Mask-Predict: Parallel Decoding of Conditional Masked Language Models
Facebook AI Research
https://arxiv.org/pdf/1904.09324.pdf
EMNLP2019
(実装): https://github.com/facebookresearch/Mask-Predict
概要
多くの機械翻訳モデルは時系列に沿って,単語を生成するautoregressiveなモデルである.
例,Transformer, RNN(lstm)ベースのencoder-decoderモデルなど.
提案手法では, non-autoregressiveに単語を生成するモデルを提案.
つまり,時系列順に単語をデコードするのではない.
ターゲット文の一部をMASKすることで,デコード時,MASK単語を予測するタスクとして, 確率スコアが低いn個の単語をイテレーション数(T)だけ,予測する(デコードする)モデル
問題点
文の時系列順に単語を生成しないので,繰り返し(“completed completed”のような)などの非文法的な文が生成されてしまう.
これはnon-autoregressiveな生成モデルでは,典型的な
multi-modalityの問題である[Gu et al.,2018].
デコード時の単語のMASK方法
MASKする単語の個数は,
n = N * T-t/T
で決定され,
例のように, N=12,T=3とすると,(論文にこうは書いていないが,恐らく解釈としてはこのようなはず)
t=1(1回目のイテレーション時)は
120.66 = 7.92 ≒ 8
t=2(2回目のイテレーション時)は
120.33 = 3.96 ≒ 4
個の単語がMASKされる,(その後,その単語がPREDICTされる)

MASKされる単語は確率スコアが低い順に選択される.
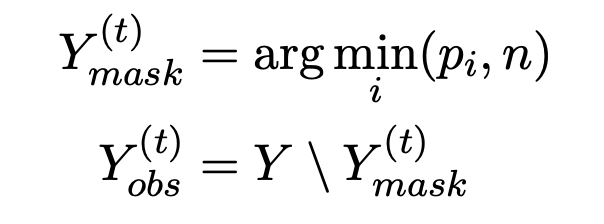
確率値Piが低い下からn個の単語がMASKされる.
モデル
ベースはTransformer
Transformerのデコーダから,self-attention機構を除いた.
言い換えると,つまり,デコーダーは双方向である.(bi-directional)
左からの情報も右からの情報も単語の予測に使うことができるので.
比較実験
Baseline: Transformer
SMALL/BASE CMLM with Mask-Predict(提案手法)
NAT w/ Fertility (Gu et al., 2018)
CTC Loss (Libovicky and Helcl ´ , 2018)
Iterative Refinement (Lee et al., 2018)
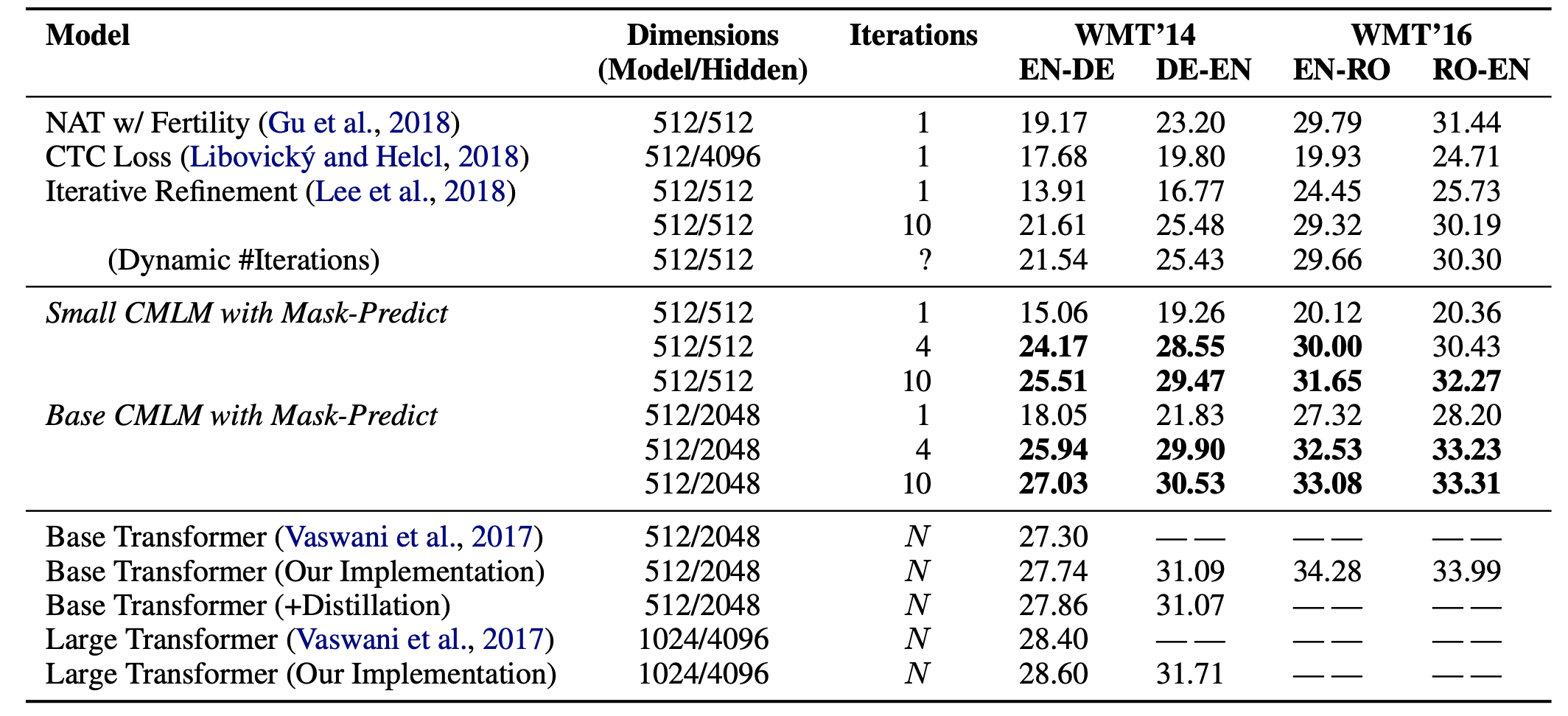
結論
他のnonautoregressiveのモデルよりも高精度に,
autoregressiveのモデルより,ずっと短い時間で,デコードが完了できた
その他問題点
- ターゲット文の長さの問題
- 知識の蒸留に対する依存を考慮できていない
などが挙げられる..
その他貢献としては,
- 広い意味で, マスク言語モデルが, テキストの意味獲得だけでなく, テキスト生成タスクにおいても有用であることを示すことができた.
次読む論文
Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK
Li, and Richard Socher. 2018. Non-autoregressive
neural machine translation. In ICLR.
multi-modality problem とはなにか