はじめに
本記事ではプライバシー強化技術(PETs)の要素技術の一つである、連合学習(Federated Learning)について解説します。プライバシー強化技術全体についての説明は下記記事をご覧ください。
また、本技術に関する簡易的な検証は下記記事をご覧ください。
(本記事では連合学習のうち、水平連合学習と呼ばれるもののみを対象にしています。)
連合学習(Federated Learning)とは
連合学習(Federated Learning)は分散して存在するデータを一箇所に集約することなく、分散環境で学習されたモデルのパラメータや更新情報のみを集約することで1つの統合モデルを全体で学習する学習手法です。「Federated Learning」という単語はGoogleが2016年に投稿した論文1の中で提唱されました。
従来、分散して存在するデータを用いて一つの機械学習モデルを学習するためには、全てのデータを一箇所に集約して学習を行う必要がありました。その場合、組織が持つ個人情報などの機密性の高い情報を共有することに高いハードルがあり、実現が困難となっておりました。
連合学習を用いることで、データを一箇所に集約することなく機械学習モデルを学習することが可能になるため、データ分析におけるプライバシー保護を強化することができる技術として注目されています。

連合学習を用いることで、ISO/IEC 29100プライバシーフレームワークで定められているData Minimization(目的に沿ってパーソナルデータへのアクセス、収集するパーソナルデータ、個人の特定や属性推定などの処理を必要最小限にする)を強化することが期待されます。
FederatedAveraging(FedAvg)
代表的な連合学習のアルゴリズムとしてFederatedAveraging(FedAvg)が挙げられます。
こちらも1の中で提案されました。
アルゴリズムのイメージを以下に記載します。
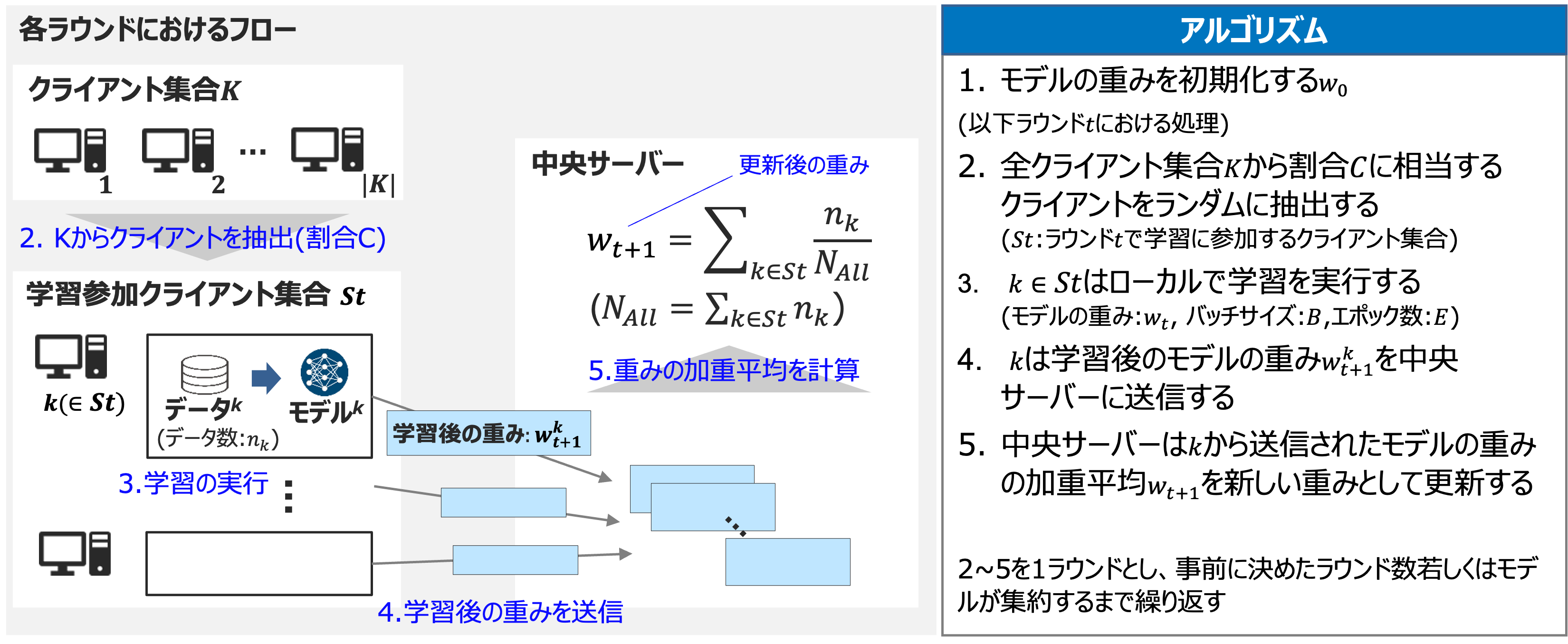
論文中ではモバイルデバイスに焦点を当てており、連合学習が適するタスクとして画像分類のモデルや次の単語の予測を行う言語モデルを挙げています。多数のモバイルデバイスが学習に参加する状況を想定しているため、FedAvgにおける学習の各ラウンドでは一部のクライアントが学習に参加するというアルゴリズムになっています。
一方で、少数の組織間で連合学習を行う事例では、各ラウンドですべてのクライアントが参加する方式も利用されており、連合学習を分類する際のポイントの一つとなっています。(サーベイ論文2では前者をCross-Device, 後者をCross-Siloと表現しています。)
連合学習の適用事例
代表的な連合学習の事例を4つ紹介します。
1. Gboard(Google)
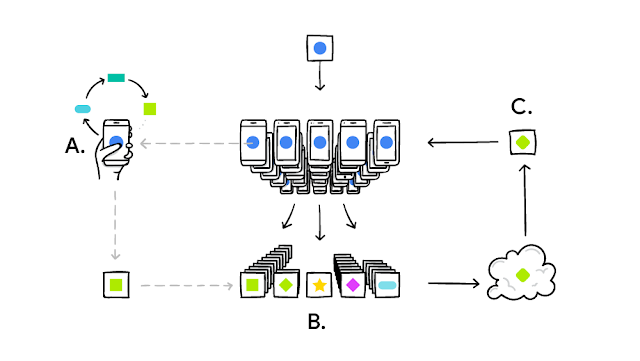
Googleが提供するGboardというソフトウェアキーボードでは、内部の予測モデルの学習・更新に連合学習が用いられています。
予測モデルの改善には利用者の変換履歴データを使う必要がありますが、予測履歴はプライバシー情報のため収集が困難という課題がありました。連合学習を用いることで、生の変換履歴データを収集することなく、予測変換モデルの学習を可能にしています。また、この学習はデバイスが使用されておらず、電源に接続され、通信料のかからない状態でのみ実行されるため、スマートフォンのパフォーマンスに影響を与えないことも特徴として挙げられます。
2. COVID-19 異常検知連合学習
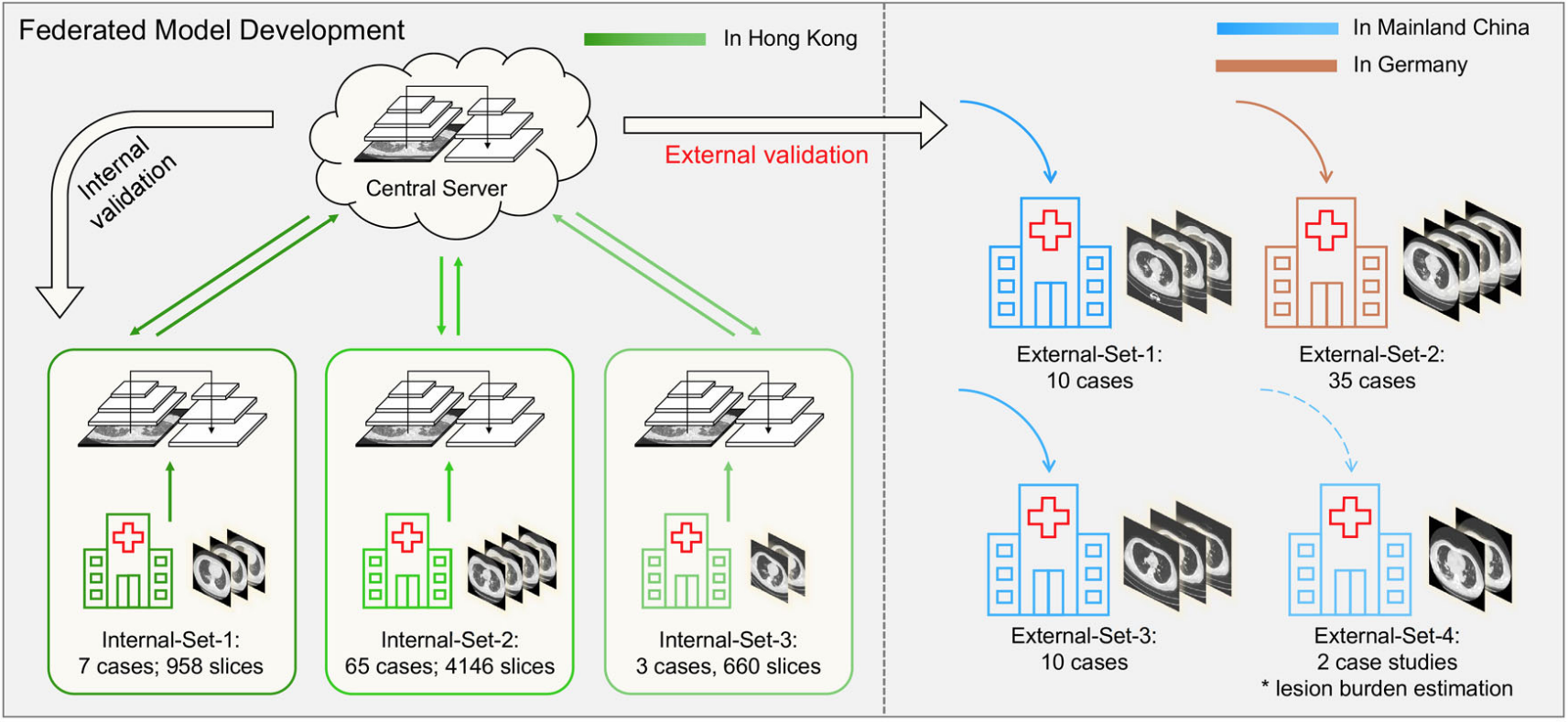
COVID-19のCT画像における肺の異常を検出するために連合学習を用いた研究です。
香港の3つの病院のCTデータを使用し、連合学習を用いてCNNベースのAIモデルの学習を行い、中国本土とドイツの病院のデータセットを用いて検証を行っています。その結果、3つの単一施設で学習したモデルすべておよびそれらのアンサンブルモデルよりも優れた汎化性能を示すことが報告されています。
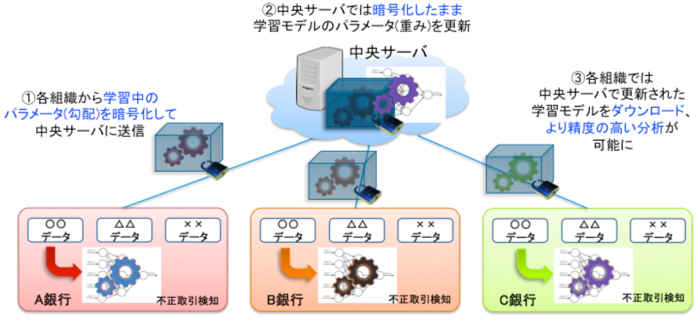
3. 金融不正送金検知連合学習(NICT他)
NICT(情報通信研究機構)、神戸大学および三菱UFJ銀行をはじめとする金融機関5行が、不正送金の検知のためのモデルを連合学習を用いて学習する実証実験を行いました。単独の金融機関では学習に十分な量の不正な取引データを用意することが難しいことや、機微な金融取引データを金融機関外に持ち出すことが難しいといった課題を連合学習により解決し、目標としていたモデルの精度を達成しています。また、個別の学習モデルでは検知できなかった不正取引が検知された事例も報告されています。
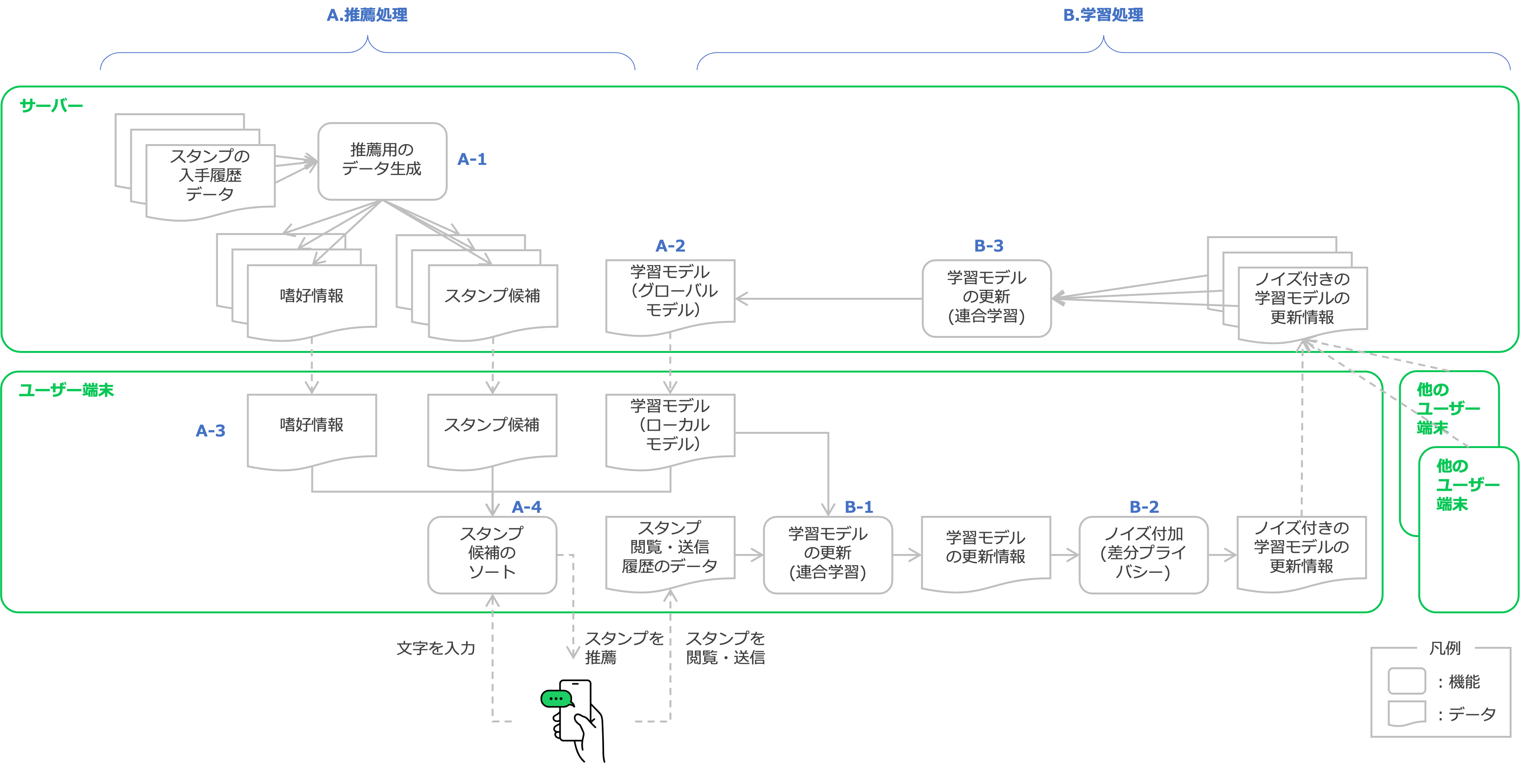
4. LINEスタンプ推薦連合学習
LINEスタンプ プレミアム(1000万異常のスタンプが使い放題)におけるスタンプの推薦モデルの学習に連合学習が使用されています。連合学習を用いることで、ユーザーのプライバシーを保護しながら、より精度の高い推薦モデルを構築することを可能としています。
著者の知る限り、日本国内において初めて連合学習が社会のサービスに実装された事例です。
連合学習の安全性
連合学習の研究領域の一つに安全性(連合学習に対する攻撃とその防御手法)があります。
代表的な研究が機械学習モデルから学習に使用されたデータを復元するものです。下記画像の例では、一枚のデータを用いて学習した機械学習モデルの更新情報と機械学習モデル本体を取得した悪意のある攻撃者が、その更新情報を再現するような入力画像をノイズから復元しています。
(上記の例は極端な条件を前提にしていますが、分かりやすいデータ再構築攻撃の一例として挙げています。)

上記の攻撃等に対処するため、連合学習でモデルを共有する際は生の学習済みモデルを直接共有するのではなく、別の保護技術と掛け合わせて用いる事例がほとんどです。
Gboardの事例では暗号化技術を使用するSecureAggregationプロトコル3を用いてモデルの集約を安全に実行しています。NICTの事例も準同型暗号技術等の秘密計算技術によって、暗号化されたモデルを中央サーバにアップロードし、中央サーバはモデルを暗号化したままモデルの統合・更新を行います。これにより、不正にモデルや更新情報を取得する攻撃者や、中央サーバによるデータの復元を防ぐことが可能となります。
LINEスタンプの事例では、クライアントがサーバに送信するモデルの更新情報に対して(局所)差分プライバシーを保証することで、モデルからユーザーの実際の行動を推定することを困難にしています。4
まとめ
本記事ではプライバシー強化技術(PETs)の要素技術の一つである、連合学習(Federated Learning)について解説しました。
連合学習はデータを共有せずにモデルのみを共有することで、データの対象者のプライバシーを保護することが可能になる技術です。従来であれば困難であった複数の病院や金融機関が協働してAIモデルを学習する事例も、連合学習により登場しています。しかし、連合学習を使えば全てが安全というわけではなく、正しい保護を実現するためには他の技術の活用や正しいシステム設計が必要不可欠です。今後、連合学習を正しく活用する事例が増え、組織間でのデータ連携がより活発化することを期待します。
-
McMahan, H. Brendan, et al. “Communication-Efficient Learning of Deep Networks from Decentralized Data.” arXiv preprint arXiv:1602.05629 (2016). https://arxiv.org/pdf/1602.05629v1 (初版) ↩ ↩2
-
Li, Qinbin, et al. “A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection.” arXiv preprint arXiv:1907.09693 (2019). Available at: https://arxiv.org/pdf/1907.09693 ↩
-
Bonawitz, Keith, et al. “Practical Secure Aggregation for Privacy Preserving Machine Learning.” Cryptology ePrint Archive, Paper 2017/281 (2017). https://eprint.iacr.org/2017/281 ↩
-
Technical Whitepaper Differential Privacy in LINE Federated Learning, https://d.line-scdn.net/stf/linecorp/en/csr/line-differential-privacy-whitepaper-ver1.0.pdf ↩