はじめに
こんにちは,株式会社IGSAでアルバイトをしている森です.
IGSAのとあるプロジェクトで,高次元データを次元削減した結果の可視化を行った際の内容を備忘録としてまとめようと思います.主な内容は次の通りです.
- PCA, t-SNE, UMAPのアルゴリズム概要
- 3次元の螺旋点群の次元削減結果の比較
- t-SNE, UMAPにおける,近傍点の数を増やしたときの次元削減結果の変化
- 次元削減後の点間の距離についての考察
PCA
主成分分析(Principal Component Analysis: PCA)は,線形な次元削減手法の代表例です.
データの分散が最大となる方向(主成分)を順に求め,上位の主成分に射影することで次元を削減します.
データセットを $N$ 個の $D$ 次元ベクトル $\boldsymbol{x}_i \in \mathbb{R}^D \ (i = 1, \dots, N)$ とし,これを $K$ 次元 ($K < D$)に圧縮することを考えます.
1: データの正規化
各特徴量のスケールと位置を揃えるため,データの平均を計算し,各データポイントから平均を引いて中心を原点に移動させます.
データの平均ベクトル $\bar{\boldsymbol{x}}$:
$$
\bar{\boldsymbol{x}} = \frac{1}{N} \sum_{i=1}^{N} \boldsymbol{x}_i
$$
中心化したデータ $\tilde{\boldsymbol{x}}_i$:
$$
\tilde{\boldsymbol{x}}_i = \boldsymbol{x}_i - \bar{\boldsymbol{x}}
$$
2: 共分散行列の算出
中心化したデータを用いて $D \times D$ の共分散行列 $\boldsymbol{C}$ を計算します.
$$
\boldsymbol{C} = \frac{1}{N} \sum_{i=1}^{N} \tilde{\boldsymbol{x}}_i \tilde{\boldsymbol{x}}_i^\top
$$
3: 固有値問題の解法
共分散行列 $\boldsymbol{C}$ に対して固有値分解を行い,固有値 $\lambda$ と固有ベクトル $\boldsymbol{v}$ を求めます.固有ベクトルはデータの分散が最大になる方向(主成分の軸)を表し,固有値はその方向の分散の大きさを表します.
$$
\boldsymbol{C} \boldsymbol{v} = \lambda \boldsymbol{v}
$$
得られた $D$ 個の固有値を大きい順に並べ替え,対応する固有ベクトルも同じ順序に並べます.
- 固有値: $\lambda_1 \geq \lambda_2 \geq \dots \geq \lambda_D$
- 固有ベクトル: $\boldsymbol{v}_1, \boldsymbol{v}_2, \dots, \boldsymbol{v}_D$
4: 射影行列の作成
次元削減を行うため,分散が大きい上位 $K$ 個の固有ベクトルを選択します.これらを列ベクトルとして並べ, $D \times K$ の射影行列 $\boldsymbol{W}$ を構築します.
$$
\boldsymbol{W} = [\boldsymbol{v}_1, \boldsymbol{v}_2, \dots, \boldsymbol{v}_K]
$$
5: データの射影
最後に,中心化したデータ $\tilde{\boldsymbol{x}}_i$ を射影行列 $\boldsymbol{W}$ を使って変換し,$K$ 次元の新しいデータ表現 $\boldsymbol{z}_i \in \mathbb{R}^K$ を得ます.
$$
\boldsymbol{z}_i = \boldsymbol{W}^\top \tilde{\boldsymbol{x}}_i
$$
t-SNE
t-SNE(t-Distributed Stochastic Neighbor Embedding)は,非線形な次元削減手法の1つです.高次元での位置関係を低次元でも維持しながら次元削減をするというモチベーションから開発された手法です.
高次元のデータセット $\boldsymbol{x}_1, \dots, \boldsymbol{x}_N \in \mathbb{R}^D$ を,低次元(通常は2次元または3次元)のマップ上の点 $\boldsymbol{y}_1, \dots, \boldsymbol{y}_N \in \mathbb{R}^d$ に変換するt-SNEの手順を以下に示します.
1: 高次元空間での非対称な類似度の計算
各データ点 $\boldsymbol{x}_i$ から見た $\boldsymbol{x}_j$ の類似度を,正規分布(ガウス分布)を用いた条件付き確率 $p_{j|i}$ として計算します.分散 $\sigma_i^2$ は,ユーザーが指定するPerplexity(パープレキシティ)に基づいてデータの密度に応じ適切に決定されます.
p_{j|i} = \frac{\exp(-\|\boldsymbol{x}_i - \boldsymbol{x}_j\|^2 / 2\sigma_i^2)}{\sum_{k \neq i} \exp(-\|\boldsymbol{x}_i - \boldsymbol{x}_k\|^2 / 2\sigma_i^2)}
(※ $p_{i|i} = 0$ とします)
2: 類似度の対称化
最適化を容易にし,外れ値の影響を和らげるために,条件付き確率を対称な同時確率 $p_{ij}$ に変換します($N$ はデータ数).
$$
p_{ij} = \frac{p_{j|i} + p_{i|j}}{2N}
$$
3: 低次元空間での類似度の定義
低次元空間における点 $\boldsymbol{y}_i$ と $\boldsymbol{y}_j$ の類似度 $q_{ij}$ を計算します.ここでは,ガウス分布ではなく裾野が広い自由度1の「スチューデントのt分布(コーシー分布)」を使用します.
q_{ij} = \frac{(1 + \|\boldsymbol{y}_i - \boldsymbol{y}_j\|^2)^{-1}}{\sum_{k \neq l} (1 + \|\boldsymbol{y}_k - \boldsymbol{y}_l\|^2)^{-1}}
(※ $q_{ii} = 0$ とします)
4: 目的関数の定義(KLダイバージェンス)
高次元空間での分布 $P$ と低次元空間での分布 $Q$ の近さを測るため,カルバック・ライブラー情報量(KLダイバージェンス) $C$ を目的関数として定義します.この値が最小になるような低次元の座標 $\boldsymbol{y}$ を探します.
$$
C = KL(P || Q) = \sum_{i} \sum_{j} p_{ij} \log \frac{p_{ij}}{q_{ij}}
$$
5: 勾配降下法による低次元表現の最適化
目的関数 $C$ を $\boldsymbol{y}_i$ について偏微分し,勾配降下法を用いて低次元の座標 $\boldsymbol{y}_i$ を反復的に更新します.
\frac{\partial C}{\partial \boldsymbol{y}_i} = 4 \sum_{j} (p_{ij} - q_{ij}) (\boldsymbol{y}_i - \boldsymbol{y}_j) (1 + \|\boldsymbol{y}_i - \boldsymbol{y}_j\|^2)^{-1}
これを収束するまで繰り返し,最終的な低次元マップ $\boldsymbol{y}_1, \dots, \boldsymbol{y}_N$ を得ます.
※補足:Perplexity
高次元空間で確率分布を計算する際,分散はPerplexityから決定されると書きました.
Perplexityは以下のように定義されています.
エントロピー $H(P_i)$:
$$
H(P_i) = -\sum_{j \neq i} p_{j|i} \log_2 p_{j|i}
$$
Perplexity $Perp(P_i)$:
$$
Perp(P_i) = 2^{H(P_i)}
$$
ここで $p_{j|i}$ は,分散を $\sigma_i^2$ としたガウス分布に基づく条件付き確率です.
高次元空間では,データの密度が場所によって異なります.そのため,t-SNEではすべてのデータ点でユーザーが指定した同じPerplexityになるように,各データ点 $i$ ごとに異なる分散 $\sigma_i^2$ を計算します.
この分散 $\sigma_i^2$ を求めるための解析的な解(一発で求まる公式)は存在しません.そのため,Perplexityが $\sigma_i$ に対して単調増加する性質を利用し,**二分探索(Binary Search)**を用いて最適な $\sigma_i$ を近似的に求めます.
具体的な計算ステップ:
- ユーザーが目標となるPerplexityを指定する.
- 各データ点 $\boldsymbol{x}_i$ について,初期の $\sigma_i$ を仮決めする.
- 仮の $\sigma_i$ を使って $p_{j|i}$ を計算し,現在のPerplexityを算出する.
- 現在のPerplexityが目標値より大きければ $\sigma_i$ を小さくし,小さければ $\sigma_i$ を大きくする(二分探索による更新).
- 目標とするPerplexityと,計算されたPerplexityの誤差が許容範囲内に収まるまで,ステップ3と4を繰り返して最終的な $\sigma_i^2$ を決定する.
UMAP
UMAP(Uniform Manifold Approximation and Projection)も,t-SNEと同様に,全ての高次元サンプルの各近傍点を調べ,それらの距離にほぼ一致する低次元表現を目指す非線形な次元削減手法です.t-SNEとの違いとしては,高次元・低次元でのデータの関係を確率分布ではなくそれぞれグラフで表現する点にあります.
高次元データ $\boldsymbol{x}_1, \dots, \boldsymbol{x}_N \in \mathbb{R}^D$ を,低次元の点 $\boldsymbol{y}_1, \dots, \boldsymbol{y}_N \in \mathbb{R}^d$ にマッピングするUMAPの手順を示します.
1. グラフの構築
(a) 各観測データ(データ点)について,与えられた距離関数(通常はユークリッド距離)$\text{Distance}_{i,j}$ に基づいて,$k$ 個の最近傍点を探索します.
(b) 各観測データ $i$ について,近傍点への最小の正の距離である $\rho_i$ を計算します.
(c) 次の方程式を解くことで,各観測データ $i$ のスケーリングパラメータ $\sigma_i$ を計算します.
$$
\log_2(k) = \sum_{j=1}^{k} \exp \left( \frac{-\max{0, \text{Distance}_{i,j} - \rho_i}}{\sigma_i} \right)
$$
(d) 重み関数を次のように定義します.
w(\boldsymbol{x}_i, \boldsymbol{x}_j) = \exp \left( \frac{-\max\{0, \text{Distance}_{i,j} - \rho_i\}}{\sigma_i} \right)
(e) 頂点が観測データであり,各エッジ $(i, j)$ について「$\boldsymbol{x}_i$ が $\boldsymbol{x}_j$ の最近傍である」,あるいは「その逆が成り立つ」重み付きグラフ $G$ を定義します.エッジ $(i, j)$ の対称化された重みは次のようになります.
\bar{w}_{i,j} = w(\boldsymbol{x}_i, \boldsymbol{x}_j) + w(\boldsymbol{x}_j, \boldsymbol{x}_i) - w(\boldsymbol{x}_i, \boldsymbol{x}_j) \cdot w(\boldsymbol{x}_j, \boldsymbol{x}_i)
2. グラフレイアウトの最適化
(a) 初期化: スペクトラル埋め込み(Spectral embedding)を用いて,低次元表現 $\boldsymbol{Y}$ を初期化します.
(b) 反復更新: グラフ $G$ のエッジに対して反復処理を行い,すべてのエッジ $(i, j)$ において,観測データ $i$ に対して次のように勾配降下法のステップを適用します.
i. 観測データ $i$ に対して,観測データ $j$ に向かう引力(低次元空間において)を適用します.
\boldsymbol{y}_i = \boldsymbol{y}_i + \alpha \cdot \frac{-2ab \|\boldsymbol{y}_i - \boldsymbol{y}_j\|_2^{2(b-1)}}{1 + a \|\boldsymbol{y}_i - \boldsymbol{y}_j\|_2^{2b}} \bar{w}_{i,j} (\boldsymbol{y}_i - \boldsymbol{y}_j)
ハイパーパラメータ $a$ と $b$ は,滑らかな近似を作成することを目的として,関数 $\left(1 + a \|\boldsymbol{y}_i - \boldsymbol{y}_j\|_2^{2b}\right)^{-1}$ を非正規化重み関数 $\exp(-\max{0, \text{Distance}_{i,j} - \rho_i})$ にフィッティングさせることでデータから調整されます.min_distというハイパーパラメータに依存しており,デフォルトでは$a\approx1.5769$, $b\approx0.8951$です.$\alpha$ は学習率です.
ii. 観測データ $i$ に対して,隣接していない頂点(グラフ $G$ に含まれないエッジ $(i, k)$) をランダムにサンプリングして,$i$から遠ざける斥力を適用します.この斥力は次の通りです.
\boldsymbol{y}_i = \boldsymbol{y}_i + \alpha \cdot \frac{b}{(\epsilon + \|\boldsymbol{y}_i - \boldsymbol{y}_k\|_2^2)(1 + a \|\boldsymbol{y}_i - \boldsymbol{y}_k\|_2^{2b})} (1 - \bar{w}_{i,k}) (\boldsymbol{y}_i - \boldsymbol{y}_k)
ここで,$\epsilon$ は(ゼロ除算を防ぐための)微小な定数です.
実験
2重螺旋点群の次元削減
PCA, t-SNE, UMAPを使用して,2重螺旋点群の次元削減をした結果を以下に示します.
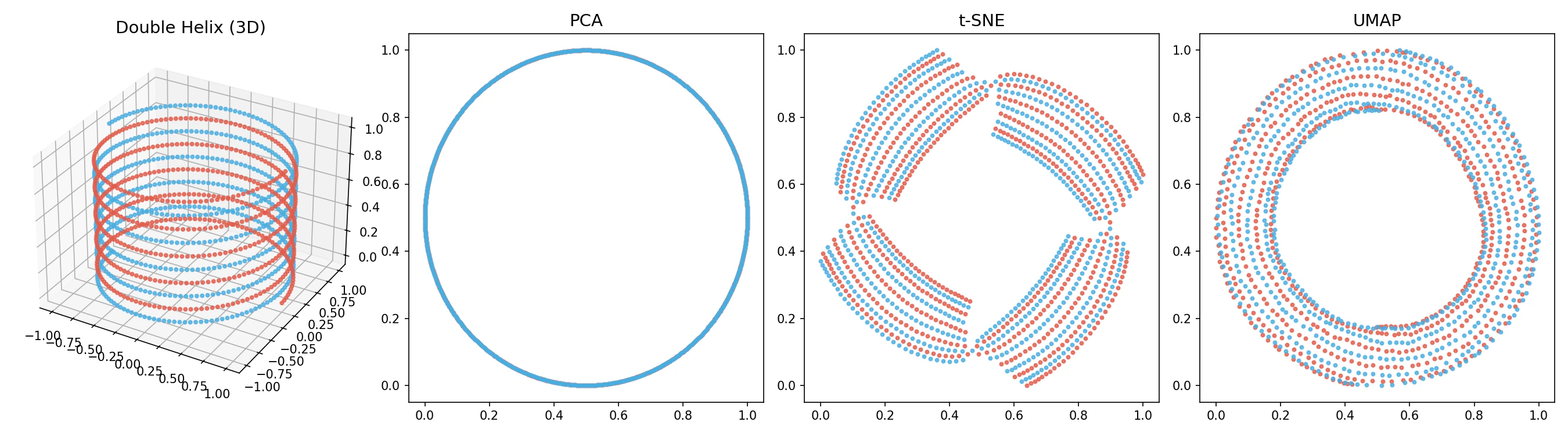
t-SNEのPerplexityは40,UMAPのn_neighborsは20で実験しました.
線形な手法であるPCAでは,螺旋の特徴を捉えられず,上からつぶしたような結果となり,螺旋や2重であるといった特徴を失う結果となりました.非線形手法であるt-SNE,UMAPはどちらも2重であるという特徴が捉えられています.t-SNEでは,螺旋が4つに分かれたような形になりました.これは,t-SNEは局所的な点を近づけ,それ以外の点を離すという特徴があることが原因だと考えられます.一方,UMAPでは大域的な特徴も考慮して最適化を行うため,t-SNEに比べ螺旋という特徴を捉えられている結果になったと考えられます.
近傍点の個数による次元削減の変化
t-SNEとUMAPを用いて,mnistの手書きデータセットの次元削減を近傍点の数を変えながら行った様子を以下に示します.データ数は10000としました.
t-SNE
どちらの手法でも,近傍点の数を増やすほどクラスターはきれいになっていきますが,あるところまでいくと,ふたたびうまくクラスタリングができなくなっていきます.この現象は,How to Use t-SNE Effectivelyで指摘されています.局所的構造と大域的構造のトレードオフにより,極端な値を設定すると,片方の構造に引っ張られてしまうようです.そのため,データセットサイズに応じて,適切な値を決めることが重要であると考えられます.
次元削減後の点間の距離についての考察
私が次元削減を使ってやりたかったことは,高次元空間において,どのデータ同士が似ているのかを視覚的に判断することでした.そこで,mnistの手書き数字データセットを使って,次のような実験を行いました.
- ランダムに30個のデータを抽出
- キーポイントとなる1点と,他の29点とのコサイン類似度を求め,ランキングを付ける
- 次元削減を行い,結果をプロット
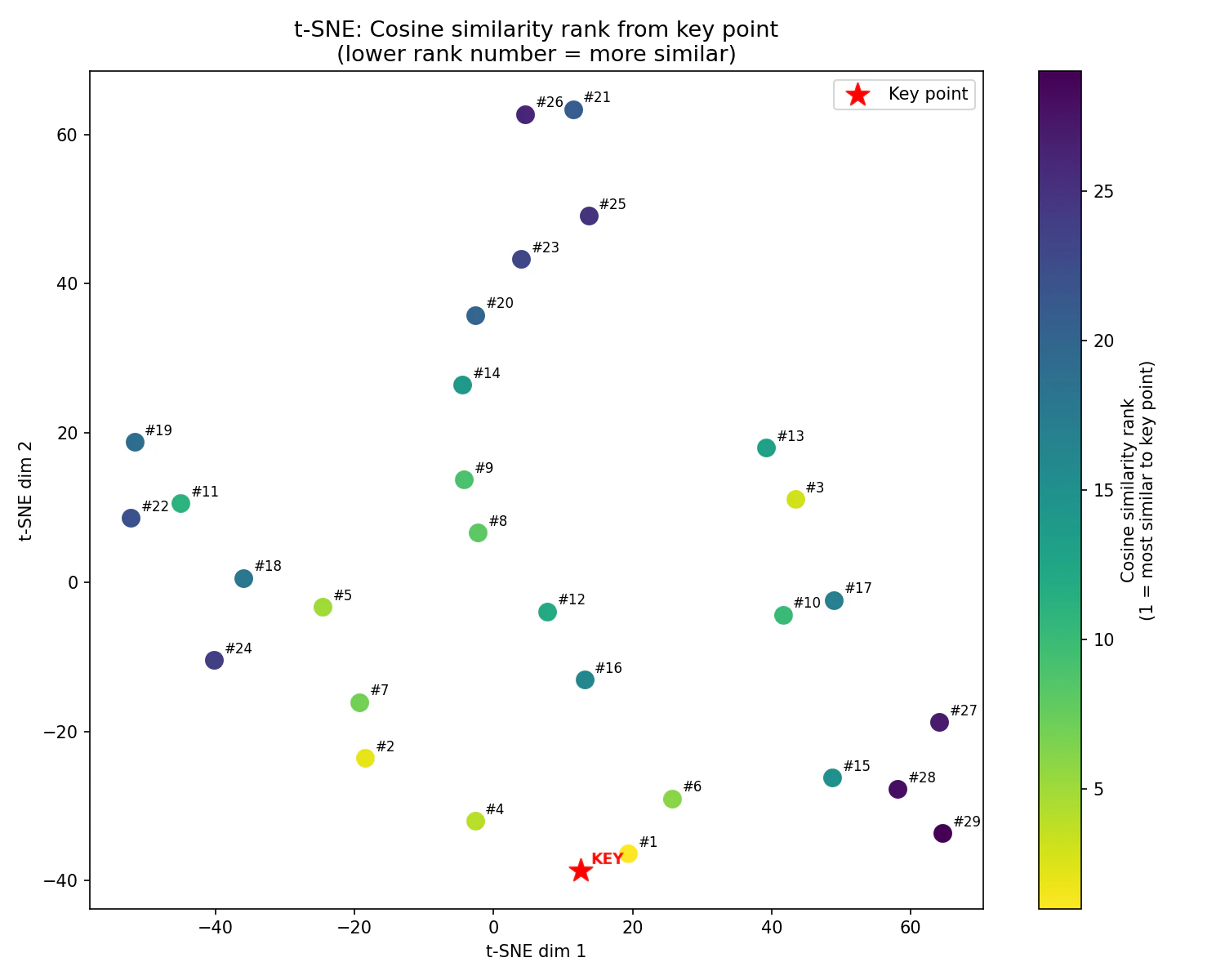
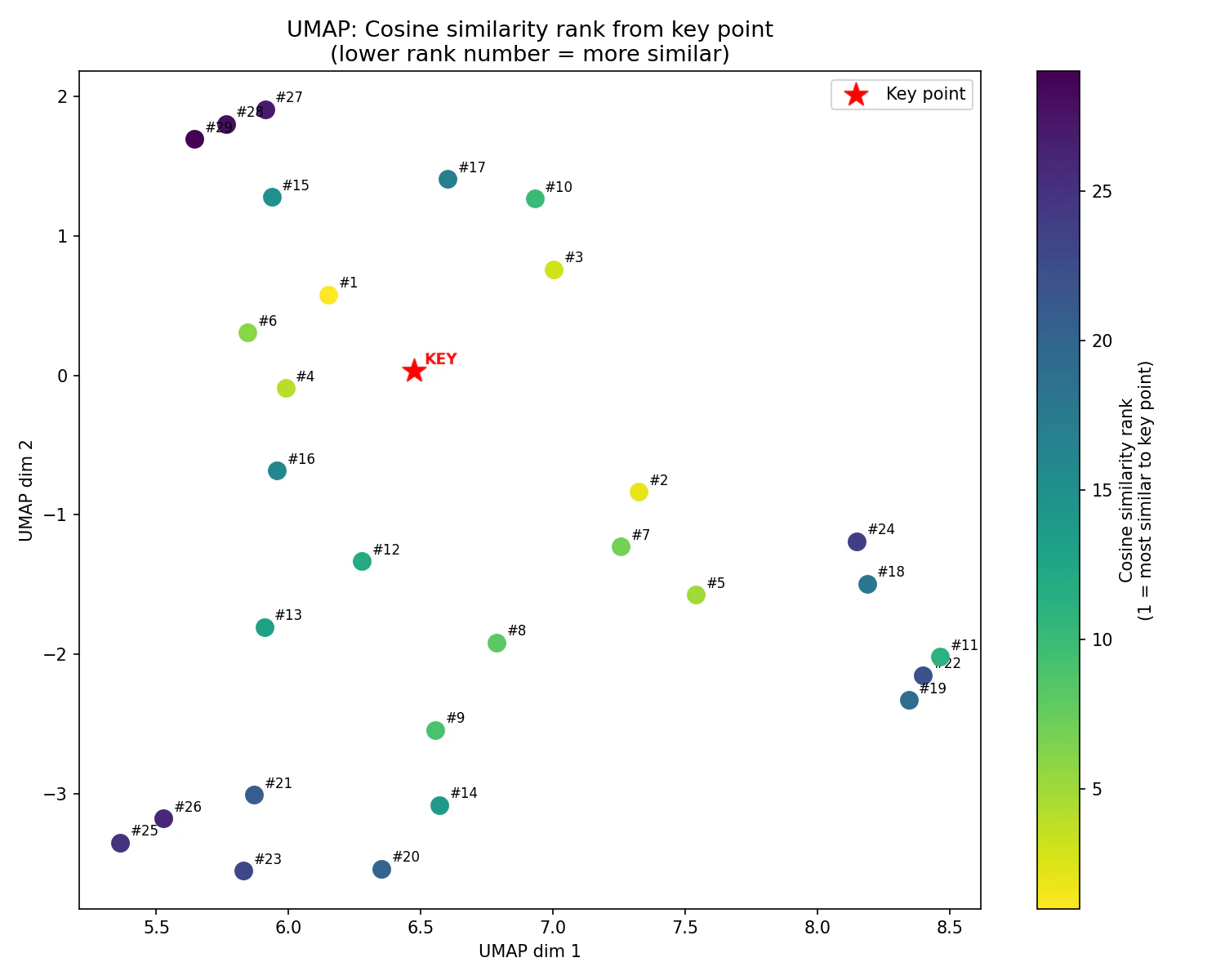
各点についている#付きの数字は,キーポイントとその他の点とのコサイン類似度を計算した際の順位になります.私の予想では,この順位が高いほど,キーポイントに近い位置にプロットされる想定でした.しかし,実際にはt-SNE, UMAPのどちらとも順位と距離が一致しないという結果になりました.順位が20位以下のデータは,比較的キーポイントから離れた位置に配置される傾向にあります.一方で,例えばUMAPの図では,3位と10位と17位がキーポイントから同じくらいの距離でプロットされているように,順位が高いほどキーポイントから距離が離れるわけではありませんでした.高次元空間で表現されていたものを,点間の関係性を維持したまま低次元で表現することは難しいようです.
まとめ
本記事では,PCA, t-SNE, UMAPのアルゴリズムを確認し,線形,非線形手法の比較,近傍点数の変化による次元削減結果の変化,次元削減後の点間の距離についての考察についてまとめました.次元削減は,データセット全体の大まかな特徴を見るために可視化することには使えそうですが,データ間の関係性から分析することには応用できなさそうです.
参考文献
- https://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
- https://arxiv.org/pdf/1802.03426
- https://arxiv.org/pdf/2012.04456
- https://distill.pub/2016/misread-tsne/
IGSAについて
IGSAは,社会を温かく柔らかく持続的に支えるAIシステムにより,持続可能な幸せを目指す,東京大学松尾・岩澤研究室発のAIカンパニーです.
脳の健康管理アプリ「はなしてね」や,中古品の画像解析SaaS「スグトリ」などのAIプロダクト提供に加え,潜在的な課題に対し柔軟な開発支援を行うパートナー事業を展開.センシングAI技術を活用した状態の定量化と分析により,人の意思決定をサポートしています.