明示のない図表等は各論文中のものを使用しています
TL;DR
Parallel DecodingやNon-Autoregressive Decodingの最近の研究を紹介します
はじめに
- テキスト生成では一単語ずつ順番に生成する手法がよく使われます
- 最近の論文で、そうではない手法をいくつか見かけたのでまとめてみます
背景
Auto-RegressiveでLeft-to-Rightなテキスト生成
- seq2seqでよくみるのはこの構造
Decoder側は出力トークンをDecoderの入力に戻して使う(Auto-Regressive)
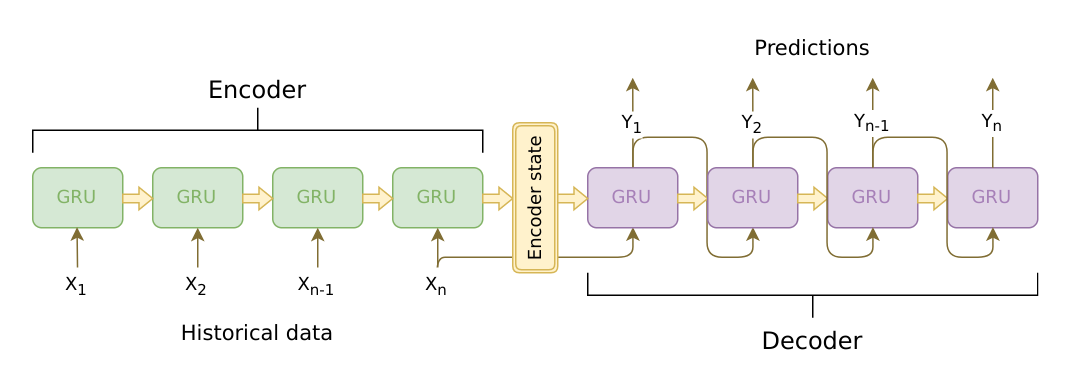
Image source: https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/
- Google翻訳でもこの構造を使ってる(はず)
https://ai.googleblog.com/2016/09/a-neural-network-for-machine.html
2016年の記事なのでだいぶ古いです。
(最近はTransformerベースのモデルを使ってるのでは...?)
このタイプのDecodingを嫌がる(?)いくつかの主張
- 遅い(Auto-Regressive)
前ステップの出力を元にDecodingしていくので並列処理が難しい - Left-to-Rightが最良であるとは言えない(L2R)
人間も、先に中心的なフレーズを考えてから文全体を生成したりする(Gu+, TACL 2019)
種類(ざっくりと)
1. Non-AutoregressiveなDecoding
- 一度でシーケンス中の全てのトークンを出力する
- Multi-Modalityという困難さが指摘されている
- 並列に処理できるので速い、Constant-Timeで処理できて良いとされる
2. Left-to-RightじゃないDecoding
- 変な箇所を修正する、良さそうな出力を挿入する、何度も繰り返して更新するなど
(メモ) Non-Autoregressiveな方法でのMulti-Modality
Non-Autoregressiveな方法では、予測される単語はそれぞれ独立に条件付けられ、同じ単語の繰り返しなどが発生しやすくなります。
例えば翻訳モデルにおいて、それらしい翻訳文が複数考えられる場合、Non-Autoregressiveな方法では、それぞれのトークン位置にてそれぞれ異なる翻訳文のトークンを予測してしまい、結果単語の繰り返しなどの問題が起こる、という仮説が考えられているます。
これをMulti-ModalityだったりMulti-Modal Problemと呼ぶようです。(Ghazvininejad+, EMNLP 2019) (どのへんがMulti-Modalなんだろうって思ってました)
論文
1. Mask-Predict: Parallel Decoding of Conditional Masked Language Models (CMLM)
Ghazvininejad+, EMNLP 2019
Facebook AI Research
https://arxiv.org/abs/1904.09324
https://github.com/facebookresearch/Mask-Predict
- BERTで使われるMask単語の予測をする事前タスクを、そのまま文章生成に使ってしまう手法を提案
- 並列処理できて速い
- 機械翻訳データセットで検証し、Parallel Decodingを行う他の手法の中ではSOTA (Transformer-BaseのAuto-Regressiveモデルには及ばない)
手法
-
Transformerを使ったEncoder-Decoderモデルをベースに使用
- ただし、デコーダー部のSelf-Attention Mask (Futureトークンを見ないためのマスク)を外してあるので、DecoderもBi-directionalな動作をする
-
複数回の予測の繰り返し
-
1度目はすべてのターゲットトークンがマスクされているものとして予測
- (純粋な)Non-Autoregressiveデコード
- 単語の繰り返しなど、Multi-Modalityの影響がみられる
-
2度目以降は予測確度の低いトークンをマスクして再予測し置き換え
- 前の予測結果を見ることになるため、Non-Autoregressiveとは言えない。
- 予測の繰り返しによって、単語の重複がなくなっていく (Multi-Modalityが壊れていくと考察されている)
- マスクする個数
nは最大イテレーション数Tで決めている $n = N * (T-t) / T$
($N$はシーケンス長、$t$はイテレーション数)
-

図 : ハイライトはMaskされる単語。t=0では単語の繰り返しが見られる。
- シーケンス長の予測
- 予測時は一度にすべてのトークンを生成してしまうため、事前にシーケンス長を指定しておく必要がある
- この論文ではEncoderにSpecial Token
LENGTHを入力に同時にあたえて、エンコードされたLENGTHトークンを使ってシーケンス長$l$を予測 - また論文では最も可能性が高い$l$以外にもいくつか選んでおいて、そのなかで最もよくデコードできたシーケンスを最終結果として評価(大変そう)
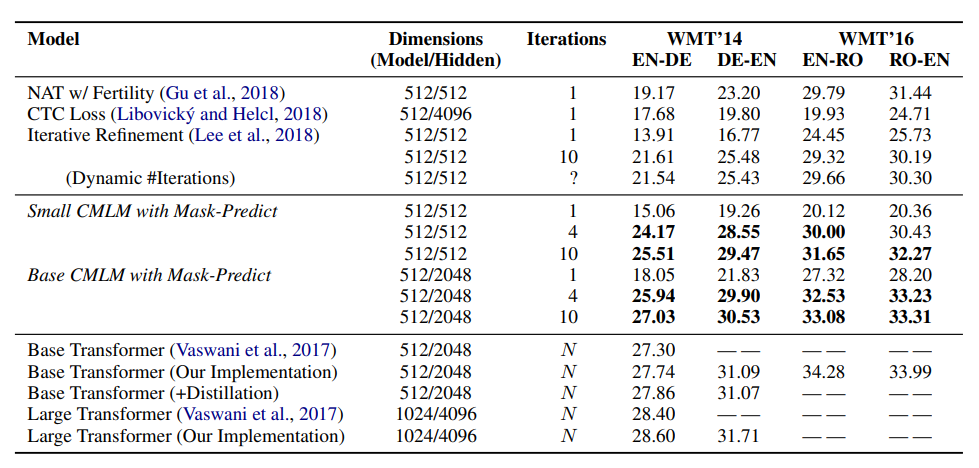
結果
- Parallel Decodingを行う他の手法の中ではSota
- Auto-RegressiveなTransformer-Baseのモデルには及ばないが、大差ではない
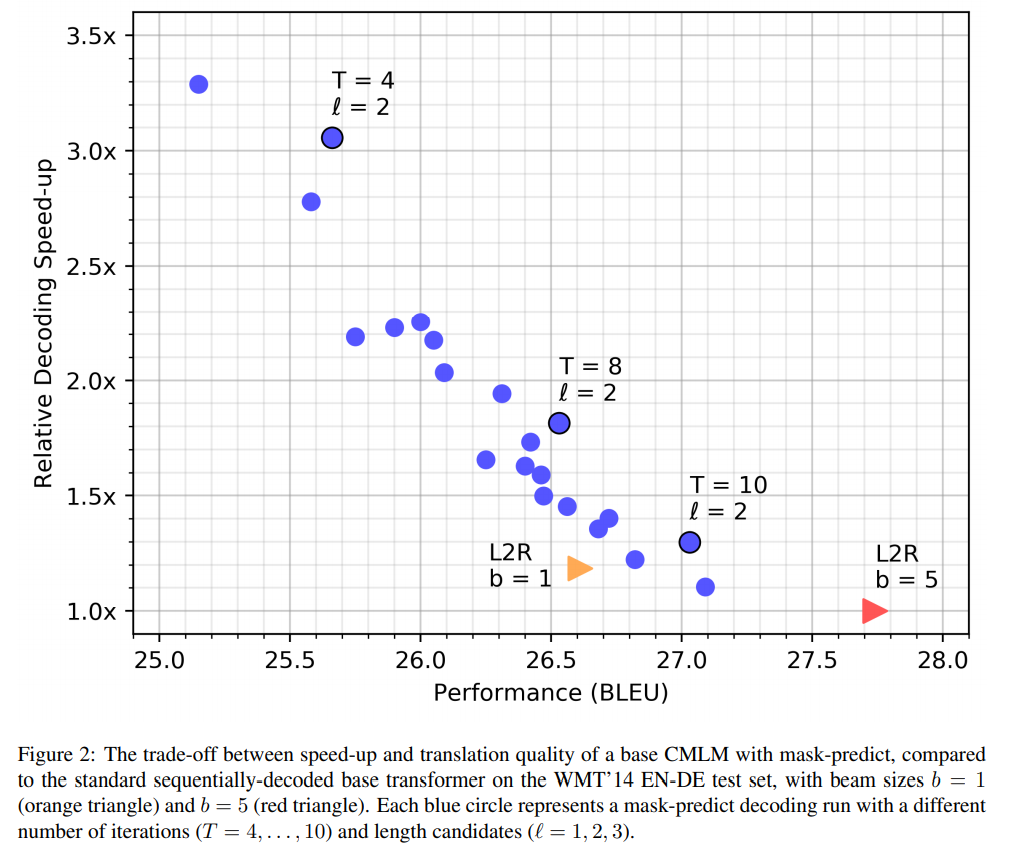
- Decodingはある程度速い
図中の▶は通常のAuto-Regressiveなモデル(bはbeam searchの幅)
イテレーションを増やすとスコアは改善するけど遅い
他の記事
- 【論文紹介】Mask-Predict: Parallel Decoding of Conditional Masked Language Models https://qiita.com/kotaaaa/items/15257d81afeb33143352
2. FlowSeq: Non-Autoregressive Conditional Sequence Generation with Generative Flow
Ma+, EMNLP 2019
Carnegie Mellon University, Facebook AI Research
https://arxiv.org/abs/1909.02480
https://github.com/XuezheMax/flowseq
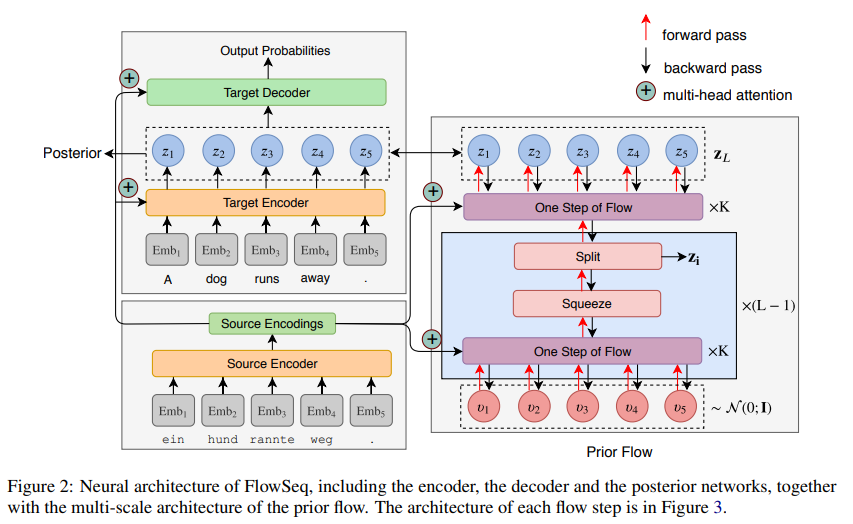
- Generative Flowで表現力を強化した潜在変数を導入
- 純粋なNon-Autoregressiveモデルの中ではSotaを達成
手法
- Non-Autoregressiveに潜在変数を導入することで、Decoderの出力トークン間の依存関係をもたせる手法はすでに提案されている
- 先行研究ではその表現力の不足していたため、Generative Flowを使う
Generative Flow
潜在変数 $\boldsymbol{v} \in \Upsilon$ はシンプルな事前分布 $p_{\Upsilon}(v)$ で容易にサンプルできるとする。全単射の関数$f: \mathcal{Z} \rightarrow \Upsilon$ (逆関数は $g=f^{-1}$ ) として、変数 $\mathbf{z}$は以下のように生成される。
$$
\boldsymbol{v} \sim p_{\Upsilon}(\boldsymbol{v}), \ \ \ \ \ \mathbf{z}=g_{\theta}(\boldsymbol{v})
$$
これによって、$\mathbf{z}$の分布は以下のように計算される。(ヤコビ行列による確率密度関数の変数変換)
$$
p_{\theta}(\mathbf{z})=p_{\Upsilon}\left(f_{\theta}(\mathbf{z})\right)\left|\operatorname{det}\left(\frac{\partial f_{\theta}(\mathbf{z})}{\partial \mathbf{z}}\right)\right|
$$
よって、複雑な$p_{\theta}(\mathbf{z})$はより簡単な$p_{\Upsilon}$から計算できる。
$f_{\theta}$はいくつかのタイプの関数を複数重ね合わせた関数$f_{\theta}=f_{1} \circ f_{2} \circ \cdots \circ f_{K}$で表現力を向上させる。
あとは通常の変分推論と同じ感じで使える。
$$
\log P_{\theta}(\mathbf{y} | \mathbf{x}) \geq E_{q_{\phi}(\mathbf{z} | \mathbf{y}, \mathbf{x})} \left[\log P_{\theta}(\mathbf{y} | \mathbf{z}, \mathbf{x})\right] -\mathrm{KL}\left(q_{\phi}(\mathbf{z} | \mathbf{y}, \mathbf{x}) | p_{\theta}(\mathbf{z} | \mathbf{x})\right)
$$
参考 : [DL輪読会]Flow-based Deep Generative Models, https://www.slideshare.net/DeepLearningJP2016/dlflowbased-deep-generative-models
モデル
結果
- 純粋なNon-Autoregressiveモデルの中ではSotaを達成
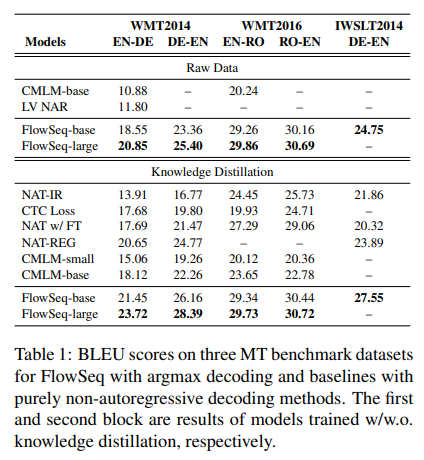
- 段階的な修正を行う方法を組み合わせてParallel Decodingとして使用した場合では、概ね他と同等の性能
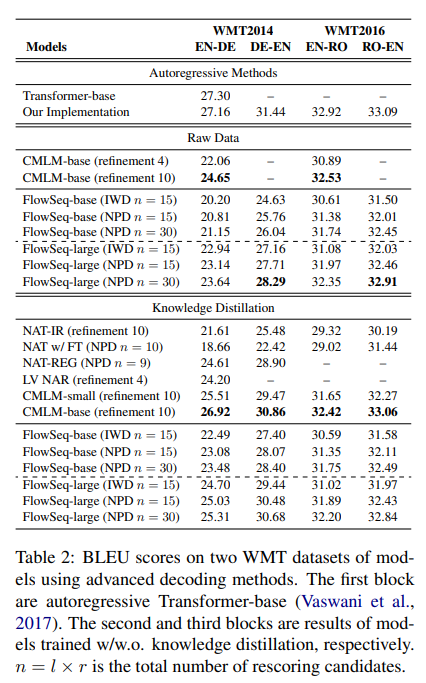
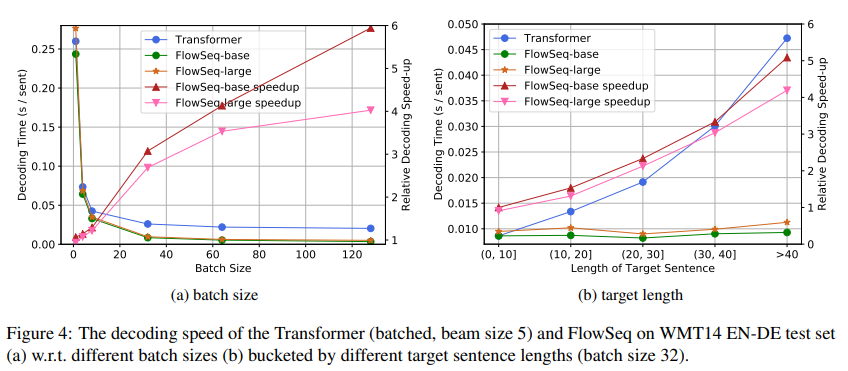
- 処理時間はTransformerベースのモデルの約6分の1
他の記事
3. Attending to Future Tokens For Bidirectional Sequence Generation
Lawrence+, EMNLP 2019
NEC Laboratories Europe
https://arxiv.org/abs/1908.05915
https://github.com/carolinlawrence/BiSon
- Decoder側でもBidirectionalな効果を得ることを期待した研究
- すでに述べたCMLMと似てる
手法
- テキスト生成の際に、プレースホルダーの系列をTransformerの出力で置き換えていくことでデコードしていく
- Left-to-Rightにデコードしていくわけではないので、Decoder側のTransformerで通常使うFuture Tokenに対するSelf-Attention Maskをかける必要がなく、Decoder側でもBidirectionalな効果を得ることができる

結果
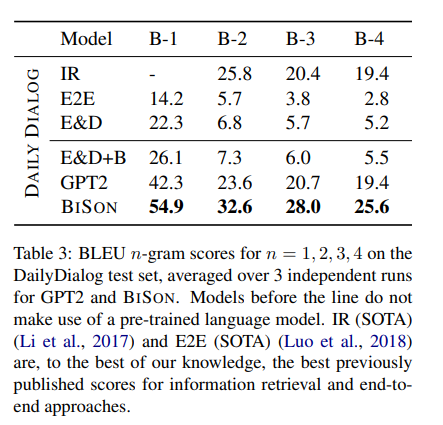
- 対話のデータセットで大幅にスコアが改善することを確認
他の記事
4. Levenshtein Transformer
Gu+, NeurIPS 2019 ★2019年10月にv2版が公開された
Facebook AI Research, New York University, Tigerobo Inc.
https://arxiv.org/abs/1905.11006
https://github.com/pytorch/fairseq/tree/master/examples/nonautoregressive_translation
- トークンの挿入・削除を繰り返すことでテキストを生成
- 強化学習的に学習
- Auto-Regressiveなモデルと同等の性能で、5倍の処理速度を達成
手法
- 多段のTransformerをEncoderとして使用
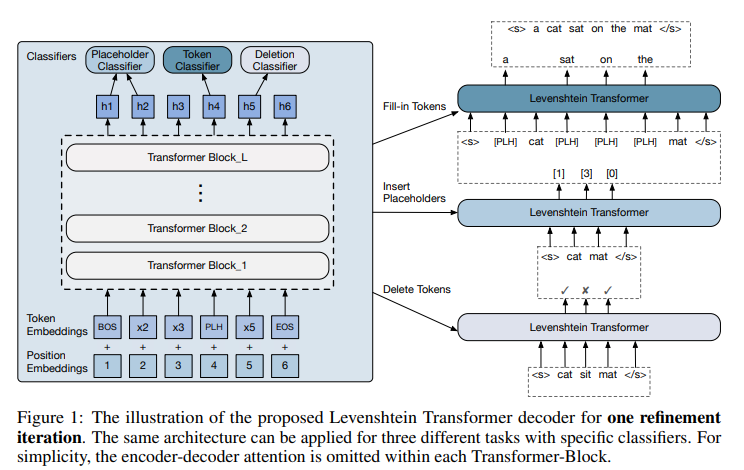
- それぞれの位置のトークンの削除(del)・挿入数の予測(plh)・挿入する単語の予測(tok)の方策を学習していく
$$
\pi(\boldsymbol{a} | \boldsymbol{y})=\prod_{d_{i} \in d} \pi^{\text {del }}\left(d_{i} | i, \boldsymbol{y}\right) \cdot \prod_{p_{i} \in \boldsymbol{p}} \pi^{\mathrm{plh}}\left(p_{i} | i, \boldsymbol{y}^{\prime}\right) \cdot \prod_{t_{i} \in t} \pi^{\mathrm{tok}}\left(t_{i} | i, \boldsymbol{y}^{\prime \prime}\right)
$$
ただし、$\boldsymbol{y}^{\prime}=\mathcal{E}(\boldsymbol{y}, \boldsymbol{d}) \text { and } \boldsymbol{y}^{\prime \prime}=\mathcal{E}\left(\boldsymbol{y}^{\prime}, \boldsymbol{p}\right)$
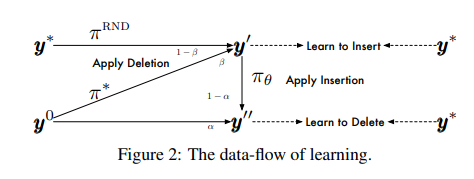
結果
- Auto-Regressiveなモデルと同等かそれ以上の性能で、Latencyは大幅に削減できている

- 処理の過程

他の記事
雑感
- Non-Autoregressiveな手法では先にシーケンス長の予測するのが大変そう
- Non-Autoregressiveな手法でもAuto-regressiveなモデルみたいに
EOSトークンを吐き出させるようにすればいいのでは?と思ったけど、だめなんだろうか
- Non-Autoregressiveな手法でもAuto-regressiveなモデルみたいに
- Auto-Regressiveなデコードは簡単の割に強力だとわかった
- Parallelな手法でもAuto-Regressiveな手法でもだいたい同じスコアに落ち着く?
- Auto-Regressiveなモデルの翻訳結果を蒸留としてParallelなモデルのトレーニングに使ってたりするので、そういうものなのかもしれない
- 別にParallelな手法がAuto-Regressiveなモデルを倒してくれても疑問に思わないんだけど、やはり難しいのか
まとめ
Parallel DecodingやNon-Autoregressive Decodingについての最近の研究について紹介しました
追記 (2020/7)
Alingmentを使った手法についてスライドを作ったので、追記します。
トークン生成の並列処理を可能にするNon-autoregressive Machine Translation研究の紹介と、先月に成果が報告されたAlingmentを用いた手法を二件紹介する。https://t.co/AxfFheNkmK
— DLHacks (@DL_Hacks) May 29, 2020