われています。
def build_training_graph(self, input_tensors):
target_index = input_tensors[reader.TARGET_INDEX_KEY]
target_lengths = input_tensors[reader.TARGET_LENGTH_KEY]
path_source_indices = input_tensors[reader.PATH_SOURCE_INDICES_KEY]
node_indices = input_tensors[reader.NODE_INDICES_KEY]
path_target_indices = input_tensors[reader.PATH_TARGET_INDICES_KEY]
valid_context_mask = input_tensors[reader.VALID_CONTEXT_MASK_KEY]
path_source_lengths = input_tensors[reader.PATH_SOURCE_LENGTHS_KEY]
path_lengths = input_tensors[reader.PATH_LENGTHS_KEY]
path_target_lengths = input_tensors[reader.PATH_TARGET_LENGTHS_KEY]
with tf.variable_scope('model'):
subtoken_vocab = tf.get_variable('SUBTOKENS_VOCAB',
shape=(self.subtoken_vocab_size, self.config.EMBEDDINGS_SIZE),
dtype=tf.float32,
initializer=tf.contrib.layers.variance_scaling_initializer(factor=1.0,
mode='FAN_OUT',
uniform=True))
target_words_vocab = tf.get_variable('TARGET_WORDS_VOCAB',
shape=(self.target_vocab_size, self.config.EMBEDDINGS_SIZE),
dtype=tf.float32,
initializer=tf.contrib.layers.variance_scaling_initializer(factor=1.0,
mode='FAN_OUT',
uniform=True))
nodes_vocab = tf.get_variable('NODES_VOCAB', shape=(self.nodes_vocab_size, self.config.EMBEDDINGS_SIZE),
dtype=tf.float32,
initializer=tf.contrib.layers.variance_scaling_initializer(factor=1.0,
mode='FAN_OUT',
uniform=True))
# (batch, max_contexts, decoder_size)
batched_contexts = self.compute_contexts(subtoken_vocab=subtoken_vocab, nodes_vocab=nodes_vocab,
source_input=path_source_indices, nodes_input=node_indices,
target_input=path_target_indices,
valid_mask=valid_context_mask,
path_source_lengths=path_source_lengths,
path_lengths=path_lengths, path_target_lengths=path_target_lengths)
batch_size = tf.shape(target_index)[0]
outputs, final_states = self.decode_outputs(target_words_vocab=target_words_vocab,
target_input=target_index, batch_size=batch_size,
batched_contexts=batched_contexts,
valid_mask=valid_context_mask)
step = tf.Variable(0, trainable=False)
logits = outputs.rnn_output # (batch, max_output_length, dim * 2 + rnn_size)
crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=target_index, logits=logits)
target_words_nonzero = tf.sequence_mask(target_lengths + 1,
maxlen=self.config.MAX_TARGET_PARTS + 1, dtype=tf.float32)
loss = tf.reduce_sum(crossent * target_words_nonzero) / tf.to_float(batch_size)
if self.config.USE_MOMENTUM:
learning_rate = tf.train.exponential_decay(0.01, step * self.config.BATCH_SIZE,
self.num_training_examples,
0.95, staircase=True)
optimizer = tf.train.MomentumOptimizer(learning_rate, 0.95, use_nesterov=True)
train_op = optimizer.minimize(loss, global_step=step)
else:
params = tf.trainable_variables()
gradients = tf.gradients(loss, params)
clipped_gradients, _ = tf.clip_by_global_norm(gradients, clip_norm=5)
optimizer = tf.train.AdamOptimizer()
train_op = optimizer.apply_gradients(zip(clipped_gradients, params))
self.saver = tf.train.Saver(max_to_keep=10)
return train_op, loss
再現実装はないみたいですね。Pytorchでも書いてみたいです。
まとめ
code2vecでの埋め込み手法を発展させたcode2seqについてまとめてみました。
code2vec, code2seqとみて、プログラムコードの機能をどのように埋め込むかについての知識がつきました。
(知らなかったのですが、)Code-to-codeという分類のタスクがあり、さらに調べてみたいと思っています。
Learning from Big Code
http://learnbigcode.github.io/
最近もFacebook AIがcodeの類似性からユーザに対して実装の提案や修正を行うためのツールを開発したと発表がありました。
Aroma: Using machine learning for code recommendation
https://ai.facebook.com/blog/aroma-ml-for-code-recommendation/
Aromaは現時点でオープンソース化はされていないようですが、記事の内容をみると"Parse tree"というASTのような木構造でSyntaxをみています。
まだ勉強中ですが、気になった論文があれば記事化していきたいと思っています。