備忘録的に記事にしました。
今回はプログラムコードの機能についての情報を持った分散表現をつくってみます。
Twitter : @m3yrin
論文情報
- 論文 : code2vec: Learning Distributed Representations of Code
- 著者 :
- URI ALON, Technion
- MEITAL ZILBERSTEIN, Technion
- OMER LEVY, Facebook AI Research
- ERAN YAHAV, Technion
- 著者実装 : https://github.com/tech-srl/code2vec
- 公式ページ : https://code2vec.org/
- arxiv : https://arxiv.org/abs/1803.09473
- Appeared in POPL'2019
TL;DR
- word2vecが単語の分散表現を作るように、プログラムコードの分散表現を得るための手法code2vecを提案
- コードをパスコンテキストに分解し埋め込みを行う
- Javaメソッドの類似性をとらえたベクトルを生成できることを確認
できること
word2vecなどによる単語の分散表現は、自然言語処理タスクにとって重要な役割を果たしました。
同様に、"プログラムコード"の機能的な情報を持つベクトルを作ることができれば、プログラムコードについても自然言語処理モデルのようなアプリケーションを作ることができるはずです。
論文中では下記のようなアプリケーションの可能性を挙げています。
- メソッド名の提案
- 機能の類似性を元にしたコード検索
- プログラムがI/Oを実行するかどうかを予測
- プログラムの必要な依存関係を予測
- プログラムがマルウェアの疑いがあるかどうかの予測
タスク
プログラムコードの埋め込みベクトルを得るために、Javaのコードスニペット(メソッド)の機能を表すラベルを予測するタスクで学習します。
例えば、以下のようなコードを入力としてあたえたとき
String[] f(final String[] array) {
final String[] newArray = new String[array.length];
for (int index = 0; index < array.length; index++) {
newArray[array.length - index - 1] = array[index];
}
return newArray;
}
以下のような機能を表すラベルを出力させるタスクを行います。
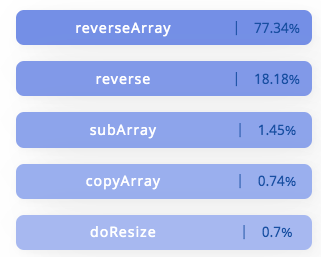
(ref: https://code2vec.org/)
ここでは予測結果が"reverseArray"となっています。
デモサイト(code2vec.org)に他の例があります。
上の例は今回説明するモデルの結果ですが、面白いのはコードの文字列中に"reverse"の文字列はないことです。
プログラムコードでは行列の要素順を逆にする処理を行なっていますが、コード中に現れる単語は"String"とか"index"とか一般的なもので、"reverse"を連想するような単語が含まれる訳ではありません。
RNN等のモデルにそのままコードを入力しても、このような結果が得るのは難しいと想像できます。
(メモ) 構造化された文章の分析のトレードオフ
構造のもつ情報を抽出するためには、プログラムを分析する仕組みが必要になりますが、プログラムの分析をどこまで精緻に行うのかと、それに続く学習の難しさにはトレードオフがあります。 単にプログラムのテキストをそのまま使った学習では、多くの場合かなりの学習が必要となります。 一方で、プログラムの詳細な分析を行うと、構造についての情報を多く得ることができますが、モデルがプログラム言語固有(さらにはタスク固有)になりがちとなるのは想像できます。モデル
まず、プログラムコードの埋め込みを行います。
埋め込みの主なアイディアは以下です。
- プログラムコードからパスコンテキストを抽出
- パスコンテキストの埋め込みを行い分散表現のバッグを作成
- 注意重みを使って分散表現の加重平均し集約
抽象構文木(AST)による分析
抽象構文木(AST)によるコードの表現
抽象構文木(AST)についてあまり詳しくないので、ここではWikipediaの説明をそのまま使うと
抽象構文木(英: abstract syntax tree、AST)とは、通常の構文木(具象構文木あるいは解析木とも言う)から、言語の意味に関係ない情報を取り除き、意味に関係ある情報のみを取り出した(抽象した)木構造のデータ構造である。
理論的には、有限なラベル付き有向木であり、分岐点[1]に演算子、葉にそのオペランドを対応させたものである。つまり、葉は変数や定数に対応する。
抽象構文木(AST)は論文中で詳しくDefinitionを書いていますが、簡単のために例で説明します。
例えば、以下のようなコードがあったとき
void f() {
boolean done = false;
while (!done) {
if (remaining() <= 0) {
done = true;
}
}
}
ASTは以下のようになります。(線の太さは一旦無視してください...)
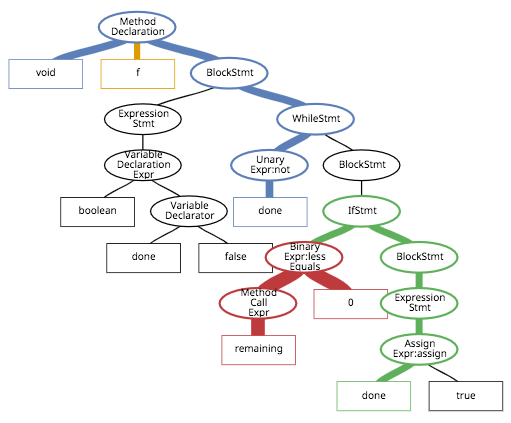
非終端ノード(分岐点、丸いところ)には演算の種類(代入、加算、whileなど)、終端ノード(葉、四角いところ)には演算の引数(オペランド)を持ち、全体で一つのrootノードを持ちます(ここではMethod Declarationです)。
ASTは各言語で生成するライブラリが提供されており、それを使います。
ASTパス
ASTで表現したプログラムを、終端ノードのペアとその間の非終端ノードの列として分解してみます。
任意の終端ノードを二つ選び、その間の非終端ノードと包含の方向でつなげたものを論文では"ASTパス"と呼んでいます。
例えば、先ほどのASTの赤色のパスについて書いてみると、終端ノード"remaining"と"0"の間は
(Method Call Expr, ↑, Binary Expr:less Equals)
となります。
パスコンテキストの作成
1つのASTパス($p$)と、開始終端ノードの値($x_s$)、終了終端ノード($x_t$)の組み合わせで、AST中の一つのパスを表します。これを"パスコンテキスト"と呼びます。
例えば赤色のパスについては
\langle x_s, p, x_t \rangle= \langle remaining, (Method Call Expr, ↑, Binary Expr:less Equals), 0\rangle
となります。
Bag of Path-Contextsの作成
ASTから作成できる複数のパスコンテキスト$\langle x_s, p, x_t \rangle$を"Bag of Path-Contexts"と呼び、与えられたプログラムコードを表す表現として使用します。
プログラムコードから生成できるパスコンテキストをすべて使ってしまうと膨大な量になります。トレーニング時のデータサイズを制限ために、パスコンテキストの最大長や、どれだけ親ノードを遡るかをハイパーパラメータとして指定します。
パスコンテキストの埋め込み
パスコンテキストから固定長の分散ベクトルを作るために、埋め込みを行います。
まず、終端ノードの値($x_s, x_t$)に対するEmbeddingマトリクスをvalue_vocab、ASTパス($p$)に対する行列をpath_vocabとすると、次のようになります。
\begin{align*}
value\_vocab &\in \mathbb{R}^{\left|X\right|\times d} \\
path\_vocab &\in \mathbb{R}^{\left|P\right|\times d}
\end{align*}
$X$は学習中に現れるAST終端ノードの値の集合("remaining"、"done"、"true"、"0"、...)、$P$はASTパスの集合、$d$は分散ベクトルの長さです。
Embeddingマトリクスはランダムに初期化された上で、学習時にネットワークと同時に学習されます。またdは100〜500の範囲だそうです。
プログラムコードから作成したBag of Path-Contexts $\mathcal{B}$
\mathcal{B}=\left\{b_1,...,b_n\right\}
について、それぞれのパスコンテキスト$b_{i}$を
b_{i}=\langle x_{s},p_j,x_{t} \rangle
とする時、$b_{i}$に対する埋め込みベクトル$\boldsymbol{c_{i}}$を次のように作ります。
\begin{equation}
\boldsymbol{c_{i}} = %embedding\left(b_{i}\right)=
embedding\left(\langle x_{s},p_j,x_{t} \rangle\right)= \\
\left[\begin{array}{l}
value\_vocab_{s} \,;\, path\_vocab_{j} \,;\, value\_vocab_{t}
\end{array}
\right] \in \mathbb{R}^{3d} \\
%\end{aligned}
\end{equation}
ここで行なっていることは、単純にパスコンテキストの終端ノードの値($x_s, x_t$)とASTパス($p$)の3つを埋め込んだベクトルを連結しているだけです。
3つの長さdのベクトルが連結されたので、長さは3dとなります。
これでそれぞれのパスコンテキストの埋め込みベクトルが、パスコンテキストの個数分つくれることになります。
注意重みを使った集約
パスコンテキストの埋め込みベクトルを一つのベクトルに集約し、プログラムコードに対する分散表現、コードベクトルを作ります。
作成したパスコンテキストの埋め込みベクトルを、全結合層で長さ3dからdに変換します。
\begin{equation*}
\boldsymbol{\tilde{c}_i} = tanh\left(W \cdot \boldsymbol{c_i}\right)
\end{equation*}
\\
\\
W\in\mathbb{R}^{d\times 3d}
活性化関数は"tanh"を使用しています。$\boldsymbol{\tilde{c}_i}$に対して、
注意重み$\alpha_i $を次のように作ります。
\begin{equation*}
\alpha_i = \frac{\exp(\boldsymbol{\tilde{c}_{i}}^{T}\cdot \boldsymbol{a})}{\sum_{j=1}^{n}\exp(\boldsymbol{\tilde{c}_{j}}^{T}\cdot \boldsymbol{a})}
\end{equation*}
注意ベクトル$\boldsymbol{a}\in\mathbb{R}^{d}$はランダムに初期化され、ネットワークと同時に学習されます。
最後に、注意重み$\alpha_i$を使って、コードベクトル$\boldsymbol{\upsilon}$を次のように計算します。
\begin{equation}
\boldsymbol{\upsilon} = \sum_{i=1}^{n}\alpha_i \cdot \boldsymbol{\tilde{c}_i}
\end{equation}
以上で、プログラムコードの構文の情報も埋め込んだ分散表現が作れました。
予測
作成したコードベクトルでラベルの予測します。
tags\_vocab\in \mathbb{R}^{\left|Y\right|\times d}
ここで、$Y$はトレーニング時のラベル値の集合、つまり具体的に推測したいラベル名の集合になります。
モデルの予測分布$q\left (y\right)$は以下のように計算します。
q\left(y_i\right)=\frac{\exp(\boldsymbol{\upsilon}^T\cdot tags\_vocab_{i})}{\sum_{y_{j}\in Y}\exp(\boldsymbol{\upsilon}^T\cdot tags\_vocab_{j})}
以上をまとめると以下の様なフローになります。(単純に見えますね。。。)
(ref: https://arxiv.org/abs/1803.09473)
学習
学習はクロスエントロピー損失を使用しています。
学習データはGitHubの10,072のリポジトリから取得したそうです。学習用のデータは著者らによって公開されています。
評価
定量的な他のモデルとの比較
論文では、類似のタスクに対するモデルとしてCNN+注意機構、LSTM+注意機構、Paths+CRFsと比較しています。
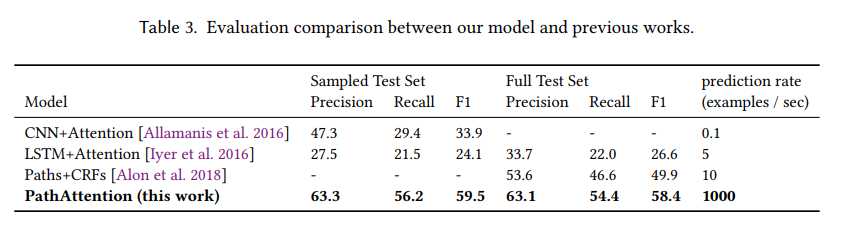
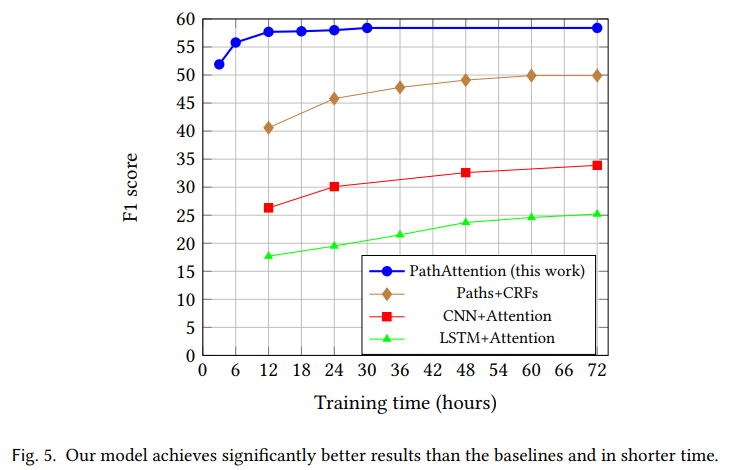
スコア的にも学習時間的にも良い結果です。Deepなモデルでもないので、推論速度も速いようです。
定性的な特徴
注意重みによる解釈性
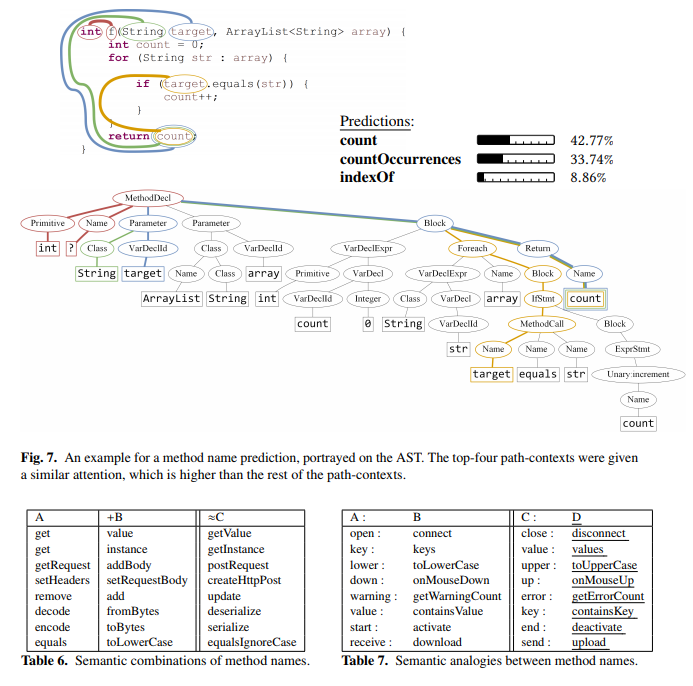
このモデルで面白いのは、どのパスコンテキストpが予測に重要であったかを注意重みから知ることができることです。
デモのサイトでは重みをきれいに可視化しています。
上図の線の太さは注意重みを反映しています。
学習された埋め込みによる意味的な性質
学習されたあるコードベクトルは、(コサイン距離などで)最も近いベクトルを探すと、意味的に似た名前を含むようになります。
また、word2vecなどによる埋め込みでは、ベクトルの加減算が意味的な追加や削除に対応していました。
例えば、$vec(“king”) - vec(“man”)+ vec(“woman”)$で計算されるベクトルは$vec(“queen”)$と類似します。
同様に、コードベクトルでも$vec("equals") + vec(toLowerCase) ≈ vec (equalsIgnoreCase)$という関係が現れ、意味的なベクトルがよく作れているように見えます。
以下(Table 6, Table 7)に例を示します。
このモデルの限界
新出のラベルに対応できない
主な問題の1つは、予測できるラベル名がトレーニング時に現れたラベルのみになることです。
また、予測したいラベルが非常に特殊かつ多様になると(例えばfindUserInfoByUserIdAndKey)、モデルはそのような名前を作れず、メインのアイデアと思われるラベル名を出力します。 (例えば:findUserInfo)
比較的大規模なデータが必要
このモデルでは学習において主に3つの難しさ(学習の効果を弱める原因; 希薄性)があります。
- 終端ノードの値はそのままシンボル(またはカテゴリでしょうか...)となります。例えば、newArrayとoldArrayは文字の大部分が同じですが、全く別のシンボルとして扱われます。
- ASTパスはほとんどのASTノードを共有していても1つのノードだけが異なる2つのパスが別シンボルとして扱われます。
- 予測したいラベル名に表記ゆれがあると、それらは別のシンボルとして扱われます。
モデルは学習中に現れたシンボルごとに埋め込みを行うため(|X|とか|P|とか|Y|が大きくなるので)、そのぶん大量のパラメータが必要となり、学習の難しさが増します。
変数名への依存
モデルの学習には、変数名の命名が良いとされるオープンソースプロジェクトのデータを使っているため、コード中の変数名もラベル予測に対して寄与しています。
これは、意味がなかったり、難読化されたり、または敵対的な変数名が与えられた場合には、ラベルの予測は正確ではありません。
実装
実装は著者らによって公開されています。
TensorFlowで実装されており、モデル部分の実装はそこまで難しくありません。
(前処理の部分は読むのが大変でした...、まだ全て追えていません)
def build_training_graph(self, input_tensors):
words_input, source_input, path_input, target_input, valid_mask = input_tensors # (batch, 1), (batch, max_contexts)
with tf.variable_scope('model'):
words_vocab = tf.get_variable('WORDS_VOCAB', shape=(self.word_vocab_size + 1, self.config.EMBEDDINGS_SIZE),
dtype=tf.float32,
initializer=tf.contrib.layers.variance_scaling_initializer(factor=1.0,
mode='FAN_OUT',
uniform=True))
target_words_vocab = tf.get_variable('TARGET_WORDS_VOCAB',
shape=(
self.target_word_vocab_size + 1, self.config.EMBEDDINGS_SIZE * 3),
dtype=tf.float32,
initializer=tf.contrib.layers.variance_scaling_initializer(factor=1.0,
mode='FAN_OUT',
uniform=True))
attention_param = tf.get_variable('ATTENTION',
shape=(self.config.EMBEDDINGS_SIZE * 3, 1), dtype=tf.float32)
paths_vocab = tf.get_variable('PATHS_VOCAB', shape=(self.path_vocab_size + 1, self.config.EMBEDDINGS_SIZE),
dtype=tf.float32,
initializer=tf.contrib.layers.variance_scaling_initializer(factor=1.0,
mode='FAN_OUT',
uniform=True))
code_vectors, _ = self.calculate_weighted_contexts(words_vocab, paths_vocab, attention_param,
source_input, path_input, target_input,
valid_mask)
logits = tf.matmul(code_vectors, target_words_vocab, transpose_b=True)
batch_size = tf.to_float(tf.shape(words_input)[0])
loss = tf.reduce_sum(tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.reshape(words_input, [-1]),
logits=logits)) / batch_size
optimizer = tf.train.AdamOptimizer().minimize(loss)
return optimizer, loss
またPyTorchによる再現実装も行われているようです。
https://github.com/src-d/code2vec
https://github.com/sonoisa/code2vec
まとめ
プログラムコードの機能的情報を持つ分散表現を作るための、埋め込み手法について書いてみました。
コンテキストパスとして埋め込む手法には納得感があります。
著者らはここでの内容を発展させたもの(https://code2seq.org/ )をICLR2019で発表するようです。